LLM 回答更加准确的秘密:为检索增强生成(RAG)添加引用源
如何让你的大模型变得更强?如何确定其获取信息来源的准确性?
想要回答这两个问题,就不得不提到今天文章的主角——RAG。RAG,也就是检索增强生成(Retrieval-augmented generation) ,可以弥补现有 LLM 应用能力的技术。
当前,LLM 的最大问题就是缺乏最新的知识和特定领域的知识。对于这一问题,业界有两种主要解决方法:微调和检索增强生成。业内许多公司(如 Zilliz、OpenAI 等)都认为相比微调,RAG 是更好的解决方法。归根究底是因为微调的成本更高,需要使用的数据也更多,因此主要适用于风格迁移(style transfer)的场景。相比之下,RAG 方法使用例如 Milvus 之类的向量数据库,从而将知识和数据注入到应用中,更适用于通用场景。
采用 RAG 方法就意味着使用向量数据库存储真理数据,这样可以确保应用返回正确的信息和知识,而不是在缺乏数据时产生幻觉,捏造回答。不过,随着越来越多的文档、用例等信息被注入应用中,越来越多开发者意识到信息来源的重要性,它可以确保信息准确性,使得大模型的回答更加真实。
这就需要用到引用或者归属(attribution)。如果返回的响应带有引用或者归属,那么我们就可以了解该响应内容来自于哪个文档或文档中的哪个片段。因此,本文将详解为 LLM 加入引用的重要性,以及如何获取引用来源。
01.如何添加 RAG 引用源?
正如上文所说,RAG(https://zilliz.com/use-cases/llm-retrieval-augmented-generation) 引用源是一种通用的解决方案,可以为 LLM 应用的响应添加引用源,从而为响应提供更多上下文信息。那么如何为响应添加 RAG 引用源呢?其实有很多解决方法。你既可以将文本块存储在向量数据库中,也可以使用 LlamaIndex 之类的框架。
接下来就让我们深入代码,学习如何同时使用 LlamaIndex 和 Milvus(https://zilliz.com/what-is-milvus) 为 LLM 响应添加引用源。
开始之前
开始前,先通过 pip install milvus llama-index python-dotenv安装所需工具和框架。milvus 和 llama-index是核心功能,而 python-dotenv用于加载环境变量,例如 OpenAI 的 API 密钥。
在本示例中,我们从百科中获取了不同城市的数据,并进行查询,最终获得带引用的响应。
首先,导入一些必要的库并加载 OpenAI API 密钥,同时也需要用到 LlamaIndex 的 7 个子模块。在本示例中,OpenAI用于访问 LLM,CitationQueryEngine用于创建引用查询引擎,MilvusVectorStore用于将 Milvus 作为向量存储数据库。此外,导入 VectorStoreIndex来使用 Milvus,SimpleDirectoryReader 用于读取本地数据,以及 StorageContext 和 ServiceContext用于访问 Milvus。最后,用 load_dotenv加载我们的 OpenAI API 密钥。
from llama_index.llms import OpenAI
from llama_index.query_engine import CitationQueryEngine
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
ServiceContext,
)
from llama_index.vector_stores import MilvusVectorStore
from milvus import default_server
from dotenv import load_dotenv
import os
load_dotenv()
open_api_key = os.getenv("OPENAI_API_KEY")
获取测试数据
首先准备和处理数据,下面的代码从百科 API 中获取了 wiki_titles列表中提到的页面并将结果保存到本地文件中。
wiki_titles = ["Toronto", "Seattle", "San Francisco", "Chicago", "Boston", "Washington, D.C.", "Cambridge, Massachusetts", "Houston"]
from pathlib import Path
import requests
for title in wiki_titles:
response = requests.get(
'<https://en.wikipedia.org/w/api.php>',
params={
'action': 'query',
'format': 'json',
'titles': title,
'prop': 'extracts',
'explaintext': True,
}
).json()
page = next(iter(response['query']['pages'].values()))
wiki_text = page['extract']
data_path = Path('data')
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", 'w') as fp:
fp.write(wiki_text)
在 LlamaIndex 中设置向量存储(Vector Store)
数据准备完成后,可以设置带应用逻辑。首先,我们需要启动向量数据库。在本例中,我们使用 Milvus Lite,因为它可以直接在笔记本电脑上运行。然后,用 LlamaIndex 的 MilvusVectorStore模块连接 Milvus,将其作为向量存储。
default_server.start()
vector_store = MilvusVectorStore(
collection_name="citations",
host="127.0.0.1",
port=default_server.listen_port
)
接着,为索引创建上下文,从而帮助索引和检索器了解需要使用哪些服务。本例使用 GPT 3.5 Turbo。此外,我们还需要创建一个存储上下文,以便索引知道在哪里存储和查询数据。本例使用上述创建的 Milvus 向量存储。
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0)
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
设置完成后可以加载此前爬取的数据,并创建向量存储索引。
documents = SimpleDirectoryReader("./data/").load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
带引用的查询
这一步可以创建一个引用查询引擎。可以设置向量索引,返回结果数量以及引用文本块大小。随后运行查询命令。
query_engine = CitationQueryEngine.from_args(
index,
similarity_top_k=3,
# 此处我们可以控制引用来源的粒度,默认值为 512
citation_chunk_size=512,
)
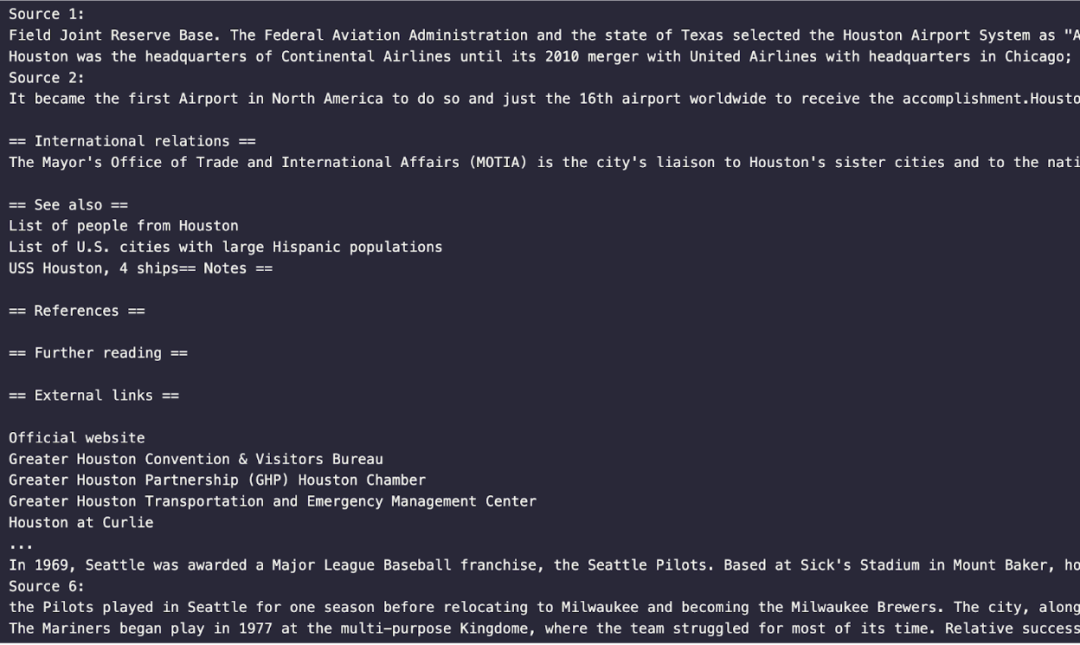
response = query_engine.query("Does Seattle or Houston have a bigger airport?")
print(response)
for source in response.source_nodes:
print(source.node.get_text())
响应如下所示:
 8179.png
8179.png
02.总结
RAG 应用是流行的 LLM 应用。本文教学了如何为 RAG 添加引用或归属。
具体来看,可以使用 LlamaIndex 作为数据路由器,Milvus 作为向量存储来构建带有引用的 RAG 应用。本文提供的示例代码先从百科上获取一些数据,然后启动一个 Milvus 实例,并在 LlamaIndex 中创建一个向量存储实例。将数据存入 Milvus 中,并使用 LlamaIndex 构建引用查询引擎来追踪返回响应的归属和引用源。
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
 Yujian Tang
Yujian Tang