



层归一化与批量归一化 - 在神经网络中解锁效率
随着神经网络在复杂性和规模上的增长,确保稳定和高效的训练变得越来越具有挑战性。在高效的训练中,归一化技术介入以减轻其中的一些挑战。归一化确保通过网络层传递的数据保持在可管理的范围内。2015年,谷歌的一篇论文提出了一种批量归一化技术;一年后,多伦多大学的一篇论文提出了一种层归一化技术。
 15.1.JPEG
15.1.JPEG
本文将揭开这些归一化技术的神秘面纱,探索它们独特的功能、优势、应用和Python语法。通过解开层归一化和批量归一化的复杂性,我们的目标是为神经网络初学者提供解锁效率和增强模型性能所需的知识。
理解归一化
归一化涉及缩放和移动输入数据,以确保其落在某个特定范围或分布内。这个过程不仅有助于减轻不同数据分布的影响,而且还有助于通过确保神经网络每层的输入在可管理的范围内来稳定学习过程。
归一化解决的一个主要挑战是内部协变量偏移。内部协变量偏移是指随着网络学习,进入每个神经网络层的数据发生变化的现象。想象一下尝试击中一个移动的目标——准确瞄准并不容易。同样,当数据不断变化时,网络就很难有效地学习。归一化有助于保持数据更稳定,就像稳定你的目标,使网络能够更好地、更快地学习。
归一化技术通过在输入数据的分布上强制一致性来减轻内部协变量偏移,从而促进更平滑、更有效的训练。通过归一化输入,神经网络可以保持更稳定的梯度流动,从而导致更快的收敛,并提高神经网络模型的整体效率和准确性。
 15.2.JPEG
15.2.JPEG
批量归一化解释
批量归一化是一种在神经网络训练中广泛使用的技术,提供了一种系统化的方法来归一化每个层的输入,跨越不同的小批量数据。这个过程涉及通过减去批量均值并除以批量标准差来归一化给定层的激活。
批量归一化的过程和公式如下:
 15.3.PNG
15.3.PNG
通过在每个小批量内归一化输入,批量归一化有助于减少内部协变量偏移,稳定训练过程并加速收敛。这种归一化使神经网络能够更有效地学习,特别是在可能发生消失或爆炸梯度问题的更深层架构中。
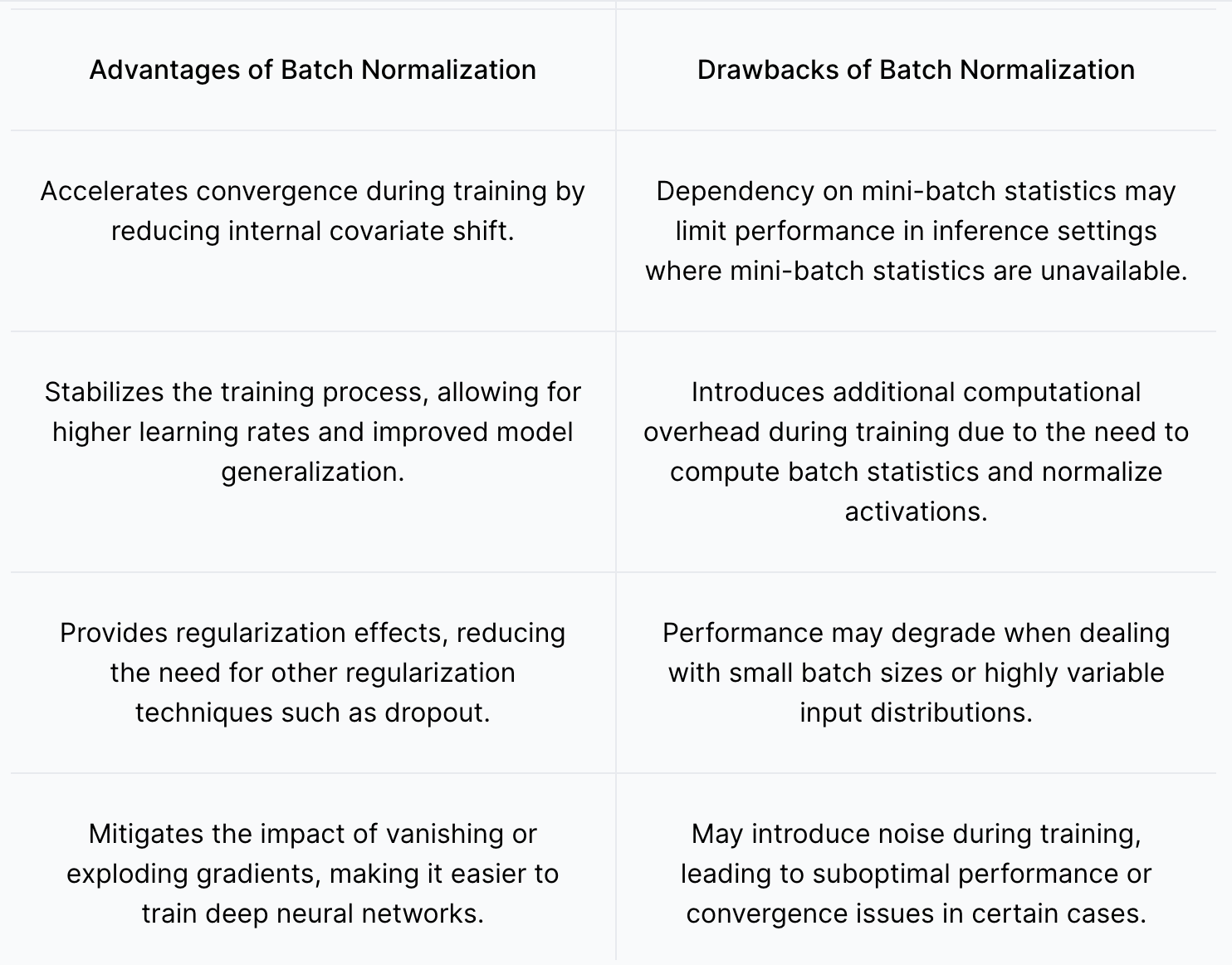
这个归一化过程独立地应用于每个输入张量特征维度(通道)。参数γ和β在训练期间与其他神经网络参数一起学习。 批量归一化的优势和缺点
批量归一化的4个主要优势和潜在缺点如下表所示:
 15.5.png
15.5.png
层归一化和批量归一化之间的选择取决于多种因素,包括数据集的特定特征、神经网络的架构以及训练环境的计算限制。虽然批量归一化在稳定训练动态和加速收敛方面表现出色,但层归一化提供了更大的灵活性和鲁棒性,特别是在小批量大小或波动的数据分布场景中。
实际应用和用例
层归一化和批量归一化在各个领域都有广泛的应用,展示了它们在增强神经网络训练和性能方面的有效性。在这里,我们深入探讨了这些归一化技术已经有效实施的真实世界应用和场景:
- 图像处理:在计算机视觉任务中,如目标检测和图像分类,层归一化和批量归一化在稳定训练动态和提高模型泛化方面发挥着关键作用。这些技术有助于减轻数据可变性的影响,并增强神经网络模型对光照条件、视角和对象尺度变化的鲁棒性。
- 自然语言处理(NLP):在NLP任务中,如语言建模、机器翻译和情感分析,归一化技术在解决不同句子长度、词汇分布和语言细微差别的挑战方面至关重要。层归一化和批量归一化有助于稳定训练过程,使神经网络模型能够捕捉长距离依赖关系,并在多样化的文本数据集上实现更优的性能。
- 强化学习:在强化学习应用中,如游戏和机器人技术,归一化技术在稳定学习过程和加速策略收敛方面至关重要。通过确保对策略参数的一致和稳定更新,层归一化和批量归一化促进了更有效的探索和开发策略,从而提高了学习效率和任务性能。
- 生成建模:在生成建模任务中,如图像和文本生成,归一化技术对于确保训练过程的稳定性和收敛至关重要。层归一化和批量归一化有助于减轻模式崩溃并提高生成样本的多样性和质量,从而产生更真实和连贯的输出。
 15.6.jpeg
15.6.jpeg
通过探索这些不同的应用和用例,我们获得了关于层归一化和批量归一化在不同领域和任务中的多功能性和有效性的宝贵见解。在下一节中,我们将讨论神经网络中归一化技术的新趋势,提供对这个不断发展领域的未来一瞥。接下来的部分将查看在Python编程语言中用于图像识别的批量归一化和层归一化的实践动手示例。
Python中的批量归一化示例
我们首先导入所有必要的依赖项:
python 导入所有必要的包 import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, BatchNormalization
from tensorflow.keras.optimizers import Adam
然后,我们加载MNIST数据集并预处理数据:
python
加载MNIST数据集
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
接下来,我们定义一个没有批量归一化的简单神经网络模型(model_no_bn)如下:
python
定义一个没有批量归一化的简单神经网络模型
model_no_bn = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
然后,我们编译并训练没有批量归一化的模型:
python
编译并训练没有批量归一化的模型
model_no_bn.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history_no_bn = model_no_bn.fit(X_train, y_train, epochs=5, validation_data=(X_test, y_test), verbose=2)
我们定义一个带有批量归一化的简单神经网络模型(model_with_bn):
python
定义一个带有批量归一化的简单神经网络模型
model_with_bn = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
BatchNormalization(),
Dense(10, activation='softmax')
])
我们编译并训练带有批量归一化的模型:
python
编译并训练带有批量归一化的模型
model_with_bn.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history_with_bn = model_with_bn.fit(X_train, y_train, epochs=5, validation_data=(X_test, y_test), verbose=2)
最后,我们可视化两个模型的训练曲线以比较它们的性能。
python
可视化训练曲线
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(history_no_bn.history['accuracy'], label='Train Accuracy (No BN)')
plt.plot(history_no_bn.history['val_accuracy'], label='Validation Accuracy (No BN)')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training Curves without Batch Normalization')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history_with_bn.history['accuracy'], label='Train Accuracy (With BN)')
plt.plot(history_with_bn.history['val_accuracy'], label='Validation Accuracy (With BN)')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training Curves with Batch Normalization')
plt.legend()
plt.tight_layout()
plt.show()
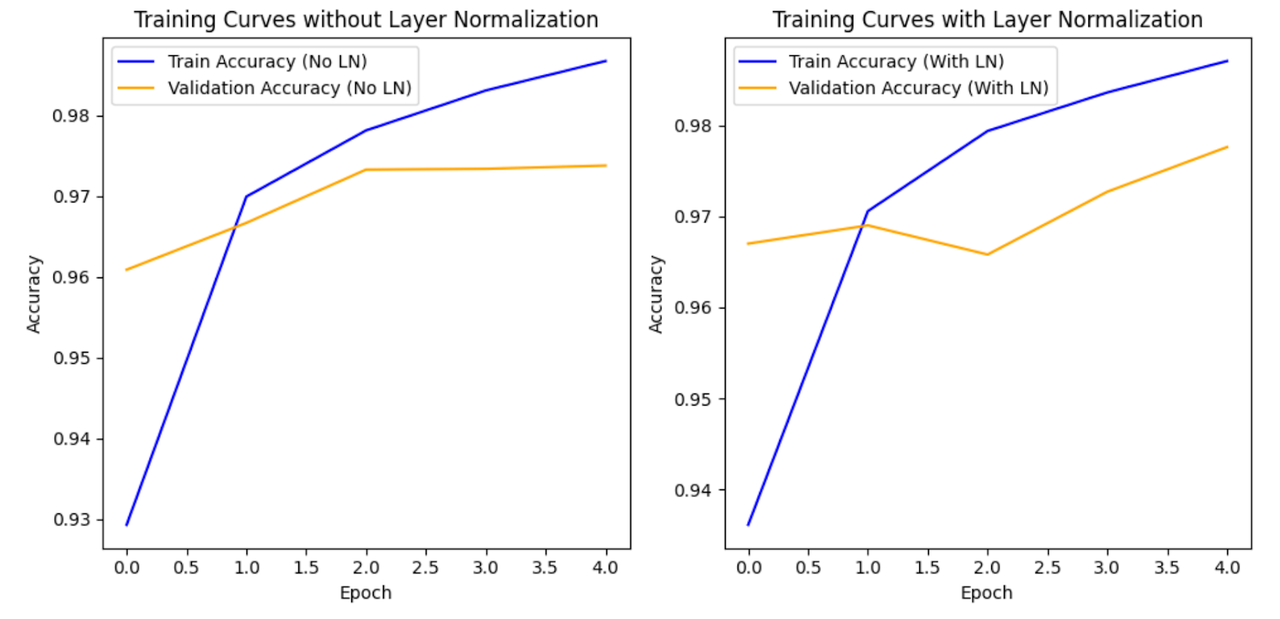
上述整个脚本的输出将如下所示(注意,每次执行时您的图表都会有所不同):
 15.7.png
15.7.png
解释输出
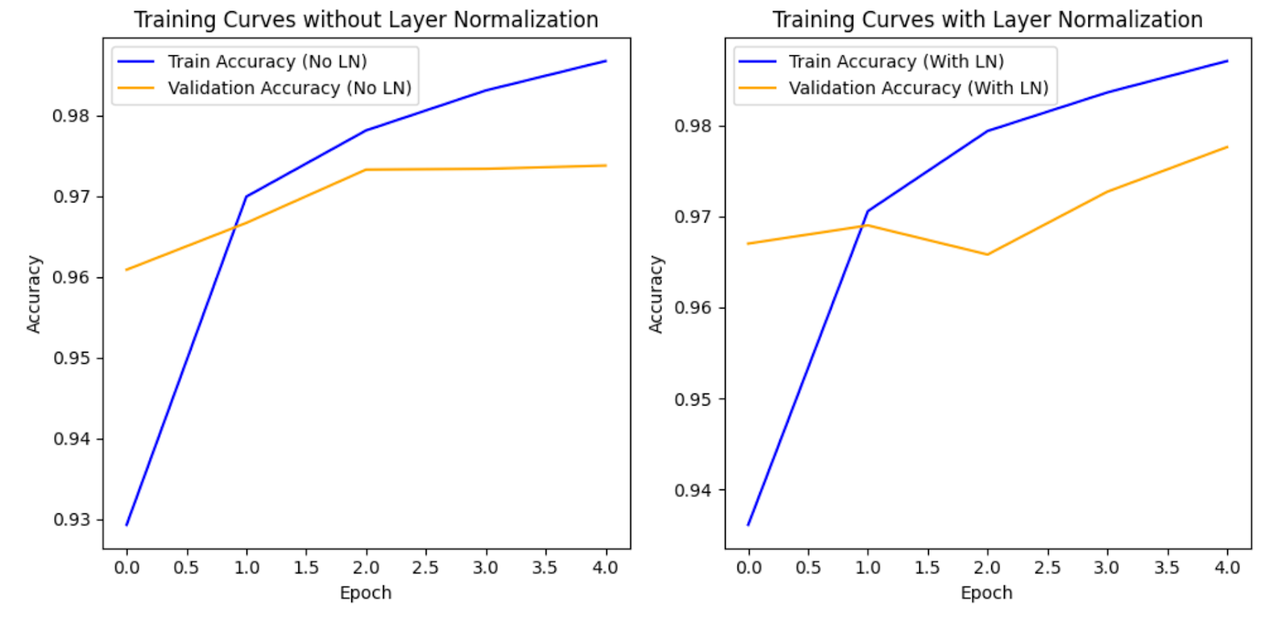
训练日志显示了每个epoch期间训练和验证集的损失和准确性值。 解释结果:
 15.8.png
15.8.png
- 损失和准确性趋势:观察损失值,我们希望它们随着epoch的减少,这表明模型在其预测中正在改进。相应地,我们希望看到准确性值的增加,反映出在训练和验证数据集上更好的性能。
- 更快的收敛:带有批量归一化的模型似乎更快地收敛。"收敛"是指模型性能稳定或达到高原的点。在这种情况下,它意味着模型更快地学习数据中的模式,并在训练过程中更早地实现更高的准确性。
- 学习率:虽然"学习率"一词通常指的是优化算法中的超参数,但在这里,它可以非正式地理解为模型从训练数据中学习的速度。更快的收敛通常意味着更高的有效学习率,意味着模型更快地更新其参数以最小化损失。
总结来说,带有批量归一化的模型展示了更快的学习速度,并在更少的epoch中实现了更好的性能(更高的准确性),与没有批量归一化的模型相比。这表明批量归一化在稳定和加速训练过程中的有效性。
 Shivek Santosh Maharaj
Shivek Santosh MaharajFreelance Technical Writer

