



开始使用LLMOps:构建更好的AI应用
OpenAI的ChatGPT的出现,在企业中引发了对大型语言模型(LLMs)的浓厚兴趣。主要的科技公司和研究机构现在正使LLMs更加易于获取,努力增强数据基础设施,为定制应用微调模型,并监控幻觉和偏见等问题。这种日益增长的兴趣也导致了对支持大型语言模型操作(LLMOps)的技术供应商的需求激增。这些供应商为开发、微调和将LLMs部署到生产环境中提供了全面的工作流程。
在最近的非结构化数据 meetup 上,Union.ai的机器学习工程师Sage Elliott讨论了部署和管理LLMs的问题,提供了将这些模型集成到商业应用中所需的工具、策略和最佳实践的宝贵见解。他的演讲对AI开发人员和运维经理特别有帮助,重点关注确保生产环境中LLM应用的可靠性和可扩展性。
在这篇文章中,我们将回顾Sage演讲的关键见解,并讨论LLMOps的概念和方法论。
什么是LLMOps?
LLMOps代表大型语言模型操作,它与MLOps类似,但专门针对大型语言模型(LLMs)。要理解LLMOps,我们首先来拆解MLOps。
MLOps(机器学习运营)指的是在生产环境中有效部署和维护机器学习模型的实践和工具。它是DevOps(开发和运营)的扩展,将应用开发和运营整合为一个协同过程。这种方法确保开发和运营不是分别在各自的孤岛中运作,而是被一起考虑。
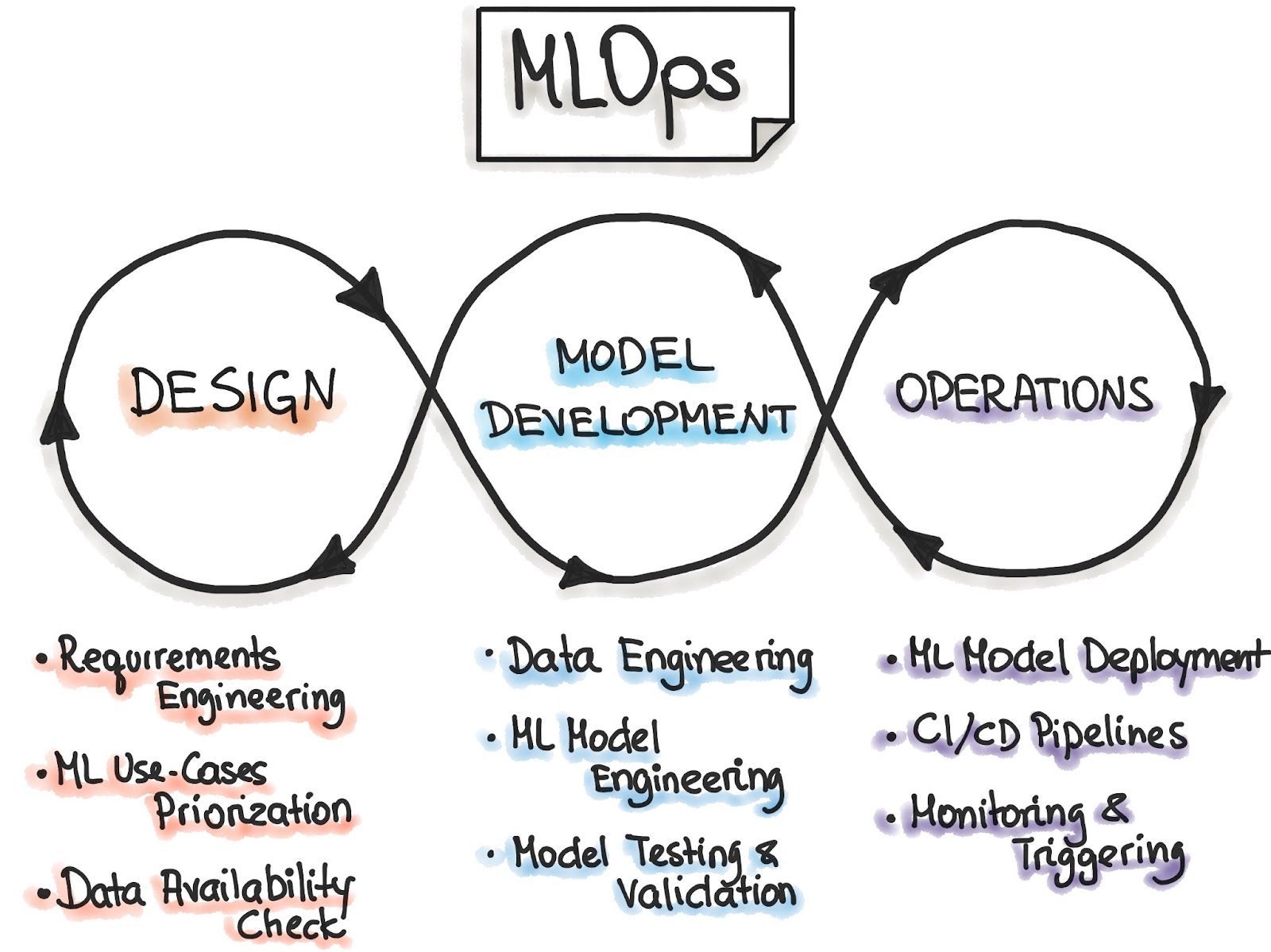 What_are_ML_Ops_49f2255e73.jpg
What_are_ML_Ops_49f2255e73.jpg
什么是MLOps?图片来源:https://ml-ops.org/content/MLOps-principles
在DevOps方法出现之前,开发团队专注于尽可能快地编写应用程序或更新,而运维团队则优先考虑应用程序的稳定性、效率和用户体验。这种分散的方法常常导致效率低下,导致应用程序开发缓慢,更新不频繁。
DevOps通过促进开发和运维团队之间的协作,转变了这一过程,确保了更流畅、更高效的工作流程。MLOps将这些原则扩展到机器学习,解决了部署和维护ML模型的挑战。
LLMOps通过将MLOps的原则应用于大型语言模型(LLM)应用,采取了全面的方法。它涉及开发、部署、维护和持续改进LLM应用的所有方面。
合作的中心理念也内在于Sage对LLMOps的定义——“共同构建AI”,这强调了所有相关业务单位,例如开发、运维、产品管理等,必须协同工作,以及时、经济高效的方式生产性能最佳的LLM应用。
持续集成和持续交付/部署(CI/CD)
与DevOps一样,LLMOps的一个核心原则是持续集成/持续部署(CI/CD):自动化LLM应用开发生命周期的过程。
持续集成(CI)是自动获取应用程序更新并与主分支合并的做法,即当前在生产中运行的LLM应用版本。当开发人员将代码提交到代码库,如GitHub时,这一行动会触发一个自动化工作流程,验证更新是否准备好进行集成。CI鼓励开发团队频繁更改,并有助于避免代码合并冲突。
持续交付/部署(CD)指的是在集成和验证后自动将更改部署到生产环境中的应用的过程。这个过程包括进一步的测试,如功能和用户接受测试以及基础设施配置。
尽管持续交付和部署通常可以互换使用,但它们之间存在差异。持续交付不包括自动生产部署,通常需要人工进行最终检查以确保组织和法规合规性。相反,持续部署会自动向用户发布应用程序更新。考虑到这一概念,真正的持续部署是罕见的——特别是在LLM应用开发中,它仍处于起步阶段。
谁应该使用LLMOps?
简而言之,任何开发LLM应用的人都应该在某种程度上使用LLMOps。
一方面,LLMOps对于生产级别的AI应用至关重要,确切的基础设施取决于应用程序的需求。相比之下,即使是一个简单的个人AI项目,也会从实施一个简单的LLMOps管道中受益。
将LLMOps集成到您的AI应用中提供了以下好处:
- 资源管理和可扩展性:了解您对计算资源的使用情况,以提供最佳的用户体验。LLMs需要大量的内存才能有效运行,因此能够确定您的硬件,即GPU,是否足以满足您的应用需求至关重要。
- 模型更新和改进:更快地了解模型的失败或不足,并相应地更新它们。
- 道德和负责任的AI实践:意识到您的AI应用的预期目的及其故障的潜在后果。关于LLMs的一个主要担忧是它们倾向于“幻觉”,即提供不准确或不相关的输出;如果这发生在提供医疗建议的应用中,可能会导致灾难性后果。
简化的LLMOps管道示例
CBInsights创建的市场地图确定了90多家公司,这些公司跨越12个类别,帮助企业从头到尾管理LLM项目。这一格局还显示了LLMOps市场的规模。
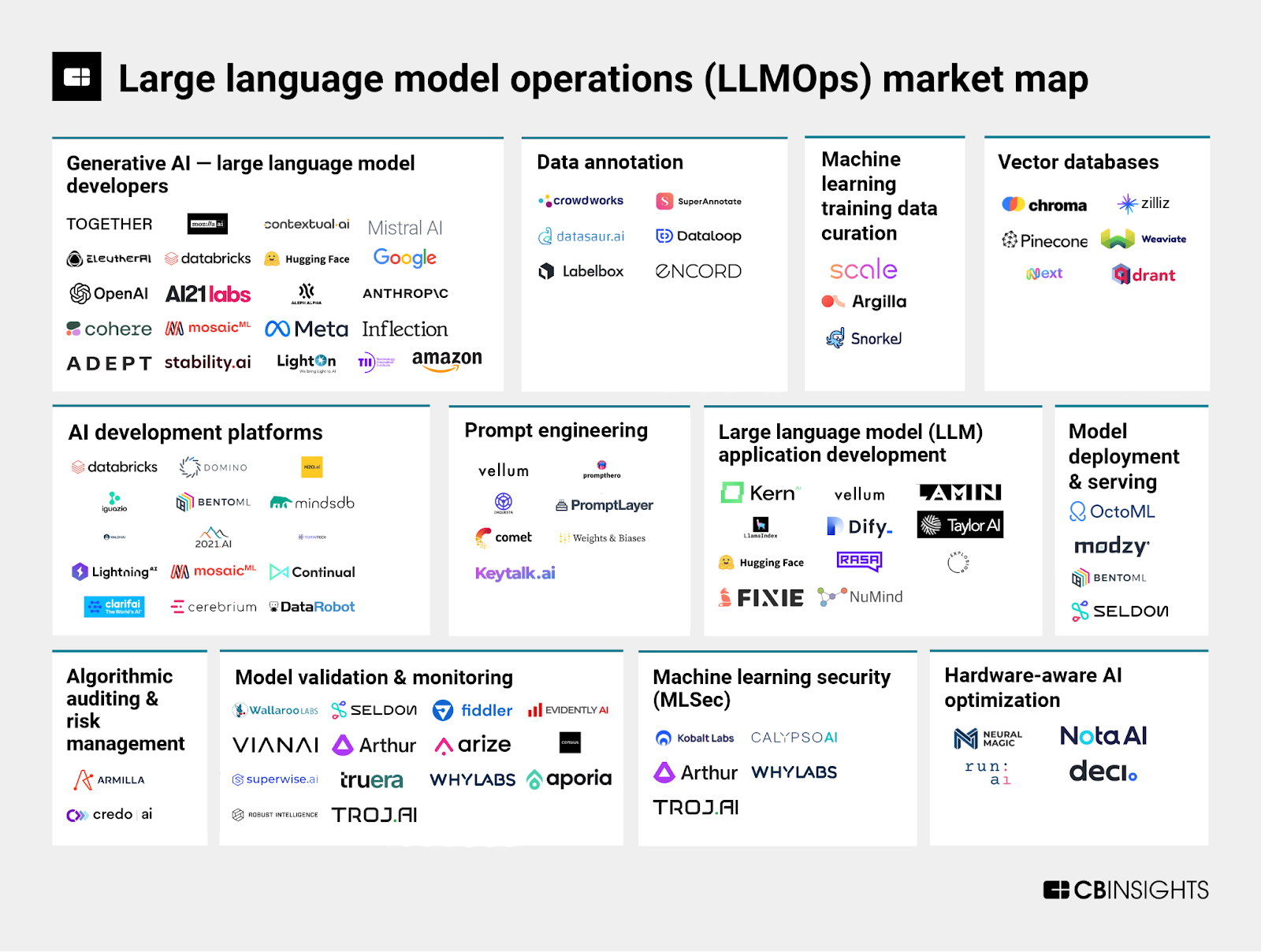 LLM_Ops_market_landscape_6ac51baf56.png
LLM_Ops_market_landscape_6ac51baf56.png
LLMOps市场格局:90多家公司跨越12个不同类别,帮助企业将LLM项目从开始到结束。
为了更容易理解,Sage创建了一个简化的LLMOps管道。
简化的LLMOps管道
让我们解释这幅图的元素:
- 系统提示:用户输入成为系统提示的一部分,并输入到LLM中。
- 模型:LLM是应用的基础,用于生成答案。
- 护栏:您放置的控制措施,以确保用户只输入适当的输入,即试图让模型生成有害或冒犯性内容。
- 数据存储:像Milvus和Zilliz Cloud(托管的Milvus)这样的向量数据库。这些数据库为LLM提供长期记忆和上下文查询信息,并帮助LLM生成更准确的结果。这个组件在检索增强生成(RAG)应用中特别有益。
- 监控:用于持续监控LLM应用的工具。
- CI/CD协调器:一个管理您的应用程序并帮助自动化其集成和部署到生产环境的平台。
开始使用LLMOps
尽管LLMOps正在迅速变化,供应商每天都在发布新的LLMOps工具,但幸运的是,LLMOps的核心原则保持不变。
这里有一个简单的三步哲学,用于开始使用LLMOps。
发货模型
发货模型指的是尽快将您的LLM应用部署到生产环境中。这种方法至关重要,因为它使您能够从与模型互动的用户那里获得准确的数据,并快速了解如何将您的LLM应用适应用户的需求。一个主要的例子是聊天机器人应用,从中获得真实用户输入的例子以及模型的响应输出,比仅仅在测试环境中预测输入要有帮助得多。
HuggingFace Spaces是一个很好的资源,它简化了将您的模型部署到生产环境的过程。它是一个托管平台,适用于大多数ML应用,提供低成本的云GPU来驱动LLMs,这使得它非常适合原型设计。您还可以将您的应用部署到一个私有空间,提供对您想要测试您的LLM应用的人的有限访问,或者将其公开以从HuggingFace的大型和活跃社区中获得反馈。
 Hugging_Face_Spaces_4ae8674167.png
Hugging_Face_Spaces_4ae8674167.png
HuggingFace Spaces
HuggingFace提供的不仅仅是用于模型部署的空间;它为开发和部署应用提供了全面的生态系统。他们的核心产品是一个庞大的超过640,000个开源ML模型集合,包括语音、计算机视觉和语言模型。此外,HuggingFace还提供几个库,包括构建端到端LLM应用所需的所有组件,以及用于训练的数据集。
为了说明如何使用HuggingFace构建LLM应用,让我们看看如何使用其Transformer(用于访问LLMs)和Datasets(用于访问训练数据)库下载和训练模型。
首先,您需要安装适当的库:
pip install torch transformers datasets
接下来,我们将下载我们希望在我们的应用中使用的LLM。如上所述,HuggingFace拥有成千上万的模型,每个模型都提供了集成到您的应用中所需的代码。例如,我们将按如下方式加载Llama 3模型:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct”)
接下来,我们需要加载数据集以微调模型。对于这个例子,我们将使用HuggingFace提供的许多数据集之一。但是,如果您更喜欢使用自己的数据进行特定领域或特定任务的微调,您只需要将文件路径替换为指向您的训练数据文件夹的路径。
from datasets import load_dataset
dataset = load_dataset("talkmap/telecom-conversation-corpus")
加载数据集后,我们需要将其标记化,将其转换为LLM可以轻松处理的子词标记。我们必须使用与Llama 3模型相关的标记器,以确保数据与预处理过程一致,并保持相同的标记到索引,或“词汇表”。您可以用几行代码完成这一步。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")# Define tokenizer functiondef tokenize_function(examples):
return tokenizer(examples["text"], padding="True", truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
现在,我们需要设置超参数配置,使用TrainingArguments对象微调我们的模型。此配置提供了109个可选参数,让您对训练过程进行细致控制。如果您愿意,可以依赖默认设置,而不传递任何特定参数。
from transformers import TrainingArguments
training_args = TrainingArguments()
最后,在定义了模型的所有元素后,我们只需将它们放入训练对象中,并调用相关的训练函数,如下所示:
将模型放入训练对象中并调用训练函数以微调我们的Llama 3基础模型。
from transformers import Trainer
trainer = Trainer(
model=model,
dataset=dataset,
args=training_args,
)
trainer.train()
就这样!仅用几行代码,您就可以下载并训练一个可以用于驱动LLM应用的语言模型。
对于有关如何使用HuggingFace简化LLM应用开发的更具体和深入的示例,请参阅我们关于使用Zilliz Cloud构建QA应用的教程。
持续监控和评估
一旦您将LLM应用部署到生产环境中,监控应用的性能至关重要,原因如下:
- 确定模型在生产中的表现,它们是否满足预期的用例?是否与用户的期望一致?
- 您如何改进模型?
- 随后,当您对模型进行改进时,这些改进是否导致预期的性能提升,或者是否需要进一步的更改?
- 您的模型消耗的计算资源:您是否需要分配更多资源,例如GPU,以使您的应用程序表现更好?此外,考虑到它消耗的资源,您的应用程序的可扩展性如何?
- 在更改后,它的表现如何,例如,额外的训练、微调?
评估指标帮助您衡量模型在响应用户提示时生成正确输出的能力。最常用的指标包括BLEU、ROUGE和BERTScore,下面将对此进行描述。
 屏幕截图 2024-11-29 103002.png
屏幕截图 2024-11-29 103002.png
此外,还有其他定性方法来评估您的LLM应用的性能。
- 评估输出的准确性和相关性:响应可能编写得很好,但它与输入提示的相关性如何?它是否提供了用户所期望的价值?
- 确定用户如何使用您的LLM应用,以及您是否必须相应地进行微调。
- 评估响应的情感:应用程序是否以所需的语气作出响应?
- 是否有任何越狱尝试,即试图让模型生成不应产生的输出?例如,询问聊天机器人如何制作自制武器。这种方法确定您是否应该在应用程序中包含保护措施,或改进您可能已经实施的保护措施。
持续监控您的LLM应用并不复杂。市场上有许多工具可用于评估您的LLM驱动应用,包括Sage在他的演讲中提到的LangKit、Ragas、Continuous Eval、TruLens-Eval、LlamaIndex、Phoenix、DeepEval、LangSmith和OpenAI Evals。
要了解有关评估LLM应用的更多信息,请查看我们关于RAG评估的文章。
改进您的模型
利用监控模型的指标和反馈,您可以在更短的时间内对LLM进行新的迭代。实施改进的一种强大而高效的方法是将MLOps协调器(如Flyte)集成到您的管道中。MLOps协调器简化了LLM应用程序管理的方式如下:
- 自动化测试:在进行更改时自动运行测试。
- 软件构建:编译代码并准备部署。
- 部署:将应用程序的最新版本移入生产环境。
- 监控和报告:跟踪构建、测试和部署的状态,并提供反馈。
协调器通过工作流管理您的应用程序,工作流是一系列执行特定任务或目标所需的步骤。工作流中的每个步骤都可以单独执行、测试和验证,而协调器处理每个任务执行的顺序。工作流的示例包括训练或微调LLM、将应用程序部署到环境中,或将新功能集成到生产中运行的应用程序中。
工作流简化了LLM应用的开发和维护。首先,工作流是可重复的,因此可以在不同的管道之间复制现有工作流,从而节省大量时间和精力。类似地,工作流可以版本化,确保您可以将管道恢复到某个时间的状态。
实际上,MLOps协调器最适合由多个人员或团队开发的企业级LLM应用,对于较小的应用程序来说可能过于复杂。相反,将模型部署到生产中,监控其使用情况,并根据您获得的见解手动更新应用程序是一种更实用的方法。
总结
因此,回顾Sage Elliott关于LLMOps的演讲:
- LLMOps指的是一系列促进高效开发、部署、维护和改进LLM应用的理念和技术。
- LLMOps也可以定义为“共同构建AI”,这意味着,像DevOps(它的来源)一样,组织内的不同团队协作构建LLM应用,而不是在孤岛中运作,目标各异。
- 尽管看起来令人不知所措,但您可以通过三步流程开始使用LLMOps:
- 发货:尽快将模型部署到生产中,以获取真实用户反馈。
- 监控:使用指标评估其性能。
- 改进:利用监控获得的见解来改进您的应用。
- HuggingFace是一个极好的资源,可以快速将原型部署到生产中。Transformer库允许您轻松下载和微调模型,Datasets库提供训练所需的数据,而Spaces提供了一个托管平台,可以快速将其部署到生产中。
- Flyte是一个MLOps协调器的示例,它简化了LLM应用程序的管理。
注:本文为AI翻译,查看原文
 Tim Mugabi
Tim MugabiFreelance Technical Writer
keepReading

LLMs 记忆体全新升级:六大新功能全面出击,用户体验值拉满!
本次,我们新增了价格计算器、取消存储配额限制、自动暂停不活跃数据库等功能,用户体验感再上新台阶。通过阅读本文,用户可以快速、详尽地了解 Zilliz Cloud 的六大新功能!

Zilliz Cloud 明星级功能详解|解锁多组织与角色管理功能,让你的权限管理更简单!
Zilliz Cloud 云服务是一套高效、高度可扩展的向量检索解决方案。近期,我们发布了 Zilliz Cloud 新版本,在 Zilliz Cloud 向量数据库中增添了许多新功能。其中,用户呼声最高的新功能便是组织与角色的功能,它可以极大简化团队及权限管理流程。

重磅版本发布|三大关键特性带你认识 Milvus 2.2.9 :JSON、PartitionKey、Dynamic Schema
随着 LLM 的持续火爆,众多应用开发者将目光投向了向量数据库领域,而作为开源向量数据库的领先者,Milvus 也充分吸收了大量来自社区、用户、AI 从业者的建议,把重心投入到了开发者使用体验上,以简化开发者的使用门槛。