



从传统关键词匹配到向量搜索和生成型人工智能的搜索演变
在当今数字化时代,随着信息的丰富,搜索引擎已成为不可或缺的工具。从帮助我们找到最新新闻到定位特定研究论文,这些引擎引导我们穿越大量数据,找到我们所需的确切信息。然而,搜索引擎检索和呈现信息的方式已经发生了显著变化,从早期的简单关键词匹配到今天看到的向量搜索和生成型人工智能(GenAI)等先进算法和技术的兴起。
本文将探讨搜索的演变、传统系统的局限性,以及现代技术如向量搜索和人工智能如何为准确性和相关性树立新标准。
传统搜索引擎概述
搜索引擎是从互联网的广阔世界中提取与用户查询相关的信息的软件系统。基于在网络浏览器中输入的搜索查询,它们索引数百万网页、文档和资源,并提供包含超链接列表以及图像和文本摘要的结果。
最早的搜索引擎创新始于1990年左右,当时是简单的索引工具。1990年在麦吉尔大学创建的Archie基于文件传输协议(FTP)索引文件并帮助用户定位文件。后来,1993年出现了类似的索引工具Veronica,它索引Gopher文件。Gopher文件属于Gopher协议,该协议通过在线分层目录系统提供信息访问。
基于网络的搜索引擎的出现始于1994年的WebCrawler,这是第一个索引网页全文的工具。后来,它被Lycos、AltaVista和Yahoo等搜索引擎所跟随。这些早期搜索引擎为现代巨头如谷歌和必应奠定了基础。谷歌于1998年正式发布,因其PageRank算法而迅速流行。它使用关键词匹配,根据指向网页的超链接的相关性和数量对搜索结果进行排名,生成准确的结果。后来,在2009年,微软发布了必应,由于其基于图像的搜索功能和与其他微软产品的集成而受到关注。
搜索引擎的基本功能
搜索引擎通过以下三个主要过程工作:爬行、索引和检索。
- 爬行:第一步是通过称为爬虫或蜘蛛的机器人尽可能多地探索互联网。这些机器人通过从一个页面到另一个页面不断跟随链接来发现网络内容。
- 索引:第二步是分析发现的内容。内容首先存储在庞大的数据库中,并使用关键词、元数据和其他相关信息进行索引。
- 检索:最后一步是检索分析过的内容。当用户输入查询时,搜索引擎会按照相关性顺序从数据库中呈现检索到的内容。
搜索引擎中使用的算法在确定搜索结果中起着至关重要的作用。它们评估用户查询并使用众多因素(如关键词密度、点击率、网站权威性等)输出相关结果。例如,谷歌的PageRank算法根据指向它的链接的质量和数量对网页进行排名。算法还根据用户位置、搜索历史和其他偏好个性化结果。
传统搜索系统的局限性
尽管传统搜索系统在许多方面都很强大,但它们也存在几个局限性。
- 难以理解上下文和语义含义。传统搜索系统常常无法充分理解用户查询的意图。它们在基于关键词匹配的方法上挣扎,无法理解单词背后的深层含义,导致结果不够准确。
- 处理自然语言查询的挑战。用户输入的查询由自然语言组成,类似于日常对话,但搜索引擎只能理解关键词而非整个复杂的句子或问题。
- 同义词和多义词的问题
- 同义词 - 使用具有相似含义的不同单词可能导致如果系统只搜索精确匹配,则会错过结果。
- 多义词 - 一个单词具有多个含义可能会导致如果系统无法辨别正确上下文,则会产生不相关的结果。
这些局限性突出了需要更先进的搜索技术来更好地理解和处理自然语言,为现代搜索引擎的发展铺平了道路。
向量相似性搜索的兴起
随着信息的体量和复杂性的不断增长,对更复杂的搜索方法的需求变得明显。向量搜索或向量相似性搜索是现代搜索引擎中使用的最新搜索技术,可以理解数据的语义含义。这种方法允许更准确和上下文相关的信息检索。
向量搜索的主要思想是将文本、图像、音频和视频等非结构化数据在高维空间中以数值表示形式(向量嵌入)表示,然后找到这些向量之间的相似性。这些向量越接近,它们就越相似。这种表示使用户可以利用机器学习算法进行有效处理。与传统依赖关键词匹配方法的搜索系统不同,向量搜索可以理解用户查询的上下文和语义,并生成更相关的结果。
向量搜索的工作原理
- 编码:第一步是使用现有的预训练词嵌入模型(如Word2Vec和GloVe)或高级变换器模型(如BERT或RoBERTa)将数据编码成嵌入。这些模型甚至可以针对您的数据集进行微调。
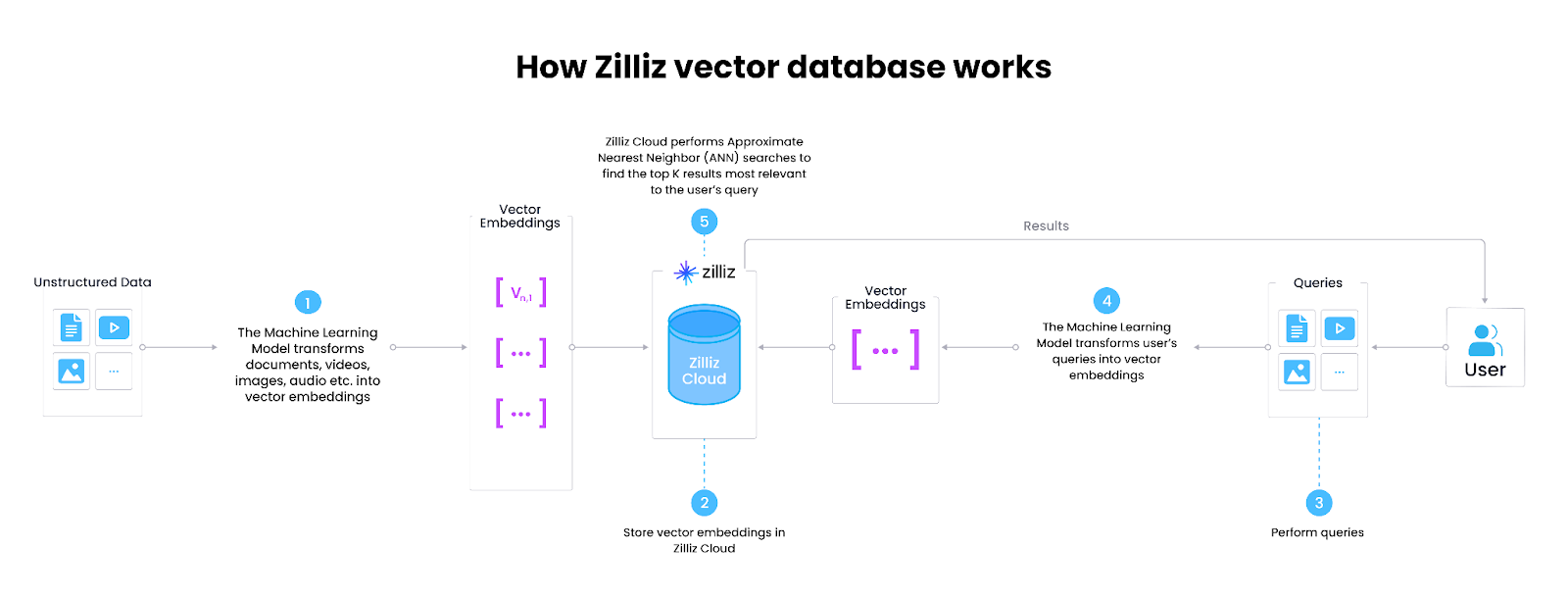
- 索引:下一步是将嵌入存储在向量数据库中,如Milvus或Zilliz Cloud(完全托管的Milkus),这些数据库专门用于存储、索引和查询这些嵌入。索引算法然后高效组织这些向量,以便在搜索过程中快速检索和比较它们。可以将其视为图书馆中书籍的分类存储,便于我们选取。
- 查询:最后,当输入搜索查询时,它也被编码成向量,使用嵌入模型。向量搜索系统(通常是向量数据库)然后将这个查询向量与索引向量进行比较,以找到最相似的向量。
 Figure_1_How_vector_databases_work_344fe30f58.png
Figure_1_How_vector_databases_work_344fe30f58.png
图1:向量数据库的工作原理
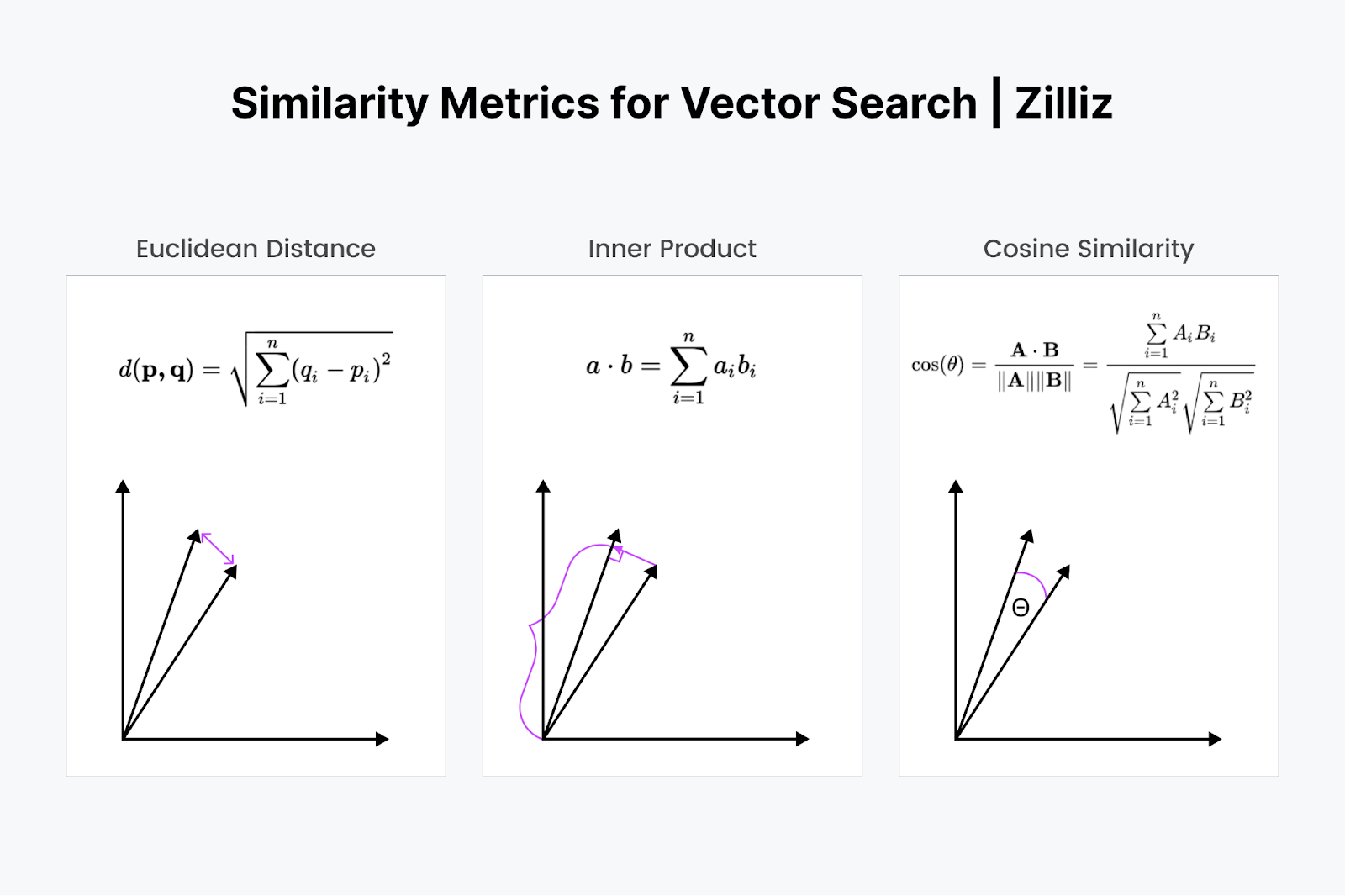
在向量搜索中,结果的相关性是通过测量查询和文档向量之间的相似性来确定的。一些流行的相似性度量方法包括:
 Figure_2_Similarity_Metrics_for_Vector_Search_aa2cab5bef.png
Figure_2_Similarity_Metrics_for_Vector_Search_aa2cab5bef.png
图2:向量搜索的相似性度量
- 欧几里得距离(L2) - 它通过计算坐标之间的平方差之和的平方根,找到两个向量之间的直线距离。它对向量的大小更敏感。因此,它在某些应用中很有用,其中大小很重要。
- 余弦相似度 - 它测量两个向量之间角度的余弦值。这个度量通常被使用,因为它关注的是方向(向量对齐的紧密程度)而不是向量的大小,使其成为比较文本嵌入的理想选择。
- 内积:内积是将一个向量投影到另一个向量上。内积的值是向量的长度。两个向量之间的角度越大,内积越小。它还随着较小向量的长度缩放。因此,当我们关心方向和距离时,我们会使用内积。例如,你必须穿过墙壁直接走到冰箱。
向量搜索的关键好处
- 语义和上下文理解 - 向量搜索能够理解实体之间复杂的关系和相似性,提供更有意义的检索。因此,它改善了自然语言查询的处理。
- 可扩展性 - 向量搜索的快速计算速度使其具有高度可扩展性。它可以轻松从大规模数据集中提取查询。
- 个性化 - 向量搜索允许服务个性化。基于用户偏好和项目属性,零售商或流媒体服务可以轻松呈现类似项目,并吸引用户群体,以获得更好的体验。
向量搜索的应用
- 语义搜索 - 向量搜索通过理解查询的语义含义,提高搜索引擎结果的准确性和相关性。这使用户能够找到与他们意图匹配的内容,即使确切的关键词不出现。
- 推荐系统 - 向量搜索通过找到与用户互动过的项目相似的项目,为推荐引擎提供动力。它有助于推荐与用户偏好一致的产品、电影、音乐或内容,增强个性化和用户满意度。
- 图像、视频和多模态搜索 - 向量搜索检索与查询视觉相似的图像或视频。它比较编码为向量的视觉特征,允许根据外观或内容相似性高效搜索和检索多媒体内容。
- 检索增强型生成(RAG):随着像ChatGPT这样的大型语言模型的兴起,向量搜索被用来减轻LLM幻觉,为它们提供额外的上下文信息。我们将在以下部分详细讨论这种技术。
有关向量搜索的更多用例,请参阅我们的用例页面或阅读这篇涵盖2024年向量搜索顶级用例的博客。
使用Milkus实现向量搜索
Milkus是一个适用于各种规模AI应用的开源向量数据库。它能够处理数十亿规模的向量,并具有毫秒级延迟。Milkus提供各种部署选项,可以随着您的项目扩展,从在Jupyter Notebook中运行演示聊天机器人到构建企业级AI搜索。
在本节中,我们将以Milkus为例,展示如何高效实现向量搜索。
安装Milkus
我们将使用Milkus Lite,这是一个可以嵌入到客户端应用程序中的PyMilkus中的Python库。
在继续之前,请确保本地环境中有Python 3.8+。让我们安装pymilvus,其中包含Python客户端库和Milkus Lite。
pip install -U pymilvus
设置向量数据库
要创建本地Milkus向量数据库,只需实例化一个MilkusClient,并指定一个文件名来存储所有数据,例如“milvus_demo.db”。
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
创建集合
Milkus需要创建一个集合来存储向量及其相关的元数据。创建集合时,您可以定义模式和各种索引参数来配置向量规范,如维度、索引类型和距离度量。现在,我们将使用默认设置.
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768, # vector dimensions will be 768
)
准备数据
- 安装模型库
- 我们需要使用嵌入模型为文本生成向量。PyMilkus是Milkus的Python SDK,它无缝集成了各种流行的嵌入模型。您可以轻松使用pymilvus[model]库中的这些函数。
- 让我们安装包含PyTorch等基本ML工具的模型库。
pip install "pymilvus[model]"
- 生成向量嵌入
- Milkus期望数据以字典列表的形式组织,每个字典代表一个数据记录。因此,让我们首先组织数据,然后使用默认模型生成嵌入。
from pymilvus import model
# This will download a small embedding model "paraphrase-albert-small-v2" (~50MB)
embedding_fn = model.DefaultEmbeddingFunction()
# Text strings to search from
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
vectors = embedding_fn.encode_documents(docs)
# The output vector has 768 dimensions, matching the collection that we just created.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# Each entity has id, vector representation, raw text, and a subject label that we use
# to demo metadata filtering later.
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
print("Data has", len(data), "entities, each with fields: ", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))
输出:
Dim: 768 (768,)
Data has 3 entities, each with fields: dict_keys(['id', 'vector', 'text', 'subject'])
Vector dim: 768
- 插入数据
- 让我们将数据插入集合中。
res = client.insert(collection_name="demo_collection", data=data)
print(res)
输出:
{'insert_count': 3, 'ids': [0, 1, 2], 'cost': 0}
- 语义搜索
- 现在,让我们通过将搜索查询文本表示为向量,并在Milkus上进行相似性搜索,执行语义搜索。
- Milkus一次可以接受一个或多个向量搜索请求。
query_vectors变量包含一个向量列表,每个向量都是一个浮点数数组。
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"])
res = client.search(
collection_name="demo_collection", # target collection
data=query_vectors, # query vectors
limit=2, # number of returned entities
output_fields=["text", "subject"], # specifies fields to be returned
)
print(res)
输出:
data: ["[{'id': 2, 'distance': 0.5859944820404053, 'entity': {'text': 'Born in Maida Vale, London, Turing was raised in southern England.', 'subject': 'history'}}, {'id': 1, 'distance': 0.5118255615234375, 'entity': {'text': 'Alan Turing was the first person to conduct substantial research in AI.', 'subject': 'history'}}]"] , extra_info: {'cost': 0}
输出是一个结果列表,每个结果对应一个向量搜索查询。每个查询包含一个结果列表,每个结果包含实体主键、与查询向量的距离以及具有指定output_fields的实体详细信息。
- 带元数据过滤的向量搜索
- Milkus提供了元数据过滤功能。您还可以在指定某些元数据值的标准时进行向量搜索。例如,让我们在以下示例中使用“
subject”字段进行过滤。
- Milkus提供了元数据过滤功能。您还可以在指定某些元数据值的标准时进行向量搜索。例如,让我们在以下示例中使用“
# Insert more docs in another subject.
docs = [
"Machine learning has been used for drug design.",
"Computational synthesis with AI algorithms predicts molecular properties.",
"DDR1 is involved in cancers and fibrosis.",
]
vectors = embedding_fn.encode_documents(docs)
data = [
{"id": 3 + i, "vector": vectors[i], "text": docs[i], "subject": "biology"}
for i in range(len(vectors))
]
client.insert(collection_name="demo_collection", data=data)
# This will exclude any text in "history" subject despite close to the query vector.
res = client.search(
collection_name="demo_collection",
data=embedding_fn.encode_queries(["tell me AI related information"]),
filter="subject == 'biology'",
limit=2,
output_fields=["text", "subject"],
)
print(res)
输出:
data: ["[{'id': 4, 'distance': 0.27030569314956665, 'entity': {'text': 'Computational synthesis with AI algorithms predicts molecular properties.', 'subject': 'biology'}}, {'id': 3, 'distance': 0.16425910592079163, 'entity': {'text': 'Machine learning has been used for drug design.', 'subject': 'biology'}}]"] , extra_info: {'cost': 0}
除了向量搜索,您还可以执行其他类型的搜索。请访问官方文档,了解如何使用Milkus实现向量搜索,以获取更多详细信息。
生成型人工智能和检索增强型生成(RAG)在现代搜索中的角色
随着搜索技术的发展,生成型人工智能和检索增强型生成(RAG)已成为显著增强搜索魔力的变革性工具。
生成型人工智能,以像ChatGPT这样的大型语言模型为代表,通过增强搜索引擎理解、处理和用自然语言生成答案的能力,重新定义了搜索引擎。与传统AI方法不同,生成型人工智能可以基于它们从预训练知识中学到的内容,创建连贯的、类似人类的文本响应,使搜索引擎能够提供更直观和上下文准确的结果。这一进步使与搜索引擎的交互更加无缝,使用户能够接收与他们的查询和意图紧密匹配的答案。
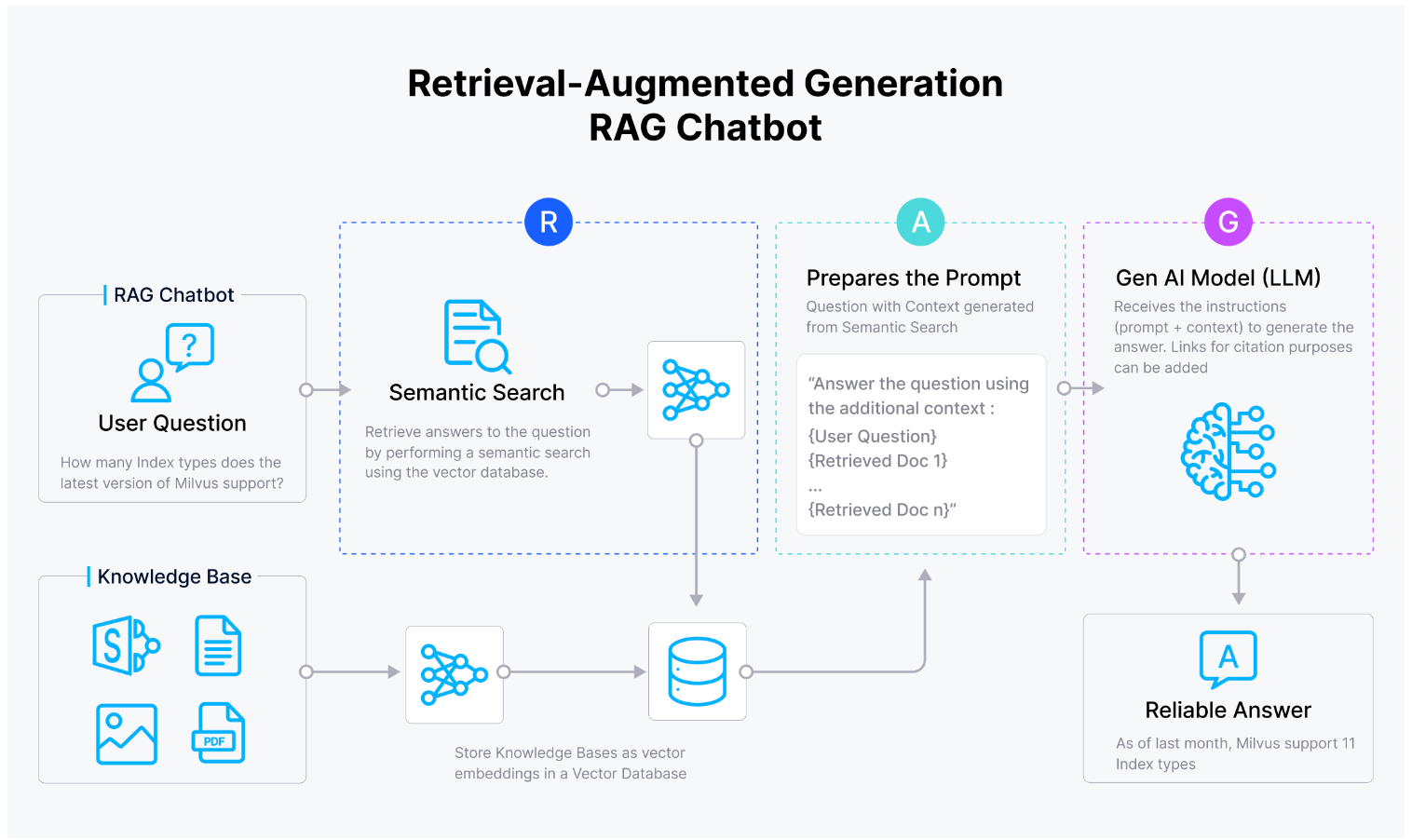
RAG是一种改进的检索技术,它结合了基于向量搜索的检索方法和生成型模型的优势,以减轻臭名昭著的LLM幻觉。在RAG中,检索系统首先使用向量搜索从向量数据库(如Milkus)中识别与用户查询最相关的文档或信息片段,然后由像ChatGPT这样的生成型模型用来创建全面且上下文准确的响应。这种方法在聊天机器人、客户支持和内容创作等应用中特别有效,这些应用中理解上下文和提供详细答案至关重要。
 Figure_Vector_database_facilitating_RAG_chatbot_1a87eb1206.png
Figure_Vector_database_facilitating_RAG_chatbot_1a87eb1206.png
图3:RAG的工作原理
搜索的未来:AI、向量搜索和关键词搜索的结合
搜索的未来将由关键词搜索、向量搜索和生成性AI的战略整合塑造,每种技术都解决特定需求。AI将通过分析用户行为模式来增强搜索,使搜索引擎能够更深入地理解复杂查询。向量搜索将在检索语义相似内容方面表现出色,使其成为多媒体和基于上下文的搜索的理想选择。关键词搜索将仍然是需要精确匹配和精确结果的任务所必需的。这些技术共同提供全面搜索体验,准确且适应我们寻求信息的多样化方式。
结论
从简单的基于关键词的系统到向量搜索,再到由GenAI驱动的现代搜索技术的演变,反映了数字时代的日益增长的复杂性和需求。随着我们继续生成和消费大量信息,这些技术将在确保我们能够快速、高效地访问最相关和准确的数据方面发挥关键作用。理解和利用这些现代搜索技术将是保持在不断演变的信息检索领域领先地位的关键。
 Yesha Shastri
Yesha ShastriFreelance Technical Writer in AI/ML

