



使用 KnowHow 通过知识图谱增强您的 RAG
检索增强生成(RAG)是一种流行技术,它通过像 Milvus 和 Zilliz Cloud(完全托管的 Milvus)这样的向量数据库为大型语言模型(LLM)提供额外的知识和长期记忆。基本的 RAG 可以解决许多 LLM 的问题,但如果有更高级的需求,如定制或对检索结果的更大控制,它是不够的。
在我们最近的非结构化数据聚会上,WhyHow 的联合创始人 Chris Rec 分享了他如何将知识图谱(KG)整合到 RAG 流程中以获得更好的性能和准确性。本博客将涵盖他演讲的关键点,包括知识图谱、RAG 的概述,以及如何将知识图谱整合到 RAG 系统中以获得更好的性能。
RAG 及其挑战的概述
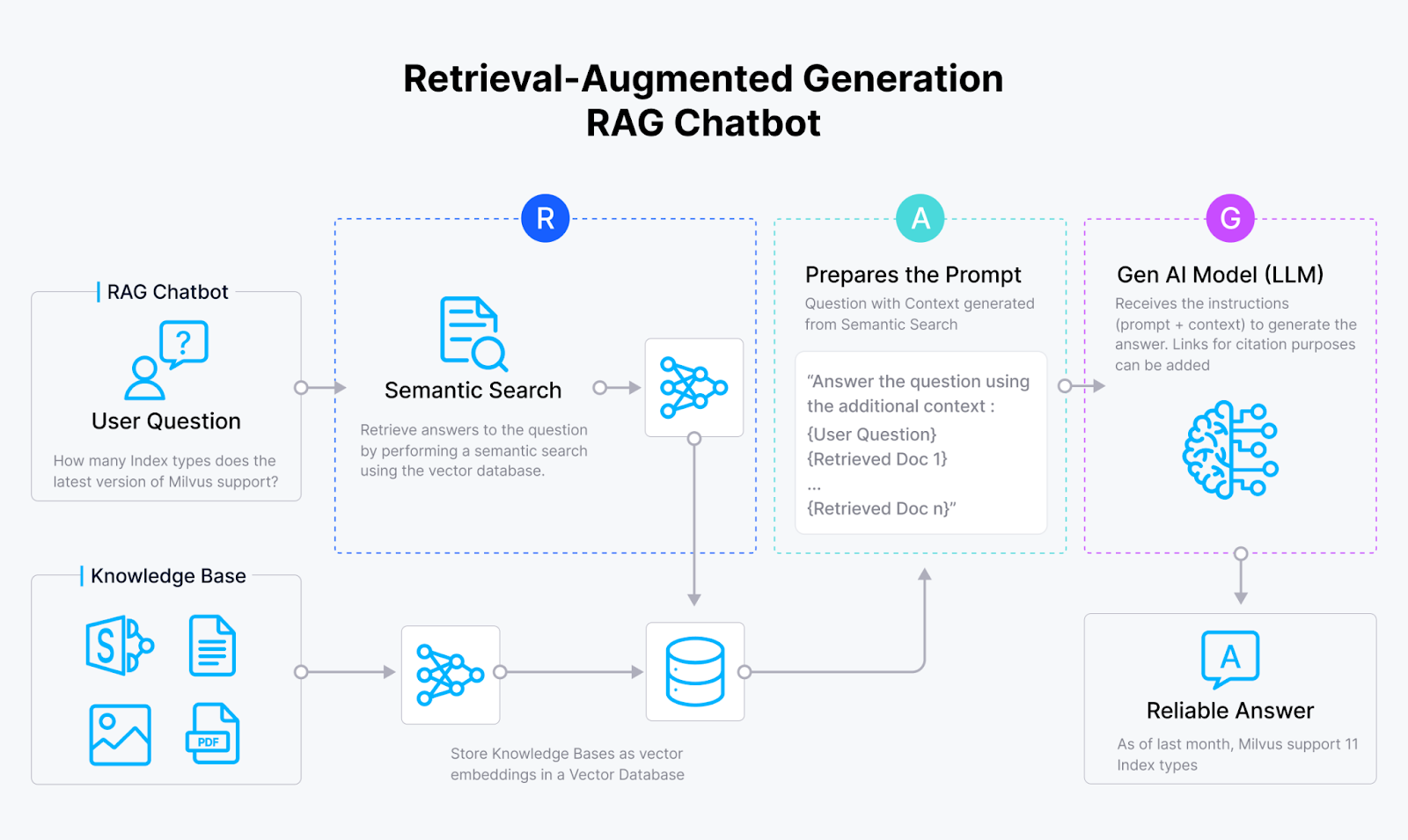
RAG 是一种利用基于检索和生成的人工智能系统的优势的方法。标准的 RAG 通常包括一个向量数据库如 Milvus、一个嵌入模型和一个大型语言模型(LLM)。
RAG 系统首先使用嵌入模型将文档转换为向量嵌入并存储在向量数据库中。然后,它从这个向量数据库中检索相关的查询信息,并将检索到的结果提供给 LLM。最后,LLM 使用检索到的信息作为上下文来生成更准确的输出。
 RAG_chatbot_2f1ff9ec07.png
RAG_chatbot_2f1ff9ec07.png
图 1:RAG 的工作原理
尽管标准的 RAG 在生成更准确和最新的结果方面非常出色,但它仍然有几个局限性。
首先,LLM 可能难以完全理解问题的具体上下文或领域,导致错误或不相关的回答。例如,“vehicular capacity” 一词可能指的是汽车可以容纳的乘客数量,也可能是道路上可以容纳的汽车数量,这造成了歧义。
其次,准确处理各种查询类型是具有挑战性的。例如,回应基于位置的查询,如“我想去伦敦”,与解决更抽象的健康相关问题,如“我工作压力大,想度假”有很大不同。
第三,区分相似性和相关性并不容易。例如,区分一英里外的“海滩别墅”和直接建在沙滩上的“海滨别墅”可能很困难。
第四,答案的完整性也是一个问题。对于复杂的问题,检索所有相关信息可能是具有挑战性的,特别是对于复杂的问题,例如列出所有至少投资了 1000 万美元并且拥有特殊数据访问权限的基金中的有限合伙人(LP)。
最后,多跳查询增加了另一层复杂性,因为它们需要准确组合多个信息片段。这种方法需要将查询分解为几个子查询,每个子查询都有特定的条件,确保最终响应准确且完整。
虽然诸如提示改进、高级分块策略、更好的嵌入模型和重新排名等解决方案可以解决与 RAG 相关的许多挑战,但 WhyHow 通过将知识图谱整合到 RAG 流程中采取了不同的方法。
知识图谱(KG)是什么?
知识图谱(KG)是一种不仅存储数据,还根据它们的关系链接相似或不相似数据的数据结构。这种方法导致一系列事物(可以是任何类型的数据)以一种可以提供相关或相关信息的方式链接。
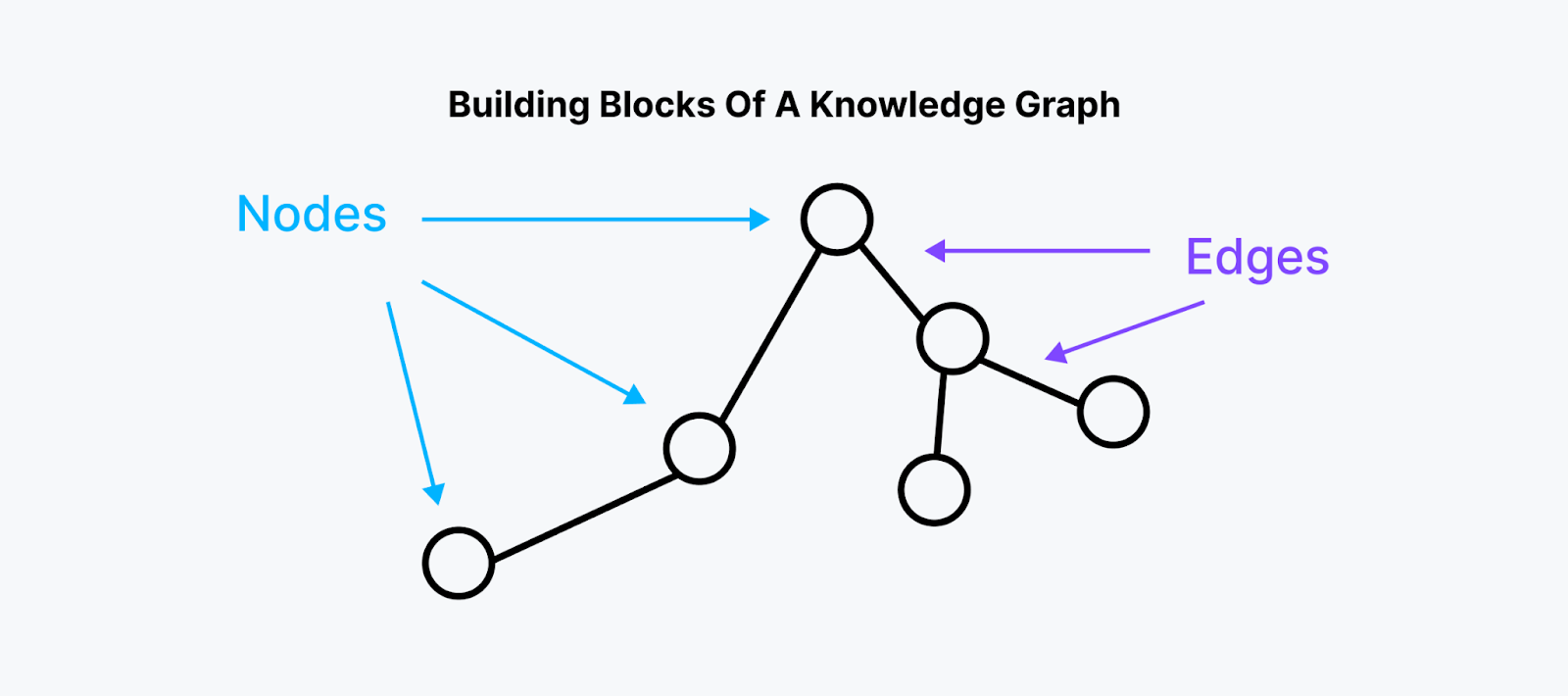
知识图谱由节点、边和属性组成。
 Fig_2_Building_Blocks_of_a_Knowledge_Graph_3a3c13c822.png
Fig_2_Building_Blocks_of_a_Knowledge_Graph_3a3c13c822.png
图 2:知识图谱的构建块
节点:
- 表示图中的实体或对象。
- 存储这些实体的值可以是任何类型的数据。
边:
- 表示实体之间的关系。
- 包含有关连接节点之间关系的信息。
属性:与单个实体相关联的特征或特征。
与传统的关系数据库不同,知识图谱使用图结构灵活表示关系,并专注于语义理解。这种方法使得复杂查询和更容易提取特定信息成为可能。
将知识图谱整合到 RAG 系统的优势
通过将知识图谱整合到 RAG 流程中,我们可以显著增强系统的检索能力和答案质量,从而实现更优越的性能、准确性、可追溯性和完整性。以下是基于知识图谱的 RAG 系统的主要优势:
增强的上下文理解
知识图谱提供了丰富、互联的信息表示,允许 RAG 系统理解实体之间的复杂关系。这种更深层次的上下文理解导致更细腻和相关的响应。
提高准确性和事实一致性
知识图谱的结构化特性有助于在生成内容中保持事实一致性。通过将响应锚定在图中的经过验证的信息上,系统可以减少传统语言模型中常见的错误和幻觉。
多跳推理能力
知识图谱使 RAG 系统能够执行多跳推理,通过逻辑路径连接不同的信息片段。这种能力允许更复杂的查询回答和推理生成。
高效的信息检索
图结构促进了快速和精确的信息检索,即使是复杂的查询也是如此。这种效率转化为更快的响应时间和更相关的内容生成。此外,基于知识图谱的 RAG 系统允许混合检索方法,结合图遍历与向量和关键词搜索,这些能力由像 Milvus 和 Zilliz Cloud 这样的向量数据库提供。
具体来说,这种混合方法可以实现:
- 通过图遍历实现精确的实体和关系匹配
- 使用向量嵌入进行语义相似性匹配
- 针对文本密集型内容进行传统的基于关键词的搜索
这种多方面的检索策略增强了系统在各种数据类型和结构中找到最相关信息的能力,从而产生更全面和准确的响应。
透明和可追溯的输出
有了知识图谱,系统可以为生成响应时使用的信息提供清晰的出处。这种可追溯性增强了用户信任,并允许更容易的事实检查和验证。
跨领域知识综合
通过在单个图结构中表示不同的领域,基于知识图谱的 RAG 系统可以更容易地综合不同领域的信息,从而获得更全面和跨学科的洞察力。
改善处理歧义的能力
知识图谱的关系结构有助于消除实体和概念的歧义,减少了术语或名称可能具有多种含义或引用时的混淆。
通过利用这些优势,增强了知识图谱的 RAG 应用程序可以为用户提供更准确、上下文相关和全面的回答。
WhyHow 是什么?它如何通过知识图谱增强 RAG?
WhyHow 是一个用于构建和管理知识图谱以支持复杂数据检索的平台。构建全面的知识图谱是具有挑战性和耗时的。WhyHow 通过多次迭代小型 KG 来解决这个问题,直到出现适用于特定领域的满意 KG。这种方法有助于使其高度特定于领域,更简单,易于使用,因为 KG 很复杂。
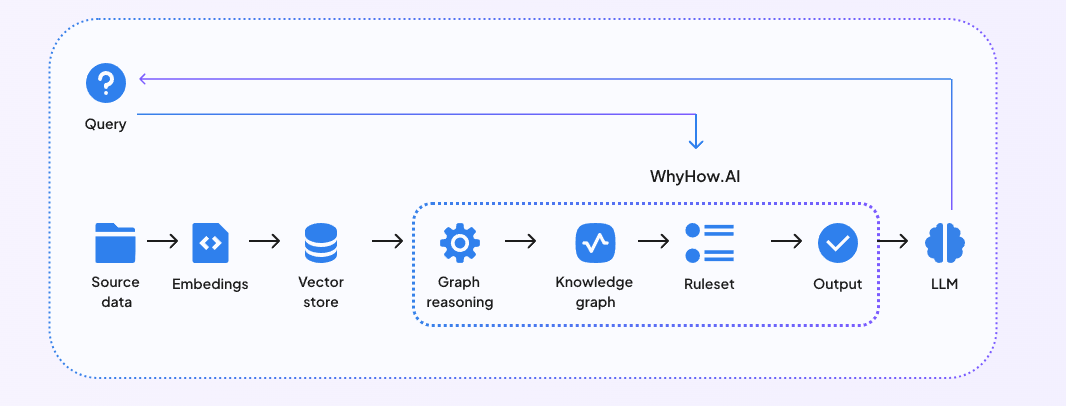
WhyHow 还为开发人员提供了构建块,以组织、上下文化和可靠地检索非结构化数据以执行复杂的 RAG。通过将 WhyHow 整合到您现有的由向量数据库驱动的 RAG 流程中,您可以使您的 RAG 系统具有更好的结构、一致性和控制。下图显示了增强型知识图谱的 RAG 如何工作。
 Fig_3_Integration_of_RAG_with_Why_How_b893400b28.png
Fig_3_Integration_of_RAG_with_Why_How_b893400b28.png
图 3:将 RAG 与 WhyHow 整合
通过将 WhyHow 整合到您的 RAG 工作流程中,您可以通过利用向量数据库提供的知识和图谱以及向量搜索能力,采取混合图和向量方法。
有关如何使用 WhyHow 构建增强型知识图谱的 RAG 的更详细指南,我们建议您观看 Chris 在由 Zilliz 主办的非结构化数据聚会上分享的现场演示。
在 RAG 中使用 WhyHow 和 Zilliz Cloud 对检索工作流程进行更多控制
除了使 RAG 应用程序更具性能和可追溯性外,许多开发人员还希望对他们的 RAG 检索内容有更多的控制。这是因为当用户发送措辞不当的查询,或者当用户需要在响应中包含上下文相关但语义不相似的数据时,RAG 应用程序有时无法始终如一地检索正确的数据块。
为了解决这些问题,WhyHow 通过与 Zilliz Cloud 集成构建了一个基于规则的检索包。这个 Python 包使开发人员能够使用高级过滤功能构建更准确的检索工作流程,使他们能够在 RAG 流程内的检索工作流程中拥有更多的控制权。这个包与 OpenAI 集成用于文本生成,与 Zilliz Cloud 集成用于存储和高效的向量相似性搜索与元数据过滤。
基于规则的检索解决方案执行以下任务:
- 向量存储创建:为存储块嵌入创建 Milvus 集合。
- 分割、分块和嵌入:使用 LangChain 的 PyPDFLoader 和 RecursiveCharacterTextSplitter 自动分割、分块和创建上传文档的嵌入,并支持 OpenAI 的 text-embedding-3-small 模型。
- 数据插入:将嵌入和元数据上传到 Milvus 或 Zilliz Cloud。
- 自动过滤:根据用户定义的规则构建元数据过滤器,以提炼针对向量存储的查询。
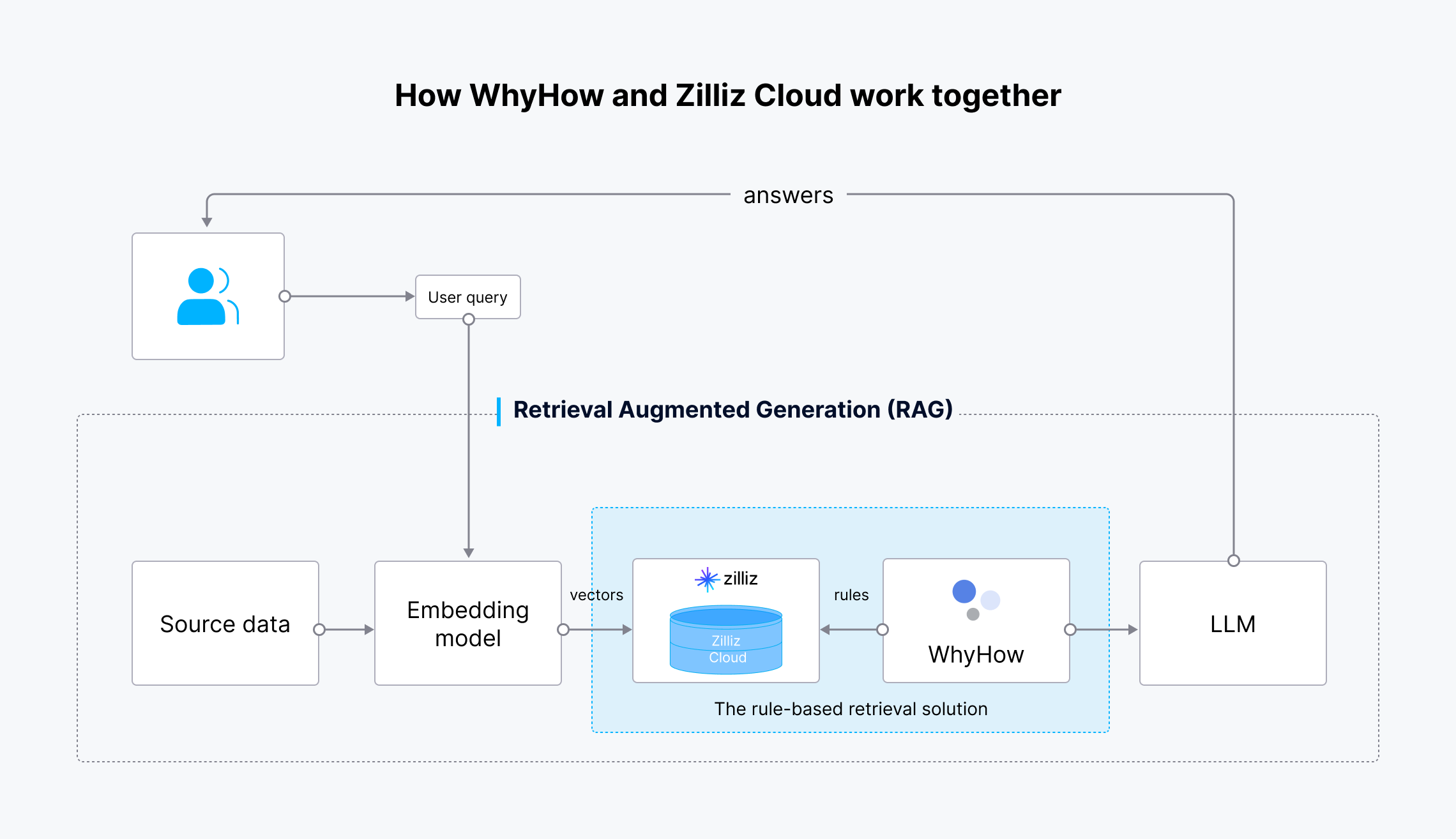
工作流程如下:
 How_Why_How_and_Zilliz_Cloud_work_together_8510ecf053.png
How_Why_How_and_Zilliz_Cloud_work_together_8510ecf053.png
图 4:基于规则的检索解决方案的工作流程
源数据使用 OpenAI 的嵌入模型转换为向量嵌入,并被摄取到 Zilliz Cloud 中进行存储和检索。当用户提出查询时,它也被转换为向量嵌入并发送到 Zilliz Cloud 以搜索最相关的结果。WhyHow 设置规则并对向量搜索添加过滤器。检索到的结果和原始用户查询随后被发送到 LLM,LLM 生成更准确的结果并将其发送给用户。
结论
LLM 确实减轻了我们寻找各种问题答案的负担。它们足够智能,能够理解提供的查询,但会产生幻觉,并且由于资源限制,很难使它们保持最新。因此,检索增强生成(RAG)技术通过为查询提供上下文来增强它们;然而,正如所讨论的,RAG 系统也有局限性。
WhyHow 识别了这些局限性,强调解决方案在于将知识图谱整合到 RAG 流程中。通过增强知识图谱的 RAG,您的 RAG 系统可以检索更相关和上下文的信息,并生成更可确定的答案,减少幻觉并提高准确性。
注:本文为AI翻译,查看原文
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer


