



一文详解动态 Schema
在数据库中,Schema 常有,而动态 Schema 不常有。
例如,SQL 数据库有预定义的 Schema,但这些 Schema 通常都不能修改,用户只有在创建时才能定义 Schema。Schema 的作用是告诉数据库使用者所希望的表结构,确保每行数据都符合该表的 Schema。NoSQL 数据库通常都支持动态 Schema 或可以不创建 Schema(即在创建数据库时无需为每个对象定义属性)。
而在 Milvus 社区中,支持动态 Schema 亦是呼声较高的功能之一。为了更好地满足用户需求,Milvus 在 2.2.9 中发布了这一功能,数据库 Schema 便可以根据用户添加数据而“动态变化”。此后,用户无需像以前一样在插入数据时严格遵循预先定义的 Schema,可以像在 NoSQL 数据库中一般,以 JSON 格式添加数据。
不过,我们发现很多用户对于在向量数据库中使用动态 Schema 的 A、B 面及其作用仍有不少疑问,本文将一一解答。
01.什么是数据库 Schema?
什么是数据库 Schema?我们举例来看:
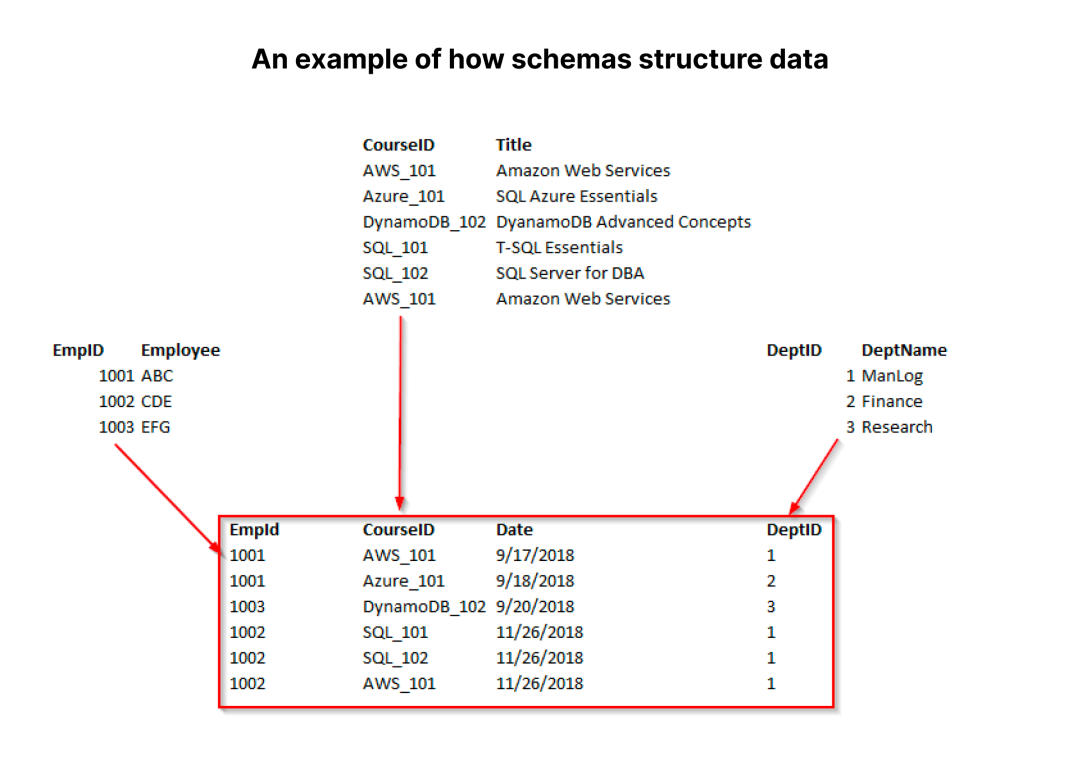
Schema 定义了如何在数据库中插入和存储数据,上图展示了如何为关系型数据库创建一个标准的 Schema。
在上图的数据库中, 一共有 4 张表,每张表都有各自的 Schema。图片中间的表有 4 列数据,其余 3 张表有 2 列数据。
此外,我们还需要在 Schema 中定义数据类型。“Employee”、“Title”和“DeptName”列都将是字符串(即VARCHAR),“CourseID”也是字符串,“EmpID”和“DeptID”列数据是整数,而“Date”列数据类型可以是日期或 VARCHAR。
02.什么是向量数据库 Schema?
以我们之前的文章《书接上回,如何用 LlamaIndex 搭建聊天机器人?》为例,下图展示了 1 个 Zilliz Cloud 实例中的 1 条数据:
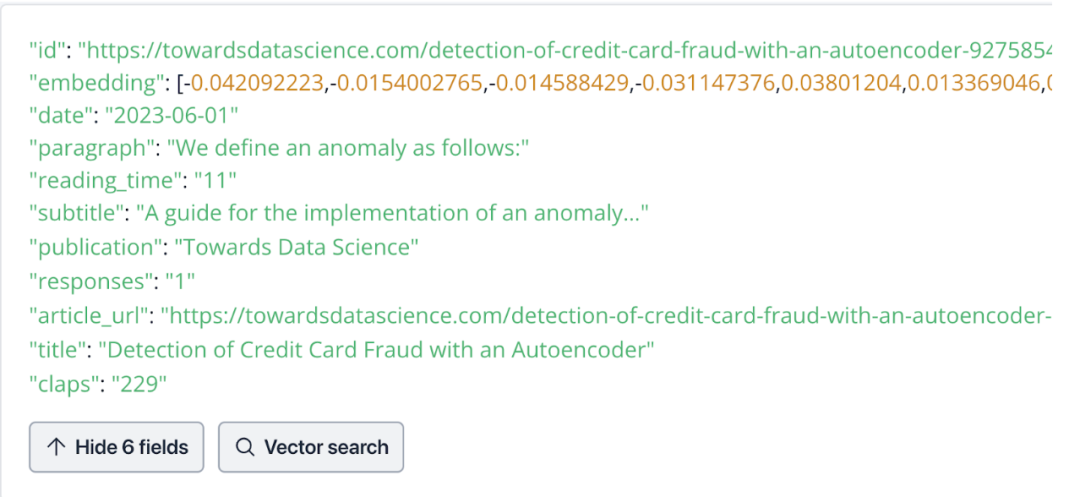
如果在传统的数据库中定义 Schema,那么针对这条数据,我们需要创建 11 列 Schema。
其中,“id”、“paragraph”、“subtitle”、“publication”、“article_url”和“title” 这 6 列数据类型为VARCHAR;“reading_time”、“responses”和“claps” 这 3 列数据类型为整数(INT);“date”列数据类型为日期(DATE);剩下的最后一列“embedding” 的数据类型为浮点向量(FLOAT_VECTOR),用于存储 Embedding 向量数据。
如何使用 Milvus 向量数据库中的 Dynamic Schema 功能?
下面的代码片段展示了如何在 Milvus 中开启动态 Schema 功能,以及如何将数据插入到动态字段并执行过滤搜索。
from pymilvus import (
connections,
FieldSchema, CollectionSchema, DataType,
Collection,
)
DIMENSION = 8
COLLECTION_NAME = "books"
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True),
FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='embeddings', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
Schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, Schema=Schema)
data_rows = [
{"id": 1, "title": "Lord of the Flies","embeddings": [0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],"isbn": "978-0399501487"},
{"id": 2, "title": "The Great Gatsby","embeddings": [0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],"author": "F. Scott Fitzgerald"},
{"id": 3, "title": "The Catcher in the Rye","embeddings": [0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],"claps": 100},
]
collection.insert(data_rows)
collection.create_index("embeddings", {"index_type": "FLAT", "metric_type": "L2"})
collection.load()
vector_to_search = [0.57, 0.94, 0.19, 0.38, 0.32, 0.28, 0.61, 0.07]
result = collection.search(
data=[vector_to_search],anns_field="embeddings",
param={},limit=3,expr="claps > 30 || title =='The Great Gatsby'",
output_fields=["title", "author", "claps", "isbn"],consistency_level="Strong")
for hits in result:for hit in hits:print(hit.to_dict())
在创建的 Collection “books”中,我们定义了 Schema,其中包含 3 个字段:id、title和embeddings。id是主键列——每行数据的唯一标识符,数据类型为INT64。title代表书名,数据类型为VARCHAR。embeddings是向量列,向量维度为 8。注意,本文代码中的向量数据为随机设置,仅用于演示目的。
Schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, Schema=Schema)
我们通过在定义时向CollectionSchema对象传入一个字段来开启动态Schema。简而言之,只需要添加enable_dynamic_field 并将其参数值设置为True 即可。
data_rows = [
{"id": 1, "title": "Lord of the Flies","embeddings": [0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],"isbn": "978-0399501487"},
{"id": 2, "title": "The Great Gatsby","embeddings": [0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],"author": "F. Scott Fitzgerald"},
{"id": 3, "title": "The Catcher in the Rye","embeddings": [0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],"claps": 100},
]
在上述代码中,我们插入了 3 行数据。id=1的数据包括动态字段isbn,id=2包括author,id=3包括claps。这些动态字段具有不同的数据类型,包括字符串类型(isbn和author)和整数类型(claps)。
result = collection.search(data=[vector_to_search],anns_field="embeddings",param={},limit=3,expr="claps > 30 || title =='The Great Gatsby'",output_fields=["title", "author", "claps", "isbn"],consistency_level="Strong")
在上述代码中,我们进行了过滤查询。过滤查询结合了ANNS(近似最近邻)搜索和基于动态和静态字段的标量过滤,查询的目的是检索满足expr参数中指定条件的数据,输出包括title、author、claps和isbn字段,expr参数允许基于 Schema 字段(或称之为静态字段)title和动态字段claps进行过滤。
运行代码后,输出结果如下:
{'id': 2, 'distance': 0.40939998626708984, 'entity': {'title': 'The Great Gatsby', 'author': 'F. Scott Fitzgerald'}}
{'id': 3, 'distance': 1.8463000059127808, 'entity': {'title': 'The Catcher in the Rye', 'claps': 100}}
Milvus 如何实现动态 Schema 功能?
Milvus 通过用隐藏的元数据列的方式,来支持用户为每行数据添加不同名称和数据类型的动态字段的功能。当用户创建表并开启动态字段时,Milvus 会在表的 Schema 里创建一个名为$meta的隐藏列。JSON 是一种不依赖语言的数据格式,被现代编程语言广泛支持,因此 Milvus 隐藏的动态实际列使用 JSON 作为数据类型。
Milvus 以列式结构组织数据,在插入数据过程中,每行数据中的动态字段数据被打包成 JSON 数据,所有行的 JSON 数据共同形成隐藏的动态列 $meta。
03.动态 Schema 的 A、B 面
当然,动态 Schema 的功能并不一定适合所有用户,大家可以根据自己的场景和需求选择开启或关闭动态 Schema。
一方面,动态 Schema 设置简便,无需复杂的配置即可开启动态 Schema;动态 Schema 可以随时适应数据模型的变化,开发者无需进行重构或调整代码。
另一方面,使用动态 Schema 进行过滤搜索比固定 Schema 慢得多;在动态 Schema 上进行批量插入比较复杂,推荐用户使用行式插入接口写入动态字段数据。
当然,为了应对上述挑战,Milvus 已经整合了向量化执行模型来提升过滤搜索效率。向量化执行的思想就是不再像火山模型一样调用一个算子一次处理一行数据,而是一次处理一批数据。这种计算模式在计算过程中也具有更好的数据局部性,从而显著提高了整体系统性能。
04.总结
看到这里,相信大家对于如何在 Milvus 中使用动态 Schema 有了更深的认识,需要提醒大家的是,动态Schema 功能拥有 A、B 两面,一方面提供了动态 Schema 设置简便,为用户提供灵活性和高效率。但另一方面,使用动态 Schema 的过滤搜索比固定 Schema 慢,而且在动态 Schema 上进行批量插入的情况更加复杂。Milvus 利用向量化执行模型来应对动态 Schema 的一些劣势,从而优化整体系统性能。
后续,我们还将在 Milvus 2.4 中增强标量索引能力,通过静态和动态字段的倒排索引加速过滤查询,实现动态 Schema 管理和查询的性能和效率提升。



