理解 DETR:使用变换器进行端到端目标检测
由 Facebook AI Research 于2020年推出,DETR(DEtection TRansformer)是使用变换器进行端到端目标检测的深度学习模型。由于其出色的性能,变换器已被广泛用于自然语言处理(NLP)任务中对序列数据进行建模,例如机器翻译和语言建模。变换器中的自注意力机制使它们能够专注于输入数据的某些部分,这些部分对特征学习更为重要。这种机制还允许 DETR 模型更有效地进行推理。同样,DETR 也利用了变换器架构的优势,用于计算机视觉中的目标检测。DETR 消除了首先生成区域提议,然后进行分类的多阶段管道的需求,而是将任务视为单阶段方法。
本博客将探讨 DETR 的概念、架构、优势和性能。我们还将介绍如何将 DETR 模型与像 Milvus 这样的向量数据库结合,用于高级数据检索应用,如图像检索系统和多模态搜索解决方案。
什么是目标检测?
在深入探讨 DETR 的概念之前,我们先来了解目标检测。
目标检测是一种计算机视觉技术,用于在图像或视频帧中识别和定位对象。想象一下,你有一个擅长发现事物的朋友。你给朋友看一张照片,他们指出并命名他们在照片中看到的一切,比如,“嘿,那是一只狗,那是一棵树,那边有一个人!”这个“聪明的朋友”就是目标检测技术使用计算机算法和模型所做的。
目标检测结合了两个主要任务:
- 目标分类:确定图像中存在哪些对象。
- 目标定位:确定每个对象在图像中的位置,通常通过在它们周围绘制边界框来实现。
通过检测和识别图像中的对象,目标检测有助于在各个领域理解视觉信息,如自动标记、汽车安全、零售、安全等。
什么是 DETR(DEtection TRansformer)?
DETR 是一种利用变换器预测图像中对象的边界框和类别标签的深度学习模型。变换器是由编码器-解码器架构组成的神经网络,具有自注意力机制。有了变换器,DETR 可以捕捉图像中对象之间的全局上下文和关系,从而实现更准确的检测。
传统的目标检测方法,如 YOLO(You Only Look Once)和 R-CNN(Region Convolutional Neural Network),会生成许多区域提议或锚框,并使用非最大抑制(Non-Maximum Suppression, NMS)进行过滤。这种方法使架构复杂,训练效率低下。
相比之下,DETR 将目标检测视为一个直接的集合预测问题。其目标是将图像中的所有对象视为一个集合,并在单次传递中预测它们的边界框和类别。这种新方法提高了检测精度,特别是在许多对象彼此靠近时。
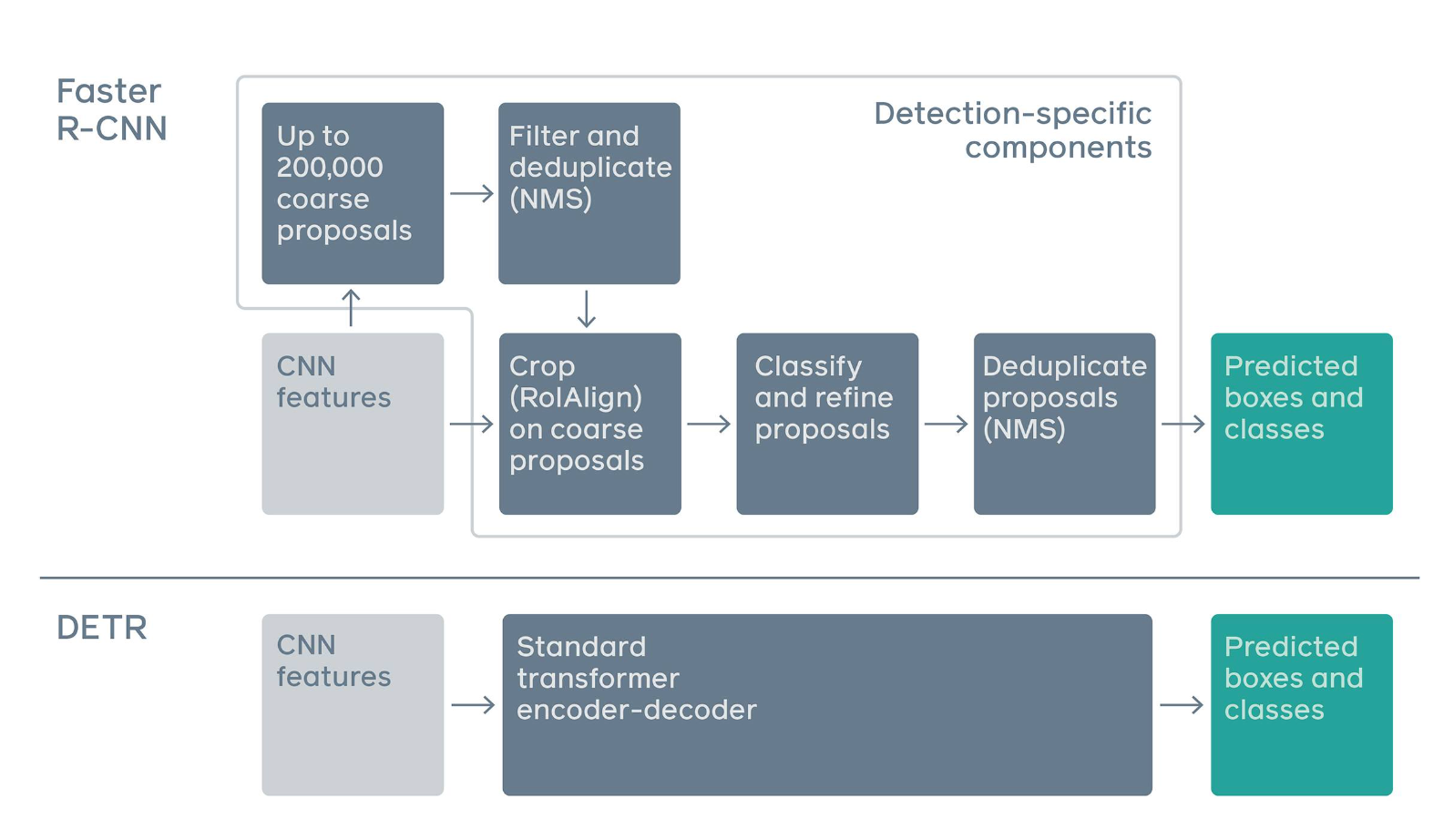 Figure_1_Difference_between_pipelines_of_Faster_R_CNN_Region_Convolutional_Neural_Network_and_DETR_Source_d90889cd4f.png
Figure_1_Difference_between_pipelines_of_Faster_R_CNN_Region_Convolutional_Neural_Network_and_DETR_Source_d90889cd4f.png
图1:Faster R-CNN(区域卷积神经网络)和 DETR 的流程差异
DETR 如何工作?
DETR 架构
DETR 架构的主要组成部分是卷积神经网络(CNN)骨干、变换器编码器和解码器以及预测头。DETR 架构如下图所示:
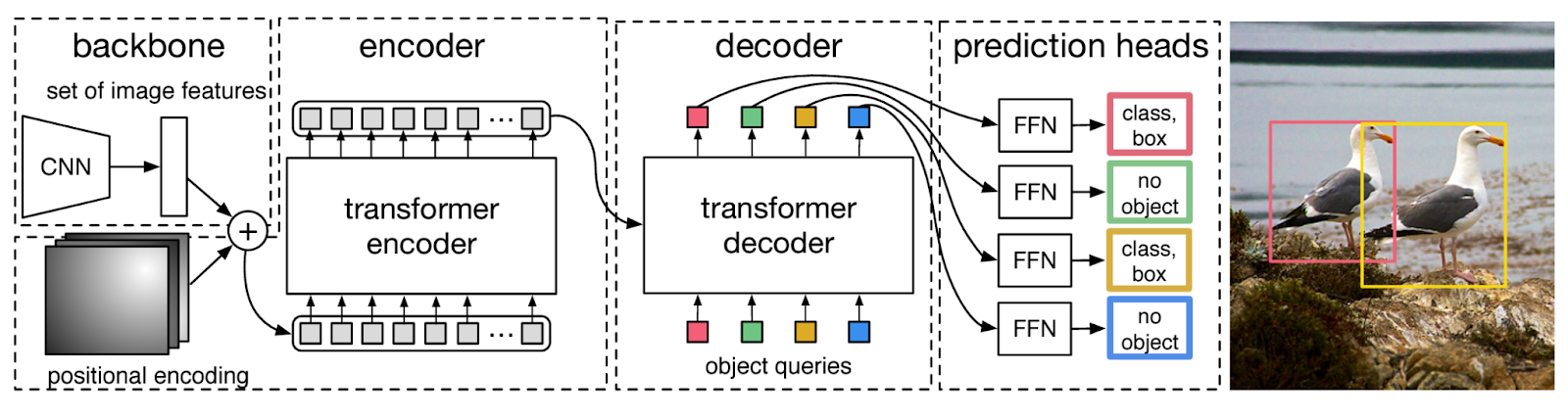 DETR_architecture_Source_a74e1aafa0.png
DETR_architecture_Source_a74e1aafa0.png
DETR 架构
- CNN 骨干:图像首先通过 CNN 骨干传递,输出图像的高级特征表示。一些流行的 CNN 骨干示例包括 Visual Geometry Group(VGG)和 ResNet。这些特征包含图像中对象的空间信息,然后作为输入传递给变换器编码器。
- 变换器编码器:变换器编码器将这些特征编码成一系列特征向量。由于编码器包含多头自注意力块,它允许通过图像不同部分之间的长期依赖关系捕获上下文信息。在这个阶段,管道的另一个关键元素是向 CNN 的输出添加位置编码。由于变换器本身没有空间理解,这些位置编码告知它们图像中对象的相对位置。
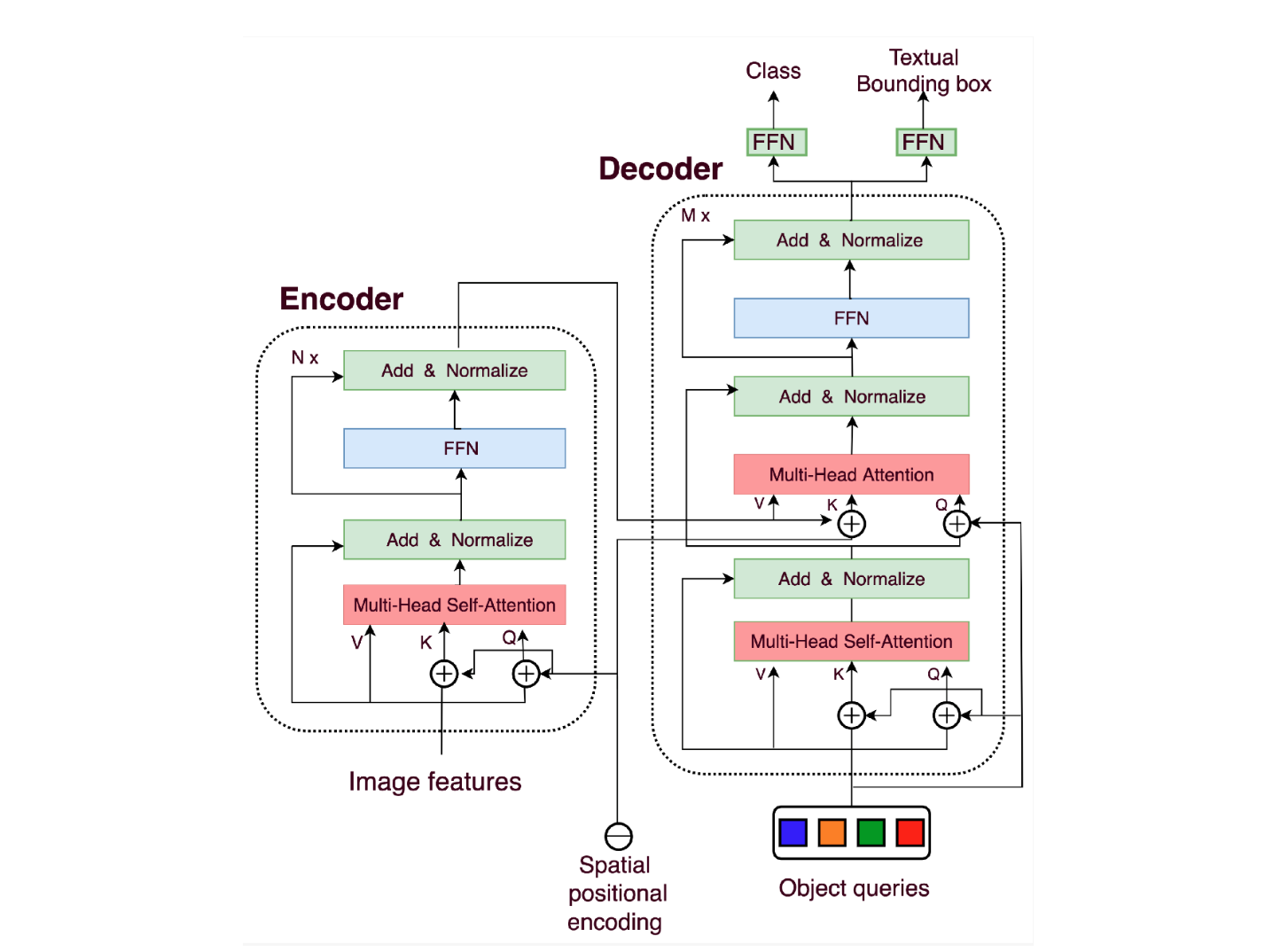 Transformer_architecture_used_in_DETR_Source_b1b3d7232d.png
Transformer_architecture_used_in_DETR_Source_b1b3d7232d.png
- 变换器解码器:变换器解码器学习 CNN 编码特征和可学习对象查询之间的关系。通常,我们需要查询、键和值来计算 NLP 中的自注意力。因此,在计算机视觉中,DETR 引入了对象查询的概念,这指的是模型需要预测的对象的可学习表示。对象查询的数量是预先确定并保持固定的。键表示图像中的空间位置,而值包含有关特征的信息。
- 预测头:预测头输出检测到的对象的边界框和类别。它们由前馈网络头组成,要么预测检测到的对象的边界框和类别,要么在没有检测到时预测一个“无对象”类别。此外,DETR 采用二分图匹配技术,以确保预测的边界框与真实对象关联。这种方法还有助于完善模型训练。
训练损失
训练管道的一个主要组成部分是训练损失。训练损失结合了分类和回归损失,因为模型预测边界框和类别。
1)集合预测损失:DETR 使用集合预测损失来衡量预测对象类别的准确性。通过计算预测和真实对象类别之间的差异,我们了解到缺失的对象类别。
2)边界框损失:DETR 使用边界框损失,衡量预测和真实边界框坐标之间的差异。这种损失有助于在图像中精确定位对象。
DETR 优势和劣势
优势
- 简化的架构:DETR 通过一次性执行边界框和类别预测,消除了多阶段管道的需求。它通过端到端方法简化了目标检测的流程。
- 全局上下文意识:由于变换器使用自注意力机制,DETR 可以通过查看图像中其他对象的位置和关系来捕获全局上下文,与早期的目标检测方法不同,后者是孤立地预测每个对象。
- 高效的训练:以前的架构,如递归神经网络,按顺序进行预测,这使它们更慢且效率低下。然而,采用基于集合的方法,DETR 可以并行进行最终的预测集合,这使得训练流程更简单、更高效。
劣势
- 计算资源:DETR 是基于变换器的模型,因此需要大量的计算资源进行训练,特别是当数据规模庞大且包含高分辨率图像或骨干模型较大时。
- 固定的物体查询数量:DETR 需要事先提到一个固定的物体查询数量,这可能限制了需要预测变化数量物体的场景。调整模型以动态处理不同物体数量是一个挑战。
- 推理速度:尽管 DETR 简化了训练流程,但由于变换器架构的复杂性,推理速度可能比传统方法慢,使其不适用于实时用例。
DETR 实验和结果
DETR 是一个监督深度学习模型。它使用 COCO 目标检测数据集和 Pascal VOC 等大型数据集进行训练。翻转、裁剪、缩放和随机抖动等数据增强技术帮助模型实现更好的泛化。在实验中,考虑了四种不同的 DETR 模型:
- 使用 ResNet-50 骨干构建的基本 DETR
- 使用 ResNet-101 骨干构建的 DETR
- 以及另外两个由 'DC5' 表示的模型,包括扩张的 C5 阶段。
'DC5' 模型通过在 CNN 的最后阶段将特征图的分辨率提高两倍,从而为较小的物体提供更好的预测。
DETR 论文的主要目标是在 COCO 2017 目标检测数据集上评估 DETR 与竞争性的 Faster R-CNN 基线。在最初发布时,DETR 超过了 Faster R-CNN 基线;然而,Faster R-CNN ResNet50 FPN V2 目前比 DETR 模型表现更好。
下表比较了论文中不同 DETR 变体与不同 Faster RCNN 基线的结果。
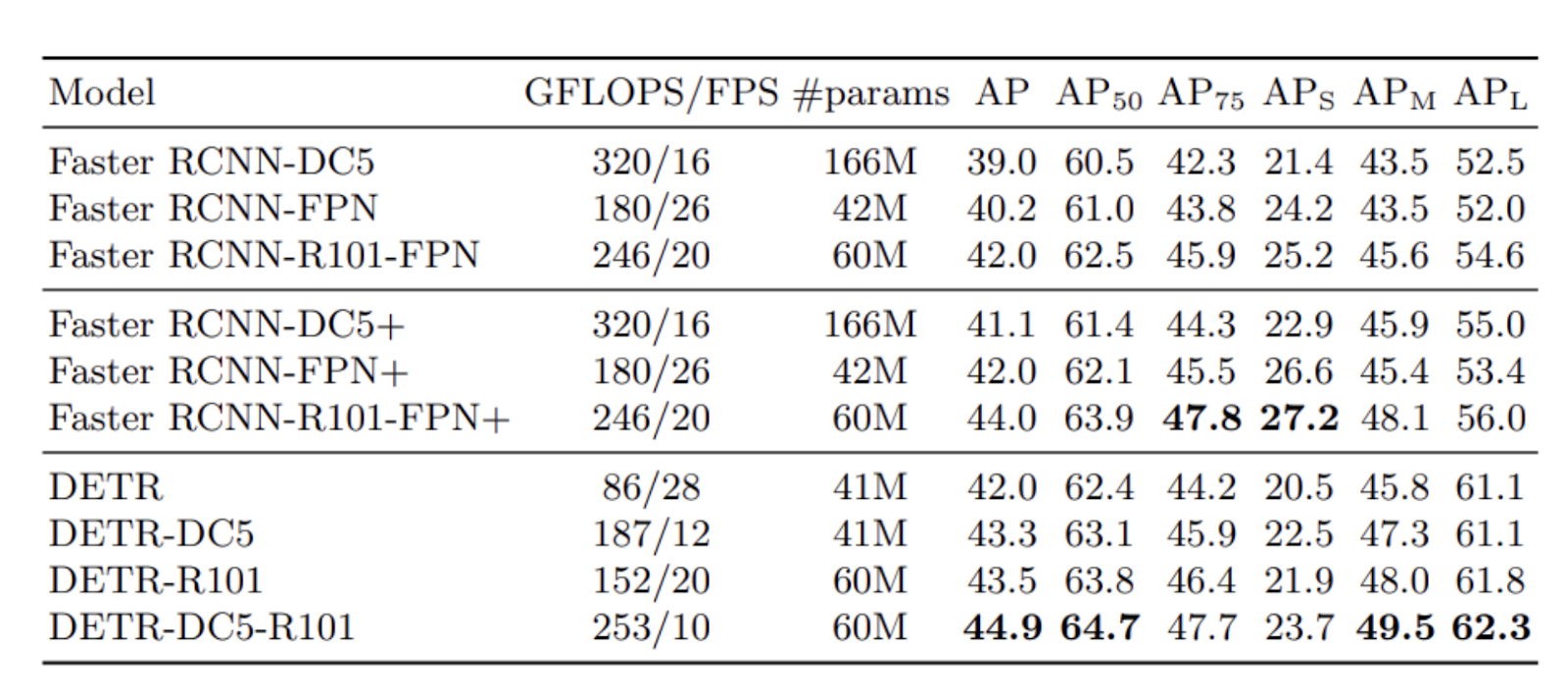 Comparison_of_results_of_DETR_variants_with_Faster_R_CNN_variants_97e009964f.png
Comparison_of_results_of_DETR_variants_with_Faster_R_CNN_variants_97e009964f.png
DETR 变体与 Faster RCNN 变体结果比较
结果表明,DETR 模型与 Faster RCNN 模型取得了相当的性能。表现最好的模型是 DETR-DC5-R101 模型,其 mAP 分数为 44.9。此外,值得一提的是,DETR 模型在大型物体上的表现明显优于小型物体。
要复现 DETR 实验和性能比较结果,请访问 GitHub 上的代码和预训练模型。
将 DETR 和向量数据库整合以增强图像检索和多模态搜索
DETR 是一种使用变换器准确识别和定位图像中对象的最先进的目标检测模型,生成包含这些对象视觉特征的高维特征向量。另一方面,像 Milvus 和 Zilliz Cloud(完全托管的 Milvus)这样的向量数据库是专门设计用于管理和执行高维向量高效向量相似性搜索的存储和检索系统。
通过利用 DETR 从图像中提取特征向量并将它们存储在向量数据库中,我们可以创建高级图像检索系统、多模态搜索解决方案等计算机视觉和数据检索应用。
例如,在电子商务应用中,DETR 可以分析产品图像以生成特征向量,然后将这些向量存储在像 Milvus 这样的向量数据库中。当用户用新图像查询时,系统可以通过比较查询的特征向量与存储的向量,快速检索相似的产品,从而提供准确高效的图像搜索能力。
此外,向量数据库可以存储和索引不同类型的数据向量,如文本、音频和视频,以及 DETR 提取的图像向量,用于多模态搜索。这种方法使用户可以执行结合多种数据类型的复杂搜索;例如,用户可以上传产品图像并提供文本描述,系统将返回与视觉和文本标准相匹配的相关产品。
这种技术组合在各个领域实现了复杂的解决方案,从自动化库存管理到增强的多媒体搜索,提高了不同模态数据检索的准确性和效率。
结论
DETR 展示了使用变换器进行目标检测的创新方法。端到端模型在一次传递中执行目标检测和分类,与以前的多阶段模型(如 RCNN 和 Faster R-CNN)不同。直接集合预测方法允许并行处理,使架构更简单。尽管 DETR 具有优势,但在计算资源消耗和推理速度方面面临挑战。正在进行的研究旨在解决这些限制,并进一步提高模型的性能。此外,使用变换器提供了一种统一的方法来解决涉及 NLP 和计算机视觉的双模态任务。因此,DETR 是一种有前景的方法,可能会改变我们处理目标检测和双模态任务的方式。
通过结合向量数据库和 DETR 技术,我们可以显著构建和增强各种计算机视觉和数据检索应用,如图像检索系统和多模态搜索解决方案。
注:本文为AI翻译,查看原文
 Yesha Shastri
Yesha ShastriFreelance Technical Writer in AI/ML