



为向量数据库优化的数据建模技术
数据建模过程简化并正式化了一个组织的数据架构。它们涉及将数据和信息表示为创建新数据库的蓝图。这增强了利益相关者的理解与合作,同时提高了数据质量和开发效率。
向量数据库与传统数据库不同,因为它们专注于高维、非结构化数据,而不是结构化数据。这在向量数据库的数据建模中引入了独特的挑战和机遇,为讨论优化技术提供了基础。
向量数据库解释
向量数据库以向量嵌入的形式存储数据。向量中的每个值代表一个独特的数据特征,共同形成了数据的全面表示。这些向量存储和管理高维非结构化数据,如文本和图像。向量化结构允许高效的数据检索和先进的搜索机制,如相似性搜索。
向量数据库还通过提供对大量向量嵌入的访问,使AI模型能够理解数据点之间的关系。
 9.1.PNG
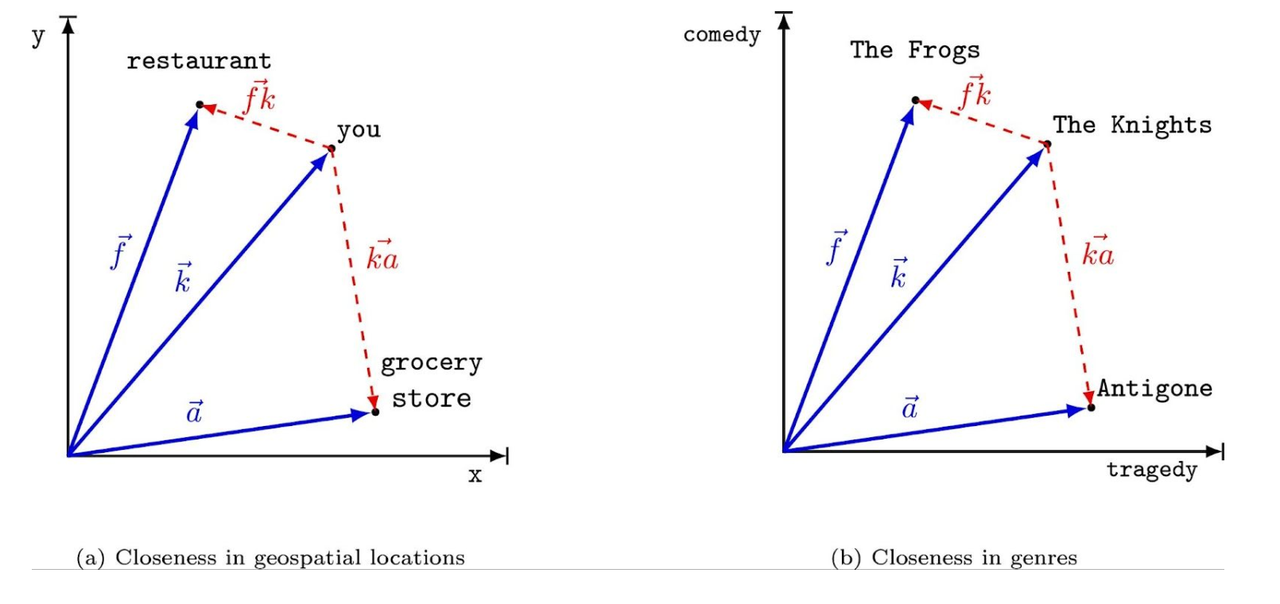
向量的图形表示
9.1.PNG
向量的图形表示
然而,其核心能力需要特别关注数据建模。工程师必须实施诸如索引之类的技术来维护搜索效率,并选择适当的算法来生成嵌入。
为向量数据库优化数据模型
向量数据库专注于向量数据的存储和检索。传统数据库忽略了向量数据的优化可能性,可能不包括使用多个查询向量等功能。因此,针对向量数据库采用了特定的数据建模技术和优化,如下所述:
 9。2.PNG
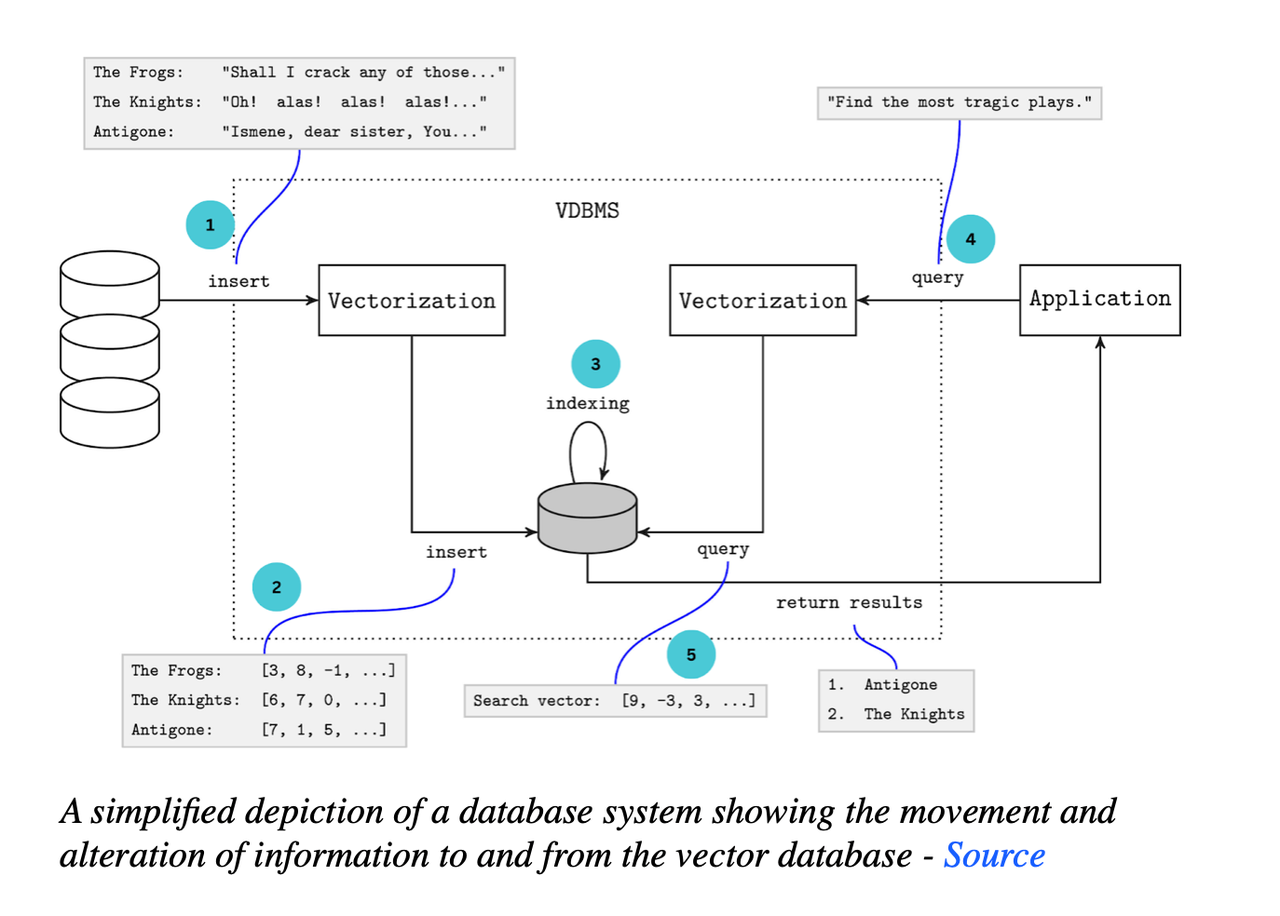
简化的数据库系统图示,显示了信息在向量数据库之间以及向量数据库内部的移动和变化
9。2.PNG
简化的数据库系统图示,显示了信息在向量数据库之间以及向量数据库内部的移动和变化
嵌入策略:各种算法从文本等非结构化数据中计算嵌入。一些流行的技术包括句子变换器、OpenAI嵌入和BGE嵌入。该图表示了嵌入算法如何将对象转换为向量表示。
每种算法都有处理能力,并适合不同的用例。选择正确的算法对于优化向量化步骤至关重要。
索引策略:一旦数据对象被向量化并存储在向量数据库中,索引就增强了查询性能。索引算法之间的权衡是关于在准确性和速度之间取得平衡,因为向量查询通常涉及近似值。像产品量化这样的流行技术通过将高维向量划分为更小的部分来实现降维,从而减少了存储空间,但牺牲了一些准确性。其他技术涉及局部敏感哈希和分层可导航小世界。
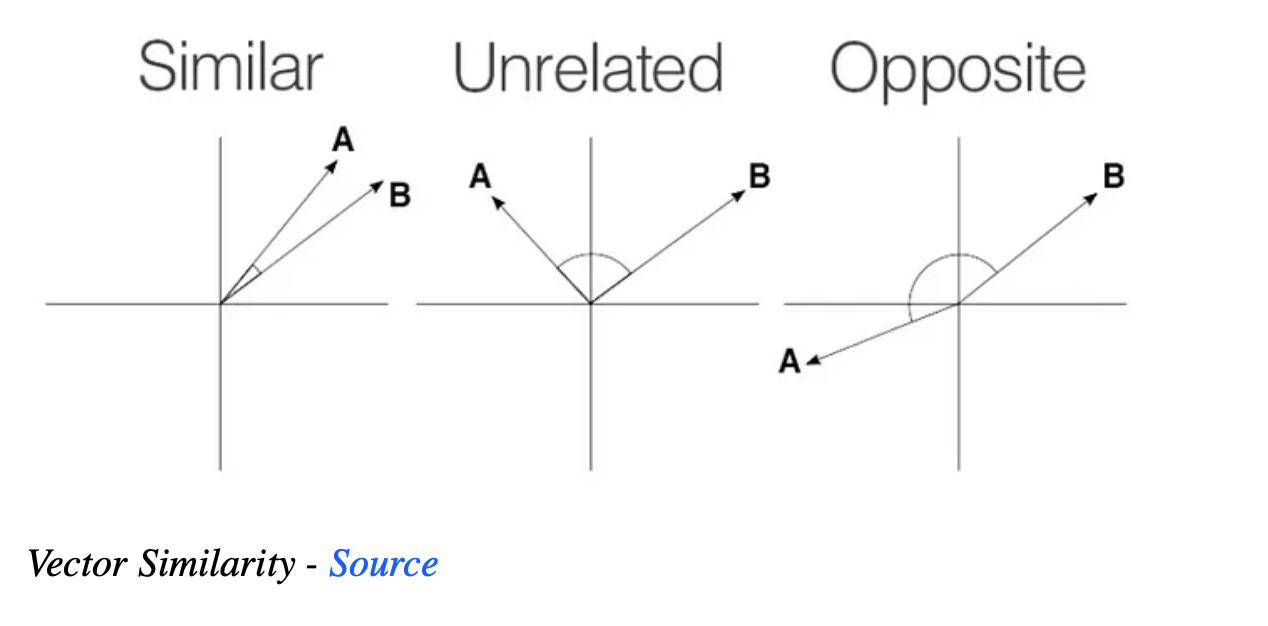
距离度量:向量数据库使用距离度量来比较查询与索引向量,以找到最近的邻居。常见的度量包括余弦相似性、欧几里得距离和点积。这种能力在各种应用中特别有价值,其中找到相似向量至关重要,如图像或文本检索系统。下图展示了向量在笛卡尔图上的距离如何表示它们的相似性。
 9.3.PNG
向量相似性
9.3.PNG
向量相似性
应用和用例
与传统数据库相比,向量数据库专注于高维数据,提供了独特的用例。下面讨论了一些用例:
语义搜索:它使用NLP和ML来理解用户搜索查询的上下文和重要性。向量数据库可以通过存储、比较和检索向量中的数据以进行相似性搜索,从而提高语义搜索的效率和准确性。一些语义搜索引擎的例子包括Google、Bing、Yummly和IBM Watson Discovery。
推荐系统:向量数据库的相似性搜索能力为推荐算法提供动力。这些系统使用算法将输入向量与存储在向量数据库中的向量进行比较,并检索相似的匹配项。这个过程为电子商务商店和Netflix等流媒体网站推荐内容。
复杂数据分析:向量数据库通过使用数据的向量表示来驱动复杂数据分析任务,如聚类、分类和异常检测。这种方法使企业能够在大型数据集中发现隐藏的模式、关系和洞察力,促进数据驱动的决策制定、运营优化和竞争优势。
结论
向量数据库代表了一种进步的数据模型,它存储高维向量,封装了丰富的非结构化数据。这种模型与传统数据库系统有显著不同,需要专门的数据建模技术和优化。这些方法解锁了向量数据库在处理复杂数据应用程序方面的全部潜力。作为AI时代数据管理的未来,深入理解这些技术和优化对于旨在在复杂数据环境中卓越的数据从业者至关重要。


