



从 CLIP 到 JinaCLIP:搜索和多模态 RAG 中的通用 文本-图像表示学习
最近,多模态 Embedding 模型的爆火在各个行业引起了广泛关注,改变了机器理解文本和图像的方式。虽然多模态 Embedding 模型发展有了重要突破,但这些模型仍旧面临一些关键挑战,其中之一就是不同模态数据的 Gap 问题——即使代表的是同一个对象,图像和文本 Embedding 在向量空间中的距离也相隔甚远。
在最近由 Zilliz 主办的非结构化数据 Meetup 上,Jina AI 的工程经理 Bo Wang 向我们介绍了模态 Gap 问题的复杂性并探讨了从 OpenAI 的 CLIP 模型到 JinaCLIP 的转变。
本文将回顾他的一些主要观点,并上手搭建一个多模态相似性搜索系统。搭建这个系统的过程中,我们将使用 JinaCLIP 生成多模态 Embedding,并使用 Milvus 向量数据库存储和检索与查询向量相似的数据。
怎样才算一个好的 Embedding 模型?
Embedding 模型的主要功能是将文本和图像等数据映射成向量。将文本或图像转换为数值表示能够有效捕捉数据中的语义关系。例如,两个向量之间的距离反映这两个向量所代表的两个 Entity(可以是两张图片、两段文本或一张图片和一段文本) 之间的相似程度。
诸如语义搜索、图像搜索等现代 AI 应用而言,核心部分是 Embedding 模型。那么怎样才算是一个好的模型呢?
跨领域、多功能
一个好的 Embedding 模型应该在多个领域(domain)中都表现良好,且不需要微调。良好的模型适应性确保了生成的 Embedding 在各种领域数据中都十分有效,不论是文本、图像还是其他类型的数据。例如,将一张图像映射到向量空间中,同时将其相关的文本也映射到相同的向量空间中,那么这两个 Embedding 向量由于其语义相似,因此在向量空间中的距离应该十分相近。Embedding 模型能否广泛用于多种数据对于相似性搜索、图像检索和跨领域应用等 AI 任务至关重要。
准确的语义相似性
另一个反应 Embedding 模型质量的关键指标是模型是否能够为语义上相关的数据生成相似性高的 Embedding 向量。这个指标不仅仅适用于文本数据,它还适用于任何其他模态的数据。无论是比较文本与文本之间、图像与图像之间还是文本与图像之间的相似性,模型都应该通过向量空间中 Embedding 的距离来反映相似性。
然而,处理文本和图像模态的旧模型通常不满足这个标准。这些模型依赖人工标记图像或使用上下文,来建立数据间的关系。这些方法无法扩展,特别是在分布外泛化(out-of-distribution)的场景中。
多模态任务的挑战
在引入像 CLIP 这样的模型之前,连接不同模态(文本和图像)是一项需要很多手动工作,无论是 Flickr 标签还是用户添加的文本描述。使用分类器标签的监督方法容易不稳定,而且在领域外(out-of-domain)的表现也不尽人意。虽然您可以通过这种方法连接图像和文本数据,但结果无法始终保持一致,特别是输入数据较为复杂的情况下。
为了解决这个问题,业界推出了 CLIP——一个语言-图像预训练模型,通过在图像-文本对上进行训练,来提高多模态模型的性能。CLIP 的创新之处在于它能够将两种模态数据通过 Embedding 投射到同一个向量空间中并保持对齐。但这个模型也有其局限性。
CLIP 模型:突破与限制
CLIP 的突破之处在于训练了两个独立的编码器,一个用于文本,一个用于图像。核心思想是让模型学习同一个向量空间,使文本和图像向量共存于这个向量空间中,而且语义相似的文本和图像距离更接近。模型训练结果令人印象深刻:CLIP 支持使用简单的余弦相似度函数进行多模态任务。
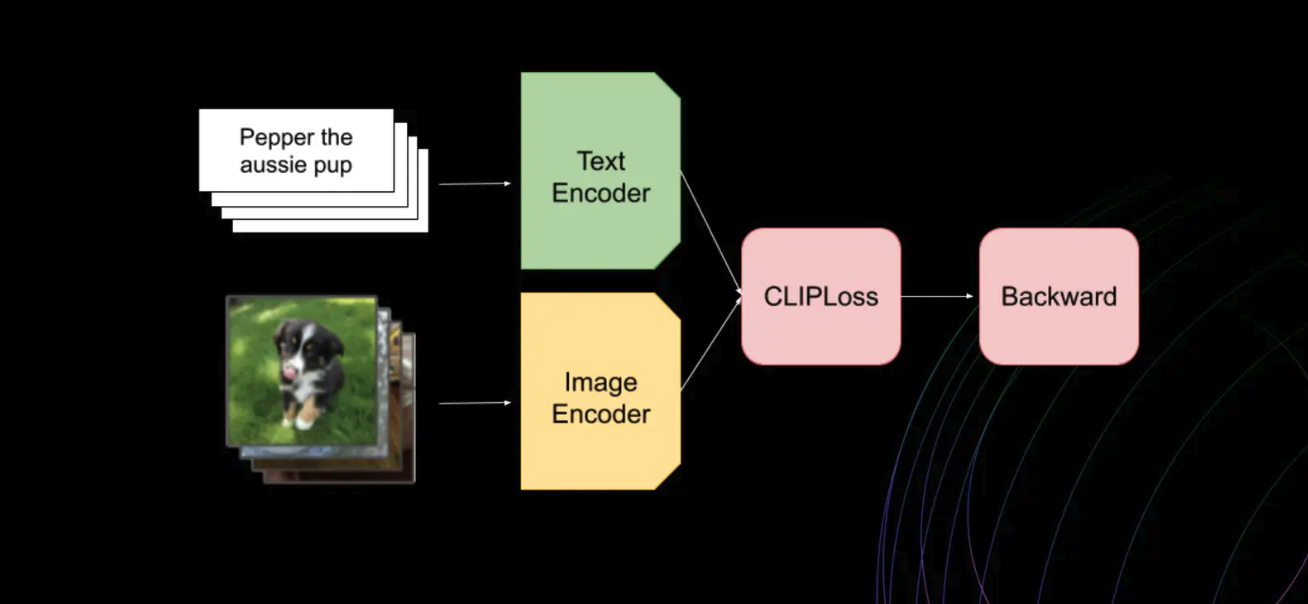 Figure_How_the_CLIP_model_works_2c4fdd3295.png
Figure_How_the_CLIP_model_works_2c4fdd3295.png
CLIP 模型虽然在多模态任务中取得了突破,但它也有一些限制。一个显著的问题是 CLIP 模型无法有效地处理仅涉及文本数据的任务。由于 CLIP 主要针对短标题(通常少于 77 个字符)进行了优化,因此处理较长的文本时会面临挑战。此外,CLIP 在其训练过程中缺乏难负例(hard-negative examples)。难负例是指那些相似但错误的示例,对于细化模型尤其重要,特别是在文本检索等任务中。没有难负例,CLIP 在需要详细文本理解的任务上的性能就无法提升。
从 CLIP 到 JinaCLIP:解决 CLIP 的不足之处
JinaCLIP 在原始 CLIP 架构的基础上进行了改进,以解决 CLIP 的局限性。JinaCLIP 扩展了文本输入,并使用了 BERT v2 架构进行文本编码。在图像处理方面,JinaCLIP 整合了 EVA-02 模型。JinaCLIP 的训练过程侧重于克服图像标题中短文本输入所带来的挑战,并引入难负例。这一过程分为三个阶段,如下所示:
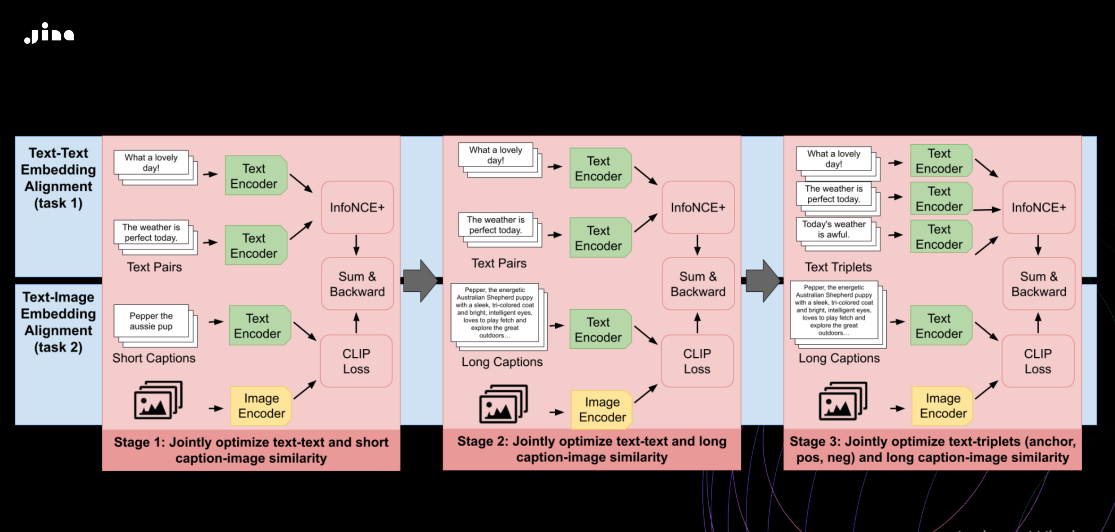 Figure_Training_Process_of_Jina_CLIP_94d30d22b2.png
Figure_Training_Process_of_Jina_CLIP_94d30d22b2.png
主要包含对齐学习、长文本整合和微调三个阶段:
使用短文本和标题进行对齐学习:在这个阶段,模型使用带有标题的图像数据和具有相似含义的文本对进行训练。目标是通过共同优化文本-图像和文本-文本相似性来对齐图像和文本 Embedding 向量。这种共同训练过程确保了模型在学会将文本与图像关联的同时,也保留了其仅处理文本的能力。虽然相比专门针对文本对训练的模型在处理文本时性能略有下滑,但这一阶段通过平衡的方法保证了模型处理仅文本数据的能力。
整合长文本描述:第二阶段引入了合成数据来训练模型。这些数据将图像与由 AI 模型生成的更长文本对齐。同时,继续使用文本数据对进行训练。模型学会了处理更广泛的文本描述,同时保持与图像的对齐能力,增强了模型理解短文本和长文本图像关系的能力。
使用文本三元组(triplet)和难负例进行微调:最后阶段使用难负例和文本三元组,文本三元组中有两个文本语义相似,但其中一个是有意保持不同的。这有助于模型进行更细微的语义区分,特别是在仅文本数据的场景中。同时,模型继续使用合成的图像-长文本对进行训练。这一阶段显著提高了模型处理仅文本数据的性能,同时确保了早期阶段学到的图像-文本保持对齐。
这种方法在保证多模态任务的性能同时,增强了仅文本数据场景下的能力。让我们看看这种新方法与原始的 CLIP 相比如何。
性能指标显示了JinaCLIP 与原始 CLIP 模型相比检索性能的变化:文本到文本检索性能提升了 165%,图像到图像检索性能提升了 12%,图像到文本检索性能提升了变化了 6%,文本到图像检索性能提升了 2%,如下图所示。
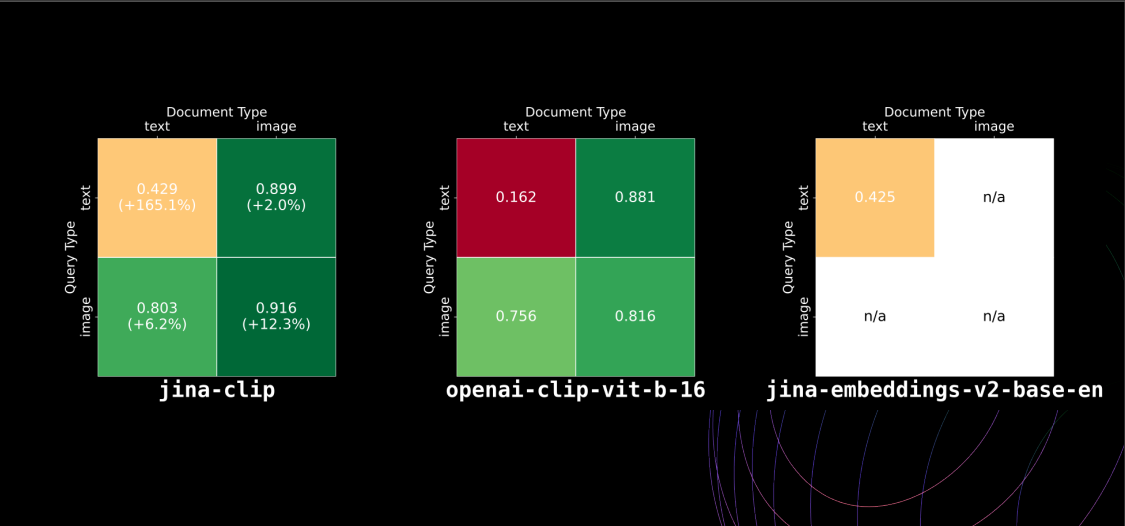 Figure_Model_performance_comparison_between_jina_clip_openai_clip_vit_b_16_and_jina_embeddings_v2_base_en_b60051c8b1.png
Figure_Model_performance_comparison_between_jina_clip_openai_clip_vit_b_16_and_jina_embeddings_v2_base_en_b60051c8b1.png
新的训练过程增强了跨多种任务的泛化能力,并有助于减少模态间隙。下一节我们将讨论模态间隙,这个问题是多模态 AI 模型中的主要障碍。我们还会介绍为什么会出现模态间隙这个问题。
模态间隙:出现的原因
模态间隙是指由不同输入数据类型转化而来的的 Embedding 向量之间出现空间分离,如文本和图像数据的语义相似但在向量空间中相距甚远。模态间隙会削弱多模态检索系统的有效性,因为 Embedding 向量没有完全反映相关的输入数据之间的真实关系。下图清楚地展示了模态间隙——图中看起来像一个截断的圆锥体,图像 Embedding 处于向量空间的一端,文本 Embedding 处于另一端。
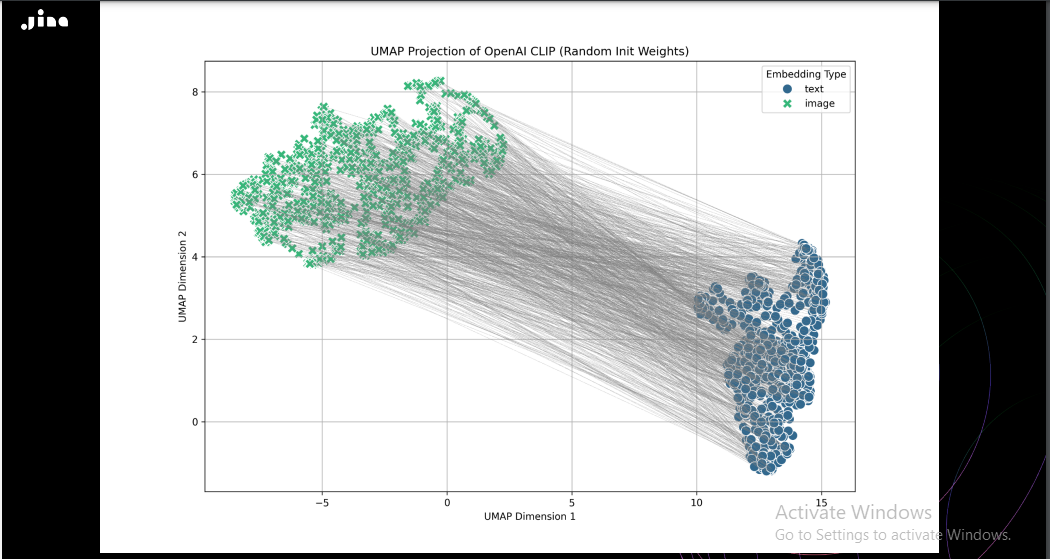 Figure_The_initial_positions_of_image_and_text_embeddings_in_Jina_CLIP_with_entirely_randomized_weights_and_no_prior_training_projected_into_two_dimensions_53de2df2a8.png
Figure_The_initial_positions_of_image_and_text_embeddings_in_Jina_CLIP_with_entirely_randomized_weights_and_no_prior_training_projected_into_two_dimensions_53de2df2a8.png
即使在现代模型中,也有几个关键原因导致模态间隙的出现。
初始化时的锥效应(The Cone Effect During Initialization)
多模态模型,特别是那些处理文本和图像输入的模型,通常使用各自的编码器。这些编码器通常以随机或预训练的权重进行初始化,导致文本 Embedding 聚集在向量空间的一个区域,而图像 Embedding 集中在另一个区域,如上图所示。这种初始分离被称为锥效应(cone effect),使得不同模态(例如图像和相关文本)的 Embedding 向量难以正确对齐。例如,由于这种初始化偏差,毛茸茸小猫的文本向量和猫的图像向量可能一开始就相隔很远,即使它们在语义上是相关的。
温度缩放(Temperature Scaling)
在训练期间,AI 模型在其对比损失函数(contrastive loss function)中使用一种称为温度缩放的技术来调整 Embedding 向量之间的对齐程度。虽然这种技术有助于微调 Embedding 之间的距离,但温度缩放也可能无意中保留模态之间的初始分离,从而加剧模态间隙。例如,如果温度缩放没有仔细调整,描述一只活泼小狗的文本和狗的图像可能在向量空间中仍然相隔太远。
批次内假负例(In-Batch False Negatives)
当使用大型数据集进行训练时,一对对不匹配的数据点(例如,一只狗的图像与“一个红苹果”的文本配对)被视为负例。然而,这些假负例中可能仍然有一部分存在一些语义上的重叠。例如,如果两个数据点都与动物这个广义概念相关(例如,一张狗的图片和“一只活泼的狼”的文本),模型可能会错误地将这些 Embedding 视为完全不相关,从而距离上排布得十分远,进一步加剧模态间隙。
理解模态间隙为何发生只是第一步。为了弥合这一间隙,业界已经开发出各种训练策略,从而使不同模态的 Embedding 更接近,确保多模态检索任务结果更准确。
解决模态间隙问题:训练技巧
模态间隙是一个结构性问题,没有一刀切的速快解决方案。但有一些策略和技巧可以有助于减轻模态间隙问题带来的影响。减少模态间隙的关键在于在训练期间减少不同模态Embedding 之间的分离,确保相关的图像和文本在向量空间中更接近。
提高温度缩放(Higher Temperature Scaling)
在实践中,提高训练过程中的温度(temperature)可以鼓励不同模态的 Embedding 向量通过增加模型学习过程中的随机性而更紧密地靠拢。例如,提高温度可以有助于对齐一张猫的图像和“毛茸茸的猫”的文本的向量。然而,这种方式的代价是更慢的收敛速度和需要更多的计算资源。使用高温缩放训练的模型虽然一定程度上有助于改善文本和图像向量的对齐,但需要更长的训练时间,而且对计算资源的要求更高。
难负例(Hard-Negative Sampling)
引入难负例,即语义上接近但不匹配的数据对,是另一种减少模态间隙的技术。这些难负例能够推动模型学习相关概念之间更细微的差别,从而提高检索准确性。例如,一张猫的图像与“小老虎”文本可能看起来不匹配,但模型通过这个数据对可以到这两个输入数据在语义上具有一定的重叠(都是猫科动物),并且应该在向量空间中保持对齐。这个过程教会模型识别相关概念之间的相似性和差异性,提高了模型区分近似概念的能力。
示例:使用 Milvus 和 JinaCLIP 实现多模态检索
我们已经探讨了不同模态数据会有 gap 的技术原因,现在让我们通过一个实际的例子,看看如何使用 Milvus 开源向量数据库和 JinaCLIP 来搭建一个多模态检索系统。
Milvus 能够管理、搜索和查询高维向量,是适用于多模态检索任务和检索增强生成(Retrieval Augmented Generation, RAG)任务的理想解决方案。无论您处理的是文本、图像还是其他类型的数据,Milvus 都帮助您高效地存储 Embedding 向量并使用先进的相似性搜索技术检索相关结果。
在本节中,我们将逐步介绍如何使用 Milvus 搭建一个能够处理文本和图像 Embeddding 的多模态检索系统。这个系统允许用户输入文本或图像,并从一个文本和图像混合的数据集中检索出语义上最相关的结果。
步骤 1: 设置环境
首先,安装在系统环境中安装我们需要使用的库。
!pip install pymilvus transformers torch timm
然后,导入所需的库并设置 encoder 类。
# Import necessary libraries
from transformers import AutoModel
from pymilvus import MilvusClient
import torch
# Define Encoder class to handle text and image embedding generation
class Encoder:
def __init__(self, model_name: str):
# Initialize the model (AutoModel from transformers instead of SentenceTransformer)
self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
def encode_text(self, text: list[str]) -> list[float]:
# Generate embeddings for text only
with torch.no_grad():
text_emb = self.model.encode_text(text)
return text_emb
def encode_image(self, image_urls: list[str]) -> list[list[float]]:
# Generate embeddings for images only
with torch.no_grad():
image_emb = self.model.encode_image(image_urls)
return image_emb
# Initialize the encoder with the model jinaai/jina-clip-v1
model_name = "jinaai/jina-clip-v1"
encoder = Encoder(model_name)
在上述代码中,我们首先导入所需的库:来自 transformers 的 AutoModel 作为我们的编码模型,MilvusClient 用于与 Milvus 交互,以及 torch 用于 tensor 操作。
然后我们定义了一个 Encoder 类,它包装了来自 transformers 的 AutoModel。encode_text 和 encode_image 方法使用模型分别为文本和图像生成 embedding 向量。torch.no_grad() 上下文管理器用于禁用梯度计算,因为这对于推理不是必需的,并且禁用后可以节省内存。
最后,我们使用 jinaai/jina-clip-v1 模型并初始化编码器,该模型可以将文本和图像编码到同一个 embedding 向量空间中。
步骤 2: 准备数据
接着,我们需要准备示例数据,转化为 Embedding 向量并插入到 Milvus 中。
# Load data: images and text for embeddings
sentences = ['A blue cat', 'A red cat', 'A red cat generated by AI', 'A dog biting on a stick']
image_urls = [
'https://i.pinimg.com/600x315/21/48/7e/21487e8e0970dd366dafaed6ab25d8d8.jpg',
'https://i.pinimg.com/736x/c9/f2/3e/c9f23e212529f13f19bad5602d84b78b.jpg',
'https://images.fineartamerica.com/images/artworkimages/mediumlarge/1/red-cat-art-3771-bb-james-ahn.jpg',
'https://images.squarespace-cdn.com/content/v1/54822a56e4b0b30bd821480c/29708160-9b39-42d0-a5ed-4f8b9c85a267/labrador+retriever+dans+pet+care.jpeg?format=1500w'
]
# Generate embeddings for text and images
text_embeddings = encoder.encode_text(sentences)
image_embeddings = encoder.encode_image(image_urls)
# Ensure consistent dimensions
dim = len(image_embeddings[0])
在这里,我们定义了示例句子和图像 URL。这些 URL 包含了红色猫、蓝色猫和狗的图片。然后使用我们的编码器为文本和图像生成 embedding 向量。dim 变量存储了 embedding 向量的维度,我们在后续创建 Milvus Collection 时会需要考虑 dim。
步骤 3: 设置 Milvus
设置 Milvus client 并为我们的多模态数据创建 Collection。
# Insert embeddings into Milvus
collection_name = "multimodal_rag_demo"
milvus_client = MilvusClient(uri="./milvus_demo.db")
# Check if collection exists and drop it if so
if milvus_client.has_collection(collection_name):
print(f"Collection {collection_name} already exists. Deleting it...")
milvus_client.drop_collection(collection_name)
# Create Milvus collection
milvus_client.create_collection(
collection_name=collection_name,
auto_id=True,
dimension=dim,
enable_dynamic_field=True,
)
我们初始化了 Milvus client 并连接到本地的数据库。随后检查是否已经存在一个同名的 Collection。如果存在,就将其删除。然后,我们创建了一个新的 Collection,并指定了 Collection 名称。通过设置参数 auto_id=True,我们让 Milvus 为插入的 Entity 自动生成 ID。我们还设置了 dimension 参数,与上一步骤中 Embedding 向量的维度相匹配。此外,我们还启用了动态列,这样一来我们就可以添加额外的元数据。
步骤 4: 创建索引
在插入数据前,我们需要创建索引来优化搜索性能:
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="vector", # The field to be indexed (your embedding field)
metric_type="COSINE", # Can be L2, COSINE, etc.
index_type="FLAT", # FLAT ensures exact search, ideal for small datasets
)
# Create the index for the collection
milvus_client.create_index(collection_name, index_params)
print(f"Index created successfully for collection: {collection_name}")
上述代码创建了FLAT 索引,并将相似度类型设置为余弦距离(Cosine) 。
步骤 5: 将数据插入到 Milvus 中
完成设置 Collection 和索引后,我们可以将数据插入到 Milvus 中。
data_to_insert = []
# Insert text embeddings
for idx, txt_emb in enumerate(text_embeddings):
data_to_insert.append({"text": sentences[idx], "vector": txt_emb})
# Insert image embeddings
for idx, img_emb in enumerate(image_embeddings):
data_to_insert.append({"image_url": image_urls[idx], "vector": img_emb})
# Insert data into Milvus
insert_result = milvus_client.insert(
collection_name=collection_name,
data=data_to_insert,
)
print(f"Insert result: {insert_result}")
milvus_client.load_collection(collection_name)
在上述代码中,我们创建了一个字典列表,每个 dict 中包含一个句子文本或者一个图片 URL,以及对应的 Embedding 向量。然后我们使用 Milvus client 的 insert 方法将数据插入到 Collection 中。数据插入成功后,我们需要加载 Collection 到内存以便后续搜索。
步骤 6: 进行多模态搜索
我们同时使用图片和文本查询进行多模态搜索。
# Multimodal search with a combination of image and text query
query_image_url = 'https://imgcdn.stablediffusionweb.com/2024/4/5/5e70d71c-a7f6-44e9-972d-8c5a27d45c3d.jpg'
query_text = "Give me similar red cats"
# Generate query embedding (image + text)
query_embedding_image = encoder.encode_image([query_image_url])[0]
query_embedding_text = encoder.encode_text([query_text])[0]
# Perform search in Milvus using image embedding
search_results_image = milvus_client.search(
collection_name=collection_name,
data=[query_embedding_image],
output_fields=["image_url", "text"], # Ensure both fields are included in the results
limit=5, # Number of results to return
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
# Perform search in Milvus using text embedding
search_results_text = milvus_client.search(
collection_name=collection_name,
data=[query_embedding_text],
output_fields=["image_url", "text"], # Ensure both fields are included in the results
limit=5, # Number of results to return
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
# Retrieve and print results from image query
print("Image Query Results:")
for result in search_results_image:
for hit in result:
image_url = hit['entity'].get('image_url')
text = hit['entity'].get('text')
if image_url:
print(f"Retrieved Image URL (from image query): {image_url}")
if text:
print(f"Retrieved Text (from image query): {text}")
# Retrieve and print results from text query
print("Text Query Results:")
for result in search_results_text:
for hit in result:
image_url = hit['entity'].get('image_url')
text = hit['entity'].get('text')
if image_url:
print(f"Retrieved Image URL (from text query): {image_url}")
if text:
print(f"Retrieved Text (from text query): {text}")
在上述代码中,我们展示了进行多模态搜索的流程。首先定义了查询图片 URL 和查询文本。查询图片如下所示:
 Figure_2_Query_input_image_of_a_red_and_white_cat_99b47e63c6.png
Figure_2_Query_input_image_of_a_red_and_white_cat_99b47e63c6.png
{kind=link}
然后,我们使用编码器对这些查询进行编码,以生成它们各自的 embedding 向量。然后在 Milvus 中进行两次独立的搜索:一次使用图像 embedding,另一次使用文本 embedding。对于每次搜索,我们都请求在输出中包含 image_url 和 text 字段,这使我们能够检索这两种类型的数据。我们将每次搜索的结果限制为 5 个,并使用余弦距离作为我们的相似度类型。在搜索参数中,nprobe 参数允许我们微调搜索的聚类数量,提供了搜索速度和准确性之间的平衡。最后,我们展示结果——每种查询类型检索到的图像或文本,从而评估系统处理基于文本和图像的查询的能力。
完整代码可在此获取。
以下为搜索结果示例
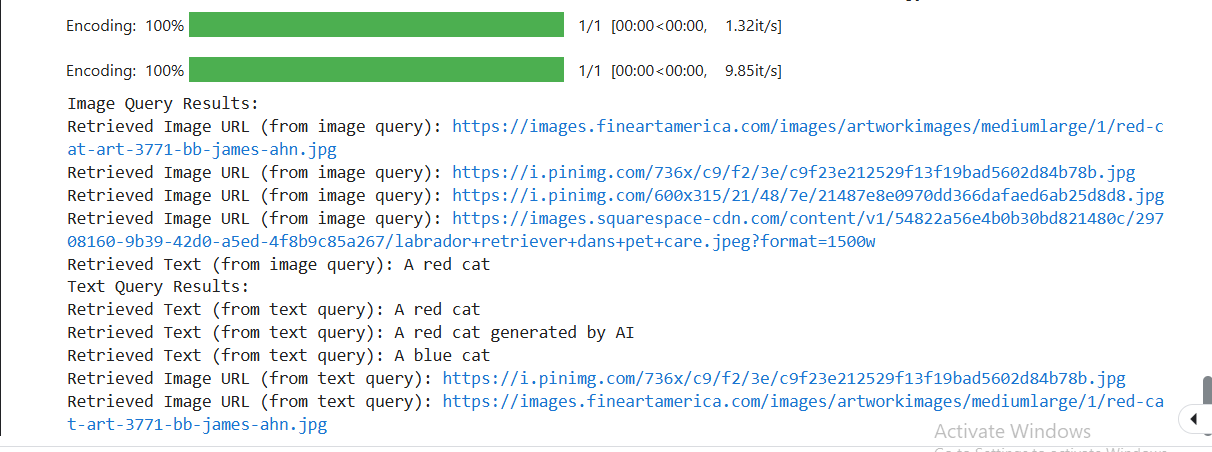 sample_results_56f73f1930.png
sample_results_56f73f1930.png
可以看到,使用图片进行向量搜索时,我们可以获得相关的图片和文本。反之亦然。这就是多模态搜索的力量。下图是在图片和文本搜索结果中都出现的一张相似图片。
 Figure_3_Output_image_of_a_red_cat_after_conducting_a_similarity_search_in_Milvus_a3fa8c7280.png
Figure_3_Output_image_of_a_red_cat_after_conducting_a_similarity_search_in_Milvus_a3fa8c7280.png
可以看到,返回的图片与我们输入的查询图片非常相似。
你还可以在系统中添加 reranker 根据相关性对搜索结果进行重排,在搜索结果中将最相关的内容排在最前面。显然,Milvus 十分擅长检索最匹配的内容。您可以基于本文的示例进一步创建一个多模态 RAG 系统。
总结
Bo Wang 解释了在多模态模型中如何弥合不同模态之间的差异,并展示了从 CLIP 到 JinaCLIP 的转变。他分解了对齐文本-图像数据过程中的关键挑战,并演示了 JinaCLIP 如何解决这些问题。
本文通过构建一个多模态相似性搜索系统,使用了 JinaCLIP 生成 Embedding 和 Milvus 实现高效检索。有了这些知识,您现在可以搭建自己的多模态搜索应用,甚至可以通过集成 reranker 这样的高级搜索技术进一步扩展多模态搜索系统。
更多资源
Multimodal RAG: Expanding Beyond Text for Smarter AI
Evaluate Your Multimodal RAG Using Trulens
Top 10 Multimodal AI Models of 2024
Build a Multimodal RAG with Gemini, BGE-M3, Milvus and LangChain
Multimodal RAG locally with CLIP and Llama3
A Review of Hybrid Search in Milvus
 Simon Mwaniki
Simon Mwaniki
keepReading

观点|从Vector Database到Vector Lakebase,如何定义AI data infra的下一个十年
了解 Zilliz Vector Lakebase 如何统一非结构化数据、索引与计算,支撑 RAG、Agent 和批量处理。
如何理解On-demand,为什么每个做大数据语义分析、挖掘、回归的团队都需要它?
Zilliz On-demand 支持大规模向量数据按需搜索、分析探索与批量挖掘,减少闲置算力和成本。

用8年时间将向量数据库做到极致后,我们为何又推出了Vector Lakebase ?
Zilliz Vector Lakebase 解耦存储与计算,让低频向量检索按需启动,降低闲置成本,支撑大规模 AI 搜索。