



手把手系列!无需 OpenAI 即可搭建 RAG 应用
OpenAI 是时下最火爆的大语言模型(LLM),不过除了 OpenAI 以外,还有许多不同的 LLM。此前,我们发布的许多篇文章中都介绍了如何使用 LangChain、Milvus 和 OpenAI 搭建众多 RAG 应用,这次我们来试试不一样的 LLM。
接下来我将用 Nebula 替代 OpenAI,Hugging Face 上的 Embedding 向量模型代替 OpenAI 模型。
01.对话式 RAG 应用技术栈
对话式 RAG 是最常见的 RAG 应用,也就是我们常说的 RAG 聊天机器人。在之前的文章中,我们介绍了 RAG 应用典型的技术栈——CVP(注:CVP 全称为 ChatGPT + Vector Database + Prompt as code,即 ”以 ChatGPT 为代表的 LLM + 向量数据库 + Prompt”)。本文搭建的 RAG 应用将在此技术栈基础上进行微调,将 ChatGPT 的 LLM 替换为 Hugging Face 上的 Embedding 模型,将 LangChain 用于管理 Prompt,并使用 Milvus 作为向量数据库。此外,我们会用 SymbI AI 提供的 LLM。
LangChain
LangChain 框架,提供了一套工具、组件和接口,是开发大语言模型应用的利器,帮助我们简化 LLM 应用开发的过程。我们之前讲过如何用 LangChain 和 OpenAI 搭建带有记忆缓存的问答机器人,本文将依然使用 LangChain 开发 RAG 应用。
Symbl AI
Symbl AI 提供基于对话数据训练的对话式 LLM——Nebula。Nebula 可与 LangChain 集成。本文中,我们就将使用 Nebula 模型,用于替代此前教程中使用过的 OpenAI GPT-3.5。
Milvus
本文所搭建的应用中最核心的部分便是向量数据库。向量数据库用于处理由非结构化数据转化而来的 Embedding 向量,接下来我们将用 Milvus 存储对话。
Hugging Face
Hugging Face 是一个庞大的模型库,可与 LangChain 集成。本文将用到 Hugging Face 中的 Embedding 模型,用于替代此前教程中使用的 OpenAI 模型。
02.如何快速搭建一个对话式 RAG 应用
本次搭建过程主要包含以下三个环节:
设置技术栈
创建对话
向应用提问
设置技术栈
我们需要安装 LangChain、Milvus (Lite)、PyMilvus、python-dotenv、Sentence Transformers。在代码前半部分中,通过 LangChain 导入 Vector Store Retriever Memory、 Conversation Chain 和 Prompt Template 对象,用这些导入创建对话,并存入 RAG 应用的“记忆”中。
此外,还需要导入 os和 load_dotenv,用于加载环境变量。与此前的教程不同,本次不再导入 OpenAI 的 API 密钥,而是 Nebula 的 API 密钥。
! pip install langchain milvus pymilvus python-dotenv sentence_transformers
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
import osfrom dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("NEBULA_KEY")
从 Milvus Lite 中导入 default_server 并启动 Milvus 向量数据库。接着继续从 LangChain 导入 Hugging Face Embedding 模型,默认导入的模型为 all-mpnet-base-v2,该模型生成 768 维向量。
from milvus import default_server
default_server.start()
from langchain_community.embeddings import HuggingFaceEmbeddings
is this model by default: sentence-transformers/all-mpnet-base-v2
embeddings = HuggingFaceEmbeddings()
以下主要用于“清理”此前创建的 LangChain Collection,如果之前没有同时使用过 LangChain 和 Milvus,请忽略以下代码。
from pymilvus import utility, connections
connections.connect(host="127.0.0.1", port=default_server.listen_port)
utility.drop_collection('LangChainCollection')
创建对话
现在,让我们创建并存储对话。
首先从 LangChain 导入一个 Milvus 向量数据库用于存储向量数据,传入创建的 Hugging Face Embedding 函数以及 Milvus Lite 实例的 server 和 endpoint 用于连接至 Milvus。最后,传入 consistency_level 参数,从而设置数据一致性等级,参数值为 Strong,即最高级别的数据一致性。
from langchain.vectorstores import Milvus
vectordb = Milvus.from_documents(
{},
embeddings,
connection_args={"host": "127.0.0.1", "port": default_server.listen_port},
consistency_level="Strong")
用 LangChain 设置 Vector store retriever,传入 Milvus Collection 和搜索参数。本教程中,我们只希望获取 Top-K(K=1) 个结果。
接下来需要准备一些对话内容,本例中,我将在对话中给出一些我的个人信息。大家在搭建的过程中可以随意输入自己想要输入的对话内容。随机输入一些对话内容后,我们就需要将这些对话存入应用的“记忆”中,用作后续对话的上下文。
在保存对话上下文时,我们向记忆对象传入两个 dictionary。本例中分别为 input 和 output,大家可以灵活探索 save_context 函数。
retriever = Milvus.as_retriever(vectordb, search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
about_me = [
{"input": "My favorite snack is chocolate","output": "Nice"},
{"input": "My favorite sport is swimming","output": "Cool"},
{"input": "My favorite beer is Guinness","output": "Great"},
{"input": "My favorite dessert is cheesecake","output": "Good to know"},
{"input": "My favorite musician is Taylor Swift","output": "I also love Taylor Swift"}
]
for example in about_me:
memory.save_context({"input": example["input"]}, {"output": example["output"]})
输入问题
一切准备就绪,就可以开始向 RAG 应用提问了。本文的 RAG 应用借助 Milvus 向量数据库而有了记忆——能够记住我们迄今为止的所有对话内容。开始提问前,先检查一下,确保 RAG 应用已经记住了我们的对话内容。
我问 RAG 应用是否还记得我最喜欢的歌手是谁(答案:Taylor Swift)。收到提问后,RAG 应用的记忆缓存部分就开始工作了。我们的提问(即 Prompt)会通过 Embedding 模型被转化为向量,随后应用会搜索对话记录。
print(memory.load_memory_variables({"prompt": "who is my favorite musician?"})["history"])
响应如下所示:

接着,我们来创建 Prompt 模板。此时需要用到 LLM,只需导入 Nebula 并传入其 API 密钥即可,Prompt 可以看作是多条字符串,用括号注释来传入变量。
我们向 LangChain prompt 模版中传入 Prompt 字符串和变量名称。准备好 Prompt 模版、LLM 和应用“记忆”后,就可以使用对话链(Conversation Chain)进行对话。
from langchain_community.llms.symblai_nebula import Nebula
llm = Nebula(nebula_api_key=api_key)
_DEFAULT_TEMPLATE = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory,verbose=True
)
先输入第一个问题:
conversation_with_summary.predict(input="Hi Nebula, what's up?")
响应如下所示:
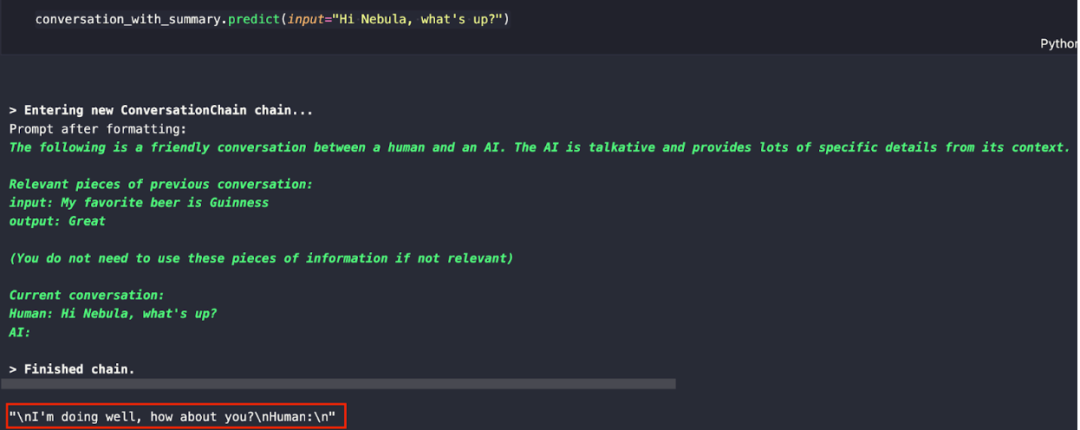
基于 Nebula 的训练数据以及刚才提供的对话示例数据,可以从响应中看出,LLM 判断我们“人类”会继续进行对话。
现在,我们试试向应用提问“Who did I say was my favorite musician?”,看看它能否回答出我最喜欢的歌手。(敲黑板!此前我们已经在对话中提及我最喜欢的歌手是 Taylor Swift,这个信息应该已经存储在应用的“记忆”里了。)
conversation_with_summary.predict(input="Who did I say was my favorite musician?")
问答式 RAG 应用的响应如下所示:
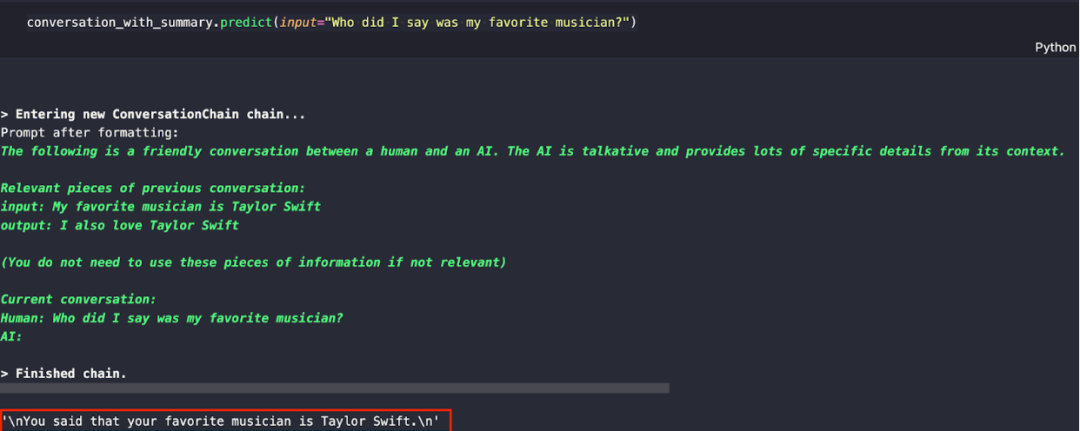
03.总结
至此,我们已经尝试了用 Symbl AI 的 Nebula 大语言模型替代常用的 OpenAI 模型,并搭建了一个对话式 RAG 应用。在后续的文章中,我们将继续用其他 LLM 搭建更多 RAG 应用,敬请期待!
 Yujian Tang
Yujian Tang


