



向量化和查询结构化数据的终极指南
在当今以数据为驱动的世界中,组织处理着各种格式的大量信息。结构化数据,如电子表格、数据库表和 CSV 文件,是一种常见的类型,它高度组织化并遵循预定义的模式。结构化数据通常用于精确搜索任务。
向量化是将数据(通常是非结构化的,如文本、图像或视频)转换为数值高维向量的过程。这种方法使机器能够理解数据的语义。向量嵌入特别适用于相似性搜索等任务,这些任务使用传统方法可能具有挑战性。
既然结构化数据用于精确搜索,为什么要向量化它呢?本指南将回答这个问题,并带你从开始到结束了解如何向量化和查询结构化数据。
结构化数据与半结构化数据与非结构化数据
如果你在处理数据,你可能经常听到“结构化”、“半结构化”和“非结构化”这些术语。但它们是什么意思,为什么你应该关心呢?
让我们分解这些数据类型之间的区别:
结构化数据遵循预定义的模式并具有一致的格式。想想一个完美组织的电子表格,行代表单个记录,列代表特定属性。结构化数据是数据世界的整洁狂,始终遵守严格的结构。
半结构化数据具有部分定义的结构,但允许更多的灵活性。它就像一个有一些结构的文档,例如标题和段落,但这些元素内的内容可能会变化。电子邮件、XML 和 JSON 文档是半结构化数据的典型例子。
非结构化数据顾名思义,缺乏预定义的结构。它是数据家族中的野孩子,以各种格式出现,如文本文档、图像、视频和音频文件。非结构化数据更难以使用传统方法进行整理和分析。
现在,你可能会想,“我该把这些数据存储在哪里?”好吧,数据库的选择取决于你的数据性质和你应用程序的特定要求。
关系型数据库如 MySQL、PostgreSQL 和 Oracle 是结构化数据的首选。这些数据库提供了一种强大且有效的方式来使用 SQL(结构化查询语言)存储、检索和操作结构化数据。
如果你处理的是半结构化数据,面向文档的数据库如 MongoDB、Couchbase 或 Cassandra 是你最好的选择。这些数据库设计用于处理灵活的模式设计,并且可以轻松容纳层次和嵌套数据结构。
对于非结构化数据,你需要像 Milvus 这样的专业向量数据库。这些系统可以处理高维向量中的大量非结构化数据,并提供你需要的可扩展性和高可用性。
为什么要向量化结构化数据?
现在我们已经涵盖了结构化数据及其各种类型的基础知识,你可能会想知道,“什么是向量化,我为什么要费心去做呢?”很好的问题!
向量化是将数据(通常是非结构化的,如文本、图像或视频)转换为数值高维向量的过程。想想它是为你的数据创建一张地图,每个数据点由一组独特的坐标表示。将你的数据转换为向量为搜索、分析和机器学习开辟了全新的可能性。
向量化使机器能够理解你的数据的语义。向量嵌入特别适用于相似性搜索等任务,这些任务使用传统方法可能具有挑战性。
为什么要向量化你的结构化数据?
既然结构化数据通常用于精确搜索,为什么要向量化它呢?想象一下,能够基于它们的含义而不是仅仅精确匹配来找到数据库中的相似记录。或者发现你不知道存在的数据中的隐藏模式和关系。向量化使所有这些成为可能。
有几个情况下你应该考虑向量化你的结构化数据集:
- 当你的数据集包含结构化和非结构化数据时。
- 当你的结构化数据包括非结构化值时,例如带有客户ID和客户评论或个人资料描述的 CSV 文件。
另一方面,有些情况下向量化你的结构化数据可能不是一个好的主意:
- 如果你的数据仅包含定量值,例如产品价格表,向量化可能不会增加太多价值。传统的结构化数据库非常适合处理这种类型的数据,它们通常是执行分析的最适当工具。
- 假设你的目标是执行汇总分析,比如确定有多少人在你的视频上停留超过2秒。在这种情况下,数据可能没有从向量化中受益的语义价值。类似 SQL 的数据库设计用于高效处理这些查询,因此通常最好坚持使用它们进行此类任务。
如何使用 Milvus 向量化和查询你的结构化数据
Milvus 是一个开源的向量数据库,用于向量相似性搜索引擎和 GenAI 应用程序。Milvus 可以存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的超过十亿个嵌入向量。
Milvus 与各种流行的嵌入模型集成,包括 OpenAI Embedding API、sentence-transformer、BM25、Splade、BGE-M3 和 VoyageAI,使其更容易为你的数据生成向量嵌入。通过利用这些嵌入模型,Milvus 简化了向量化结构化数据的过程,使你能够专注于构建利用向量相似性搜索和检索的强大应用程序。
现在我们已经理解了这些概念,让我们带你了解如何使用 Milvus 集成来向量化你的结构化数据并执行相似性搜索。
在这个例子中,我们将创建一个 DataFrame,一个包含像文本这样的非结构化数据的结构化数据集。我们将向量化结构化数据中的非结构化数据,为整个数据集创建一个集合,然后查询它。
在你利用 Milvus 集成进行向量生成之前,你必须在你的计算机上安装 Milvus 和必要的包。按照这个指南安装 Milvus。
让我们看看使用 Milvus 向量化和查询你的结构化数据的逐步程序。
步骤 1:安装所需库
 88.1.png
88.1.png
这条命令安装了所需的 Python 库:pymilvus(包括 model 包)。pymilvus 是 Milvus 的 Python 客户端。
步骤 2:导入所需库
 88.2.png
88.2.png
步骤 3:启动 Milvus 服务器
 88.3.png
88.3.png
在这一步中,我们从 PyMilvus 导入了必要的模块。
我们创建了一个 MilvusClient 的实例来连接 Milvus,并将 URI ./milvus.db 传递到 MilvusClient 的初始化中。
将 URI 设置为本地文件,例如 ./milvus.db,是最方便的方法,因为它自动使用 Milvus Lite 将所有数据存储在此文件中。
重要提示:如果你有超过一百万的文档,我们建议你在 Docker 或 Kubernetes 上设置一个更高性能的 Milvus 服务器。在使用此设置时,请使用服务器 URI,例如 http://localhost:19530,作为你的 URI。
步骤 4:准备数据
 88.4.jpeg
88.4.jpeg
输出
 88.5.png
88.5.png
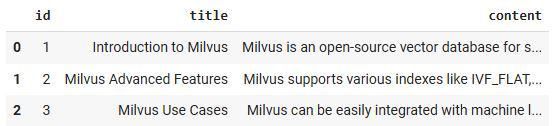
在这里,我们以 pandas DataFrame 的形式准备了结构化数据。数据包含三列:id、title 和 content。content 列包含我们想要向量化的文本数据。
步骤 5:向量化数据
 88.6.png
88.6.png
步骤 6:创建集合模式和集合
 88.7.png
88.7.png
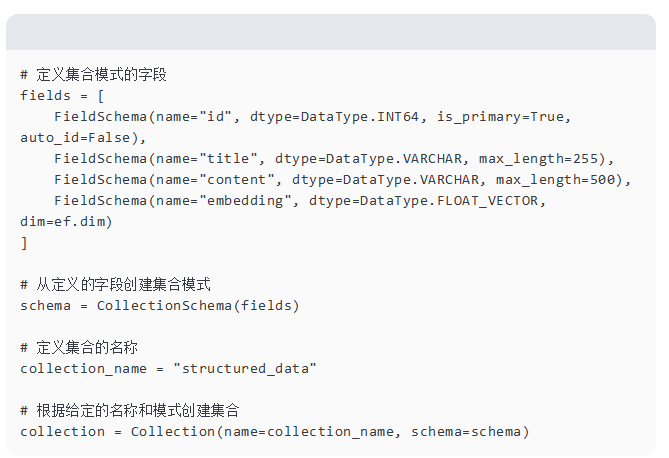
我们通过指定字段及其数据类型来定义集合的模式。FieldSchema 对象表示集合中的列。在这种情况下,我们有字段 id、title、content 和 embedding。
embedding 字段是一个浮点向量,其维度等于嵌入函数(ef.dim)的输出维度。然后我们使用定义的字段创建一个 CollectionSchema,并使用模式和集合名称实例化一个 Collection 对象。
步骤 7:将数据插入集合
 88.8.png
88.8.png
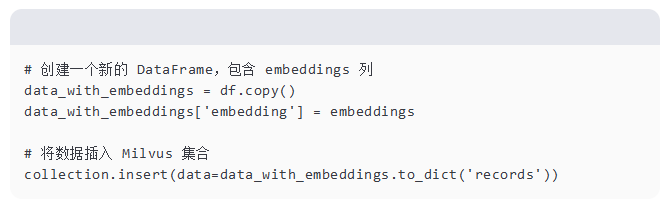
我们通过复制原始 DataFrame df 并添加计算出的 embeddings 列来创建一个新的 DataFrame data_with_embeddings。然后我们使用 insert 方法将数据插入 Milvus 集合,将数据作为字典列表传递。
步骤 8:创建索引
 88.9.png
88.9.png
为了执行高效的相似性搜索,我们在 embedding 字段上创建了一个索引。我们指定了索引参数,包括度量类型(余弦相似性)、索引类型(HNSW)以及其他参数,如邻居数量(M)和构造参数(efConstruction)。
步骤 9:将集合加载到内存中
 88.10.png
88.10.png
输出
 88.11.png
88.11.png
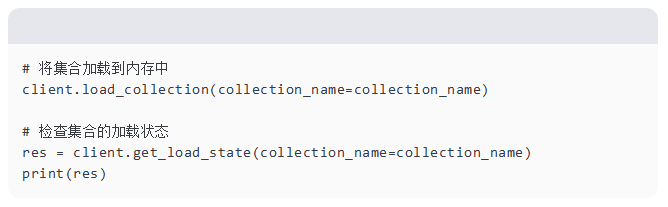
在执行搜索之前,我们必须使用 client.load_collection 将集合加载到内存中。然后我们使用 client.get_load_state 检查集合的加载状态,以确保它准备好进行查询。
步骤 10:执行相似性搜索
 88.12.png
88.12.png
输出
 88.13.png
88.13.png
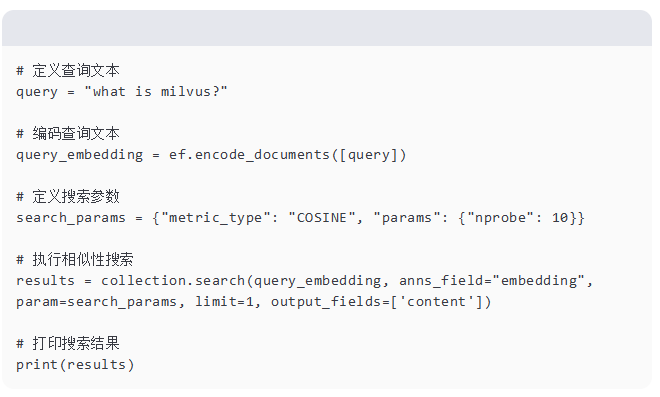
最后,我们执行一个相似性搜索。我们使用相同的嵌入函数(ef.encode_documents)对查询文本进行编码。我们定义了搜索参数,包括度量类型(余弦相似性)和 nprobe 参数,该参数控制搜索期间要探索的候选数量。
然后我们调用集合上的搜索方法,传递查询嵌入、要搜索的 embedding 字段、搜索参数、要返回的结果的最大数量(limit=1)以及要包含在结果中的 output_fields(在这种情况下,只有 content 字段)。
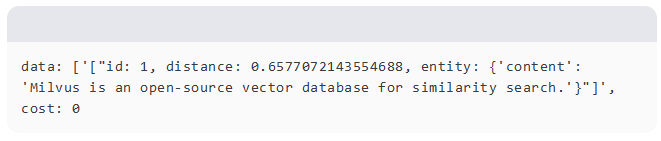
搜索结果包含基于查询嵌入和文档嵌入之间的余弦相似性最相似的文档。
通过遵循这些步骤,你可以有效地利用 Milvus 向量化并对你的结构化数据执行相似性搜索。
利用 Milvus 在 RAG 中进行相似性检索
现在,我们将看到使用 Milvus、LangChain 和 OpenAI 语言模型构建一个简单的检索增强生成(RAG)系统的过程。我们将从网络资源中加载和向量化结构化数据,将其导入 Milvus,执行相似性搜索,将检索结果发送到语言模型,并生成对用户问题的最终答案。
安装所需库
 88.14.png
88.14.png
首先,我们需要安装必要的 Python 库
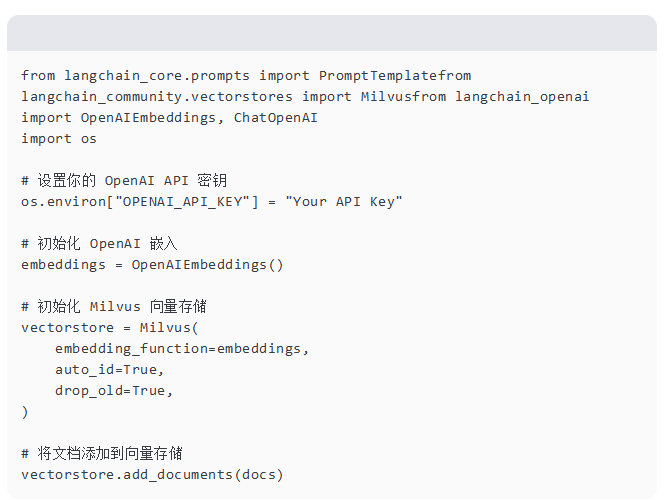
加载和预处理数据集
我们将加载一个样本数据集(Seaborn 的 "Tips" 数据集)并预处理它以供导入 Milvus。
 88.15.png
88.15.png
设置向量存储和 LLM
我们将设置 Milvus 向量存储,初始化 OpenAI 嵌入和语言模型,并将文档添加到向量存储。
 88.16.png
88.16.png
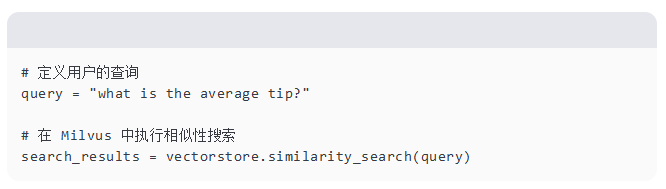
定义查询并执行相似性搜索
现在,我们将定义用户的查询并在 Milvus 中执行相似性搜索以检索最相关的文档。
 88.17.png
88.17.png
构建 RAG 链
我们将为 RAG 系统定义提示模板,初始化 OpenAI 语言模型,并使用 LangChain 的表达式语言构建 RAG 链。
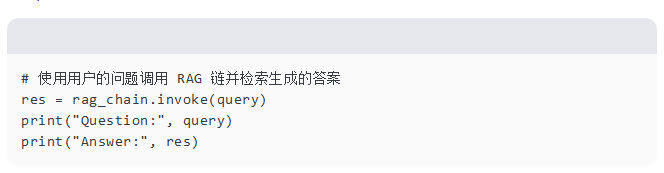
生成答案
最后,我们将使用用户的问题调用 RAG 链并检索生成的答案。
 88.18.png
88.18.png
输出
 88.19.png
88.19.png
通过利用 Milvus 进行高效的向量相似性搜索,并将其与像 OpenAI 这样的强大语言模型相结合,你可以创建复杂的 RAG 系统,为用户提供准确且与上下文相关的答案。
使用 Zilliz Cloud Pipelines 进行向量化和查询
Zilliz Cloud 是一个完全托管的向量数据库,构建在 Milvus 向量数据库之上。Zilliz Cloud Pipelines 是一个一站式解决方案,用于向量创建和检索。它提供了一套全面的工具和 API,允许你轻松连接到各种数据源,应用预构建或自定义向量化模型,并将向量化数据存储在 Zilliz Cloud 中,以进行高性能的相似性搜索和检索。
让我们通过一个示例,了解如何使用 Zilliz Cloud Pipelines 向量化数据并将嵌入存储在 Zilliz Cloud 中进行相似性搜索。
设置 Zilliz Cloud Pipelines
获取你的 Zilliz Cloud 集群的相关信息,包括集群 ID、云区域、API 密钥和项目 ID。更多信息,请参见 Zilliz Cloud 控制台。
 88.21.png
88.21.png
创建摄取管道
定义一个摄取管道,处理和向量化你的结构化数据,并将嵌入存储在 Milvus 中。
在上述代码中,我们通过指定必要的详细信息来定义一个摄取管道,例如管道名称、描述、项目 ID、集群 ID 和集合名称,其中嵌入将存储在 Milvus 中。
我们还定义了管道内的两个函数:
- INDEX_TEXT:此函数用于处理并为文本数据生成嵌入。
- PRESERVE:此函数保留与结构化数据相关的附加元数据。
最后,我们发送一个 POST 请求来创建摄取管道,并从响应中提取管道 ID。
运行摄取管道
使用创建的摄取管道将你的结构化数据导入 Milvus。
 88.22.png
88.22.png
我们向管道的运行端点发送一个 POST 请求来运行摄取管道,提供结构化数据作为输入。此示例有一个文本列表(text_list)和一些相关的元数据(metadata)。
摄取管道将处理结构化数据,使用指定的嵌入服务为文本生成嵌入,并将嵌入与元数据一起存储在指定的 Milvus 集合中。
使用 Zilliz Cloud Pipelines,你可以轻松地向量化你的结构化数据,并在 Zilliz Cloud 中存储嵌入以进行相似性搜索。该平台提供了一种无缝且高效的方式来处理和搜索你的结构化数据,使用向量嵌入。
有关更详细的信息和额外的代码示例,请参考 Zilliz Cloud 开发者中心的快速入门指南。
总结
本文探讨了为什么要向量化结构化数据,并演示了如何加载和向量化它,将其导入 Milvus,执行相似性搜索,并使用 OpenAI 语言模型生成上下文相关的答案。
 Uppu Rajesh Kumar
Uppu Rajesh KumarFreelance Technical Writer


