Milvus Week | 向量搜索遇上过滤筛选,如何选择最优索引组合?
前言
在向量数据库产业,有这样一个反常识的认知:
很多人以为,执行检索前,增加的过滤条件越多,查询过程越简化,效率越高;
但其实,各种预过滤与筛选往往会增加系统的复杂度和优化难度。
想象一下,某一天,你突发奇想,想用数百万张猫咪图片,做一个的 meme 应用。
接下来,你要面临的一个场景可能是这样,用户想搜索点赞量超过 50 (标量过滤)的 小猫后空翻 (召回top K的向量相似度检索)照片。
换句话说,我们需要在向量相似度检索的过程中,增加了传统的标量过滤条件,然后数据库会根据图片的内容和元数据返回匹配结果。
整个流程看起来非常便捷,但实际上,向量搜索融合标量过滤其实是一个极其复杂的工程优化问题。你可能面临以下问题
先过滤还是先检索?
向量和元数据存储在不同的模块中,如何协同工作?
预过滤筛掉一批数据后,导致图索引过程中图结构“断连”,无法实现有效的相似度检索
……
为此,在 Milvus与Zilliz Cloud 中,我们做了大量底层优化。
本篇文章,将深入解析我们在 Cardinal 索引引擎和整个向量数据库系统层面所做的优化工作,揭示 Milvus 如何在不显著增加延迟或损害召回率的前提下,做到向量搜索与标量过滤双管齐下。
01
图索引优化(Graph Index Optimization)
在大规模数据集中,加速向量搜索离不开索引的构建。比如,当我们处理数百万甚至数十亿向量时,若不建立索引而直接进行暴力搜索显然不现实。
为了解决这一问题,图索引算法(如 HNSW)应运而生。通过将向量数据点构建成一个稀疏图,搜索时从某个起点开始沿图遍历,通过逐跳接近目标,最终返回 TopK 最近邻,显著减少需要遍历和计算的向量数量,从而以较低成本,最大限度的提升整个搜索的查询速度。
在此基础上,做元数据过滤的时候,Milvus 的常见做法是:先基于元数据生成一个 bitset(位图,本质是一个布尔向量),标记哪些向量符合过滤条件,然后在搜索时引用这个 bitset,跳过不匹配的向量。假设你用 SIMD 对 256 个候选向量同时计算欧氏距离,再结合 bitset,一次 SIMD 判断就能快速跳过不合法的结果,提升 CPU吞吐率。
虽然这种方式可以借助 SIMD 加速标量判断,但对图索引(比如HNSW)不总是适用——特别是当大多数点都不符合过滤条件时。
其逻辑在于, 图索引的核心是“遍历图”,而不是“线性扫描”。如果很多邻居在 bitset 中被过滤(即为 0),那么搜索路径会“断掉”,导致图搜索提前终止或 miss 掉结果。
此外,图索引期望候选节点越多越好(recall高),如果 bitset 中符合条件的点很少,那就会导致图结构基本“失联”,直接退化成 brute-force。
如下图所示,绿色点表示符合过滤条件的向量,红色点表示不符合。若遍历图时跳过红色点 A,那么点 B 和 C(它们与查询点距离很近)可能会因此无法被访问,导致图结构“断连”,形成“孤岛”。
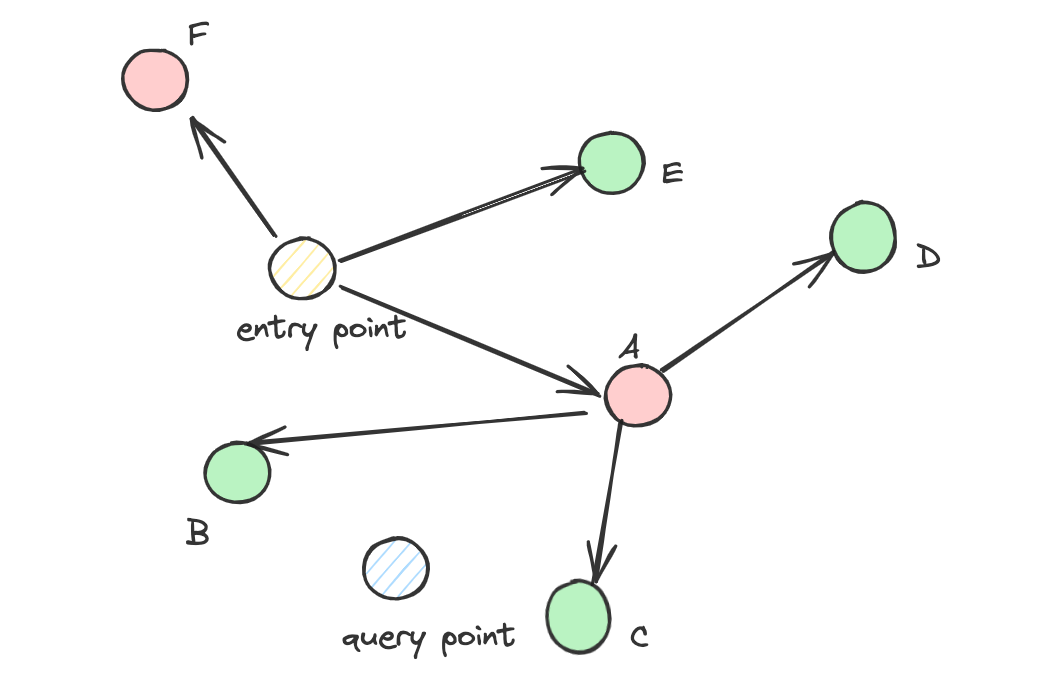
因此,我们不能简单地跳过不符合过滤条件的点,否则召回率会严重下降。概念上讲,过滤率越高(越多向量被排除),“孤岛”现象越严重。
在这种背景下,查询无法到达目标点,往往不是因为目标点被过滤掉,而是因为到达路径被中断了。
反过来,如果完全不跳过过滤掉的点,图遍历的成本就会显著增加,接近暴搜。可以把图索引想象成一个城市地图,查询点位于最南端,有效点都在北方。遍历路径就会导致我们要绕更多的路才能到达北方,检索过程中,还会不断向东西扩展,大大扩大搜索空间,降低系统吞吐(QPS)。
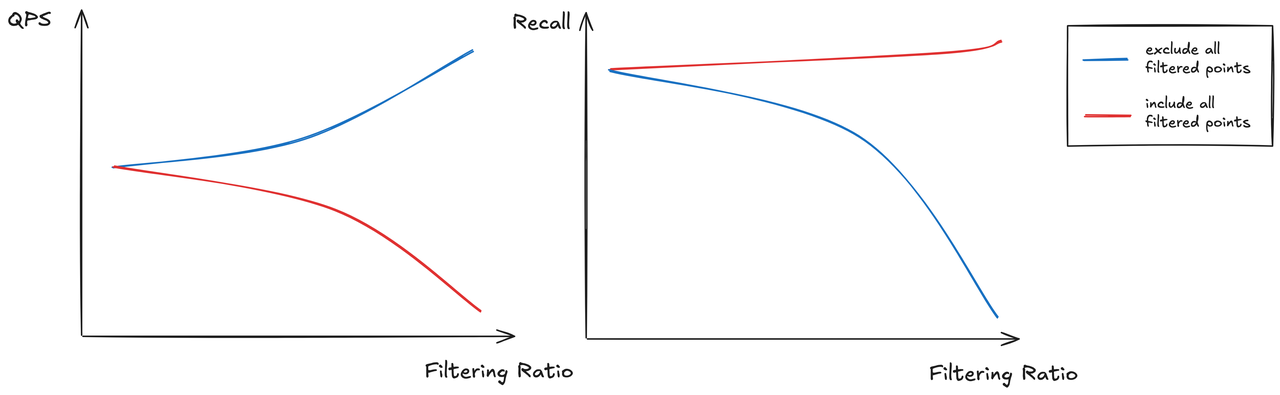
为了解决上述问题,我们引入了以下几种方法,旨在尽可能保持图连通性的同时减少无效点的遍历。
(1)Alpha 策略
根据过滤比例引入一个概率因子 alpha,用于动态决定是否在搜索路径中包含被过滤的点。
HNSW 等图索引中,搜索靠邻居逐跳遍历。一旦过滤条件(如 "地区=上海")过于严格,bitset 中的 0 太多,会导致:起点不满足条件;邻居也大多不满足;图中符合条件的点“孤立”,遍历路径断裂,无法到达这些节点;recall 急剧下降,搜索基本失效。
Alpha 策略的核心思想是不一刀切地丢弃不符合过滤条件的点,而是“有概率性地保留”一部分不合法节点参与图遍历。通常α是一个介于 0 和 1 的参数,当 bitset[i] = 0(原本会被过滤掉)时,系统会以概率 α 保留该点,允许它作为跳板(bridge)参与图遍历,但不会进入最终 topK 结果。实际操作过程中,我们可以根据 bitset 中 1 的比例动态调整 α 值,高过滤率 → α 值越高
(2)ACORN (Approximate Clustering with Over-connected Randomized Neighbors)方法
在 HNSW 中,通常会对图进行边修剪以保持稀疏性,但 ACORN 则反其道而行之,保留尽可能多的边,甚至为每个节点增加候选邻居,通过把“稀疏图”变成“高连接图”,来增强图的连通性和搜索鲁棒性。此外,ACORN 的遍历算法会向前看两步(检索邻居的邻居),从而进一步增加抗干扰能力,以提高检索效果。
(3)动态选择邻居
在搜索过程中,候选邻居是根据当前查询的特征、搜索上下文和过滤条件动态选取的,不同于 Alpha 策略,这种方法更精细、更具控制力,尤其是应对大规模图索引 + 元数据过滤的复杂检索任务时,可以避免邻居过多导致性能下降。
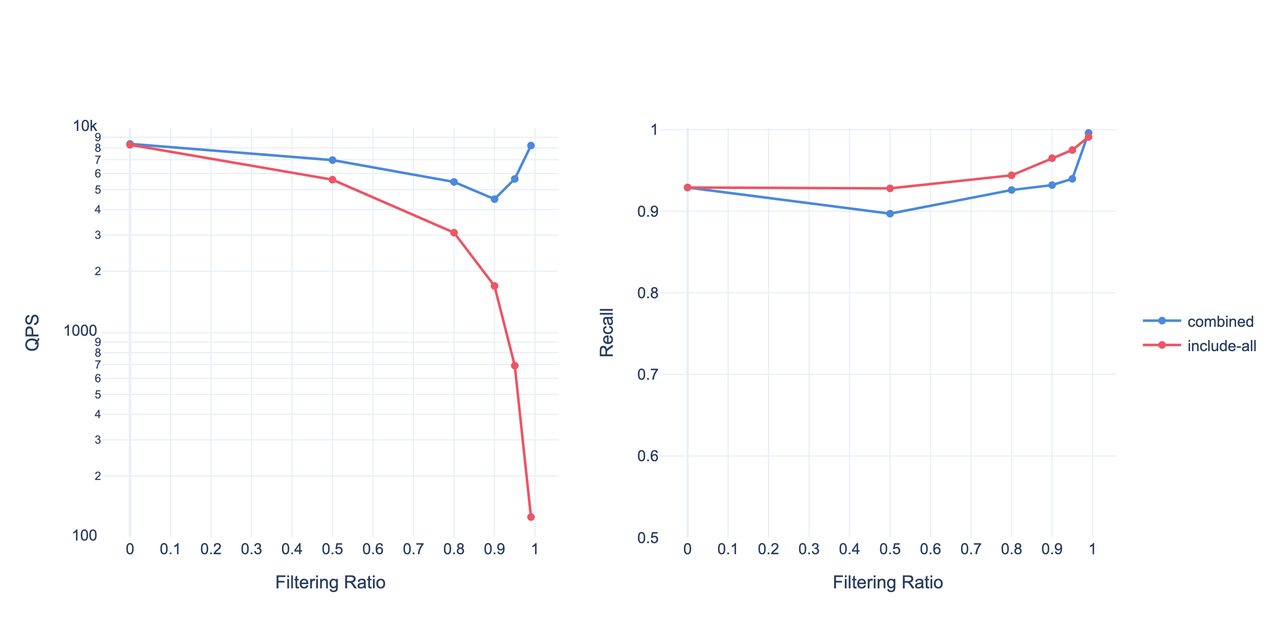
除此之外,当过滤比例极高(如 99% 以上向量都不符合条件)时,图路径会变得极长,孤岛增多,性能大幅下滑。此时系统会自动切换为暴力搜索以提升整体效果。
我们在 AWS r7gd.4xlarge(16 vCPU,64 GB 内存)上,对 Cohere 1M 数据集(维度 = 768)进行了测试。图中蓝线代表上述动态组合策略,红线为基线方案(遍历全部被过滤点)。
02
元数据感知索引(Metadata-Aware Indexing)
在向量检索结合元数据过滤的过程中,经常遇到的一种情况是元数据(如图片来源)与向量的语义内容无直接关联。为此我们引入了“元数据感知索引”(metadata-aware vector index)机制:通过分析元数据分布,提前构建子图,以提升向量索引查询性能。
例如,如果两个标量列分别描述颜色和形状,你可以基于每个不同取值构建对应的子图(subgraph)。当过滤条件命中某个子图区域时,可以在该子图中执行搜索,从而加快查询速度。
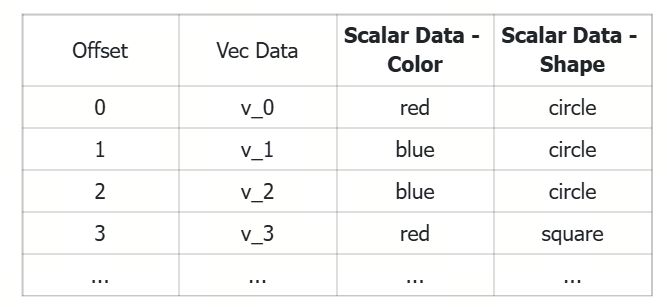
如下图所示,原始图索引被称为 基础图(base graph),而由标量字段生成的子图称为列图(column graphs)。我们同时限制图的出度(out-degree),以平衡内存与性能。当用户的搜索请求中没有元数据过滤时,系统会使用基础图(base graph)查询;而当指定了元数据过滤条件时,系统会使用与过滤字段对应的列图(column graphs)来加速搜索过程。

03
迭代过滤(Iterative Filtering)
当用户使用一些复杂的元数据过滤条件(如 JSON 规则或复杂的字符串比较)时,评估这些过滤条件所耗费的时间可能成为整个搜索过程中的核心瓶颈。正如前文提到的,标准做法是在向量搜索开始前先执行元数据过滤,相应的,瓶颈通常并不在向量检索本身,而是出现在过滤逻辑的执行上。
一个看似合理的替代方案是:先执行向量搜索,再对返回的 TopK 结果进行元数据过滤。不过,这种方式也有风险:如果过滤条件过于严格,可能会导致返回结果数量不足。
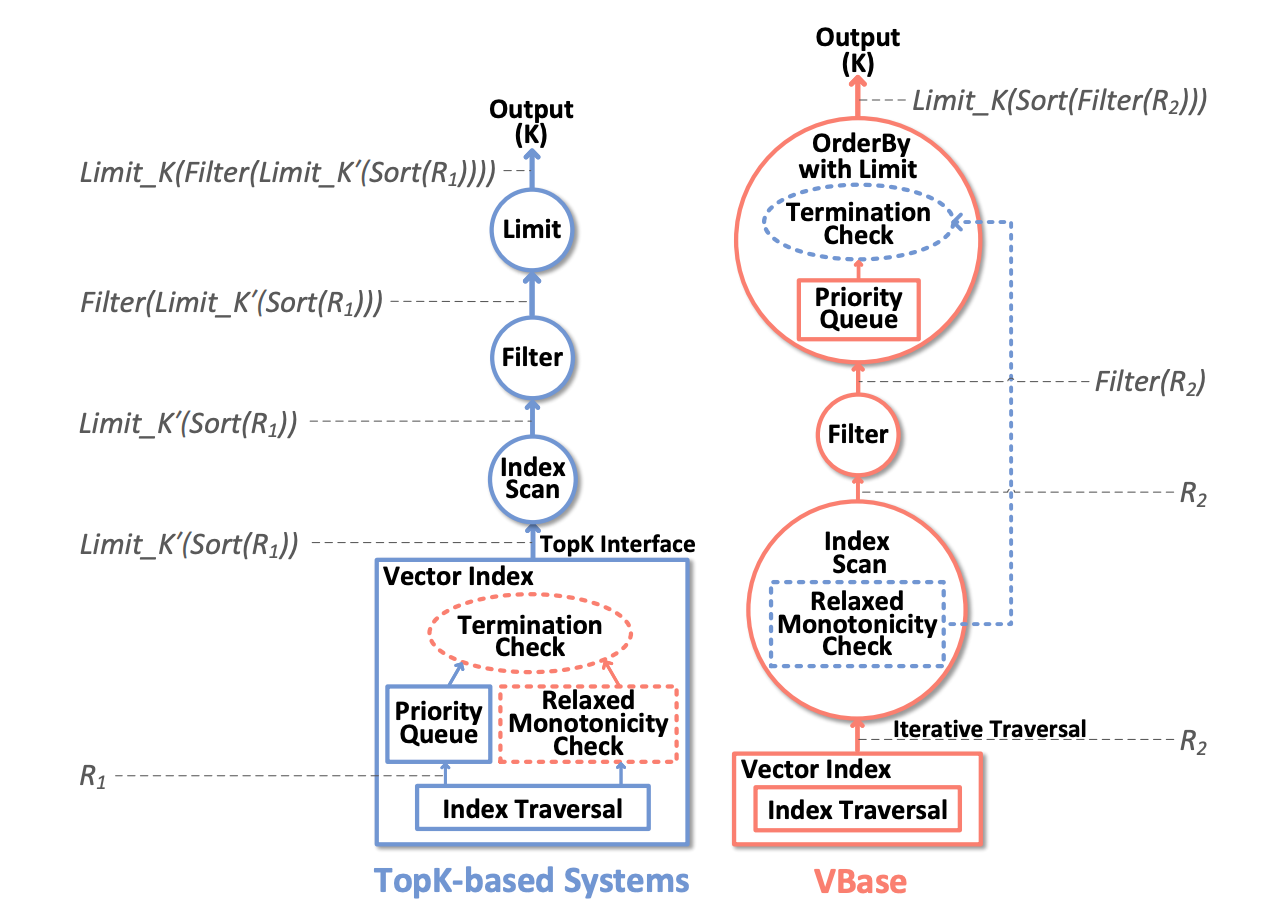
为了解决这个问题,受VBase启发,我们引入了 迭代式过滤(Iterative Filtering)。该方法利用向量索引提供的迭代器,逐步返回最近邻结果,每获取一批候选结果就执行一次元数据过滤。
这种方式兼顾了 性能 和 准确性,特别适合以下场景:过滤条件复杂、判断成本高(如 JSON 嵌套、正则匹配);过滤条件很“窄”,命中率低(即只匹配少量数据);结果需要 TopK 条,但常规过滤容易返回不足。
详情可见:https://docs.zilliz.com/docs/filtered-search#iterative-filtering
04
自动索引调优器(AutoIndex)
由于向量搜索本质上是近似搜索,如何权衡精度与效率显得尤为关键。AutoIndex 是 Zilliz Cloud (全托管的 Milvus 服务)中的机器学习优化器,能够自动调整索引参数,以达成召回率(recall)与性能之间的最优平衡。
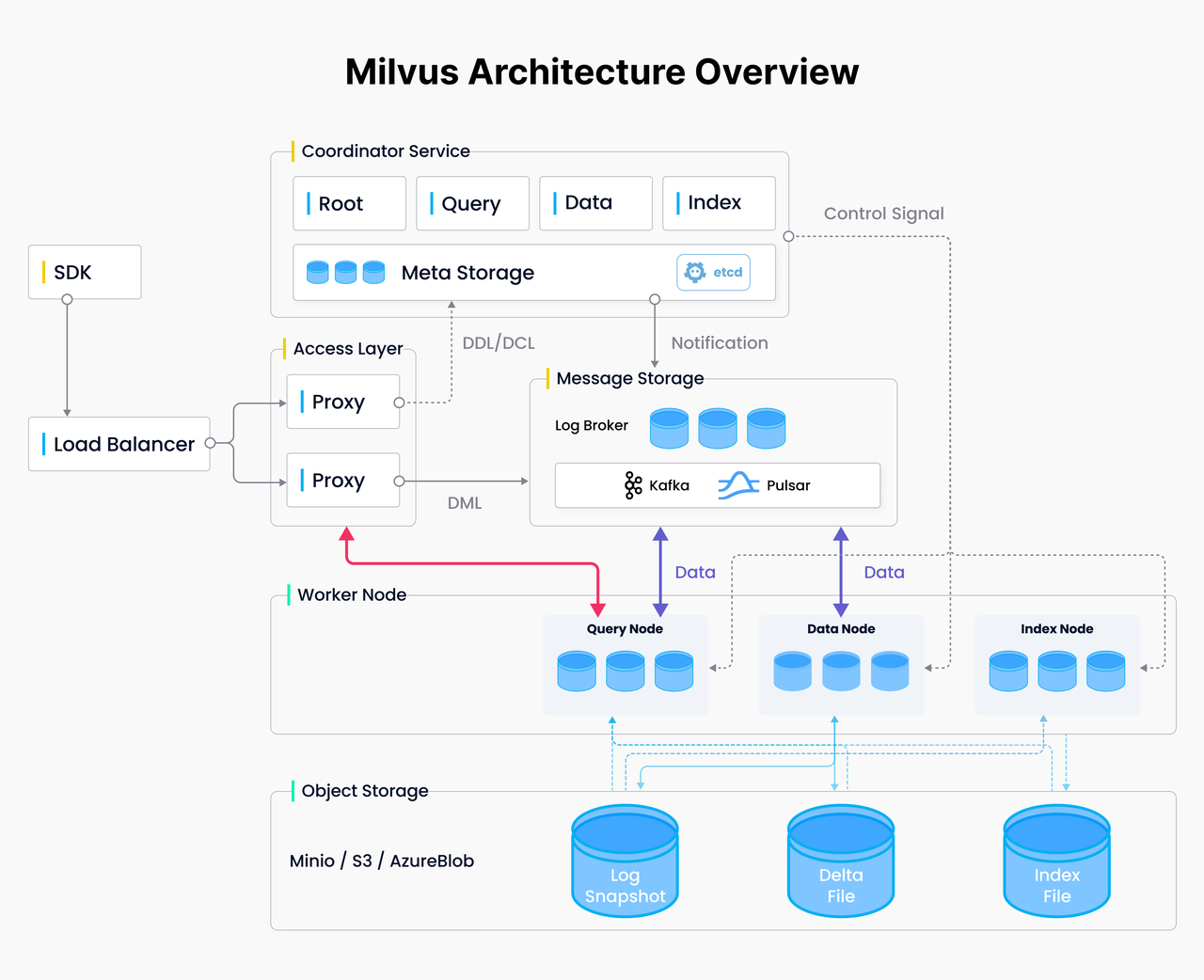
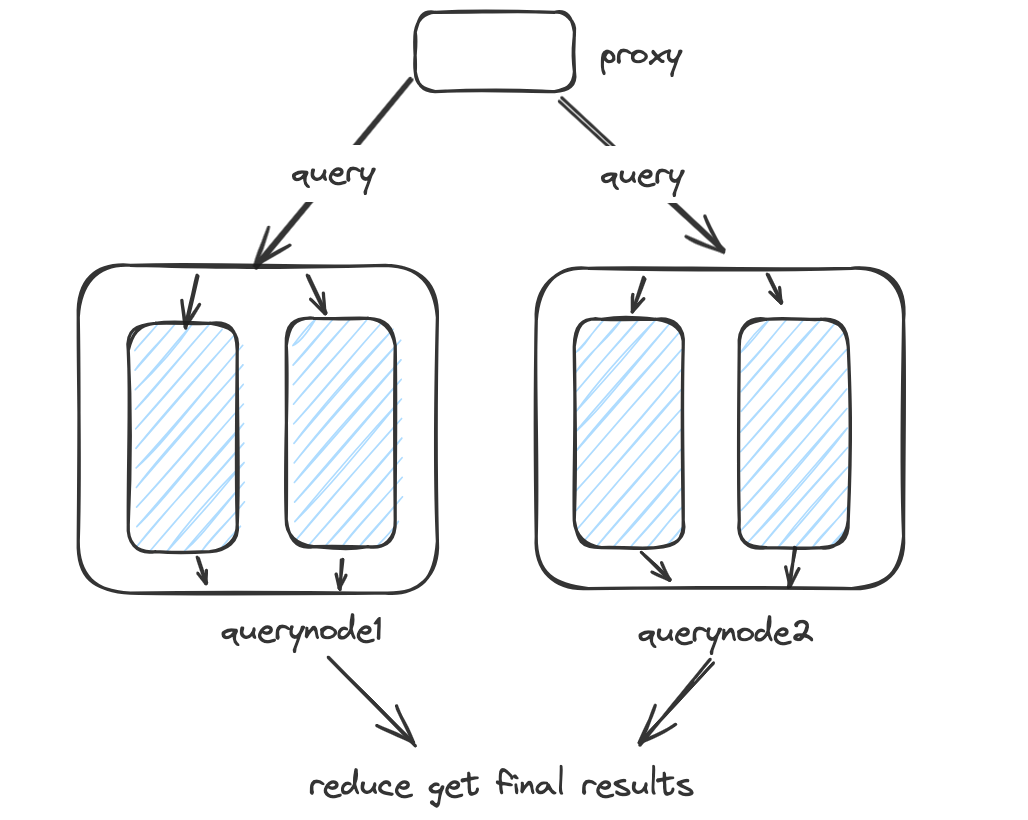
Milvus 查询流程如下:Proxy 将请求分发至多个 QueryNode,每个节点处理对应 Segment 的 局部TopK,最后合并结果。
由于 AutoIndex 拥有对 segment 级别统计信息的全面可见性,它能够区分过滤命中率高和过滤命中率低的 segment:
对于过滤率较低的 segment,会扩大查询范围,以提升召回;
对于过滤率较高的 segment,则会缩小查询范围,避免在大概率会被过滤的候选上浪费资源。
这些判断基于对过滤命中率和预期结果数量的统计建模。
但 AutoIndex 的作用不仅限于索引优化,它还会辅助选择最合适的过滤策略。通过解析过滤表达式并采样 segment 数据,它可以预估执行过滤所需的计算成本。如果发现过滤代价过高,它会自动切换为更高效的策略,如迭代式过滤(Iterative Filtering)。这种动态调整机制可以确保每条查询始终采用最适合的执行策略,实现性能与结果质量的双赢。
05
外部过滤(External Filtering)
在实际应用中,经常有这种一种情况:标量元数据体量庞大,且存储在向量数据库之外。例如,用户可能在关系型数据库中维护一些复杂的标签信息,同时使用向量数据库进行语义搜索。为了避免在向量数据库中冗余存储这部分非向量数据,客户端通常会在外部先对标量字段进行过滤,获取匹配的 ID,再用这些 ID 去过滤向量搜索结果。
可一旦当数据量达到数百万行以上时,传输大量 ID 就会极大占用网络带宽,而在 Milvus 中执行庞大的过滤表达式也会带来额外开销。
为了解决这一问题,我们引入了 External Filtering,这是一种轻量级的 SDK 层解决方案,基于搜索迭代器(search iterator)API 实现。用户可以定义一个自定义过滤函数,该函数会在每一批搜索结果上执行过滤判断。如果当前这批结果中有效命中数量不足,迭代器会自动继续拉取下一批结果,直到满足要求为止。
以下是在 pymilvus 中使用 External Filtering 的示例代码:
vector_to_search = rng.random((1, DIM), np.float32)
expr = f"10 <= {AGE} <= 25"
valid_ids = [1, 12, 123, 1234]
def external_filter_func(hits: Hits):
return list(filter(lambda hit: hit.id in valid_ids, hits))
search_iterator = milvus_client.search_iterator(
collection_name=collection_name,
data=vector_to_search,
batch_size=100,
anns_field=PICTURE,
filter=expr,
external_filter_func=external_filter_func,
output_fields=[USER_ID, AGE]
)
while True:
res = search_iterator.next()
if len(res) == 0:
search_iterator.close()
break
for i in range(len(res)):
print(res[i])
不过,与在 segment 级别迭代器上运行的 **迭代式过滤(Iterative Filtering) 不同,外部过滤(External Filtering) 是在全局查询层面上进行处理的。这种设计能够最大程度地减少元数据的评估操作,并避免在 Milvus 内部执行大规模过滤表达式,从而实现更轻量、更快速的端到端查询性能。
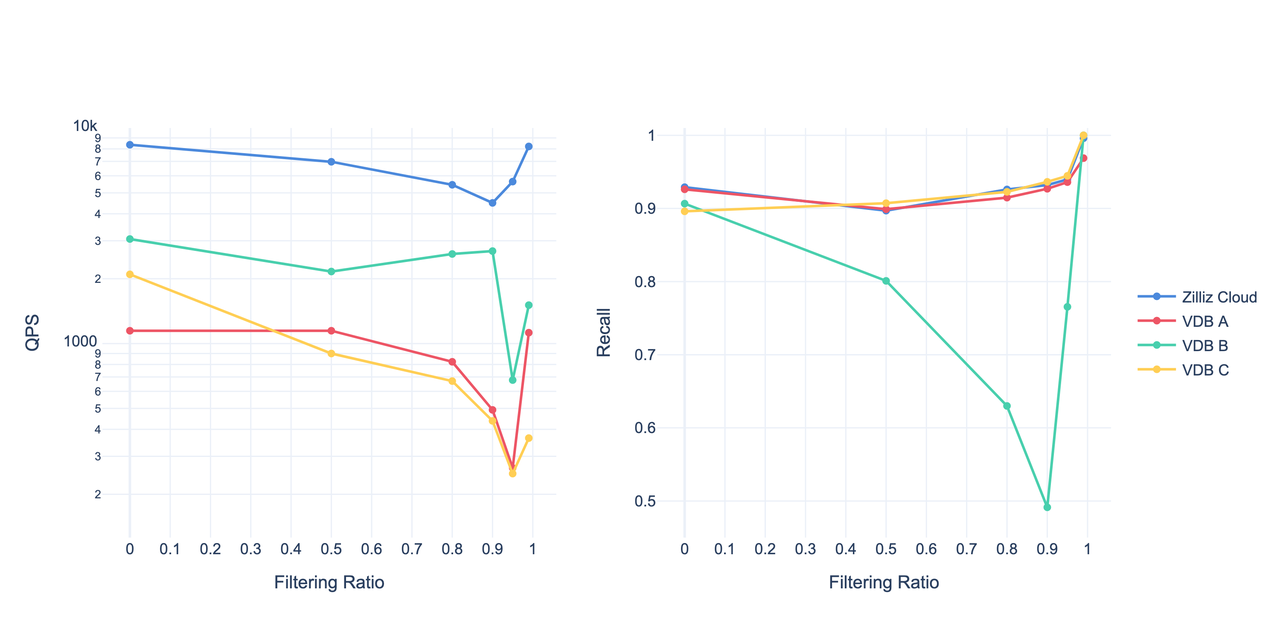
06 1000 美元预算下的对比测试
我们近期对多款向量数据库进行了基准测试,评估1000 美元云端预算内的最佳性能方案。
测试使用了 Cohere 1M 数据集,并通过开源基准测试工具 vdb-bench 模拟真实世界的过滤查询负载。参评的其他解决方案以“VDB A”、“VDB B”和“VDB C”匿名展示。
在有过滤和无过滤的多种场景下,Zilliz Cloud 在相同硬件资源条件下始终表现出最优的吞吐性能**,展现出卓越的处理能力和性价比。
总结
乍一看,带过滤条件的向量搜索似乎只是给查询加一个 filter 子句那么简单。但实际上,这背后是一个高度复杂的复杂系统工程,需要多维度的工程手段协同解决:
图索引优化:在保留图结构连通性的同时,有效管理被过滤的节点,避免孤岛
迭代式过滤:高效处理复杂的元数据过滤逻辑,用于复杂/开销大的过滤条件
AutoIndex:通过数据驱动的索引调优,在召回率和 QPS 之间动态平衡
External Filtering((外部过滤):优化 Milvus SDK,使过滤逻辑在客户端侧执行,减少大量数据传输,适用高效处理海量 ID 过滤
随着非结构化数据规模不断扩大,我们正持续突破向量数据库的性能边界,助力 Milvus 与 Zilliz Cloud 用户实现更快速、更可扩展的 AI 搜索。未来,我们还将引入更多数据库特性(如 Partition Key)进一步增强性能,敬请期待!
如果你在搜索性能方面遇到挑战,欢迎访问 milvus.io/community 与我们交流。