Skills 取代MCP?是agent落地最大的误解
不久前,在MCP推出一周年之际,Anthropic 发了篇博客,大意是MCP工具很好,但是会让大模型把大量token浪费在定义MCP工具上。
尤其遇到有大量中间工具的情况,这个情况会更明显:比如,把一个会议记录下载然后转存到另一个软件中,那么整个会议记录会被计算两次,token消耗会直接爆炸。
为了解决这个问题,Anthropic 推出了个新工具—— Claude Skills 。简单来说, Claude Skills 是一个Markdown 文件,里面有预先编写好的脚本、指令文档、资源,作用是告诉模型什么情况下调用,以及怎么执行某项任务。
如此一来,模型在决定如何调用工具之前,会先读取所有工具 Markdown 文件的YAML(只有几十token),然后决定是否对其进行调取。
那么问题来了,** Skills 会取代 MCP吗?很显然,答案是否定的。**
接下来,本文将对skills在内claude生态工具做一个详细解读,并附带Milvus体系内skills+MCP实操。
01
Skills是什么,解决了什么问题?
传统 AI Agent 的核心痛点在于指令会被遗忘。
即使你在 System Prompt 里写得再详细,随着对话轮次增加,Claude 也会逐渐忘记你的要求。
根源在于:传统 System Prompt 是一次性注入的静态指令,会和对话历史、文件内容一起竞争上下文窗口。当任务变复杂、对话变长时,这些指令的权重就会被稀释。
Skills 通过将专业技能封装为可复用、可管理、持久化的指令模板,在需要时自动激活,不用时不占用上下文,且始终保持一致性。
另外,Anthropic 很聪明的一点是,在做Skills 的时候,会让模型在先读取所有工具 Markdown 文件的YAML(只有几十token),然后决定是否对其进行调取。
如此一来,简单的目录读取替代完整且繁琐的上下文,能够让单个技能在启动时仅消耗 30-50 个 tokens,实现了极高的上下文效率。
 1.webp
1.webp
02
快速理解Skills、Prompts、Projects、Subagents、MCP之间关系
理解了 Skills 的本质(提示词模板)和工作机制(纯 LLM 推理),一个关键问题随之而来:Skills 和 MCP 在内其他工具是什么关系?它们会互相取代吗?
不难发现,现如今,模型上下文、调用工具标准多的让人眼花缭乱,仅仅是Anthropic 生态,就能分出Skills、Prompts、Projects、Subagents、MCP五大类型。
不久前Anthropic官方出了一个文档:Skills explained: How Skills compares to prompts, Projects, MCP, and subagents很好的解释了互相之间的关系与适用场景,核心内容总结如下:
(1)Skills:包含指令、脚本和资源的文件夹,会根据任务动态匹配加载,采用渐进式披露机制(先加载元数据,再按需加载完整内容和资源)。
适合场景:组织工作流(品牌指南、合规流程);专业领域技能(Excel 公式、数据分析);个人常用流程(笔记方法、编码模式);需跨对话重复使用的专业操作(如按 OWASP 标准做代码安全审查)。
(2)Prompts:对话中向 Claude 提供的自然语言指令,临时且仅在当前对话有效,无持久性。
适合场景:一次性请求(总结文章、格式化列表);对话式调整(优化语气、补充细节);即时上下文需求(分析特定数据、解读内容);临时指令(无需重复使用的单次操作)。
(3)Projects:独立工作区,含专属聊天记录和知识库,支持 200K 上下文窗口,超出限制时自动启用 RAG 模式扩展 10 倍容量。
适合场景:需持久上下文的项目(如产品 launch 相关的所有对话);工作区分类(不同 initiatives 分开管理);团队协作(共享知识库和对话历史,仅团队 / 企业版支持);项目专属规则(统一语气、分析视角)。
(4)Subagents:具备独立上下文窗口、自定义系统提示和工具权限的专门 AI 助手,可独立执行任务并反馈结果。
适合场景:专业任务分工(代码审查、测试生成、安全审计);上下文隔离(避免主对话杂乱);并行处理(多个子代理同时推进不同任务);工具权限控制(如仅授予只读权限)。
(5)MCP:模型上下文协议(Model Context Protocol),是连接 AI 应用与外部工具、数据源的开放式标准。
适合场景:访问外部数据(Google Drive、Slack、GitHub、数据库);使用业务工具(CRM 系统、项目管理平台);连接开发环境(本地文件、IDE、版本控制);集成自定义系统(企业专有工具和数据源)。
基于以上背景,可以发现Skills与MCP:它们解决完全不同的问题,且互为补充。
 2.webp
2.webp
以代码搜索为例:
MCP(如 claude-context):提供访问 Milvus 向量数据库的能力
Skills:规定优先展示最近修改的代码,按相关性排序,用 Markdown 表格呈现
一个提供能力,一个定义流程——两者缺一不可。
03
自定义 Skills 实操(以 claude-context 为例)
claude-context 是一个 MCP 插件,为 Claude Code 添加语义代码搜索功能,让整个代码库成为 Claude 的上下文。
环境准备
系统要求
Node.js >= 20.0.0 且 < 24.0.0
OpenAI API Key(用于嵌入模型)
Zilliz Cloud API Key(免费向量数据库)https://zilliz.com.cn/
3.1第一步:配置 MCP 服务(claude-context)
在终端中运行以下命令:
claude mcp add claude-context \ -e OPENAI_API_KEY=sk-your-openai-api-key \ -e MILVUS_ADDRESS=https://xxxxxxxxx-cn-hangzhou.cloud.zilliz.com.cn \ -e MILVUS_TOKEN=your-zilliz-cloud-api-key \ -e COLLECTION_NAME=medium_articles \ -- npx @zilliz/claude-context-mcp@latest
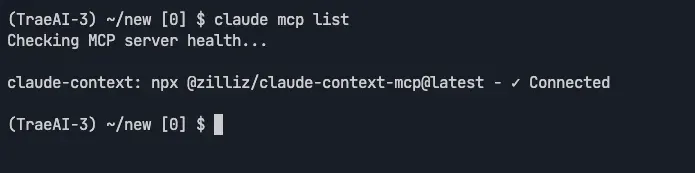
检查结果:
claude mcp list
 3.webp
3.webp
此时,MCP 已经配置完成。Claude 现在可以访问 Milvus 向量数据库了。
3.2第二步:创建 Skills
创建Skills 目录
mkdir -p ~/.claude/skills/milvus-code-searchcd ~/.claude/skills/milvus-code-search
创建 SKILL.md
---name: milvus-code-searchdescription: 专为 Milvus 代码库设计的语义代码搜索与架构分析技能---## Instructions当用户询问Milvus代码库相关问题时,我将:1. **代码搜索**:使用语义搜索在Milvus代码库中查找相关代码片段2. **架构分析**:分析Milvus的模块结构、组件关系和设计模式3. **功能解释**:解释特定功能的实现原理和代码逻辑4. **开发指导**:提供代码修改建议和最佳实践## Target Repository- **核心模块**: - `internal/` - 核心内部组件 - `pkg/` - 公共包和工具 - `client/` - Go客户端 - `cmd/` - 命令行工具## Usage Examples### 架构查询用户:Milvus的查询协调器是如何工作的?助手:[搜索querycoordv2相关代码] 让我为你分析Milvus查询协调器的工作原理...### 功能实现用户:Milvus是如何实现向量索引的?助手:[搜索index相关代码] Milvus的向量索引实现主要在以下几个模块...### 代码理解用户:这个函数的作用是什么?[指向具体代码]助手:[分析代码上下文] 根据Milvus代码库的上下文,这个函数主要负责...### 开发指导用户:如何为Milvus添加新的向量距离计算方法?助手:[搜索distance相关代码] 基于现有的实现模式,你可以按以下步骤添加...## Best Practices1. **精确搜索**:使用具体的技术术语和模块名称2. **上下文理解**:结合Milvus的整体架构理解代码片段3. **实用建议**:提供可操作的代码修改和优化建议4. **性能考虑**:关注Milvus作为高性能向量数据库的特殊需求---*专为Milvus开源向量数据库项目定制的代码搜索技能*
3.3第三步:重启 claude 生效 skills 并演示效果
claude
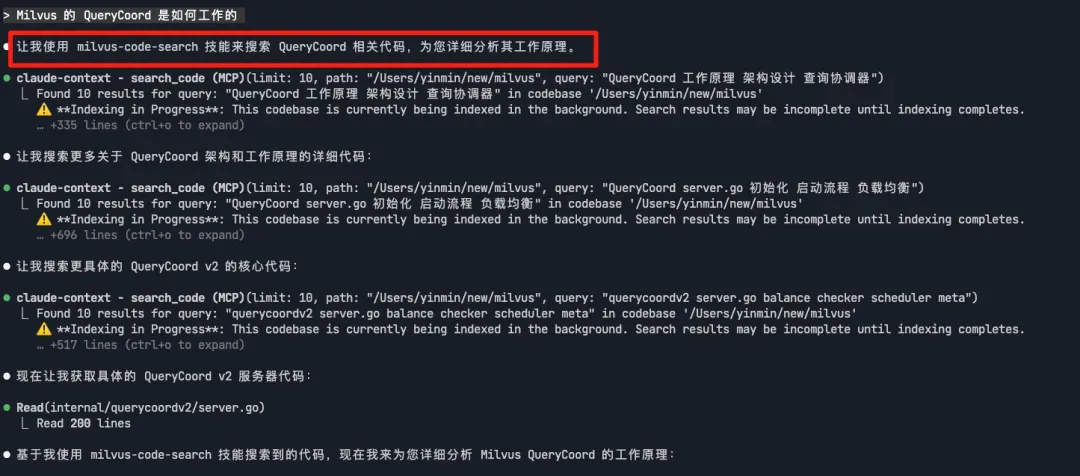
说明:配置完成后,我们可以直接使用 Skills 查询 Milvus 代码库:
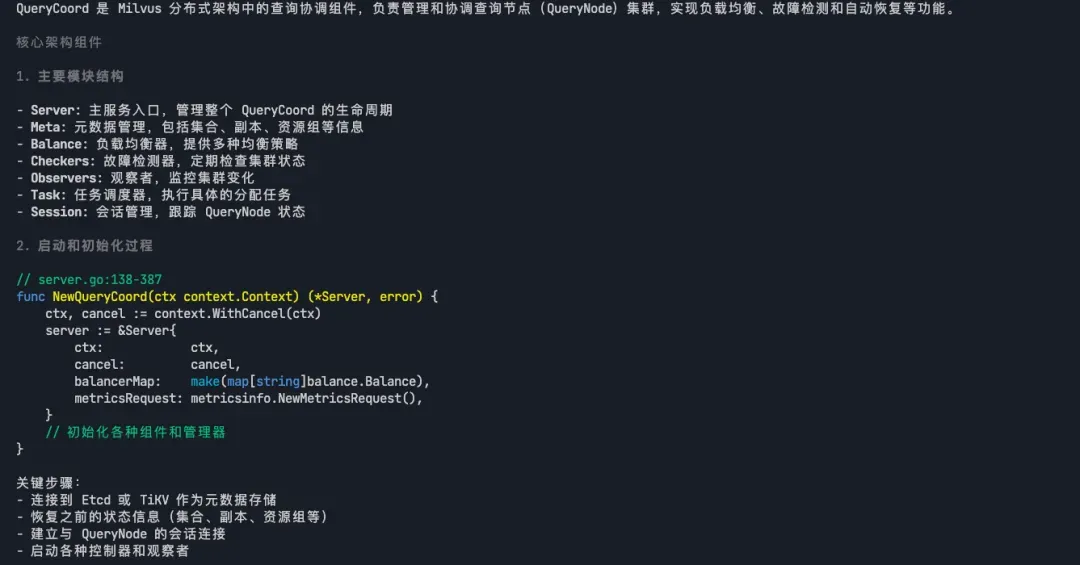
Milvus 的 QueryCoord 是如何工作的
 4.webp
4.webp
 5.webp
5.webp
 6.webp
6.webp
04
结尾
Skills 本质上是一种专业知识的封装与传递机制。通过 Skills,AI 可以继承团队的隐性经验、遵循行业的最佳实践。比如:代码审查的检查清单,可能是文档的撰写规范。把这些隐性知识显性化为 Markdown 文件,模型的输出质量会有质的提升。
长期来看,Skills积累能力,或许会成为每个人、每个团队是否能用好AI的核心差距来源。
 尹珉
尹珉Zilliz 黄金写手