



实用指南|如何使用 Milvus 将 JSON 数据向量化并进行相似性搜索
JSON,即 JavaScript 对象表示法,是用于服务器与 Web 应用间数据存储和交换的文本格式。其简单、灵活、兼容的特性使其在各行各业得到广泛应用,如物联网(IoT)设备和传感器都可通过 JSON 与 Web 界面顺畅交互。
然而,JSON 数据的层次结构虽然实用,但在存储、检索及数据分析时操作起来较为复杂。将 JSON 数据向量化能够提升数据处理、存储、检索及分析的效率,进而提高系统整体性能和操作便利性。
本文将介绍 Milvus 向量数据库如何有效简化 JSON 数据的向量化处理、数据摄取和相似性检索流程。同时,本文还将提供一份详细的操作指南,详解如何使用 Milvus 对 JSON 数据进行向量化、摄取数据及检索的具体步骤。
 截屏2024-08-08 16.37.40.png
截屏2024-08-08 16.37.40.png
如何使用 Milvus 优化 JSON 数据的向量化和检索
Milvus 是一款高度可扩展的开源向量数据库,可以管理大量的高维向量数据,非常适合检索增强生成(RAG)、语义搜索和推荐系统等应用。现在,让我们详细了解 Milvus 是如何促进高效处理和检索 JSON 数据的。
支持动态 Schema 的 JSON 数据
Milvus 支持在用户的 Collection 中无缝存储和查询 JSON 数据与向量数据。用户能够批量地高效插入 JSON 数据,并基于 JSON 字段中的值进行高级查询和筛选。这一功能对于那些需要动态调整 Schema的应用。
集成主流 Embedding 模型
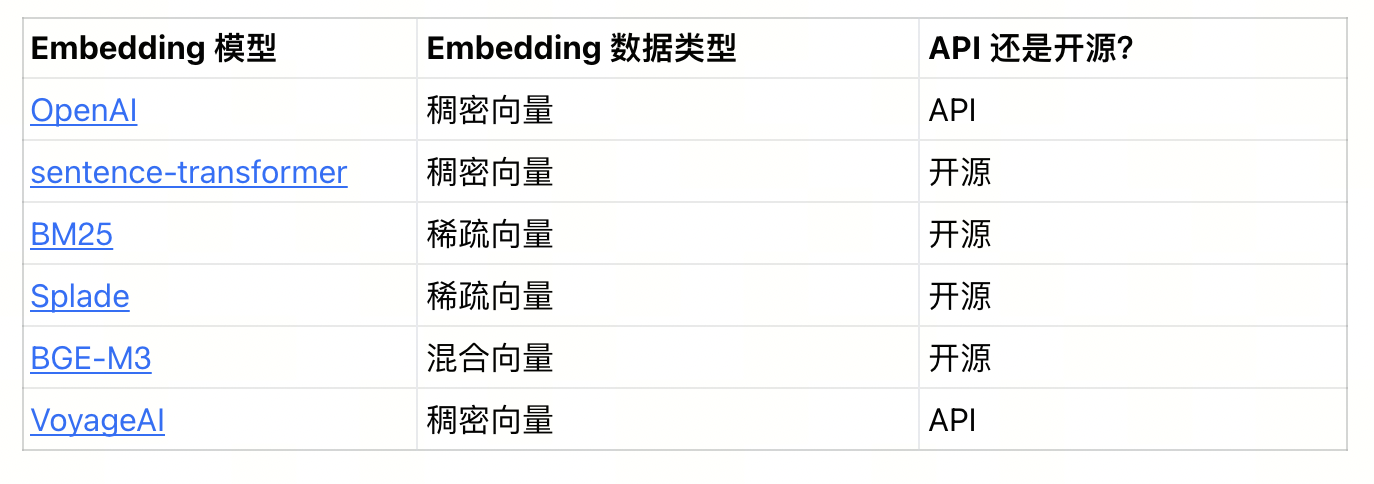
Milvus 通过其 Python SDK,即 PyMilvus,实现了与主流 Embedding 模型的集成,包括 OpenAI Embedding API、sentence-transformer、BM25、Splade、BGE-M3 和 VoyageAI。这种集成简化了向量数据的准备过程,降低了整个数据 Pipeline 的复杂性,而且开发人员也无需添加额外的数据处理层。
如何使用 Milvus 生成 Embedding 并进行相似性搜索
现在,我们将展示如何使用 Milvus 与主流 Embedding 模型的集成生成 Embedding 向量,并对 JSON 数据进行相似性搜索。所有完整代码,请参考 notebook。
步骤 1: 导入 JSON 数据
import json
Path to the JSON file
json_file_path = 'data.json'Load JSON datawith open(json_file_path, 'r') as file:
articles = json.load(file)
Display the data to ensure it's loaded correctly
print(articles)
- 导入 JSON 库:这行代码包括了 Python 的内置 JSON 库,用于处理 JSON 格式的数据。
- 设置 JSON 文件路径:这一步设置了您的 JSON 文件路径,假定文件名为 data.json。
- 加载并打印 JSON 数据:以读取模式打开 JSON 文件,将数据加载到名为 article 的变量中,并打印,以验证数据是否正确加载。使用 with 语句确保在数据读取后文件会自动关闭,这种方式既高效又安全。 数据的格式如下:
{
"title": "The Impact of Machine Learning in Modern Healthcare",
"content": "Machine learning is revolutionizing the healthcare industry by improving diagnostics and patient care. Techniques such as predictive analytics are being used to forecast patient outcomes, enhance personalized treatment plans, and streamline operations.",
"metadata": {
"author": "Jane Doe",
"views": 5000,
"publication": "HealthTech Weekly",
"claps": 150,
"responses": 20,
"tags": ["machine learning", "healthcare", "predictive analytics"],
"reading_time": 8
}
},...
我们将仅关注向量化“标题(title)”和“内容(content)”的过程。使用上述代码,我们已将数据中的两个字段向量化,并将它们保存为独立字段。以下是步骤分解:
- model = SentenceTransformerEmbeddingFunction('all-MiniLM-L6-v2'):这行代码用于加载 all-MiniLM-L6-v2 模型,该模型通过 PyMilvus 模型库进行预训练,可生成文本输入的稠密 Embedding 向量。
- article['title_vector'] = model.encode(article['title']) 和 article['content_vector'] = model.encode(article['content']):这几行代码用于将加载的 sentence-transformer 模型应用于每篇文章的标题和内容,将标题和内容编码为 Embedding 向量。encode 函数将文本信息转化为高维空间,其中语义相似的文本向量更为接近。这种转化对于许多依赖于理解文本底层语义的机器学习(ML)应用(如语义搜索、聚类和信息检索等)至关重要。
- print({key: articles[0][key] for key in articles[0].keys()}):这行代码用于打印出第一篇文章的所有键值对,包括为标题和内容生成的新向量。
- 输出展示了文本数据如何转换为 Embedding 向量并得到增强。我们不难发现,数据驱动应用又着丰富的数据结构。
步骤 3: 设置 Milvus
现在我们使用 Milvus 向量数据库管理文本数据转换而来的 Embedding 向量数据。
from pymilvus import connections, CollectionSchema, FieldSchema, DataType, Collection, utility
# Connect to Milvus
connections.connect(alias="default", host="localhost", port="19530")
# Define fields for the collection schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title_vector", dtype=DataType.FLOAT_VECTOR, dim=384),
FieldSchema(name="content_vector", dtype=DataType.FLOAT_VECTOR, dim=384)
]
# Create a collection schema
schema = CollectionSchema(fields, description="Article Embeddings Collection")
# Create the collection in Milvus
collection_name = "articles"if not utility.has_collection(collection_name):
collection = Collection(name=collection_name, schema=schema)
print(f"Collection '{collection_name}' created.")
else:
collection = Collection(name=collection_name)
print(f"Collection '{collection_name}' already exists.")
以下为代码详解:
-connections.connect(alias="default", host="localhost", port="19530"):这行代码用于连接至在本地机器(localhost)19530 端口运行的 Milvus 服务器。参数 alias="default" 表示此连接在后续操作中将作为默认连接使用。此步骤建立了应用程序与向量数据库之间的通信,连接后,我们就可以进行数据插入、查询和管理等操作。
FieldSchema 和 CollectionSchema:使用 FieldSchema 定义 Milvus 存储数据的字段。每个字段都扮演特定的角色:
- id:配置为主键的整数字段,并设置为自动为每个 Entity分配唯一标识符。
- title_vector 和 content_vector:这些字段存储浮点向量(FLOAT_VECTOR),分别代表文章标题和内容的 Embedding。dim=384 为这些 Embedding 向量的维度,需要与 Embedding 模型输出的向量维度匹配一致。
这些字段定义汇集成一个 CollectionSchema,基本描述了 Collection 中所有数据的结构和类型。
collection_name = "articles":这行代码用于设置 Collection 名称。
步骤 4: 插入数据
# Prepare the data for insertion
entities = [{
"title_vector": article['title_vector'],
"content_vector": article['content_vector']
} for article in articles]
# Insert the data into the collection
insert_result = collection.insert(entities)
print(f"Data inserted, number of rows: {len(insert_result.primary_keys)}")
步骤 5: 创建索引
索引是所有数据库管理系统中不可或缺的重要环节,因为索引可以直接提升搜索查询的性能。AI 应用尤其注重数据分析是否能够实时响应,因此需要使用索引来大幅提升搜索速度,从而提供最佳的用户体验。
# Define index parameters for title_vector and content_vector
index_params = {
"index_type": "IVF_FLAT", # Inverted File System, suitable for L2 and IP distances
"metric_type": "L2", # Euclidean distance
"params": {"nlist": 100} # Number of clusters
}
# Create an index on the 'title_vector' field
collection.create_index(field_name="title_vector", index_params=index_params)
print("Index created on 'title_vector'.")
# Create an index on the 'content_vector' field
collection.create_index(field_name="content_vector", index_params=index_params)
print("Index created on 'content_vector'.")
# Load the collection into memory for searching
collection.load()
print("Collection loaded into memory.")
通过对向量空间进行聚类,IVF_FLAT 索引减少了查询的搜索范围,在数据量特别大的情况下能显著提升搜索速度。最终,我们将 Collection 加载进内存以提升操作效率。使用 IVF_FLAT 索引类型,我们将向量空间分成 100 个簇,并选择 L2 (欧式距离)相似度类型,从而提升搜索效率和准确性。接着,在 title_vector 和 content_vector 字段上创建索引以加快检索任务的速度,并在每次创建索引后提供确认创建成功的信息。
步骤 6: 进行相似性搜索
# Define search parameters
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10}
}
# Assume using the first article's content vector for the query
query_vector = [entities[0]["content_vector"]]
# Execute the search on the 'content_vector' field
search_results = collection.search(
data=query_vector,
anns_field="content_vector",
param=search_params,
limit=5,
output_fields=["id"]
)
# Print search resultsfor hits in search_results:
for hit in hits:
print(f"Hit: {hit}, ID: {hit.id}")
这一步的开头,我们在 search_params 字典中定义搜索参数:
- 使用 L2 相似度类型计算向量间距离
- nprobe 设置为 10,以平衡搜索速度和精确度
我们使用第一篇文章的 content_vector 作为查询向量,搜索集合中内容相似的文章。Mivus 根据上述参数在 content_vector 字段上进行搜索。我们限制在结果中返回前 5 个最接近的向量及其 ID。
最后,打印每个搜索结果及其 ID 来迭代搜索结果。
总结
向量数据库优化了 JSON 数据的向量化和查询过程,实现了相似性搜索、复杂模式识别,并打破了传统数据库的限制。Milvus 向量数据库支持 JSON 数据的存储和检索,同时集成了主流 Embedding 模型。开发者能够轻松将 JSON 数据向量化,无需添加额外的技术栈,显著简化了开发过程。
此外,当不是每个文档都包含所有键时,JSON 数据会变得稀疏,导致向量中有许多零值,表示信息缺失或为空。这样一来,会形成一个复杂的高维向量空间,数据处理和查询变得更具挑战。Milvus 与 Embedding 模型的集成优化了数据结构和算法,能够有效管理稀疏的高维数据。Milvus 还支持动态 Schema,能够适应多种数据大小和类型,提升存储和查询复杂 JSON 结构的效率,开发人员也无需预处理 Collection Schema。



