



开源|十天1500+star,深度解读DeepSearcher核心技术架构
前言
【捷报速递】🔥不久前我们推出了DeepSearcher开源项目 ,十日狂揽1500 Stars!
感谢全球开发者和各位读者们的火热支持!
尝鲜链接:https://github.com/zilliztech/deep-searcher
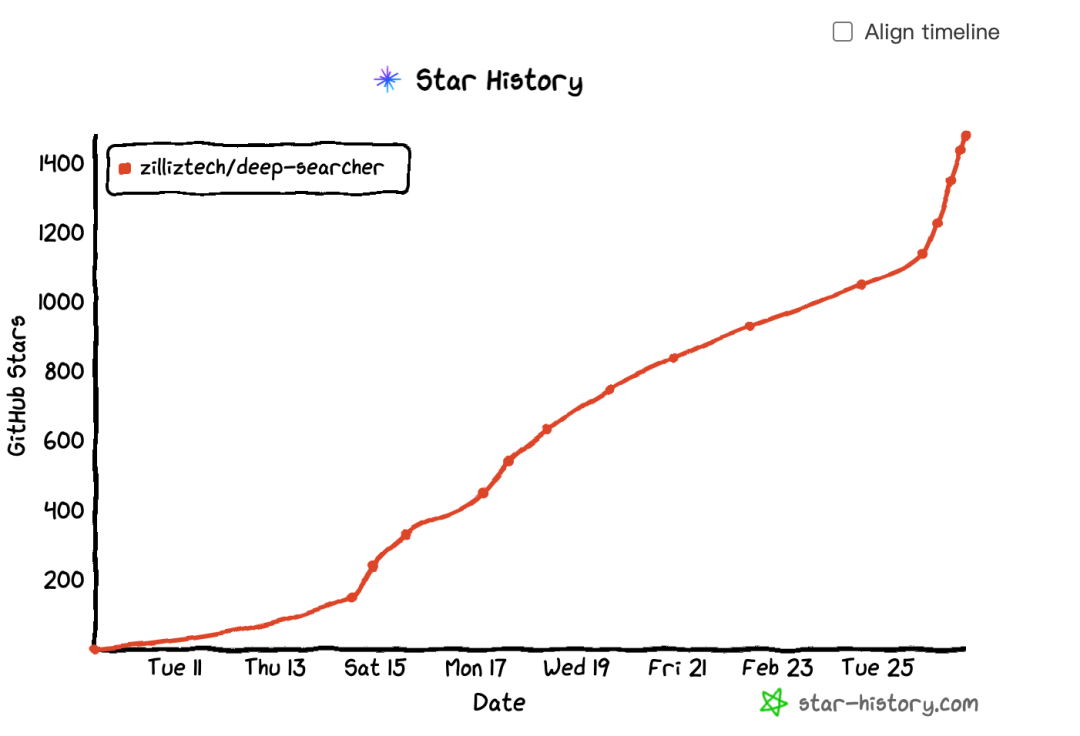 2.26-1.png
2.26-1.png
与此同时,我们的内容在hacknews上一经推出,也成功登顶TOP3关注。
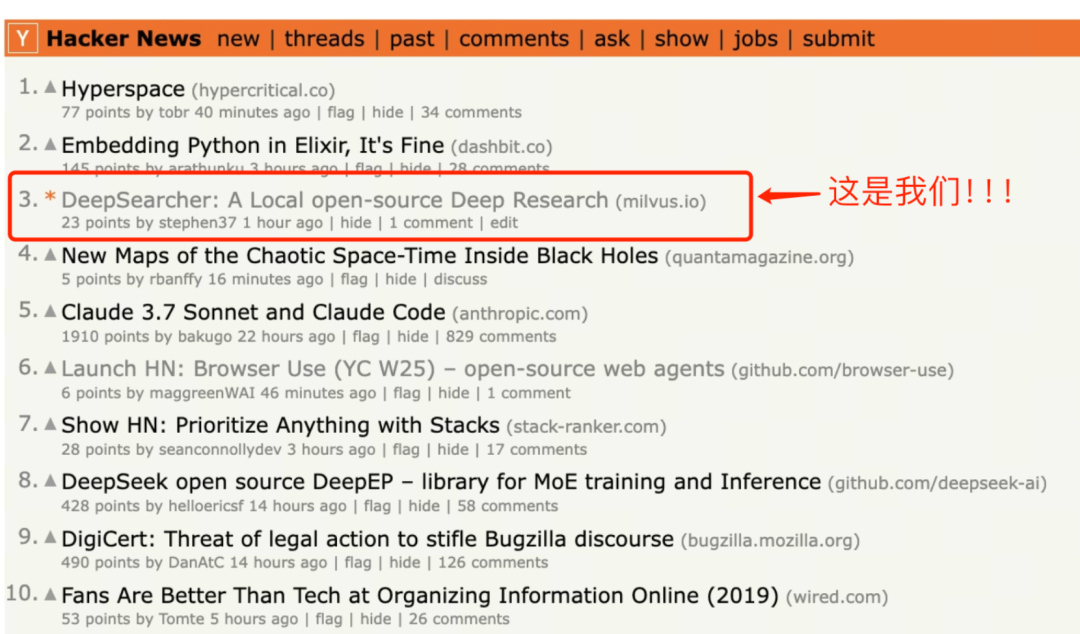 2.26-2.png
2.26-2.png
在社区中,我们也收获了很多的激烈讨论。
比如,很多开发者表示,相比OpenAI推出的报告生成神器DeepResearch,DeepSearcher通过引入本地知识库,以及灵活的大模型选择,更适合企业级部署。相比传统RAG,DeepSearcher的三大突破:智能查询路由、条件执行流程和混合检索机制,也十分让人惊喜。
但也有开发者提出了一些改进意见与质疑:
比如,DeepSearcher作为新一代RAG范式,算力成本较高,且推理的速度往往比较久,生成一份报告可能触发上千次LLM调用,导致推理带宽已成为核心瓶颈。
为此,在本篇文章中,我们将展示如何使用SambaNova定制的DeepSeek-R1推理模型,让整体的生成速度达到竞品的两倍。
(注:SambaNova作为美国AI芯片新锐,其SN40L芯片系统专为万亿参数模型设计,基于可重构数据流架构RDU打造。)
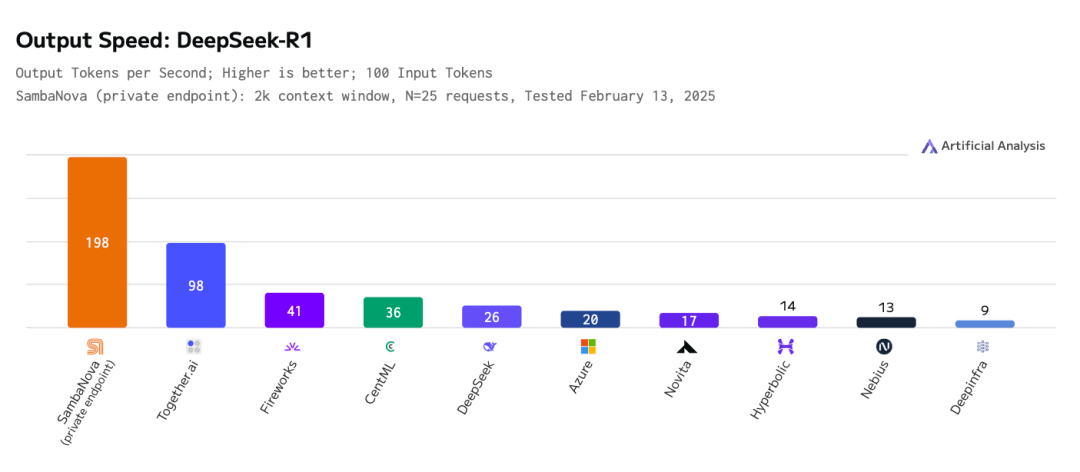 2.26-3.png
2.26-3.png
再比如,不同开发者的技术选型偏好不太一样,有人可能更倾向于Dify等平台做开发,那么要如何根据自己的偏好去复现DeepSearcher呢?
此前文章中,我们已经对DeepSearcher的核心思路做了解读。
戳这里阅读原文
和你一起进步的,公众号:Zilliz教你本地复现Deep Research:DeepSeek R1+ LangChain+Milvus
在本篇文章中,我们将通过代码实现和理论阐释,完整呈现DeepSearcher的工具调用、查询分解、推理链构建和结果反思等关键环节是何如运行的,助力您打造更符合需求的个性版DeepSearcher。
01
DeepSearcher 架构揭秘
DeepSearcher 的架构可以被分解为四个环节:定义/细化问题、研究、分析、综合,在此架构基础上,我们对其中一些细节做了重点改进。
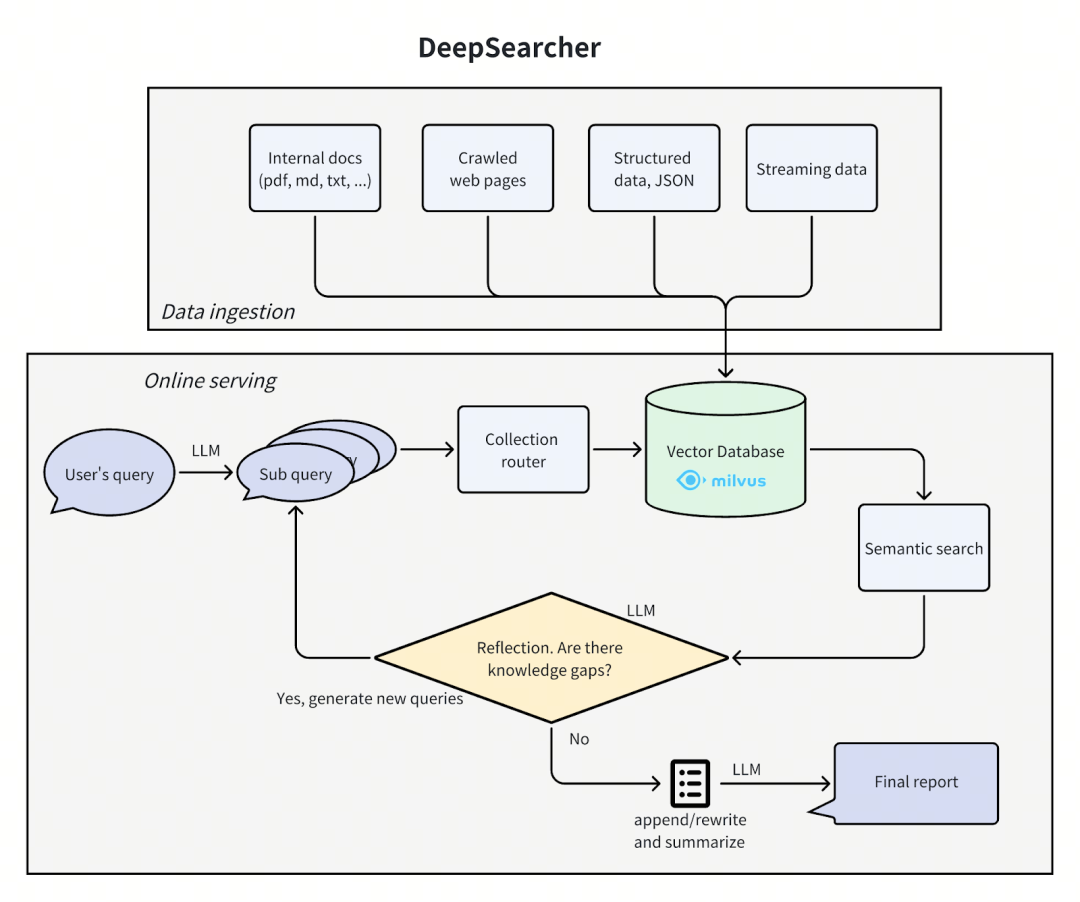 2.26-4.png
2.26-4.png
图:DeepSearcher架构
第一步:定义并细化问题
在 DeepSearcher 的设计中,我们会采用渐进式问题细化策略。
用户最初提出的查询首先会被分解为多个子查询。以查询“How has The Simpsons changed over time?”(辛普森一家随着时间的推移发生了什么变化?)为例,它生成的初始子查询如下文所示:
Break down the original query into new sub queries: [ 'How has the cultural impact and societal relevance of The Simpsons evolved from its debut to the present?', 'What changes in character development, humor, and storytelling styles have occurred across different seasons of The Simpsons?', 'How has the animation style and production technology of The Simpsons changed over time?', 'How have audience demographics, reception, and ratings of The Simpsons shifted throughout its run?']
研究过程中,系统将根据信息完备程度,动态调整问题框架。
第二步:研究与推理
在将查询分解为子查询之后,Agent 的研究推理就开始了。大致来说,这部分有四个步骤:路由决策、混合检索、反思和迭代优化。
(1)路由
我们的数据库包含来自不同来源的多个表格或集合。如果我们能够将语义搜索限制在与当前查询相关的那些来源上,效率将会更高。
以下是语义路由引擎动态选择数据源的示例:
def get_vector_db_search_prompt( question: str, collection_names: List[str], collection_descriptions: List[str], context: List[str] = None,): sections = [] # common prompt common_prompt = f"""You are an advanced AI problem analyst. Use your reasoning ability and historical conversation information, based on all the existing data sets, to get absolutely accurate answers to the following questions, and generate a suitable question for each data set according to the data set description that may be related to the question.
Question: {question}""" sections.append(common_prompt)
# data set prompt data_set = [] for i, collection_name in enumerate(collection_names): data_set.append(f"{collection_name}: {collection_descriptions[i]}") data_set_prompt = f"""The following is all the data set information. The format of data set information is data set name: data set description.
Data Sets And Descriptions:""" sections.append(data_set_prompt + "\n".join(data_set))
# context prompt if context: context_prompt = f"""The following is a condensed version of the historical conversation. This information needs to be combined in this analysis to generate questions that are closer to the answer. You must not generate the same or similar questions for the same data set, nor can you regenerate questions for data sets that have been determined to be unrelated.
Historical Conversation:""" sections.append(context_prompt + "\n".join(context))
# response prompt response_prompt = f"""Based on the above, you can only select a few datasets from the following dataset list to generate appropriate related questions for the selected datasets in order to solve the above problems. The output format is json, where the key is the name of the dataset and the value is the corresponding generated question.
Data Sets:""" sections.append(response_prompt + "\n".join(collection_names))
footer = """Respond exclusively in valid JSON format matching exact JSON schema.
Critical Requirements:- Include ONLY ONE action type- Never add unsupported keys- Exclude all non-JSON text, markdown, or explanations- Maintain strict JSON syntax""" sections.append(footer) return "\n\n".join(sections)
我们可以让大语言模型(LLM)以 JSON 格式返回结构化输出,以便能轻松地将其输出内容转化为关于下一步行动的决策。
(2)混合检索
选定了各种数据源后,搜索步骤我们可以使用 Milvus 进行相似度搜索。与市面上常见的DeepResearch复现方案类似,源数据已经被预先进行了分块、向量化处理,并存储在向量数据库中。
对于 DeepSearcher 而言,有了本地和指定范围的在线检索数据源,大模型就不会做漫无目的的全网检索,更加高效便捷。
(3)反思
与市面上常见的Deep Research复现方案不同的是,DeepSearcher还引入了 动态反思形式,即将先前的输出作为上下文输入到一个提示中,通过多轮问答识别信息盲区:
以下是创建该提示的方法:
def get_reflect_prompt( question: str, mini_questions: List[str], mini_chuncks: List[str],): mini_chunk_str = "" for i, chunk in enumerate(mini_chuncks): mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n""" reflect_prompt = f"""Determine whether additional search queries are needed based on the original query, previous sub queries, and all retrieved document chunks. If further research is required, provide a Python list of up to 3 search queries. If no further research is required, return an empty list.
If the original query is to write a report, then you prefer to generate some further queries, instead return an empty list.
Original Query: {question} Previous Sub Queries: {mini_questions} Related Chunks: {mini_chunk_str} """
footer = """Respond exclusively in valid List of str format without any other text.""" return reflect_prompt + footer
然后,我们让大语言模型(LLM)返回结构化输出,这次输出是以可被 Python 解释的数据形式呈现。
以下是在回答了上述初始子查询后,通过反思 “发现” 的新子查询示例:
New search queries for next iteration: [ "How have changes in The Simpsons' voice cast and production team influenced the show's evolution over different seasons?", "What role has The Simpsons' satire and social commentary played in its adaptation to contemporary issues across decades?", 'How has The Simpsons addressed and incorporated shifts in media consumption, such as streaming services, into its distribution and content strategies?']
(4)迭代优化
相比市面上常见的DeepResearch复现方案,DeepSearcher还采用智能循环控制策略,当反思模块检测到信息缺口时,会不断自动触发新一轮研究,直到大模型判定可以退出循环并生成报告。
以我们前面查询的"辛普森一家"为例,系统通过两轮迭代补充了配音团队变迁、流媒体适配策略等深度信息。
第三步阶段:结构化综合
最后一阶段,大模型会基于拆解后的子问题,以及对应的检索到的数据对其进行综合,生成一份完整的报告。以下是创建该提示的代码:
def get_final_answer_prompt( question: str, mini_questions: List[str], mini_chuncks: List[str],): mini_chunk_str = "" for i, chunk in enumerate(mini_chuncks): mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n""" summary_prompt = f"""You are an AI content analysis expert, good at summarizing content. Please summarize a specific and detailed answer or report based on the previous queries and the retrieved document chunks.
Original Query: {question} Previous Sub Queries: {mini_questions} Related Chunks: {mini_chunk_str} """ return summary_prompt
这种方法相较于早期简单拼接式方案,实现了三大提升:
信息去重:通过全局上下文感知消除内容冗余
逻辑验证:自动检测论点矛盾
风格统一:保持全篇叙述连贯性
02
结果展示
以下是使用 DeepSeek-R1,通过以 Simpsons 的维基百科页面作为源材料,针对问题 “How has The Simpsons changed over time?” 生成的报告中的一个示例:
Report: The Evolution of The Simpsons (1989–Present)1. Cultural Impact and Societal RelevanceThe Simpsons debuted as a subversive critique of American middle-class life, gaining notoriety for its bold satire in the 1990s. Initially a countercultural phenomenon, it challenged norms with episodes tackling religion, politics, and consumerism. Over time, its cultural dominance waned as competitors like South Park and Family Guy pushed boundaries further. By the 2010s, the show transitioned from trendsetter to nostalgic institution, balancing legacy appeal with attempts to address modern issues like climate change and LGBTQ+ rights, albeit with less societal resonance.…ConclusionThe Simpsons evolved from a radical satire to a television institution, navigating shifts in technology, politics, and audience expectations. While its golden-age brilliance remains unmatched, its adaptability—through streaming, updated humor, and global outreach—secures its place as a cultural touchstone. The show’s longevity reflects both nostalgia and a pragmatic embrace of change, even as it grapples with the challenges of relevance in a fragmented media landscape.
完整报告可参考
(https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view)
以下是使用 GPT-4o mini 的 DeepSearcher 的报告对比(https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view)。
03
尾声
总结来说, DeepSearcher (https://github.com/zilliztech/deep-searcher)作为最新研究型RAG的开源实践,成功验证了条件执行流、混合路由等创新理念。
此外,在此架构中,我们可以通过接入SambaNova等云端接口,自由选择DeepSeek-R1等推理服务(单次查询调用DeepSeek-R1 推理服务 65 次,消耗2.5万输入/2.2万输出token,成本0.3美元),可以实现从本地丐版的量化模型到满血DeepSeek大模型的跨越式升级。
当然,除了DeepSeek,DeepSearcher 还可以与大多数推理服务配合使用,比如 OpenAI、Gemini、DeepSeek 以及 Grok 3。
接下来,我们还将对其以下能力进行重点突破:
多模态研究能力集成
动态视角切换机制
自动化质量评估体系
诚邀开发者体验DeepSearcher(https://github.com/zilliztech/deep-searcher),您的Star与反馈将助力开源社区持续进化!


