



多智能体系统中,如何用向量数据库共享上下文?OpenAgents x Milvus
今年以来,围绕到底是单一agent好,还是多agent协作更优这个话题,行业已经反反复复吵了好几轮。
通常来说,面对简单问题,采用react模式的单一agent就能搞定。可遇到复杂问题,单一agent就会立刻出现包括但不限于以下问题:
串行执行效率低:无法同时完成并行的子步骤(如 “同时爬取 A、B 两个网站的数据”)。
长任务推理链易断裂:任务步骤超过窗口容量时,早期推理结果被遗忘,导致逻辑断层。
工具调用能力有限:单一 Agent 可调用工具太多,反而导致输出效果下滑。
但是落地多agent系统吧,又会出现新的问题,如何编排多个agent之间的规则之外,agent一多上下文就多,而上下文一旦太长,大模型的输出效果可能就崩掉了?
如何解决单agent系统能力有限,而多agent编排复杂、上下文过长的缺陷?
本文将以OpenAgents x Milvus为代表,解读这一问题。
01 现状分析:为什么agent协作需要分布式
当前主流的 AI Agent 框架(LangChain、AutoGen、CrewAI 等)普遍采用任务封闭型架构,即围绕单一任务或预定义工作流构建 Agent 系统。这种设计模式在实际应用中暴露出三个结构性问题:
1. 知识隔离问题
Agent 的知识和经验被限制在单一部署实例内,无法跨系统复用。例如,研发部门的代码审查 Agent 无法为产品团队提供技术可行性评估,导致知识资产重复建设。
2. 协作刚性问题
即便在 Multi-Agent 框架中,Agent 间的协作也依赖于预先定义的工作流。这种静态编排方式无法应对动态变化的协作需求,限制了系统的适应性。
3. 状态持久化缺失
传统 Agent 采用"启动-执行-销毁"的生命周期模型,无法在多次交互中积累上下文和关系网络。每次会话都是独立的,缺乏长期记忆能力。
这些问题源于将 Agent 定位为任务执行工具而非协作主体,忽视了 Agent 系统的网络效应和涌现特性。
也是因此,在OpenAgents 团队在看来:当前的Agent不止需要更强的大脑,也需要一个高效的协作机制,让agent之间能够发现同伴、建立关系、共享知识、协同工作。
但是这种高效协作不应该是中心化的,而是应该采用互联网一样的分布式框架。因此,OpenAgents 的设计中,不存在一个用于编排一切的总控制器。
02 核心架构:三层协作模型
理解了 OpenAgents 的核心理念后,让我们看看它是如何在技术层面实现这个愿景的。整个架构可以拆解为三个递进的层次:
 11-2-1.webp
11-2-1.webp
1.Agent Network:协作空间抽象
Agent Network 是持久化的协作单元,核心特性:
持久化运行:独立于单个任务的生命周期,Network 创建后持续在线
动态加入:Agent 通过 Network ID 接入,无需预注册
多协议支持:统一的抽象层之上支持 WebSocket、gRPC、HTTP、libp2p
自治配置:每个 Network 拥有独立的权限、治理规则和资源配额
一行代码启动一个 Network,任意 Agent 可通过标准接口加入协作。
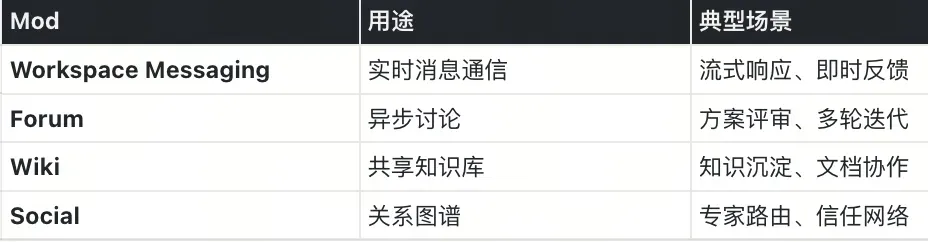
2.Mods:可插拔协作能力
Mods 是插件化的协作能力层,将协作模式从核心系统解耦。开发者可根据场景组合不同 Mods:
 11-1-1.webp
11-1-1.webp
Mods 基于统一的事件系统,可自定义扩展。
3.Protocol-Agnostic:传输层
支持异构 Agent 互联互通的关键在于多协议适配层:
HTTP/REST:通用跨语言集成
WebSocket:低延迟双向通信
gRPC:高性能 RPC,适合大规模集群
libp2p:P2P 去中心化传输
A2A:新兴的 Agent-to-Agent 专用协议
协议之间通过统一的消息格式(基于事件模型)实现无缝转换。开发者无需关心对端使用何种协议,框架自动处理适配。任何语言、任何框架开发的 Agent,都能接入 OpenAgents 网络,无需重构现有代码。
03 向量数据库集成:基于 Milvus 的记忆系统
OpenAgents 已经解决了 Agent 的通信和协作问题,但协作产生的知识如何沉淀和复用?这就需要一个高性能的记忆层。
Milvus 为 Agent Network 提供持久化的语义检索能力,具备三个关键特性:
1. 语义化检索
基于向量相似度(支持 HNSW、IVF_FLAT 等算法),识别语义相近的历史记录,避免 Agent 重复回答相似问题。
2. 高性能扩展
- 支持数十亿级向量存储
- Top-K=100 查询延迟 < 10ms(P99)
- 分布式架构,线性扩展
3. 多租户隔离
通过 Partition Key 实现逻辑隔离,不同项目组拥有独立记忆空间。相比创建多个 Collection,性能开销更低且支持跨租户检索。
集成方式:OpenAgents 通过 Memory Mod 调用 Milvus API,Agent 消息自动向量化并存储。开发者可自定义 Embedding 模型和检索策略。
04 实现案例:多 Agent 技术问答系统
让我们通过一个实际案例,看看如何将 Milvus 集成到 OpenAgents 中,构建一个具备长期记忆的技术问答 Agent Network。
目标:我们要构建一个技术支持社区,其中有多个专业 Agent(Python 专家、数据库专家、DevOps 专家等)协作回答开发者问题。
环境准备
python3.11+
conda
Openai-key
1.定义依赖
说明:定义项目所需的 Python 包
# 核心框架
openagents>=0.6.11
# 向量数据库
pymilvus>=2.5.1
# 嵌入模型
sentence-transformers>=2.2.0
# LLM集成
openai>=1.0.0
# 环境配置
python-dotenv>=1.0.0
2.环境变量
说明:提供环境变量配置模板
# LLM配置 (必填)
OPENAI_API_KEY=your_openai_api_key_here
OPENAI_BASE_URL=https://api.openai.com/v1
OPENAI_MODEL=gpt-4o
# Milvus配置
MILVUS_URI=./multi_agent_memory.db
# 嵌入模型配置
EMBEDDING_MODEL=text-embedding-3-large
EMBEDDING_DIMENSION=3072
# 网络配置
NETWORK_HOST=localhost
NETWORK_PORT=8700
STUDIO_PORT=8050
3.openagents 网络配置
说明:定义 Agent 网络的结构和通信配置
# 网络传输协议(HTTP 8700端口)
# 多频道消息系统(general、coordination、专家频道)
# Agent角色定义(coordinator、python_expert等)
# Milvus集成配置
network:
name: "Multi-Agent Collaboration Demo"
transports:
- type: "http"
config:
port: 8700
host: "localhost"
mods:
- name: "openagents.mods.workspace.messaging"
config:
channels:
- name: "general" # 用户提问频道
- name: "coordination" # 协调者频道
- name: "python_channel" # Python专家频道
- name: "milvus_channel" # Milvus专家频道
- name: "devops_channel" # DevOps专家频道
agents:
coordinator:
type: "coordinator"
description: "协调者Agent,负责任务分析和专家协调"
channels: ["general", "coordination"]
python_expert:
type: "expert"
domain: "python"
channels: ["python_channel", "coordination"]
4.实现多个专业 Agent 的协作
说明:部分核心代码示例(不包含完整代码)
# SharedMemory: Milvus向量数据库共享记忆系统
# CoordinatorAgent: 协调者Agent,负责任务分析和专家调度
# PythonExpertAgent: Python技术专家
# MilvusExpertAgent: Milvus运维专家
# DevOpsExpertAgent: 运维专家
import os
import asyncio
import json
from typing import List, Dict
from dotenv import load_dotenv
from openagents.agents.worker_agent import WorkerAgent
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
import openai
load_dotenv()
class SharedMemory:
"""所有Agent共享的Milvus记忆系统"""
def __init__(self):
connections.connect(uri="./multi_agent_memory.db")
self.setup_collections()
self.openai_client = openai.OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL")
)
def setup_collections(self):
"""创建记忆集合:专家知识库、协作历史、问题解决方案"""
collections = {
"expert_knowledge": "专家知识库",
"collaboration_history": "协作历史",
"problem_solutions": "问题解决方案"
}
# 创建向量集合的代码...
async def search_knowledge(self, query: str, collection_name: str):
"""搜索相关知识"""
# 向量搜索实现...
async def store_knowledge(self, agent_id: str, content: str, metadata: dict, collection_name: str):
"""存储知识"""
# 存储到向量数据库...
class CoordinatorAgent(WorkerAgent):
"""协调者Agent - 分析问题并协调其他Agent"""
def __init__(self):
super().__init__(agent_id="coordinator")
self.expert_agents = {
"python": "python_expert",
"milvus": "milvus_expert",
"devops": "devops_expert"
}
async def analyze_question(self, question: str) -> List[str]:
"""分析问题需要哪些专家"""
keywords = {
"python": ["python", "django", "flask", "异步"],
"milvus": ["milvus", "向量", "索引", "性能"],
"devops": ["部署", "docker", "kubernetes", "运维"]
}
# 关键词匹配逻辑...
return needed_experts
async def coordinate_experts(self, question: str, needed_experts: List[str]):
"""协调专家Agent协作"""
# 1. 通知专家开始协作
# 2. 向各专家发送任务
# 3. 收集专家响应
# 4. 返回专家意见
async def on_channel_post(self, context):
"""处理用户问题的主要逻辑"""
content = context.incoming_event.payload.get('content', {}).get('text', '')
if content and not content.startswith('🎯'):
# 1. 分析问题 → 2. 协调专家 → 3. 整合答案 → 4. 回复用户
class PythonExpertAgent(WorkerAgent):
"""Python专家Agent"""
async def analyze_python_question(self, question: str) -> str:
"""分析Python问题并提供专业建议"""
# 1. 搜索相关经验
# 2. 调用LLM生成专家意见
# 3. 存储到协作历史
return answer
**启动所有Agent**
async def run_multi_agent_demo():
coordinator = CoordinatorAgent()
python_expert = PythonExpertAgent()
milvus_expert = MilvusExpertAgent()
devops_expert = DevOpsExpertAgent()
# 连接到OpenAgents网络
await coordinator.async_start(network_host="localhost", network_port=8700)
# ... 启动其他Agent
while True:
await asyncio.sleep(1)
if __name__ == "__main__":
asyncio.run(run_multi_agent_demo())
5.创建激活虚拟环境
conda create -n openagents
conda activate openagents
5.1安装依赖
pip install -r requirements.txt
5.2配置 API 密钥
cp .env.example .env
5.3启动 OpenAgents 网络
openagents network start .
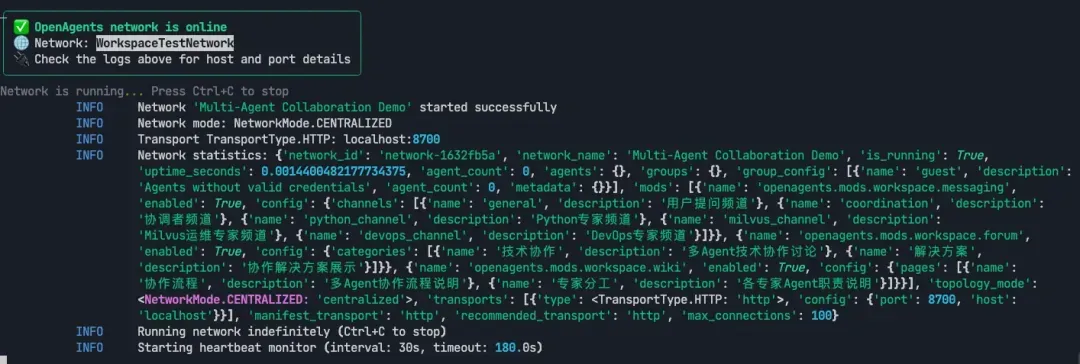 11-0-1.webp
11-0-1.webp
5.4启动 muilt-agent 服务
python multi_agent_demo.py
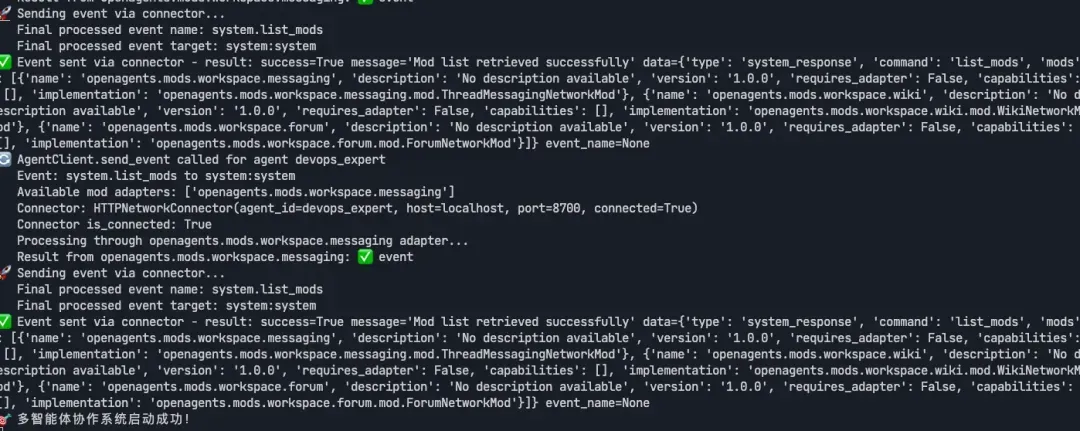 11-0-2.webp
11-0-2.webp
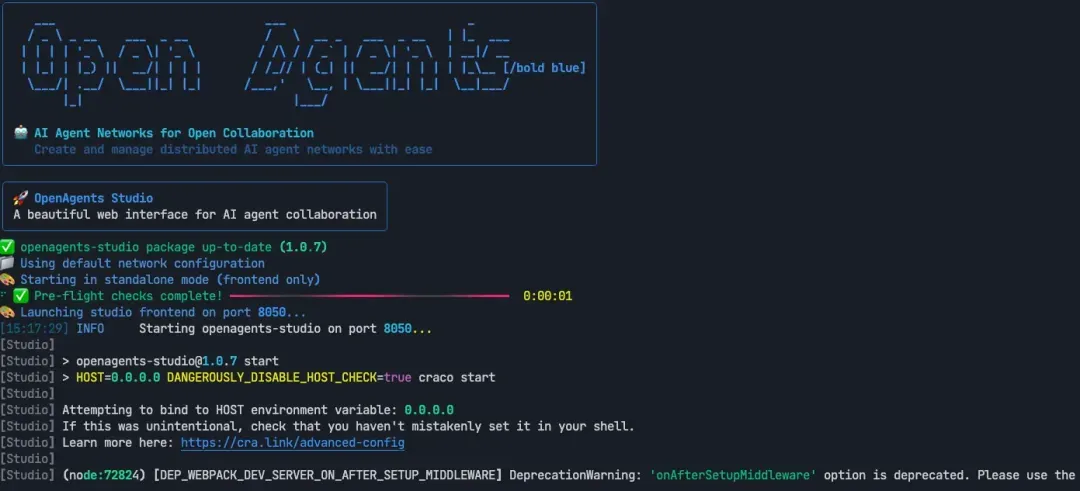
5.5启动 stuido
openagents studio -s
 11-0-3.webp
11-0-3.webp
5.6访问stuido
http://localhost:8050
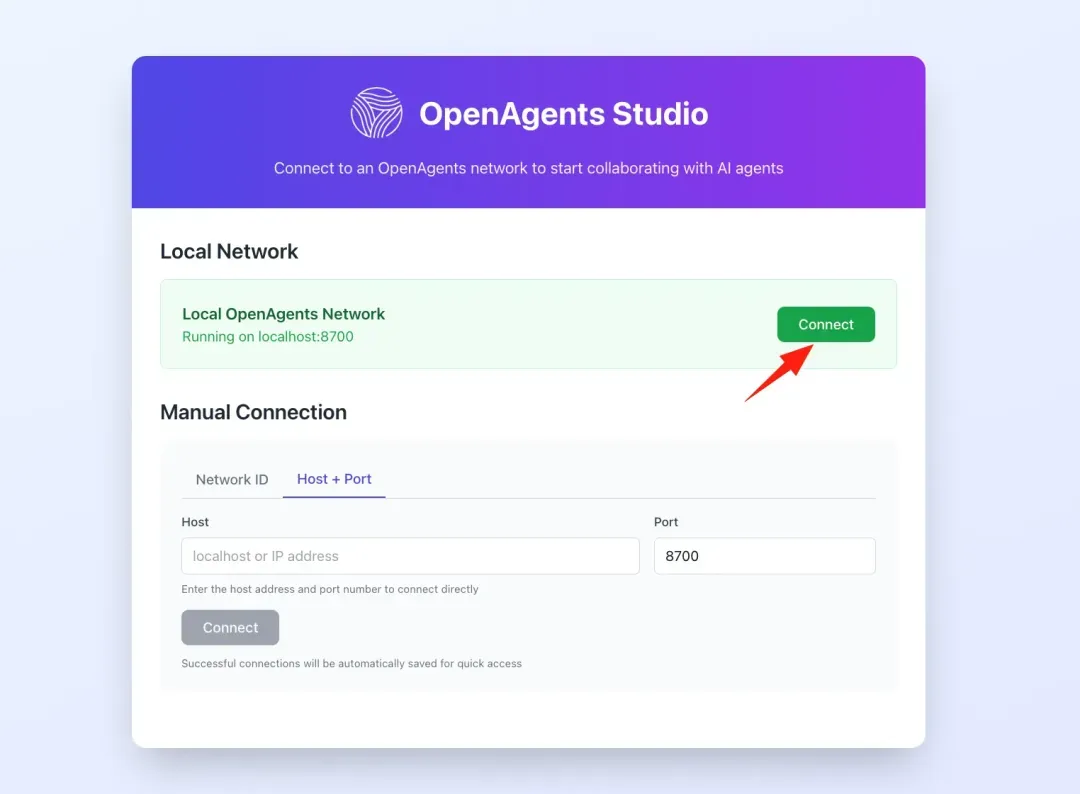 11-0-4.webp
11-0-4.webp
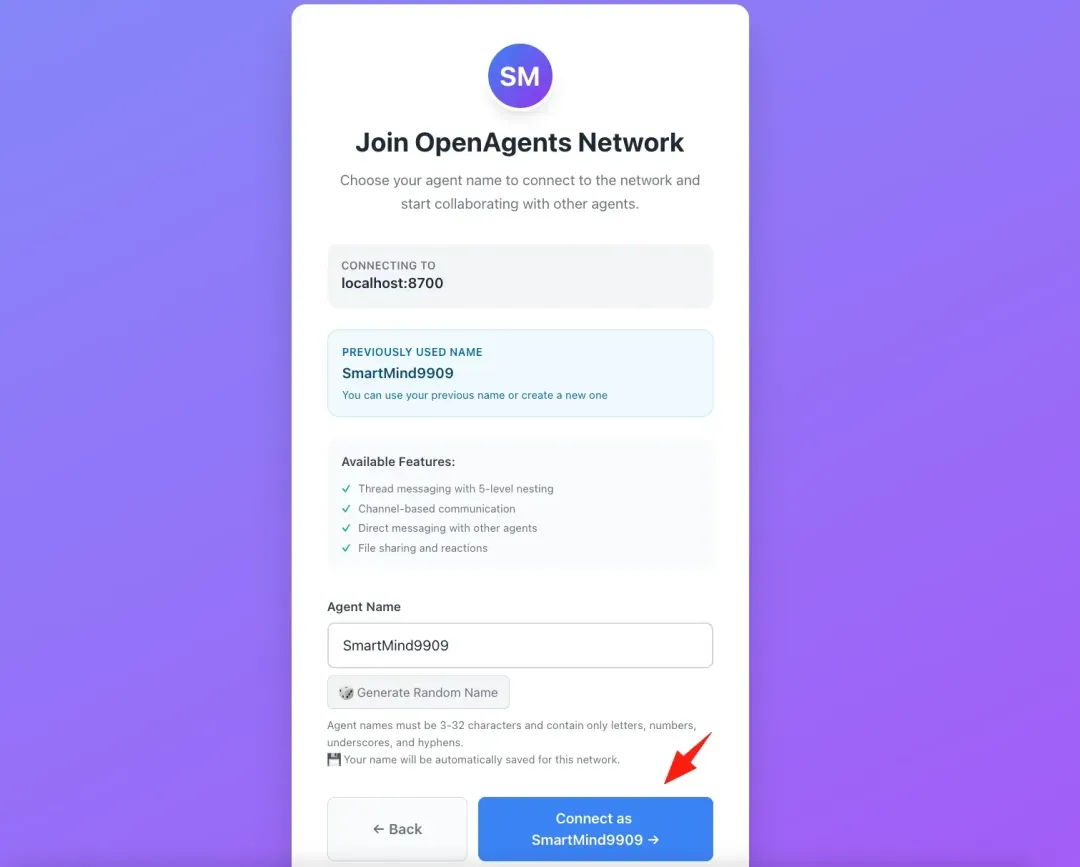 11-0-5.webp
11-0-5.webp
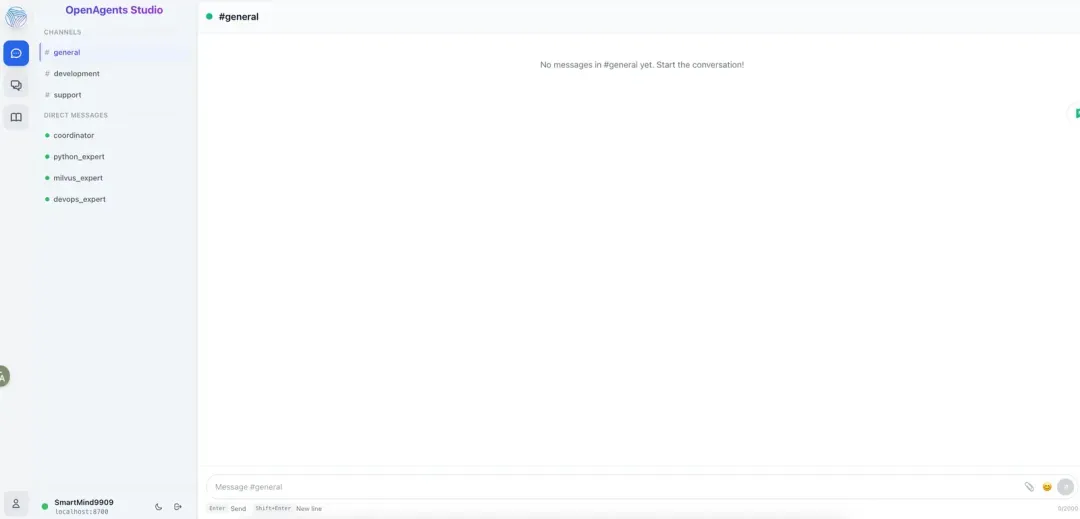 11-0-6.webp
11-0-6.webp
5.7检查服务状态
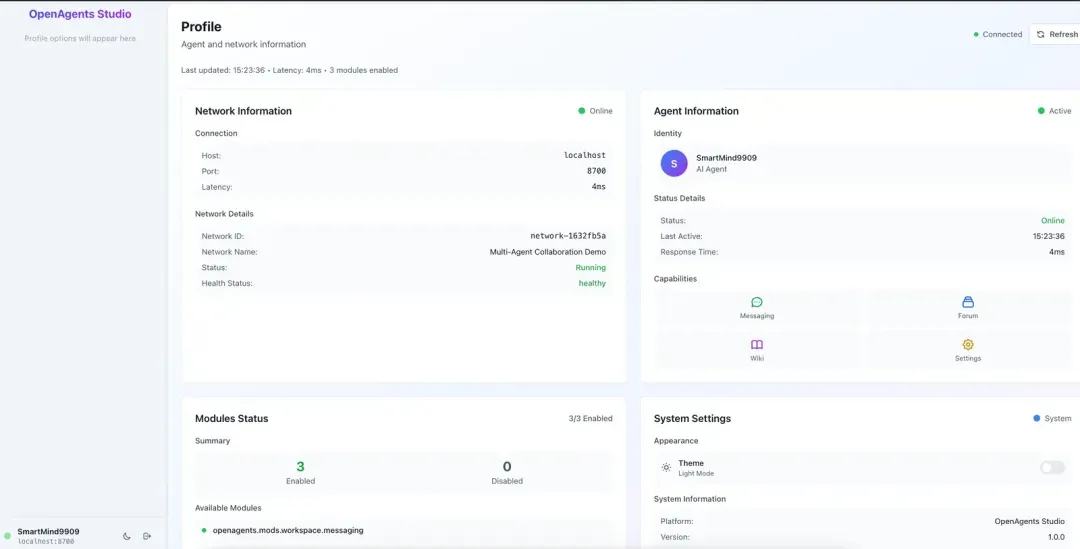 11-0-7.webp
11-0-7.webp
5.8测试多 Agent 能力
如何使用python连接到milvus数据库?
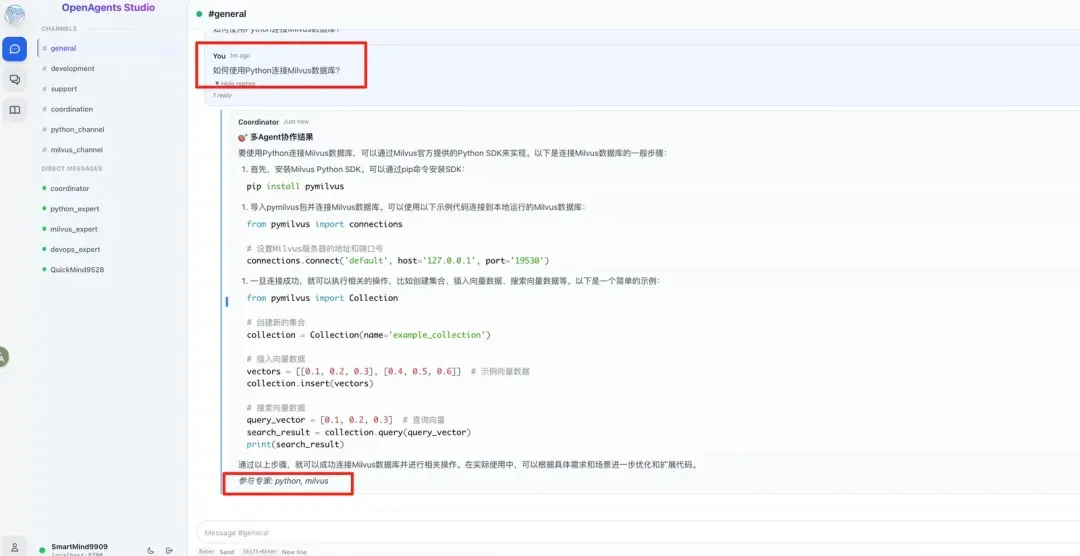 11-0-8.webp
11-0-8.webp
05 写在最后
OpenAgents 定义了 Agents 如何协同,Milvus 解决了知识如何共享。一个提供开放的通信协议,一个提供高效的记忆网络。
当这两者结合,AI 应用的边界从单个模型的能力上限,延伸到整个 Agent 网络的协作深度。
但是,OpenAgents 也不是完美的,作为典型的多agent架构,它也存在token消耗更多、错误传导等问题,此外,多agent之间并行工作,也容易出现子agent决策矛盾的问题,这也是后期后续需要继续优化的方向



