不止语义检索,Milvus+LangChain全文检索RAG教程来了
前言
最近,OpenAI和LangChain杠上了。一个是大模型扛把子,一个是最受欢迎的大模型框架
而抬杠的原因很简单LangChain觉得OpenAI 根本不懂agent:
具体争论细节,可以参考我们的历史文章Langchain 吐槽OpenAI根本不懂 AI agent和workflow?知识点全解析
但总结一句话来说,就是对于agent开发,OpenAI更倾向于高级抽象能加速开发;而LangChain则觉得大模型要能真正发挥作用,需要精确控制能确保可靠性,因此workflow和agent都必不可少。
实际上,两者的争论没有完全的对错之分。OpenAI指出的的是长期趋势,而LangChain给出的,则是立足当下,针对具体问题的更优解决方案。
以企业内部知识库问答系统构建来说,长期看,通过大模型智能调度各种工具然后基于milvus在内的向量数据库进行检索并给出答案,会是大势所趋;
但是具体到各种现实场景,仅仅是对接milvus,向量数据库中的索引算法有几十种,根据用户的需求不同,以及成本的不同考量,要如何对其中进行抉择,往往还需要开发者们的实际经验参与,将其写成workflow。
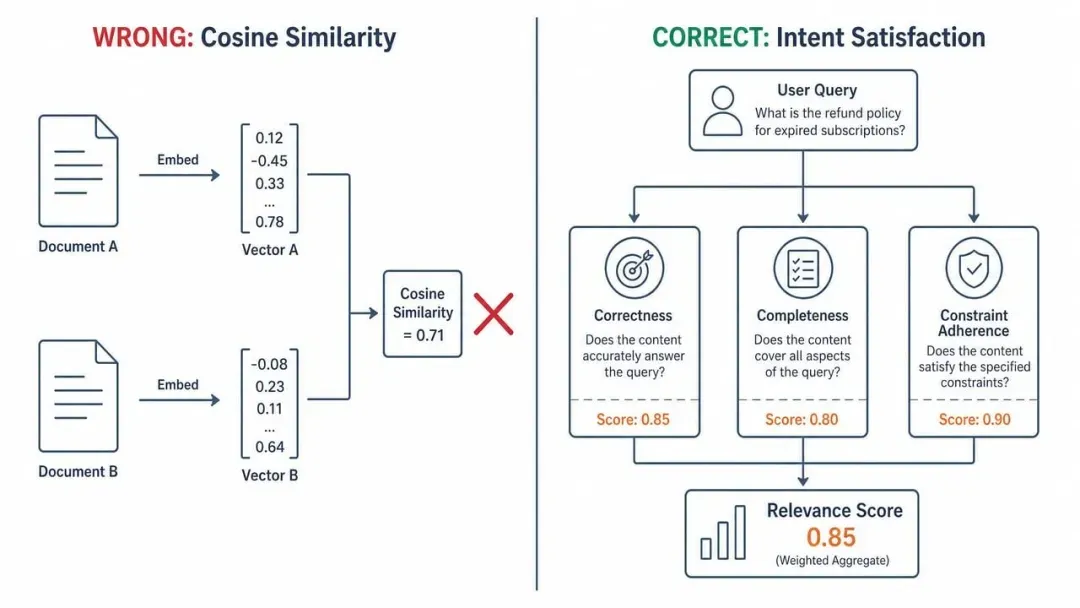
一个最简单的例子是,全文检索和语义搜索究竟哪个效果更佳?
答案是,看你在搜什么。
比如,同样是检索鲁迅先生的文章,在我们需要查找“藤野先生”“祥林嫂”的时候,全文检索就是最优解;
但是当我们检索诸如“少年在瓜田刺猹”这类描述性内容,那么语义检索就是帮你精准找到相关内容的最优解。
那么,该如何通过LangChain与Milvus构建一个RAG系统?本文将对此做出解读。
01
背景科普:如何在向量数据库中实现全文检索
(本章节主要做一些基础技术内容的科普,如果已经了解相关背景,可直接跳过)
全文检索是一种信息检索技术,能够从大量文本数据中快速找出包含特定词语或短语的文档,非常适合精确术语的查找。
例如,当你需要查找包含"Python 3.9新特性"的文档时,全文检索能够精确定位包含这些关键词的内容。
不过,与简单的关键词匹配不同,全文检索考虑了词语在文档中的重要性、出现频率以及上下文关系,从而提供更加精准和相关的搜索结果。
 4.24-1.png
4.24-1.png
与之相对应的是语义搜索,主要关注内容的含义而非具体词语,适合理解查询意图。例如,当你搜索"编程语言最新版本功能"时,语义搜索可能会返回关于Python、Java等多种语言最新版本的信息,即使文档中没有出现你使用的确切词语。
长久以来,很多人可能会有一个误解,那就是ES适合全文检索,而向量数据库只适合语义检索。
其实Milvus等现代向量数据库的一个重要创新是实现了稀疏向量(用于全文检索)和密集向量(用于语义搜索)的协同工作。这种融合使系统能够同时支持基于关键词的精确匹配和基于语义的相似性搜索,为用户提供更全面的搜索体验。
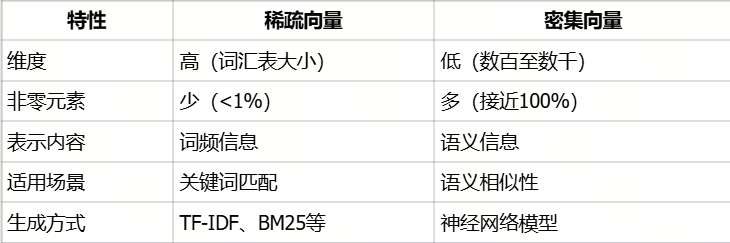
稀疏向量:想象一个超长的列表,对应词汇表中的每个词。如果文档包含某个词,对应位置标记为1(或词频),其余位置为0。例如,在一个包含10万词的词汇表中,一篇文档可能只包含100个不同的词,所以向量中99.9%的元素都是0。
密集向量:想象一个相对较短的列表(如几百个数字),每个数字都包含文档的某些语义特征。与稀疏向量不同,密集向量中几乎所有元素都有非零值,它们共同表示文档的"意义",而不是具体的词。
稀疏向量和密集向量在表示方式和应用场景上有显著差异:
 4.24-2.png
4.24-2.png
一句话总结来说,就是稀疏向量可以通过更多的维度,以及更少的非零元素,来实现关键词匹配等效果。
在Milvus中,通过内部优化机制,这两种向量表示能够高效协同工作,为用户提供更准确、更全面的搜索结果。
02
实战:LangChain与Milvus构建RAG系统
第一步,环境准备
Python 3.8+
Docker(用于运行Milvus)
OpenAI API密钥
基本的Python编程知识
了解向量数据库的基本概念
第二步,启动Milvus服务
使用Docker Compose启动Milvus服务:
wget https://github.com/milvus-io/milvus/releases/download/v2.2.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
docker-compose up -d
验证Milvus服务是否正常运行:
docker ps | grep milvus
安装必要的依赖
pip install --upgrade langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai bs4
设置环境变量
# import os 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
# 设置Milvus连接信息
URI = "http://localhost:19530"
TOKEN = "your-token-here" # 如果需要
第三步,文档预处理与向量化
文档预处理是构建高效RAG系统的关键第一步。以下是使用LangChain和Milvus进行文档预处理和向量化的详细步骤:
首先,我们需要从各种来源加载文档。LangChain提供了多种文档加载器,可以处理不同格式的文件。
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader
# 加载文本文件
def load_text_documents(directory):
loader = DirectoryLoader(directory, glob="**/*.txt", loader_cls=TextLoader)
return loader.load()
# 加载PDF文件
def load_pdf_documents(directory):
loader = DirectoryLoader(directory, glob="**/*.pdf", loader_cls=PyPDFLoader)
return loader.load()
# 组合加载多种格式
def load_all_documents(directory):
text_docs = load_text_documents(directory)
pdf_docs = load_pdf_documents(directory)
return text_docs + pdf_docs
接下来,我们需要把长文档分割成较小的块,以便更好地进行向量化和检索。
from langchain.text_splitter import RecursiveCharacterTextSplitter
def split_documents(documents, chunk_size=1000, chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""]
)
return text_splitter.split_documents(documents)
参数说明:
chunk_size:每个文档块的最大字符数
chunk_overlap:相邻块之间的重叠字符数,用于保持上下文连贯性
separators:分割文本的分隔符列表,按优先级排序
接下来,我们使用OpenAI的嵌入模型将文档块转换为向量,并存储在Milvus中。
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings
def create_vector_store(documents, collection_name, uri=URI):
# 创建嵌入模型
embeddings = OpenAIEmbeddings()
# 配置BM25分析器参数(用于生成稀疏向量)
analyzer_params = {
"tokenizer": "whitespace", # 使用空格分词
"filter": ["lowercase", {"type": "stop", "stop_words": ["the", "a", "an", "and", "or", "but", "is", "are", "in", "to", "with", "of"]}]
}
# 创建向量存储
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
builtin_function=BM25BuiltInFunction(analyzer_params=analyzer_params),
vector_field=["dense", "sparse"], # 同时存储密集向量和稀疏向量
connection_args={"uri": uri},
collection_name=collection_name,
)
return vector_store
技术说明:
OpenAIEmbeddings:使用OpenAI的嵌入模型生成密集向量
BM25BuiltInFunction:使用BM25算法生成稀疏向量,用于全文检索
vector_field=["dense", "sparse"]:同时存储两种向量,支持混合搜索
下面是一个完整的文档处理流程,从加载到向量化存储:
def process_documents(directory, collection_name, chunk_size=1000, chunk_overlap=200):
try:
# 1. 加载文档
print("正在加载文档...")
documents = load_all_documents(directory)
print(f"成功加载 {len(documents)} 个文档")
# 2. 分割文档
print("正在分割文档...")
chunks = split_documents(documents, chunk_size, chunk_overlap)
print(f"文档已分割为 {len(chunks)} 个块")
# 3. 创建向量存储
print("正在创建向量存储...")
vector_store = create_vector_store(chunks, collection_name)
print(f"向量存储已创建,集合名称:{collection_name}")
return vector_store
except Exception as e:
print(f"处理文档时出错:{str(e)}")
raise
使用示例:
# 处理文档并创建向量存储
vector_store = process_documents(
directory="./documents",
collection_name="knowledge_base",
chunk_size=1000,
chunk_overlap=200
)
保存向量存储配置以便后续使用
vector_store.save_local("./vector_store_config")
第四步,知识库问答系统实现
在开始实现之前,需要准备以下环境和依赖:
# 安装必要的依赖包
pip install langchain langchain-openai langchain-milvus python-dotenv
# 环境变量设置
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 确保设置了OpenAI API密钥
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("请设置OPENAI_API_KEY环境变量")
# Milvus连接设置
MILVUS_URI = os.getenv("MILVUS_URI", "http://localhost:19530")
完整实现方案
import os
from typing import List, Dict, Any, Optional
from langchain_core.documents import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 1. 加载文档
def load_documents(directory: str) -> List[Document]:
"""
从指定目录加载所有文本文档
Args:
directory: 文档所在目录路径
Returns:
Document对象列表
"""
documents = []
try:
for filename in os.listdir(directory):
if filename.endswith(('.txt', '.md', '.pdf')):
file_path = os.path.join(directory, filename)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
documents.append(Document(
page_content=content,
metadata={"source": filename, "path": file_path}
))
except Exception as e:
print(f"读取文件 {filename} 时出错: {str(e)}")
except Exception as e:
print(f"读取目录 {directory} 时出错: {str(e)}")
print(f"成功加载了 {len(documents)} 个文档")
return documents
# 2. 文档分割
def split_documents(documents: List[Document],
chunk_size: int = 1000,
chunk_overlap: int = 200) -> List[Document]:
"""
将文档分割成更小的块
Args:
documents: 要分割的文档列表
chunk_size: 每个块的最大字符数
chunk_overlap: 相邻块之间的重叠字符数
Returns:
分割后的文档块列表
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""]
)
split_docs = text_splitter.split_documents(documents)
print(f"文档被分割为 {len(split_docs)} 个块")
return split_docs
# 3. 创建向量存储
def create_vector_store(documents: List[Document],
collection_name: str = "knowledge_base",
recreate: bool = False) -> Milvus:
"""
创建向量存储
Args:
documents: 要存储的文档列表
collection_name: Milvus集合名称
recreate: 是否重新创建集合
Returns:
Milvus向量存储对象
"""
try:
# 配置向量存储
embeddings = OpenAIEmbeddings()
# 配置BM25分析器参数
analyzer_params = {
"tokenizer": "jieba", # 使用结巴分词器处理中文
"filter": ["lowercase", {"type": "stop", "stop_words": ["的", "了", "是"]}],
}
# 创建向量存储
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
builtin_function=BM25BuiltInFunction(analyzer_params=analyzer_params),
vector_field=["dense", "sparse"], # 同时存储密集向量和稀疏向量
connection_args={"uri": MILVUS_URI},
collection_name=collection_name,
drop_old=recreate, # 是否删除已存在的集合
)
print(f"成功创建向量存储,集合名称: {collection_name}")
return vector_store
except Exception as e:
print(f"创建向量存储时出错: {str(e)}")
raise
# 4. 创建问答链
def create_qa_chain(vector_store: Milvus,
temperature: float = 0.0,
search_k: int = 5) -> RetrievalQA:
"""
创建检索问答链
Args:
vector_store: Milvus向量存储对象
temperature: 生成模型的温度参数
search_k: 检索的文档数量
Returns:
RetrievalQA链对象
"""
try:
# 创建混合检索器
retriever = vector_store.as_retriever(
search_type="hybrid", # 使用混合搜索模式
search_kwargs={
"k": search_k, # 检索top-k个文档
"hybrid_search": {
"dense_weight": 0.7, # 密集向量权重
"sparse_weight": 0.3, # 稀疏向量权重
}
}
)
# 创建自定义提示模板
template = """
使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。
{context}
问题: {question}
回答:
"""
prompt = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# 创建大语言模型
llm = ChatOpenAI(temperature=temperature)
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt}
)
return qa_chain
except Exception as e:
print(f"创建问答链时出错: {str(e)}")
raise
# 5. 完整流程示例
def build_knowledge_qa_system(docs_directory: str,
collection_name: str = "knowledge_base") -> RetrievalQA:
"""
构建完整的知识库问答系统
Args:
docs_directory: 文档目录
collection_name: 向量存储集合名称
Returns:
问答系统链
"""
# 加载文档
documents = load_documents(docs_directory)
# 分割文档
split_docs = split_documents(documents)
# 创建向量存储
vector_store = create_vector_store(split_docs, collection_name)
# 创建问答链
qa_chain = create_qa_chain(vector_store)
return qa_chain
# 6. 使用示例
def query_example():
"""
示例:如何使用问答系统
"""
# 构建问答系统
qa_system = build_knowledge_qa_system("./documents", "company_knowledge")
# 查询示例
query = "公司的年假政策是什么?"
result = qa_system({"query": query})
# 输出结果
print(f"问题: {query}")
print(f"回答: {result['result']}")
# 输出来源文档
print("\n来源文档:")
for i, doc in enumerate(result["source_documents"]):
print(f"文档 {i+1}: {doc.metadata['source']}")
print(f"内容片段: {doc.page_content[:100]}...\n")
第五步,运行效果示例。以下是系统运行的示例输出:
成功加载了 15 个文档
文档被分割为 78 个块
成功创建向量存储,集合名称: company_knowledge
问题: 公司的年假政策是什么?
回答: 根据公司政策,正式员工每年享有15天带薪年假。工作满3年的员工额外增加3天年假,满5年的员工额外增加5天年假。年假可以分多次使用,但每次至少使用半天。未使用的年假可以结转到下一年,但最多结转5天。
来源文档:文档 1: company_policy.txt
内容片段: # 公司员工手册 ## 休假政策 ### 年假 正式员工每年享有15天带薪年假。工作满3年的员工额外增加3天年假,满5年...
文档 2: hr_faq.txt
内容片段: # 人力资源常见问题 ## 休假相关 Q: 年假如何申请? A: 员工可通过OA系统提交年假申请,需提前3个工作日申请...
03
经验总结
通过上文,我们展示了一个比较初级的基于全文检索的企业知识库系统的构建,但是实操中,我们可能还会遇到一些更加具体且琐碎的问题,比如
比如全文检索基于精确的词语匹配,可能无法处理同义词(不同词语表达相同含义)和多义词(同一词语有多种含义)的问题。例如,用户搜索"汽车"时,可能无法找到只包含"轿车"或"车辆"的文档。
我们可以有三个解决思路。(1)同义词扩展:在索引和查询时添加同义词; (2)查询扩展: 自动扩展用户查询以包含相关术语;(3)结合语义搜索:通过密集向量捕捉语义关系。
再比如,不同语言有不同的语法结构和词形变化规则,这给全文检索带来挑战。例如,中文不像英文那样有明显的词语边界,需要特殊的分词技术。
解决方案主要有两个。 (1)语言特定分词器:为不同语言使用专门的分词技术; (2)多语言支持 :构建支持多种语言的索引。
此外,随着数据量的增长,全文检索系统需要处理越来越多的文档,这对系统性能提出了挑战。
解决方案有三个。 (1)分布式索引:将索引分散到多个服务器;(2)增量索引更新:只更新变化的部分;(3)冷热数据,缓存机制:缓存热门查询结果。
 尹珉
尹珉Zilliz 黄金写手