低内存、高召回, DiskANN才是低成本实现十亿级向量搜索更优解
前言
什么是 DiskANN?
一句话解读,就是能让你在十亿向量的规模下,实现成本节约75%, 95% 准确率、毫秒级延迟的高效索引算法。
过去,多数主流索引方法(如 HNSW)必须依赖大量内存才能实现低延迟和高召回,虽在中等规模数据集上效果理想,但一旦扩展至数亿数据点,成本便迅速上升,难以落地到实际业务中。
DiskANN 则通过将索引存储在 SSD 上,大幅降低了内存占用。
它采用了一种专为磁盘访问优化的扁平图结构,仅用少量内存就能支持十亿级向量检索。在实际表现中,DiskANN 可在 5ms 延迟内实现 95% 的检索准确率,支持多达十亿条向量,而基于 RAM 的算法在类似性能下往往止步于一到两亿条数据。
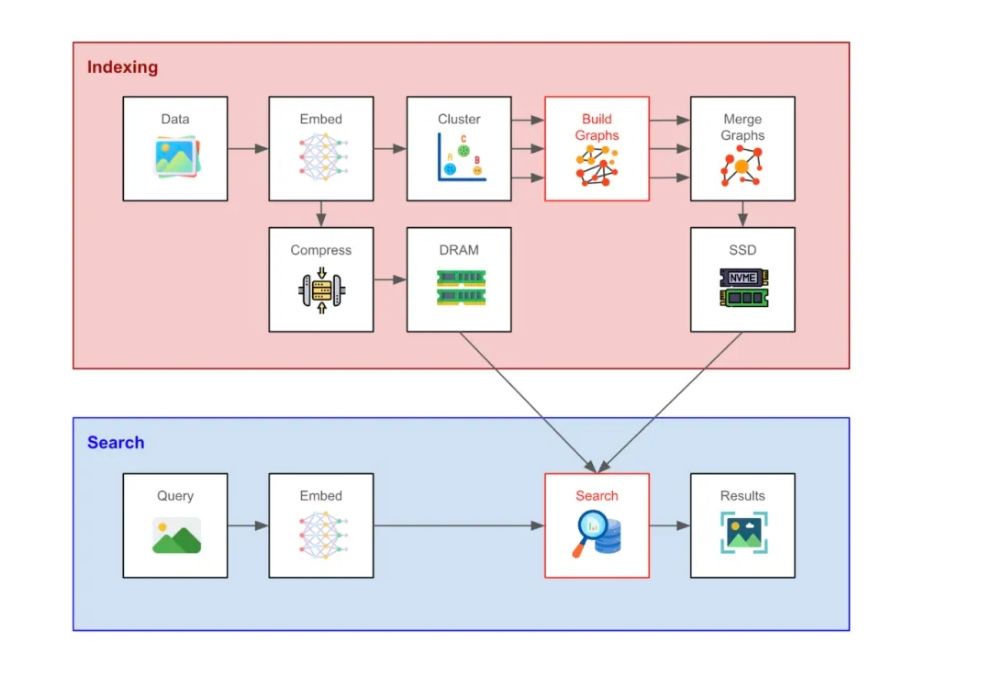
图示:DiskANN 的向量索引与搜索流程
尽管 DiskANN 相较于纯内存算法在延迟上略有增加,但其在成本控制与可扩展性上具备无可比拟的优势。尤其在需要在通用硬件上进行大规模向量检索的场景中,DiskANN 是极具实用性的解决方案。
本文将深入解析 DiskANN 如何在 RAM 和 SSD 间实现高效协同,并通过一系列巧妙设计显著减少磁盘读取开销,从而实现低成本、高性能的向量搜索。
01
DiskANN 如何工作?
DiskANN 属于图结构向量搜索方法,与 HNSW 同属一类。其核心思想是构建一张搜索图:图中每个节点对应一个向量(或向量组),边表示两个向量在空间中“相对接近”。
搜索过程通常从一个随机的“入口节点”开始,系统会贪心地选择最接近查询向量的邻居,逐步前进,直到无法找到更优路径,找到局部最优为止。
不同图索引方法的本质区别,在于图的构建方式与搜索策略。接下来我们将深入探讨 DiskANN 在这两个环节的创新点,以及它如何实现低延迟、低内存的搜索能力。
02
DiskANN 工作流程概览
假设用户已生成一组向量嵌入,DiskANN 的第一步是对这些向量进行聚类。随后,每个聚类单独构建一张局部搜索图,使用的正是后文将介绍的 Vamana 算法。最后,所有子图最终将合并为一张全局图。
这一“分而治之”的图构建策略,能有效压缩内存开销,同时保持了较高的检索效率与召回率,在面对大规模数据时表现尤为出色。
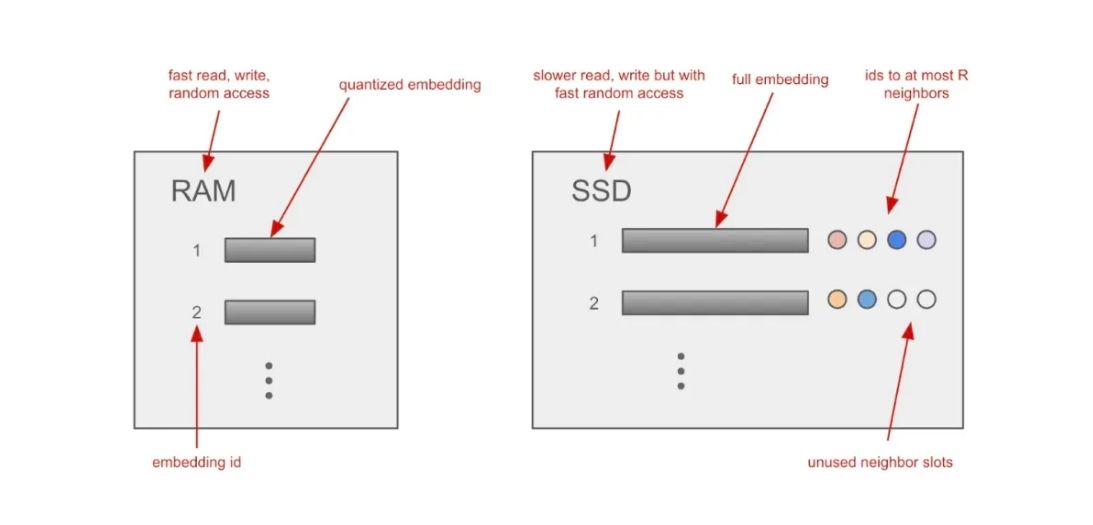
图示:DiskANN 如何在 RAM 与 SSD 之间存储向量索引
构建完成的全局搜索图会与高精度原始向量一同存储在 SSD 上。挑战在于:如何在尽量少的 SSD 读取次数内完成检索,因为 SSD 相较于 RAM 的访问成本更高。为此,DiskANN 采用了一系列巧妙设计来控制读操作的开销:
结构优化:Vamana 算法在构图时引导相近节点形成更短路径,并限制每个节点的最大邻居数量,从根本上减少搜索时的访问范围。
定长存储:每个节点的向量及其邻居信息使用固定大小的数据结构存储(见上图),使得系统可以通过简单的偏移计算直接定位并批量读取节点数据,提升了访问效率。
顺序读取:利用 SSD 的特性,每次读取操作可以获取多个节点(如邻居节点),进一步降低了读请求的频率。
与此同时,DiskANN 还通过 乘积量化(Product Quantization) 对向量进行压缩,并将压缩向量存入内存,用于初步粗略搜索。这样即使是十亿级向量数据,也可在单机内存中进行快速的近似相似度计算,避免频繁访问磁盘。
这一阶段的作用是快速初筛潜在候选节点,为接下来的 SSD 精排阶段提供指导。需要特别指出的是:最终的检索结果仍基于 SSD 中读取的原始全精度向量进行精确比对,从而确保召回率不受影响。
换言之,DiskANN 的搜索包含两个阶段:
内存中基于量化向量进行粗排;
SSD 上对候选集合进行精排匹配。
在上述流程中,我们略去了两个关键但技术细节繁复的环节:图的构建与图中的搜索策略。它们在上图中已用红框标注,接下来的章节将逐一深入解析。
03
“Vamana” 图构建方法
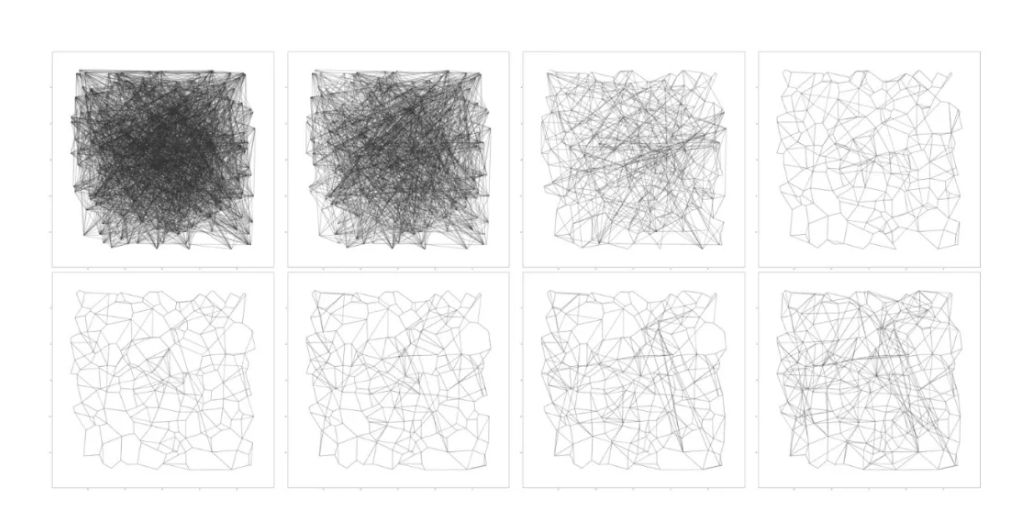
DiskANN 的作者提出了一种创新的图构建方法,称为 Vamana 算法。它首先随机为每个节点添加 O(N)O(N)O(N) 条边,构建出一个“连接良好”的搜索图,尽管此时尚无法保证贪心搜索的收敛性。接着,算法通过剪枝与重连操作,在保留足够长程连接的同时优化图结构(详见上图)。下面是详细流程:
初始化阶段
搜索图初始为一个随机有向图,每个节点连接 RRR 个出边。与此同时,算法会计算出整张图的 medoid,即到其他所有节点平均距离最小的节点,可理解为集合中实际存在的“质心”。
候选节点搜索
初始化后,算法遍历图中每个节点,在每一步同时进行边的添加与删除。对于某个节点 ppp,算法从 medoid 出发,采用贪心策略逐步接近 ppp,每一步都会加入当前最近节点的所有出邻居。最终返回距离 ppp 最近的 LLL 个候选节点。
(提示:如果你对 “medoid” 这一概念不熟悉,它是图中到其他节点平均距离最短的点,相当于质心在图结构中的等价物。)
剪枝与连边
候选邻居按距离排序后,算法会判断每个候选节点的方向是否与已选邻居过于接近。如果“方向重复”,则将其剪枝。这个步骤鼓励邻居间的方向多样性(angular diversity),实验证明这能提升图的导航能力。
简而言之,这种结构让搜索算法能从任意节点迅速到达目标节点,依赖的是稀疏而覆盖面广的长短连接组合。
剪枝完成后,算法还会补充沿着贪心搜索路径到节点 ppp 的边。整个剪枝过程分为两轮进行,第二轮使用更宽松的阈值,以保留关键的长距离跳跃连接。
后续发展
DiskANN 的研究成果还被进一步拓展。例如 FreshDiskANN 便在其基础上引入了支持构建后索引更新的能力。这一索引类型在内存占用、查询延迟与搜索精度之间实现了出色平衡,并已作为 DISKANN 类型集成进 Milvus 向量数据库中,可直接使用。
04
如何在Milvus中使用Disk ANN
在 Milvus 中构建 DiskANN 索引可以使用 add_index() 方法,将 index_type 设置为 DISKANN:
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # 要索引的向量字段名称
index_type=
"DISKANN"
,
# 要创建的索引类型
index_name="vector_index", # 要创建的索引名称
metric_type="L2", # 或者使用"IP"等其他适合的度量类型
params={}
# DISKANN索引不需要额外索引参数,此处为空
)
配置完索引参数后,可以通过以下任意方法创建索引:
MilvusClient.create_index(
collection_name="your_collection_name", # 指定 Collection 名称
index_params=index_params
)
在创建 Collection 时传入索引参数: 在使用 create_collection() 方法创建 Collection 时,可以直接传入索引参数,从而在创建 Collection 的同时创建 FLAT 索引。有关更多信息,请参考创建 Collection。
 Zilliz
Zilliz