



外行如何速成专家?Embedding之BM25、splade稀疏向量解读
在 《孙悟空 + 红楼梦 - 西游记 = ?一文搞懂什么是向量嵌入》这篇文章中,我们已经知道了文本怎么变成稠密向量,并且还能够表达文本的语义。但是,对于嵌入模型的“专业领域”外的文本,它的效果不尽如人意。
打个比方,假设你身体不舒服去看医生,医生完全理解你的描述,他会判断病因然后做出诊断。但是,如果你问医生“人工智能如何影响汽车行业?”,医生大概会觉得你不仅身体不舒服,脑子也需要治一治。医生不懂这方面的知识。
想要获得答案,你可以去找人工智能或者汽车领域的专家。当然,你还有另一个选择,去找一位聪明的门外汉,“冒充”专家。
聪明的门外汉——BM25
稠密向量(Dense Vector)的维度较低,一般在几百到上千左右,每个维度的元素一般都不为零。相对的,还有一种稀疏向量(Sparse Vector),它的维度远远超过稠密向量,一般有几万甚至十万,但是大部分维度的元素都为零,只有少数元素是非零的。
稀疏向量分成统计得到的稀疏向量和学习得到的稀疏向量两种,我们先聊聊第一种,代表就是 BM25。
BM25 是一位聪明的门外汉,你问他领域外的知识,他虽然不理解,但是他会找到问题中的关键词,比如“人工智能”和“汽车”,然后去查文档,把文档中和关键词最相关的信息告诉你。
那么,这位门外汉具体是怎么做的呢?
首先,他会搜索成百上千篇相关文档,并且快速地翻一遍,了解这些文档中有哪些专业术语。什么样的词是专业术语呢?作为一个聪明的门外汉,他决定通过单词出现的频率判断。像“的”、“是”、“了”等常见词肯定不是专业术语,反而是那些出现频率比较低的词,更可能是专业术语。
这就好比你有两个微信群,一个是工作群,平时消息不多,但是一旦有消息,不是领导布置任务,就是同事反馈进度,都很重要,你把这个群置顶了。
另一个是吃喝玩乐群,一群朋友在群里聊天吹水,一整天消息不断,但是没那么重要,错过就错过了,忙的时候你还会设置成“信息免打扰”。
对你来说,不同的群权重不同,门外汉也会为不同的词设置不同的权重。他会为文档中出现的词建立一个词汇表,并且根据单词出现的频率赋予权重,出现的频率越低,权重越大,越可能是专业术语。
然后,他要判断哪些文档和“人工智能”以及“汽车”这两个专业术语更相关。他会对照词汇表,数一数每篇文档中这两个术语出现的频率,频率越高,相关性越大。
以上是 BM25 的极简版解释,实际算法要复杂很多。公式越多,读者越少,所以下面我就简单介绍下 BM25 算法的工作原理。
首先,BM25对文档集合做分词处理,得到一张词汇表。词汇表的单词(准确来说是 token)的数量,就是稀疏向量的维度。
然后,对查询也做分词处理,比如,如果查询是“人工智能如何影响汽车行业?”,分词得到“人工智能“”、“影响”和“汽车行业”这三个词。
接下来,计算文档集合中的每个词的逆文档频率 IDF,以及查询中的某个词在指定文档中的词频 TF。
逆文档频率 IDF(Inverse Document Frequency),很绕口的一个名字。简单来说,它用来计算某个词在文档集合中出现的次数。出现次数越少,数值越大。门外汉用它给出现频率低的专业术语,赋予更大的权重。
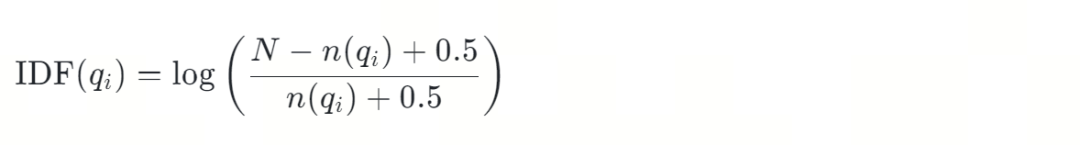 1.png
1.png
其中:
是单词 的逆文档频率。
是文档总数。
是语料库中,包含查询词 的文档数量。
是一个平滑因子,用于避免分母为零的情况。
词频TF(Term Frequency)表示查询中的某个词,在指定文档中出现的频率,频率越大数值越大,也就意味着查询和该文档的相关性更高。
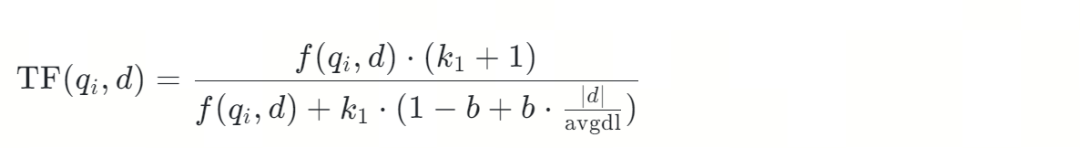 2.png
2.png
其中:
是查询词 在文档 中的词频。反映了查询词在文档中的重要性。
是查询。
是语料库中的某一个文档。
是查询中的第 个 token。
是查询词 在文档 中出现的次数。
是一个调节参数,用于控制词频的影响。 取值在1.2到2之间
是一个调节参数,用于控制文档长度对词频的影响。 取值为0.75。
是文档的长度。文档长度指的是分词后的 token 数量。
是语料库中所有文档的平均长度。
最后,根据 IDF 和 TF 计算 BM25分数,用来表示查询与指定文档的相关程度。
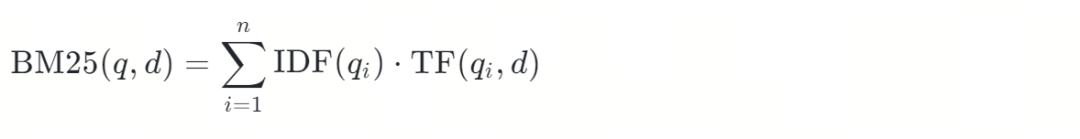 3.png
3.png
BM25 代码实践
好啦,纸上谈兵到此结束,下面我们用代码实际操练一番吧。先做点准备工作:
Milvus 版本:>=2.4.0
安装依赖:
!pip install pymilvus==2.4.7 "pymilvus[modle]" torch
假如下面的字符串列表就是我们的文档集合,每个字符串是一个文档:
docs = [
"机器学习正在改变我们的生活方式。",
"深度学习在图像识别中表现出色。",
"自然语言处理是计算机科学的重要领域。",
"自动驾驶依赖于先进的算法。",
"AI可以帮助医生诊断疾病。",
"金融领域广泛应用数据分析技术。",
"生产效率可以通过自动化技术提高。",
"机器智能的未来充满潜力。",
"大数据支持是机器智能发展的关键。",
"量子隧穿效应使得电子能够穿过经典力学认为无法穿过的势垒,这在半导体器件中有着重要的应用。"
]
使用BM25对第一个文档“机器学习正在改变我们的生活方式。”做分词处理:
from pymilvus.model.sparse.bm25.tokenizers import build_default_analyzer
from pymilvus.model.sparse import BM25EmbeddingFunction
# 使用支持中文的分析器
analyzer = build_default_analyzer(language="zh")
# 分析器对文本做分词处理
tokens1 = analyzer(docs[0])
print(tokens1)
分词结果如下:
['机器', '学习', '改变', '生活', '方式']
接下来对整个文档集合做分词处理,并且计算文档集合的 IDF 等参数:
# 创建BM25EmbeddingFunction实例,传入分词器,以及其他参数
bm25_ef = BM25EmbeddingFunction(analyzer)
# 计算文档集合的参数
bm25_ef.fit(docs)
# 保存训练好的参数到磁盘以加快后续处理
bm25_ef.save("bm25_params.json")
我们看下参数有哪些内容:
import json
file_path = "bm25_params.json"
with open(file_path, 'r', encoding='utf-8') as file:
bm25_params = json.load(file)
print(bm25_params)
corpus_size 是文档数量,avgdl、idf_value 等参数都在前面的公式中出现过。
{'version': 'v1', 'corpus_size': 10, 'avgdl': 5.4, 'idf_word': ['机器', '学习', '改变', '生活', '方式', '深度', '图像识别', '中', '表现出色', '自然语言', '计算机科学', '领域', '自动', '驾驶', '依赖于', '先进', '算法', 'AI', '医生', '诊断', '疾病', '金融', '广泛应用', '数据分析', '技术', '生产', '效率', '自动化', '提高', '智能', '未来', '充满', '潜力', '大', '数据', '支持', '发展', '关键', '量子', '隧穿', '效应', '电子', '穿过', '经典力学', '势垒', '半导体器件'], 'idf_value': [0.7621400520468966, 1.2237754316221157, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.2237754316221157, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.2237754316221157, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.2237754316221157, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.2237754316221157, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331, 1.845826690498331], 'k1': 1.5, 'b': 0.75, 'epsilon': 0.25}
idf_word 是 BM25对文档集合的分词结果,也就是前面提到的词汇表。词汇表中单词的数量,也是稀疏向量的维度。
# BM25词汇表中的单词数量
print(f"BM25词汇表中的单词数量:{len(bm25_params['idf_word'])}")
# BM25稀疏向量的维度
print(f"BM25稀疏向量维度:{bm25_ef.dim}")
返回的结果:
BM25词汇表中的单词数量:46
BM25稀疏向量维度:46
需要的参数计算好了,接下来就可以生成文档集合的稀疏向量了。文档集合中有10篇文档,也就是10个字符串,而稀疏向量的维度是46,所以文档集合的稀疏向量是一个10行46列的矩阵。每一行表示一个文档的稀疏向量。
# 生成文档集合的稀疏向量
sparse_vectors_bm25 = bm25_ef.encode_documents(docs)
# 打印文档集合的稀疏向量
print(sparse_vectors_bm25)
输出结果:
(0, 0) 1.0344827586206897
(0, 1) 1.0344827586206897
(0, 2) 1.0344827586206897
(0, 3) 1.0344827586206897
(0, 4) 1.0344827586206897
: :
(9, 7) 0.7228915662650603
(9, 38) 0.7228915662650603
(9, 39) 0.7228915662650603
(9, 40) 0.7228915662650603
(9, 41) 0.7228915662650603
(9, 42) 1.1214953271028039
(9, 43) 0.7228915662650603
(9, 44) 0.7228915662650603
(9, 45) 0.7228915662650603
我们来看下第一个文档“机器学习正在改变我们的生活方式。”的稀疏向量:
# 第一个文档的稀疏向量
print(list(sparse_vectors_bm25)[0])
结果为:
(0, 0) 1.0344827586206897
(0, 1) 1.0344827586206897
(0, 2) 1.0344827586206897
(0, 3) 1.0344827586206897
(0, 4) 1.0344827586206897
你发现了吧,第一个文档的稀疏向量只有5个非零元素,因为它的分词结果是5个单词,对应上了。而且,每个元素的值都相同,说明它们的逆文档频率 IDF 和词频 TF 都是一样的。
第一个文档的分词结果:
['机器', '学习', '改变', '生活', '方式']
文档集合处理好了,我们再给出一个查询的句子,就可以执行搜索了。
query = ["自动驾驶如何影响汽车行业?"]
# 把查询文本向量化
query_sparse_vectors_bm25 = bm25_ef.encode_queries(query)
# 打印稀疏向量
print(query_sparse_vectors_bm25)
# 查询的分词结果
print(analyzer(query[0]))
查看查询的稀疏向量,以及它的分词结果。
(0, 12) 1.845826690498331
(0, 13) 1.845826690498331
['自动', '驾驶', '影响', '汽车行业']
你可能会有疑问,为什么查询分词后得到4个单词,但是它的稀疏向量只有2维?因为这4个单词中,词汇表中只有“自动”和“驾驶”,没有“影响”和“汽车行业”,后两个词的 BM25 分数为0。
哎,毕竟是门外汉啊。
刚入门的新人——splade
如果说稠密向量是精通特定领域的专家,统计得到的稀疏向量 BM25是聪明的门外汉,那么学习得到的稀疏向量 splade 就是刚入门的新人。他理解领域内专业术语的语义,而且能够举一反三,增加更多语义相近的词,一起查找。但是他毕竟还是新人,并不精通,还是通过数专业术语出现的次数,找到最相关的文档。
具体来说,splade 是这样工作的:
首先,splade 先对句子分词,通过嵌入模型 BERT (BERT 相关内容详见 《孙悟空 + 红楼梦 - 西游记 = ?一文搞懂什么是向量嵌入》)得到单词的向量。向量可以表达语义,所以 splade 能够“举一反三”,找到更多语义相似的单词。
比如,对于“人工智能如何影响汽车行业”这个句子,分词得到“人工智能”和“汽车”两个 单词,以及与“人工智能”相似的“AI”等单词。
splade 也有一张词汇表,不过它不需要像 bm25 那样根据文档集合统计,而是预先就有的,来源于 BERT。
接下来,splade 生成这些单词的稀疏向量。它会计算每个单词出现在词汇表中的每个位置的概率。也就是说,单词和词汇表中某个位置的词在语义上越接近,计算得到的概率越大。这个概率就是单词的权重。
以“人工智能”为例,假设词汇表中第5个词也是“人工智能”,两个词完全一样,计算得到的概率就很高,比如40%。而词汇表第8个词是“机器学习”,两个词比较相似,概率是20%。而词汇表中其他的词和“人工智能”语义相差较远,概率很小,忽略不计。最后,“人工智能”的权重就是 40% + 20% = 60%。
然后再用相同的方法,计算出“AI”和“汽车”的权重,得到稀疏向量:
sparse_vector = {"人工智能": 0.6,"AI": 0.5,"汽车": 0.1}
splade 代码实践
老规矩,我们还使用代码验证下前面的内容。这次使用英文的文档集合:
# 使用英文
docs_en = [
"Machine learning is changing our way of life.",
"Deep learning performs exceptionally well in image recognition.",
"Natural language processing is an important field in computer science.",
"Autonomous driving relies on advanced algorithms.",
"AI can help doctors diagnose diseases.",
"Data analysis technology is widely applied in the financial field.",
"Production efficiency can be improved through automation technology.",
"The future of machine intelligence is full of potential.",
"Big data support is key to the development of machine intelligence.",
"The quantum tunneling effect allows electrons to pass through potential barriers that classical mechanics consider impassable, which has important applications in semiconductor devices."
]
生成文档集合的稀疏向量:
from pymilvus.model.sparse import SpladeEmbeddingFunction
query_en = ["How does artificial intelligence affect the automotive industry?"]
model_name = "naver/splade-cocondenser-selfdistil"
# 实例化splade嵌入模型
splade_ef = SpladeEmbeddingFunction(
model_name = model_name,
device="cpu"
)
# 生成文档集合的稀疏向量
sparse_vectors_splade = splade_ef.encode_documents(docs_en)
print(sparse_vectors_splade)
和 BM25 一样,我们同样得到一个稀疏向量矩阵:
(0, 1012) 0.053256504237651825
(0, 2003) 0.22995686531066895
(0, 2047) 0.08765587955713272
: :
(9, 27630) 0.2794925272464752
(9, 28688) 0.02786295674741268
(9, 28991) 0.12241243571043015
splade 的词汇表是预先准备好的,词汇表中的单词数量同样也是稀疏向量的维度。
# splade词汇表中的单词数量
from transformers import AutoModelForMaskedLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
print(f"splade词汇表中的单词数量:{tokenizer.vocab_size}")
print(f"splade稀疏向量维度:{splade_ef.dim}")
二者相同:
splade词汇表中的单词数量:30522
splade稀疏向量维度:30522
我们再来看看查询的分词结果及其稀疏向量:
# 查看查询的分词
tokens = tokenizer.tokenize(query_en[0])
print(f"“{query_en[0]}” 的分词结果:\n{tokens}")
print(f"tokens数量:{len(tokens)}")
# 生成查询的稀疏向量
query_sparse_vectors_splade = splade_ef.encode_queries(query_en)
print(query_sparse_vectors_splade)
结果如下:
“How does artificial intelligence affect the automotive industry?” 的分词结果:
['how', 'does', 'artificial', 'intelligence', 'affect', 'the', 'automotive', 'industry', '?']
tokens数量:9
(0, 2054) 0.139632448554039
(0, 2079) 0.08572433888912201
(0, 2106) 0.22006677091121674
(0, 2126) 0.038961488753557205
(0, 2129) 0.6875206232070923
(0, 2138) 0.5343469381332397
(0, 2194) 0.32417890429496765
(0, 2224) 0.011731390841305256
(0, 2339) 0.33811360597610474
: :
(0, 26060) 0.0731586366891861
比较分词的数量和稀疏向量的维度,你有没有发现有什么不对劲的地方?没错,分词数量和稀疏向量的维度不一样。这就是 splade 和 BM25的重要区别,splade 能够“举一反三”,它在最初9个分词的基础上,又增加了其他语义相近的单词。
那么,查询现在一共有多少个单词呢?或者说,它的稀疏向量的非零元素有多少呢?
# 获取稀疏向量的非零索引
nonzero_indices = query_sparse_vectors_splade.indices[query_sparse_vectors_splade.indptr[0]:query_sparse_vectors_splade.indptr[1]]
# 构建稀疏词权重列表
sparse_token_weights = [
(splade_ef.model.tokenizer.decode(col), query_sparse_vectors_splade[0, col])
for col in nonzero_indices
]
# 按权重降序排序
sparse_token_weights = sorted(sparse_token_weights, key=lambda item: item[1], reverse=True)
# 查询句只有9个tokens,splade通过举一反三,生成的稀疏向量维度增加到了98个。
print(f"splade 稀疏向量非零元素数量:{len(sparse_token_weights)}")
一共有98个:
splade 稀疏向量非零元素数量:98
具体是哪些单词?我们打印出来看一下:
# 比如,和“artificial intelligence”语义相近的 “ai”,和“automotive”语义相近的“car”。
for token in sparse_token_weights:
print(token)
splade 增加了大量语义相近的单词,比如和“artificial intelligence”语义相近的 “ai”,和“automotive”语义相近的“car”和“vehicle”。
('artificial', 2.588431)
('intelligence', 2.3582284)
('car', 1.590975)
('automotive', 1.4835068)
('vehicle', 0.798108)
('ai', 0.676852)
: :
搜索实践
我们已经了解了两种稀疏向量的特点,以及生成方法,下面就在搜索中体会下它们的区别吧。
我们需要用 Milvus 创建集合,然后导入数据,创建索引,加载数据,就可以搜索了。这个过程我在 朋友圈装腔指南:如何用向量数据库把大白话变成古诗词中有详细介绍,就不多赘述了。
创建集合。
from pymilvus import MilvusClient, DataType
import time
def create_collection(collection_name):
# 检查同名集合是否存在,如果存在则删除
if milvus_client.has_collection(collection_name):
print(f"集合 {collection_name} 已经存在")
try:
# 删除同名集合
milvus_client.drop_collection(collection_name)
print(f"删除集合:{collection_name}")
except Exception as e:
print(f"删除集合时出现错误: {e}")
# 创建集合模式
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
# 设置分区数量,默认为16
num_partitions=16,
description=""
)
# 添加字段到schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, max_length=256)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=256)
# bm25稀疏向量
schema.add_field(field_name="sparse_vectors_bm25", datatype=DataType.SPARSE_FLOAT_VECTOR)
# splade稀疏向量
schema.add_field(field_name="sparse_vectors_splade", datatype=DataType.SPARSE_FLOAT_VECTOR)
# 创建集合
try:
milvus_client.create_collection(
collection_name=collection_name,
schema=schema,
shards_num=2
)
print(f"创建集合:{collection_name}")
except Exception as e:
print(f"创建集合的过程中出现了错误: {e}")
# 等待集合创建成功
while not milvus_client.has_collection(collection_name):
# 获取集合的详细信息
time.sleep(1)
if milvus_client.has_collection(collection_name):
print(f"集合 {collection_name} 创建成功")
# 示例
collection_name = "docs"
uri="http://localhost:19530"
milvus_client = MilvusClient(uri=uri)
create_collection(collection_name)
导入数据。
# 准备数据
entities = [
{
# 文本字段
"text": docs[i],
"text_en": docs_en[i],
# bm25稀疏向量字段
"sparse_vectors_bm25": list(sparse_vectors_bm25)[i].reshape(1, -1),
# splade稀疏向量字段
"sparse_vectors_splade": list(sparse_vectors_splade)[i].reshape(1, -1),
}
for i in range(len(docs))
]
# 导入数据
milvus_client.insert(collection_name=collection_name, data=entities)
创建索引。
# 创建索引参数
index_params = milvus_client.prepare_index_params()
# 为稀疏向量bm25创建索引参数
index_params.add_index(
index_name="sparse_vectors_bm25",
field_name="sparse_vectors_bm25",
# SPARSE_INVERTED_INDEX是传统的倒排索引,SPARSE_WAND使用Weak-AND算法来减少搜索过程中的完整IP距离计算
index_type="SPARSE_INVERTED_INDEX",
# 目前仅支持IP
metric_type="IP",
# 创建索引时,排除向量值最小的20%的向量。对于稀疏向量来说,向量值越大,说明在该维度上的重要性越大。范围[0,1]。
params={"drop_ratio_build": 0.2}
)
# 为稀疏向量splade创建索引参数
index_params.add_index(
index_name="sparse_vectors_splade",
field_name="sparse_vectors_splade",
# SPARSE_INVERTED_INDEX是传统的倒排索引,SPARSE_WAND使用Weak-AND算法来减少搜索过程中的完整IP距离计算
index_type="SPARSE_INVERTED_INDEX",
# 目前仅支持IP
metric_type="IP",
# 创建索引时,排除向量值最小的20%的向量。对于稀疏向量来说,向量值越大,说明在该维度上的重要性越大。范围[0,1]。
params={"drop_ratio_build": 0.2}
)
# 创建索引
milvus_client.create_index(
collection_name=collection_name,
index_params=index_params
)
查看索引是否创建成功。
# 查看索引信息
def show_index_info(collection_name: str) -> None:
"""
显示指定集合中某个索引的详细信息。
参数:
collection_name (str): 集合的名称。
返回:
None: 该函数仅打印索引信息,不返回任何值。
"""
# 查看集合的所有索引
indexes = milvus_client.list_indexes(
collection_name=collection_name
)
print(f"已经创建的索引:{indexes}")
print()
# 查看索引信息
if indexes:
for index in indexes:
index_details = milvus_client.describe_index(
collection_name=collection_name,
# 指定索引名称,这里假设使用第一个索引
index_name=index
)
print(f"索引 {index} 详情:{index_details}")
print()
else:
print(f"集合 {collection_name} 中没有创建索引。")
# 示例
show_index_info(collection_name)
如果创建成功,你会看到下面的输出:
已经创建的索引:['sparse_vectors_bm25', 'sparse_vectors_splade']
索引 sparse_vectors_bm25 详情:{'drop_ratio_build': '0.2', 'index_type': 'SPARSE_INVERTED_INDEX', 'metric_type': 'IP', 'field_name': 'sparse_vectors_bm25', 'index_name': 'sparse_vectors_bm25', 'total_rows': 0, 'indexed_rows': 0, 'pending_index_rows': 0, 'state': 'Finished'}
索引 sparse_vectors_splade 详情:{'drop_ratio_build': '0.2', 'index_type': 'SPARSE_INVERTED_INDEX', 'metric_type': 'IP', 'field_name': 'sparse_vectors_splade', 'index_name': 'sparse_vectors_splade', 'total_rows': 0, 'indexed_rows': 0, 'pending_index_rows': 0, 'state': 'Finished'}
加载集合。
# 加载集合
print(f"正在加载集合:{collection_name}")
milvus_client.load_collection(collection_name=collection_name)
# 验证加载状态
print(milvus_client.get_load_state(collection_name=collection_name))
如果加载成功,会显示:
正在加载集合:docs
{'state': <LoadState: Loaded>}
加载完成,下面就是重头戏了,搜索。
定义搜索函数:
# 定义稀疏向量搜索参数
search_params_sparse_vectors = {
"metric_type": "IP",
"params": {"drop_ratio_search": 0.2},
}
# 执行向量搜索
def vector_search(
query_vectors,
field_name,
search_params,
output_fields,
):
# 向量搜索
res = milvus_client.search(
collection_name=collection_name,
# 指定查询向量。
data=query_vectors,
# 指定要搜索的向量字段
anns_field=field_name,
# 设置搜索参数
search_params=search_params,
output_fields=output_fields
)
return res
再定义一个打印结果的函数,方便查看结果。
# 打印向量搜索结果
def print_vector_results(res):
for hits in res:
for hit in hits:
entity = hit.get("entity")
print(f"text: {entity['text']}")
print(f"distance: {hit['distance']:.3f}")
print("-"*50)
print(f"数量:{len(hits)}")
首先,我们使用 BM25搜索。
# 使用稀疏向量BM25搜索
query1 = ["人工智能如何影响汽车行业?"]
query_sparse_vectors_bm25 = bm25_ef.encode_queries(query1)
field_name = "sparse_vectors_bm25"
output_fields = ["text"]
# 指定搜索的分区,或者过滤搜索
res_sparse_vectors_bm25 = vector_search(query_sparse_vectors_bm25, field_name, search_params_sparse_vectors, output_fields)
print_vector_results(res_sparse_vectors_bm25)
但是并没有搜索到任何结果:
数量:0
为什么呢?我们查看下 query1的分词结果:
# 查看query1的分词结果
print(analyzer(query1[0]))
分词结果只有“人工智能”一个词:
['人工智能', '影响', '汽车行业']
BM25的词汇表中虽然有“智能”这个词,但是并不包含“人工智能”、“影响”和“汽车行业”这些词,所以没有返回任何结果。
我们把“人工智能”替换成“机器智能”,就可以搜索到了。
# 使用稀疏向量BM25搜索
query2 = ["机器智能如何影响汽车行业?"]
query_sparse_vectors_bm25 = bm25_ef.encode_queries(query2)
field_name = "sparse_vectors_bm25"
output_fields = ["text"]
# 指定搜索的分区,或者过滤搜索
res_sparse_vectors_bm25 = vector_search(query_sparse_vectors_bm25, field_name, search_params_sparse_vectors, output_fields)
print_vector_results(res_sparse_vectors_bm25)
而且,这次还搜索到了包含“机器学习”的句子。
text: 机器智能的未来充满潜力。
distance: 2.054
--------------------------------------------------
text: 大数据支持是机器智能发展的关键。
distance: 1.752
--------------------------------------------------
text: 机器学习正在改变我们的生活方式。
distance: 0.788
--------------------------------------------------
数量:3
这是因为分词时把“机器智能“分成了“机器”和“智能”两个词,所以能搜索到更多句子。
# 查看query2的分词结果
print(analyzer(query2[0]))
分词结果:
['机器', '智能', '影响', '汽车行业']
接下来,我们使用 splade 搜索,看看和 BM25的搜索结果有什么不同。
先定义一个打印结果的函数。
# 打印向量搜索结果
def print_vector_results_en(res):
for hits in res:
for hit in hits:
entity = hit.get("entity")
print(f"text_en: {entity['text_en']}")
print(f"distance: {hit['distance']:.3f}")
print("-"*50)
print(f"数量:{len(hits)}")
然后使用 splade 搜索。
query1_en = ["How does artificial intelligence affect the automotive industry?"]
query_sparse_vectors_splade = splade_ef.encode_queries(query1_en)
field_name = "sparse_vectors_splade"
output_fields = ["text_en"]
res_sparse_vectors_splade = vector_search(query_sparse_vectors_splade, field_name, search_params_sparse_vectors, output_fields)
print_vector_results_en(res_sparse_vectors_splade)
比较 BM25 和 splade 的搜索结果,我们很容易发现它们之间的区别。splade 的文档集合中并不包含“artificial intelligence”这个词,但是由于它具有“举一反三”的能力,仍然搜索到了包含“AI”、“machine intelligence”以及“Autonomous”的句子,返回了更多结果(其实是返回了所有文档)。
text_en: The future of machine intelligence is full of potential.
distance: 10.020
--------------------------------------------------
text_en: Big data support is key to the development of machine intelligence.
distance: 8.232
--------------------------------------------------
text_en: AI can help doctors diagnose diseases.
distance: 7.291
--------------------------------------------------
text_en: Autonomous driving relies on advanced algorithms.
distance: 7.213
--------------------------------------------------
text_en: Production efficiency can be improved through automation technology.
distance: 6.999
--------------------------------------------------
text_en: Machine learning is changing our way of life.
distance: 6.863
--------------------------------------------------
text_en: Data analysis technology is widely applied in the financial field.
distance: 5.064
--------------------------------------------------
text_en: The quantum tunneling effect allows electrons to pass through potential barriers that classical mechanics consider impassable, which has important applications in semiconductor devices.
distance: 3.695
--------------------------------------------------
text_en: Deep learning performs exceptionally well in image recognition.
distance: 3.464
--------------------------------------------------
text_en: Natural language processing is an important field in computer science.
distance: 3.044
--------------------------------------------------
数量:10
如果把查询中的“artificial intelligence”替换成“machine intelligence”,仍然会返回所有结果,但是权重有所不同。
text_en: The future of machine intelligence is full of potential.
distance: 15.128
--------------------------------------------------
text_en: Big data support is key to the development of machine intelligence.
distance: 12.945
--------------------------------------------------
text_en: Machine learning is changing our way of life.
distance: 12.763
--------------------------------------------------
text_en: Production efficiency can be improved through automation technology.
distance: 7.446
--------------------------------------------------
text_en: AI can help doctors diagnose diseases.
distance: 6.055
--------------------------------------------------
text_en: Autonomous driving relies on advanced algorithms.
distance: 5.309
--------------------------------------------------
text_en: Data analysis technology is widely applied in the financial field.
distance: 4.857
--------------------------------------------------
text_en: The quantum tunneling effect allows electrons to pass through potential barriers that classical mechanics consider impassable, which has important applications in semiconductor devices.
distance: 3.356
--------------------------------------------------
text_en: Deep learning performs exceptionally well in image recognition.
distance: 3.317
--------------------------------------------------
text_en: Natural language processing is an important field in computer science.
distance: 2.688
--------------------------------------------------
数量:10
藏宝图
如果你想深入研究稀疏向量,可以参考下面的资料:
代码可通过链接获取:https://pan.baidu.com/s/18BgYOdKw2suuwhTggNlINA?pwd=1234 提取码: 1234
 江浩
江浩Zilliz 黄金写手

