



放弃ES,用向量数据库构建网站AI查询助手才是王道
技术开发过程中,你是否也经常面临这种困境:
产品经理和老板催着快速交付结果,但开发过程中遇到的技术文档复杂又臃肿,对于一个新人来说,想要直观快速的了解开发平台上的各种功能和特性难如登天。
当然,多数平台都在其技术文档中提供基于ES的基本搜索功能,开发者输入关键词,平台就能提供一系列相关文档来回答问题,但这种基本搜索功一般都是基于关键词,做精准匹配,故而难以理解我们查询中的真正语义,从而导致返回不相关或者不完整的搜索结果。
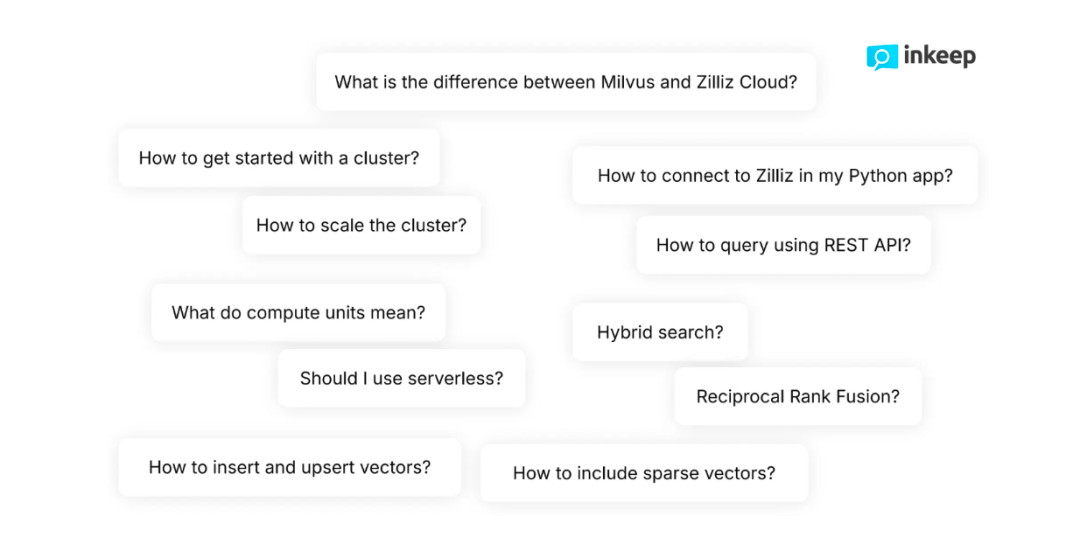
例如,在浏览 Zilliz 的技术文档时,开发者通常会提出以下问题:“如何在检索中,同时使用稀疏向量和稠密向量?”或“如何动态扩展集群?”
用ES等方式构建的基础搜索通常准确回答这些细致且复杂的问题。
 1.23-1.png
1.23-1.png
图一:开发者询问和 Milvus 相关的经典问题
加入 AI 助手则可以很好的解决这些问题。通过大模型、RAG__等自然语言处理(NLP)技术驱动, AI 助手可以通过理解开发者查询背后的意图和语义信息,进而提供答案或定位到精确的页面。
那么,如何构建一个聪明的文档检索助手?接下来,我们将对其基本原理以及实现路径进行解读。
01.
实现路径:检索增强生成(RAG)
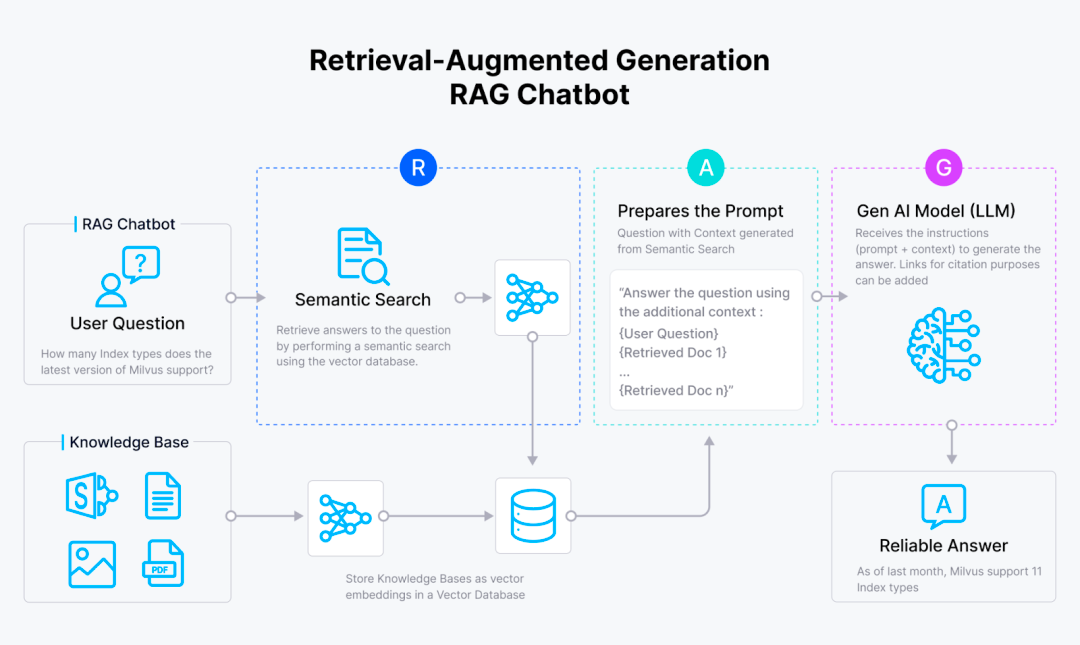
通常来说,我们会用RAG(检索增强生成)来搭建文档内内容搜索的基础架构。通过结合向量搜索和大型语言模型(LLMs),RAG可以对用户查询生成准确的答案。
其工作流程大概是这样的:用户提出一个问题,RAG 对包含查询答案的相关文档进行检索,接着,查询和相关文档会被合并成一个连贯的 prompt发送给大型语言模型(LLM),并最终生成答案。
在以上流程中,RAG 的核心作用是为 LLM 提供相关上下文。这种方法至少有两个好处:首先,它减少了 LLM 产生幻觉的风险,即生成不准确和不真实的回答。其次,LLM 生成的回答会更加贴合上下文,并针对我们的查询进行调整。以上优势,使得RAG在 查询内部文档内容时,相较单一的LLM而言,内容生成会更加的精准与高效。
 1.23-2.png
1.23-2.png
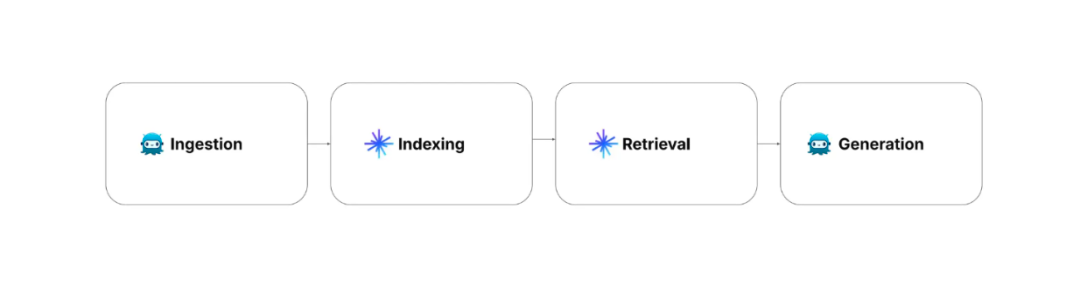
在具体构建 RAG 时,主要有四个步骤:数据整理、索引、检索和生成。
数据整理: 主要包括数据的收集和预处理,可能会收集每条记录的相关信息和元数据。
索引: 使用优化的索引方法来存储数据,从而实现快速检索。在这个步骤中,预处理的数据会通过一个 embedding 模型,转换为向量 embedding,然后使用 FLAT、FAISS 或 HNSW 等高级索引算法,存储在 Milvus 等向量数据库中。
检索: 主要包括向量搜索操作,将用户的查询与存储的数据进行匹配。在这个过程中,用户的查询会通过与存储数据相同的 embedding 模型转换为 embedding向量。然后,在用户的查询和存储数据之间,执行相似性搜索,从而在向量数据库中找到最相关的信息。
生成: 利用 LLM 与检索结果生成最终答案。首先,将用户的查询和检索获得的最相关上下文合并成一个 prompt。然后,LLM 根据 prompt 中提供的上下文,生成对用户查询的响应。
 1.23-3.png
1.23-3.png
图:RAG 的步骤
在实施上述每个步骤时,我们需要考虑几个因素。例如,在数据整理阶段,我们需要考虑数据来源、数据清理方法以及 chunking 方法。同时,在索引阶段,我们需要选择合适的 embedding 模型和向量数据库,以及适合我们的索引算法。
在下一部分中,我们将详细讨论,如何使用大模型和向量数据库构建 AI 助手,以及这个 AI 助手怎样用于 Zilliz 和 Milvus 网站内的文档查询。
02
教程:如何构建 AI 助手
如前所述,构建RAG 的第一步是数据整理。在这一步骤中,我们需要先从各种来源(如技术文档、支持与常见问题解答页面以及 GitHub )收集与 Zilliz 和 Milvus 相关的文本数据。这些文本数据随后被清洗和 chunking,以确保每条信息既不过于宽泛,也不过于细碎。
在进入下一步之前,也会收集每条 chunking 记录的元数据。这些元数据包括:
来源类型:数据通常来自 GitHub 、技术文档、支持与常见问题解答页面等。
记录类型:包括数据的版本、文本与代码。如果是代码,还会记录所使用的编程语言。
层次结构引用:包括每个数据点的子节点、父节点和兄弟节点,这些数据是从 Zilliz 的网站收集的。
URL、标签、路径:例如数据来源的 URL。这些元数据非常有用,因为它们在 LLM 生成的响应中,提供了引用或来源链接。
日期:每条数据的发布日期。
收集了数据和元数据之后,接下来,我们需要将预处理的数据转换为向量 embedding,然后在检索环节中实现相似性搜索。
将数据转换为向量 embedding的过程中,我们往往需要思考,到底应该将其转化为稀疏 embedding ,还是稠密 embedding 。
其中,稀疏 embedding 通常用于关键词匹配以及是或非的布尔匹配。因此,通过稀疏 embedding 查询到的相关文档,通常包含查询的关键词。我们通常有两种不同类型的模型可以将数据转换为稀疏 embedding:基于传统统计的 embedding模型和基于深度学习的 embedding模型。本次 AI 助手的构建中,我们可以使用 BM25 作为基于传统统计的 embedding模型,使用 SPLADE/BGE-M3 作为深度学习的 embedding模型。
而稠密 embedding 则更适合捕捉查询中的细微差别或语义含义。通过稠密 embedding 获取的文档,不一定包含我们所查询的关键词,但它的内容通常与查询高度相关。要将数据转换为稠密 embedding,有许多深度学习模型可供选择,例如 OpenAI、Sentence-Transformers、VoyageAI 等的 embedding 模型。此次AI助手的构建,我们后续会使用三种不同的 embedding 模型:MS-MARCO、MPNET 和 BGE-M3。
 1.23-4.png
1.23-4.png
图:稀疏和稠密嵌入
一旦所有数据都转换为稀疏向量和稠密向量表示后,这些数据就会被存储在向量数据库中,就可以实现快速检索。
但看到这里,你可能会有疑问,那就是为什么我们需要对多种稀疏 embedding 和稠密 embedding结合使用,而不是只选择一种模式呢?
答案是,在实际部署中,单纯的语义检索,或者单纯的关键词检索,都是比较少见的。例如,如果我们的查询较短(少于5个词)的内容,那么使用稀疏 embedding 可能就足够了。而如果我们的查询较长,那么在大多数情况下,使用稠密 embedding 会提供更好的结果。
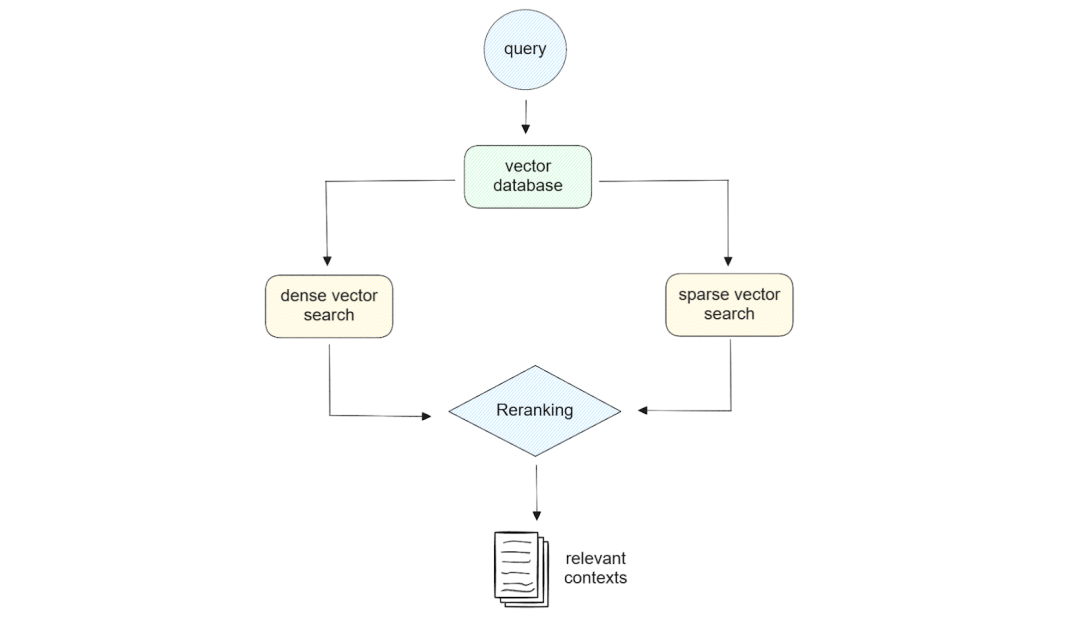
此外,如果我们使用 Milvus 作为向量数据库,我们可以利用它的混合搜索能力,即结合稀疏 embedding 和稠密 embedding 进行相似性搜索。此外,在前不久推出的milvus 2.5中,我们还在2.4版本的稀疏向量检索和混合检索基础之上,还推出了全文检索(FTS,Full-Text Search)功能以应对不同客户的多种向量检索需求。
 1.23-5.png
1.23-5.png
图:混合搜索示意图
值得一提的是,当用混合搜索来查询最相关的内容时,我们还需要考虑如何进行结果的重排。在本次文档助手的部署中,我们会采用两种不同的重排方法:加权评分(WeightedRanker )和倒数排序融合(RRF)。
加权评分背后的机制很简单:我们为每种方法分配一个权重。例如,我们可以为稠密 embedding 的相似性结果分配60%的权重,为稀疏 embedding 分配40%的权重。
而在 RRF 中,上下文的得分是通过将它们在两种不同方法中的倒数排名相加,来计算得到的,通常会加上一个小的常数,是以避免除以零的情况。
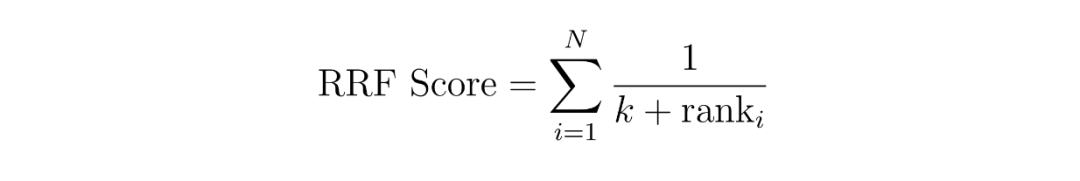 1.23-6.png
1.23-6.png
图:RRF计算函数
其中,是方法的数量,这里应该是 2,因为我们采用了稀疏 embedding 和稠密 embedding 这两种结合的混合搜索。变量“”是上下文在方法中的排名,是一个常数。
使用上面的 RRF 公式,我们可以计算每个上下文的 RRF 得分。得分最高的上下文,将被确定为和查询最相关的上下文。
一旦获取了相关上下文,原始查询和最相关的上下文,将被合并成一个 prompt。然后,这个 prompt 将被发送到 LLM,生成最终的响应,接下来大模型选型中,我们会主要使用 OpenAI 和 Anthropic 的模型。
完成以上流程,一个完整的文档AI助手搭建就正式完成了,你那可以在 Milvus 的官网文档页面上对其进行体验。
03
效果展示
当你打开 Milvus 文档页面时,会在屏幕右下角看到“Ask AI”按钮。点击此按钮即可访问AI助手。
 1.23-7.png
1.23-7.png
接下来,会弹出一个屏幕,提示你输入任何你想在Milvus文档中查找的内容。你也可以选择点击弹出屏幕右上角的“Search”选项,进行基本搜索。
假设我们想知道如何使用 BGE-M3 和 Milvus Python SDK ,将数据转换为向量 embedding。我们只需简单地输入问题,AI 助手就会给我们提供答案。
 1.23-8.png
1.23-8.png
除了提供回答外,AI 助手还会给出引用或相关页面,以便我们进一步查找与生成答案相关的信息。
 1.23-9.png
1.23-9.png
图:截屏信息
04
结论
RAG(检索增强生成)是构建页面内 AI 助手的核心组件,它可以帮助 LLM(大型语言模型)在处理细致且复杂的查询,并提供了更准确且贴合上下文的回答。 而像 Milvus 这样的向量数据库,则是 RAG pipeline 中的关键组件,负责执行索引和检索步骤。


