



深度分析 | 自动驾驶数据挖掘的三座大山与向量数据库胜负手
自动驾驶这盘棋,从2014年热到2024年,烧掉了千亿,从“万箭齐发”到漫长低谷,但故事到了这两年,开始变得不一样了。
2024年3月,伴随华为技术加持问界M9大规模交付,几乎开箱即用的智驾功能,在此后长达一年时间里蝉联中国市场50万元以上价位销量冠军的背景下,成为豪车标配。
同一时期,作为国内智驾投入最为激进的车企,小鹏正式宣布,面向智驾经验用户即刻推送无限XNGP智能辅助驾驶功能,并且,该功能将不限城市、不限路线,有导航的地方就能使用。
仅仅一个月后,4月20日的智能驾驶发布会上,蔚来宣布全域领航辅助NOP+“全域全量”落地,正式从高速走向城区,向全量NT2平台的车型用户推送。
行业从“预言期”走向“检验期”,量产、落地、安全成为新的关键词。
一边是算法飞驰,另一边却是数据挖掘与处理的滞后:数据挖掘手段陈旧、corner case 难以捕捉、数据采集成本居高不下,三座大山挡在真正智能化的前夜。
围绕如何让自动驾驶更低成本的挖掘与利用数据,一场新的数据挖掘范式变革,正悄然展开。
01 自动驾驶数据挖掘的三座大山
关于真正的无人驾驶什么时候才能实现,知名智库兰德曾有一个很有意思的说法:自动驾驶汽车需要行驶110亿英里,才能比人类表现高出20%。
当单位到了亿级很多人就没了概念,我们对此做一下拆分就会发现其中的吊诡之处:普通人一年开车的总里程大概是1.3万英里,达成110亿英里,需要大约100万年。即使换成时速25英里、24小时无休、100辆车组成的自动驾驶车队,达成110亿英里,也需要足足518年的时间。
而人类历史上,汽车的出现迄今,也不过一百四十余年。
再更进一步算一笔账, IBM官方曾给出一个数据,仅 Nvidia 一辆测试车辆上的摄像头,每小时就能产生 1TB 的数据,而量产车队每天则可能生成数百万个有效数据。如果人工标注这些验证数据来发现这些场景,那么每天仅行驶 8 小时的 100 辆车车队就需要超过 100 万名标注员来管理车辆上所有摄像头拍摄的帧。(source:What Is Active Learning?-nvidia)
线性外推:标出110亿英里英里的数据,需要100 万*3*518,大约15亿名标注员一齐上阵,对应的存储、计算资源更是超出当下科技进步之所能。
那么,有什么办法,能够让自动驾驶的训练速度再快一点?
答案是,对自动驾驶来说,数据从来不稀缺,好数据才稀缺。无论是来自人类司机的驾驶数据,还是自动驾驶的路测数据与虚拟环境的合成数据,我们并不需要全部对其进行处理。通过清洗筛选,剔除无效数据后的内容,才能用于自动驾驶训练。
不过,清洗后的数据总量同样惊人:2022年,作为自动驾驶方案的头部供应商,Mobileye 坐拥约 200PB 的海量驾驶数据。基于这个数据集,Mobileye 针对多数长尾场景,可在数秒内提供数千条结果。但代价则是,Mobileye 丰富且相关的数据集需要由 2,500 多名专业标注员组成的团队自动和手动进行标注。该计算引擎依靠 AWS 云端 50 万个峰值 CPU 核心,每月处理 5,000 万个数据集。
但对于这样的海量数据集标注,传统的人工标注正在失效,这种失效可以从三方面去解读:
- 其一,纯手工标注成本居高不下。长尾场景需要复杂的时空理解、视频级别的逐帧解析和跨模态信息融合,需要对视频、传感器数据等多模态信息进行逐帧解析,导致单视频片段的标注成本是静态图像的 3-5 倍。即使是经验丰富的标注员,处理一个典型场景的效率也仅为 2–5 分钟/例,错误率居高不下。
- 其二,手动标注的效率与能力也在不断与行业需求脱轨。自动驾驶数据涉及多传感器输入(如摄像头、激光雷达、GPS等),其标签体系需要保持跨模态对齐。人工维护的过程中,时间同步误差、标注标准不统、需求理解偏差等问题常导致返工率高达20%-30%,严重影响数据质量和算法训练效果,数据清洗和标签修正的成本可能高达数百万元。
- 其三,纯手工标注在数据的完整语义识别上仍有劣势。传统的手工标注,在框选红色卡车、夕阳、红绿灯之类的需求面前毫无压力;可是一旦需求变为一个非常具体的真实场景:红色卡车在夕阳下向左转向,此时恰好碰到黄灯,斑马线上又有一个牵着小狗缓慢行走的老太太,这样的复杂描述,再精细的手工标签也会彻底崩溃失灵。
数据挖掘手段陈旧、corner case 难以捕捉、数据采集成本居高不下,成为自动驾驶数据管理头顶的三座大山。
旧的范式已经逐渐失灵,但新的范式又该是什么?
02 向量数据库,如何成为Corner case挖掘新范式?
大模型与向量数据库的发展,带来了自动驾驶数据挖掘的新解法。
变革的第一步发生在挖掘侧,从传统yolo到最新的大模型,各种层出不穷的数据挖掘算法,开始取代手工打标。
早几年,行业会引入跨模态模型(如 CLIP)和向量搜索技术,生成弱标签或自然语言,并对其进行相似性检索,但这一时期的语义理解仍较粗糙。
到了近两年,通过多模态大模型(如 GPT-4o、Gemini),已经无需随着数据需求的变化而微调模型,就能够在大型数据集中识别罕见或复杂的模式,直接从原始视频中提取细粒度语义。而基于多模态大模型输出的视频级别的 Cilp、图像级别的 Frame 以及子图级别的 Sub-object等数据,会进一步变成标签、文本描述、embedding(text、video、inage)形式,被存储与检索,显著提升数据挖掘效率与智能化水平。
伴随数据挖掘的范式发生进化,传统数据检索与管理,也随之产生巨变。向量数据库开始取代传统的数据库产品来辅助企业进行海量非结构化数据检索,是这一时期的鲜明特征。
传统数据库只能根据各种标签以及数据进行内容筛选,在做大规模向量检索(上亿乃至十亿)时存在天然劣势之外,对多模态数据对齐、复杂场景语义筛选上,也存在先天不足。
而向量数据库除了传统的标签检索、数据检索之外,还能支持更高级的以文搜图、以图搜图。更进一步,Zilliz Cloud为代表的现代向量数据库还支持多向量列等高级操作,如对文本(图像内容描述)、向量、标签同时进行多路检索。
当然,语义检索成为新的显学的同时,并不意味着传统标签检索的失效或淘汰。要想落地自动驾驶,向量数据库还必须同时具备语义+标签的两大核心检索能力。
而这也是生产级向量数据库产品的最大特色。以 Zilliz Cloud /Milvus为例,它们不仅能支持以向量为核心的存储、索引和管理,兼顾海量数据的高效读写和可扩展性;同时,针对标量数据,也具备完善的数据类型支和索引加速能力。
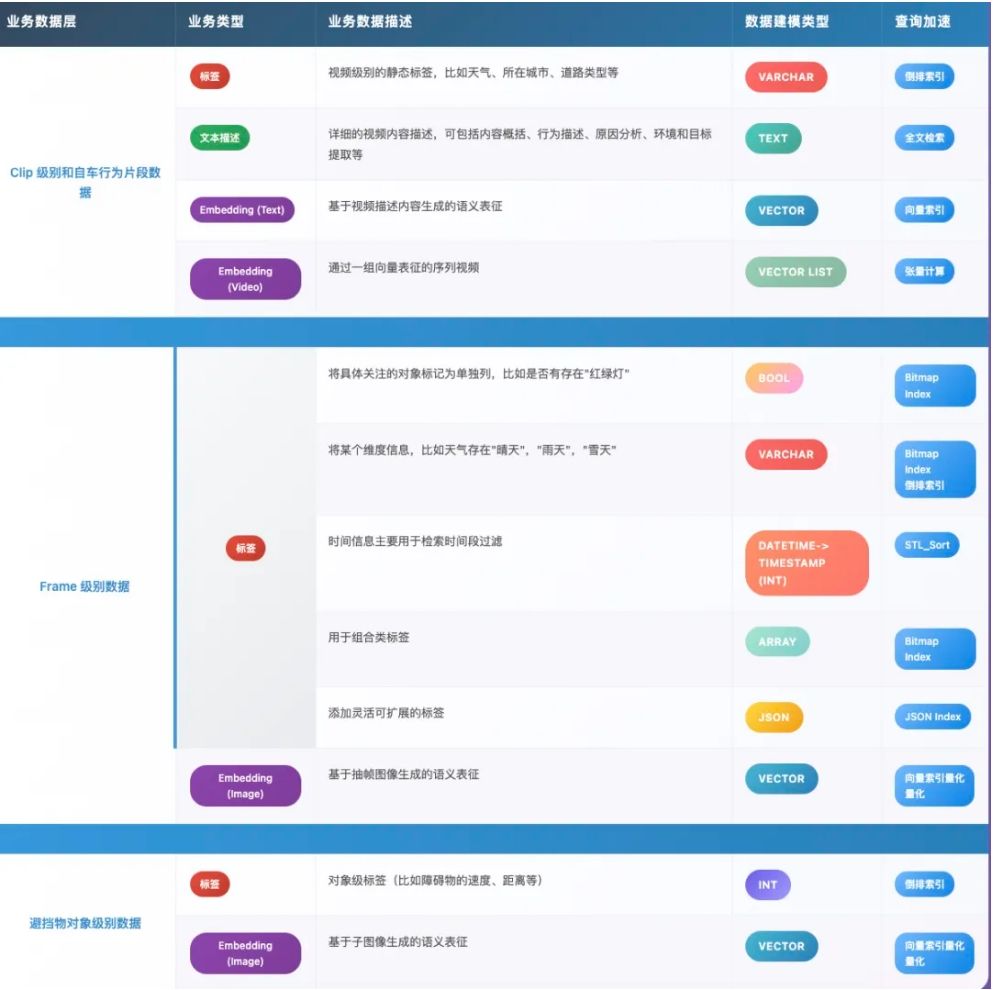
以下是 Zilliz Cloud /Milvus针对不同类型自动驾驶数据的能力建设:

Tire1巨头博世就是一个最好的例子,通过合作Milvus,博世能够从已有的数据库中挖掘出70%-80%所需场景,如果所需数据已经存在于数据库中,可以实现几乎即时的数据获取;而相比其他向量数据库产品,最令博世意外之处就在于,Milvus 提供的量化索引技术还大幅降低了存储和计算资源的消耗,让博世在处理大规模数据集时不必在成本与效率之间反复权衡,企业每年数据存储成本减少近千万。
03 成本如何成为自动驾驶数据挖掘的胜负手
对一个典型的自动驾驶企业来说,其数据管理难点,除了Corner case挖掘之外,还需要重点考虑另一件事情——成本。
近些年来,随着车企取代传统科技公司,成为自动驾驶产业的最大甲方,一个技术如何能够快速在汽车上普及,标准也逐渐变得明确:能不能塞进20万以内的车里?
然而,现实是,从激光雷达到GPU,链条上每一环都太贵了:
感知层:激光雷达平均成本上千乃至一万,一台车动辄多颗;摄像头虽然便宜,但你得配好几 个才能搞定全车视野;
算力层:大模型 + 多传感器同步处理,让 GPU 成本飞涨;高算力芯片(如Orin-X)一颗动辄 3000+ 元,还不一定能撑起大模型推理;
数据层:每天数百 GB 原始感知数据,后端还要数据标注、仿真训练、存储、回传、OTA更新、策略部署…
上到高速容易,下到本地数据中心难——算力黑洞 + 数据成本地狱,成了影响很多车企使用新技术的难关。
但所有数据都值得被一视同仁,以相同成本对待吗?
某头部新势力车企,在建设智能驾驶数据平台时,一度计划采购市面上某头部向量数据库方案,用于数据管理。要求也很简单,能存下来(要存冷数据 + 热数据);管起来(文本、标签、embedding全都支持);搜得出(要支持高并发、低延迟检索);与此同时,能支持批量的数据导入,而且还得每次模型迭代都能支持批量替换embedding。可一测算成本,管理内部百PB级别数据,采用传统向量数据库,每年的成本将高达千万乃至上亿人民币,计划瞬间告吹。
但事实上,数据天然分冷热、也分在线与离线。自动驾驶场景中,多数数据任务都集中在大量数据去重、数据分析等离线任务。对于这类数据,采用传统向量数据库往往是一种性能冗余。
因为这种离线数据分析任务通常具有以下特点:
数据量巨大:通常需要处理百亿级甚至更大规模的数据集,这对成本和效率都提出了更高的要求,需要合理设计数据存储和索引方式,提高读取和计算效率,同时降低存储冗余和计算成本。
延迟容忍度较高:相较于实时查询,离线任务允许较长的处理时间,例如分钟级甚至小时级,以换取更低的计算和存储成本。
数据预处理复杂,计算资源消耗大:数据处理以批量和分布式的方式进行,包括数据清洗、转换、索引构建、聚合分析等。在数据清洗、转换、降维等环节,计算资源消耗大,传统的单机处理方式难以满足需求,需要高效的分布式计算方案。
数据格式不统一:数据存在多份拷贝,用于不同目的的计算和处理,复杂的转换过程和冗余的存储。需要专门的面向海量数据检索成本优化的方案。
Zilliz Cloud 提出的 Vector Lake(向量数据湖)方案,正是为此而生。
该方案的特性,用一句话总结即是(牺牲一定召回时间的情况下)用存算分离架构,解决海量离线数据处理中的成本问题。
该方案的核心优势在于:
全栈数据整合:在数据层实现了在线与离线数据的无缝对接,确保数据格式统一、高效存储。
融合计算架构:与传统数据湖生态(如 Spark、 Ray 、Iceberg等)天然融合。不仅适用于向量化任务,还能涵盖传统的 ETL、统计分析等业务流程,通过新旧技术的自然融合,丰富的查询方式,实现更复杂的分析能力。
成本可控:设立多级存储,将频繁访问的数据保存在高速存储介质(如 NVMe,SSD),冷数据则归档到对象存储(如 S3),平衡性能与成本。借助先进的数据索引技术与存储策略,可以大幅提升数据读写效率,并支持动态扩展。
总而言之,通过Vector Lake,Zilliz可以真正帮助自动驾驶、大模型训练等具备海量非结构化数据处理需求的企业,完成低成本、一体化数据管理的需求。
04 为什么是向量数据库,为什么是Zilliz?
用向量数据库做自动驾驶数据管理,已经成为多数头部企业的共同选择,但关于如何选择向量数据库,依然是困扰不少企业的新问题。
原因很简单,向量数据库这个赛道太新了。
尽管早在2019年Zilliz就已经开源了全球首个向量数据库产品Milvus,时至今日已经在GitHub取得3.5W star的成绩,但是整个赛道,却已经到了2023年GPT爆火才真正崛起,被大众熟知。
而此后相当长一段时间,行业对向量数据库品牌的认知,几乎可以用面目模糊来形容——看起来区别不大,不到poc几乎感知不到区别。
但自动驾驶是个例外,其天生的海量数据、多维异构数据特性,对向量数据库的要求已经不局限于有索引、分布式、能用,这几个最基础的能力。
更直白来说,自动驾驶企业并不缺数据库——他们缺的是一个企业级的向量数据库产品,而企业级,则可以拆分为适应业务变化、低成本、高效三大重点。
适应业务变化,指的是能适应海量数据的高效导入,也能根据算法的需求变化,对已有数据的 embedding 与标签进行批量替换。
相应的,Zilliz可以提供三大能力。能力一,标签管理与 Schema 演进:支持根据数据特征和业务需求灵活添加标签,通过动态 JSON 列插入任意标签数据,并借助 JSON path index 加速对特定键的访问;并支持增列操作,确保数据结构能随业务发展不断更新,避免频繁的全局重构。能力二,批量替换 embedding:在自动驾驶算法持续迭代的背景下,Zilliz 允许对已有数据的 embedding 进行批量替换,配合 alias 机制可帮助业务在无感切换模型的同时保持数据查询的稳定性:Zilliz 支持同时写入由不同模型生成的向量,并可通过混合搜索(hybrid search)对多向量列进行检索,为模型对比和联合分析提供便利。能力三,批量导入:针对海量数据,Zilliz 提供 bulk_import 批量导入机制,可在保证高吞吐的同时有效控制加载延时。无论数据规模多大,都能保持稳定的导入性能。
低成本与高效,依赖的则是高效索引与量化能力。
围绕量化,Milvus的RabitQ技术,既能实现一比特的极度量化,又能保证高 recall。而围绕高效,针对不同场景与需求,Zilliz cloud /Milvus则推出了不同的索引机制。
通过多样化的搜索查询能力,Zilliz 能够在自动驾驶领域灵活应对不同业务需求:无论是基于文本关键词、向量相似度还是综合标签与属性的混合搜索,都能快速定位目标数据,并结合迭代搜索(Iterator Search)、 RangeSearch 、TopK、重排序(Rerank)等高级检索功能,进一步提高召回精度与查询效率。
与此同时,Zilliz向量数据湖产品通过与Iceberg的对接,对Spark查询的支持,也同样成为了复杂场景分析、低成本数据挖掘与管理的新思路。
目前这一套方案,已经在全球多家头部车企以及自动驾驶平台企业的数据中台落地。(如对具体落地方案感兴趣,可后台私信,我们安排工程师与您1V1交流)
尾声
事实上,自从大模型技术被用于自动驾驶,这场战争就从过去的竞速赛变成了一个维度竞赛。过去拼的是算法,如今比的是数据量、数据质量与基础设施能力。谁能在正确的时间,以最低的代价,找到最关键的那一帧,谁就离终极目标更进一步;长尾场景谁先掌握,谁就拥有最强的数据闭环飞轮。
在此过程中,企业不只在拼参数、卷路线,更深的“算力–数据–成本”三角平衡成为新的关注重点。而围绕三角平衡,大模型、向量数据库与数据湖,则成为了企业底层数据能力的“新三驾马车”。
届时,自动驾驶的漫长竞赛里,最后的赢家,或许不是跑得最快的那一个,而是踩得最稳、看得最远、数据挖得最深的那一个。
 Zilliz
Zilliz


