



详解 BGE-M3 与 Splade 模型
在之前的文章中,我们已经讨论了信息检索技术从简单的关键词匹配到复杂的情境理解的发展,并提出了稀疏 Embedding 向量可以通过“学习”获得的观点。这些巧妙的 Embedding 技术融合了稠密和稀疏向量检索方法的优点。学习型的(Learned)稀疏向量不仅解决了密集检索中常见的跨领域问题,还通过融合更多的上下文信息,增强了传统稀疏向量搜索的能力。
在了解学习型稀疏向量的众多优势后,您可能会好奇哪些模型能生成这类 Embedding 向量。因此,本文将探索两种先进的 Embedding 模型——BGE-M3 和 Splade,深入解析它们的设计理念和工作原理。
快速回顾 Embedding 向量的概念
Embedding 向量或者向量表示,是指在高维向量空间中以数值描述表示对象、概念或实体(Entity)。每个 Entity 由一个向量表示,此向量通常长度固定,每个维度反映了Entity 的一个特定属性或特征。Embedding 向量类型主要分为三种:传统的稀疏向量、稠密向量以及“学习到的”(learned)稀疏向量。
传统的稀疏向量,常用于语言处理领域,其特点是高维且多数维度值为零。这些维度通常代表一个或多个语言中的不同标记,非零值则显示了该标记在特定文档中的相对重要性。例如,BM25 算法生成的稀疏向量通过增加一个术语频率饱和函数和长度规范化因子,对 TF-IDF 方法进行了改进,因此非常适合执行关键词匹配任务。
相反,稠密向量的维度较低,但信息量大,所有维度均为非零值。这种向量通常由 BERT 等模型生成,常用于基于语义相似性而非仅仅是关键词匹配来排序结果的语义搜索任务。
“学习到的”稀疏向量则是一种高级的 Embedding 向量类型,它结合了传统稀疏向量的精确性与稠密向量的丰富语义。这种混合型的向量通过融入上下文信息来增强稀疏向量检索。如 Splade 和 BGE-M3 等机器学习(ML)模型能够生成这种类型的向量。这些模型能学习到可能出现但并非直接出现在文本中的相关标记,从而形成一个有效捕捉所有相关关键词和分类的(“学习到的”)稀疏向量表示。
如需了解如何使用 Milvus 等向量数据库来进行向量搜索或混合搜索,请阅读指南。
BERT:BGE-M3 和 Splade 的模型的基石
BGE-M3 和 Splade 均基于 BERT 架构发展。在我们深入了解这两个模型前,需要先理解 BERT 的基本工作原理,以及它是如何作为基石推动 Embedding 技术的发展。
BERT,全称为 Bidirectional Encoder Representations from Transformers,是自然语言处理(NLP)领域领域内的一大突破。不同于传统模型那样单向处理文本,BERT 通过同时考察整个词序列来捕捉词汇的上下文,且不局限于任何一个方向。 BERT 的核心在于其预训练机制,结合了两种创新策略:
- Masked Language Modeling(MLM):在这一任务中,模型随机隐藏输入的部分词汇,然后训练模型去预测这些被掩盖的词汇。与之前只能理解单向上下文的模型不同,BERT 考虑到了句子整体的上下文,包括掩盖词的左右两边,以填补空缺。
- Next Sentence Prediction(NSP):BERT 在这一任务中学习判断两个句子是否逻辑上连贯,这对于理解段落结构中句子间的关系非常重要。
BERT 架构的关键特性是其自注意力(Self-attention)机制。变换器中的每一层编码器通过 Self-attention 机制来评估句中其他单词在解释某个特定词时的重要性,使得模型能够在不同的上下文中理解词义。
位置编码是另一核心元素,它让 BERT 能够理解词语的顺序,给原本没有位置感的 Self-attention 过程添加了“序列”概念。
BERT 工作原理
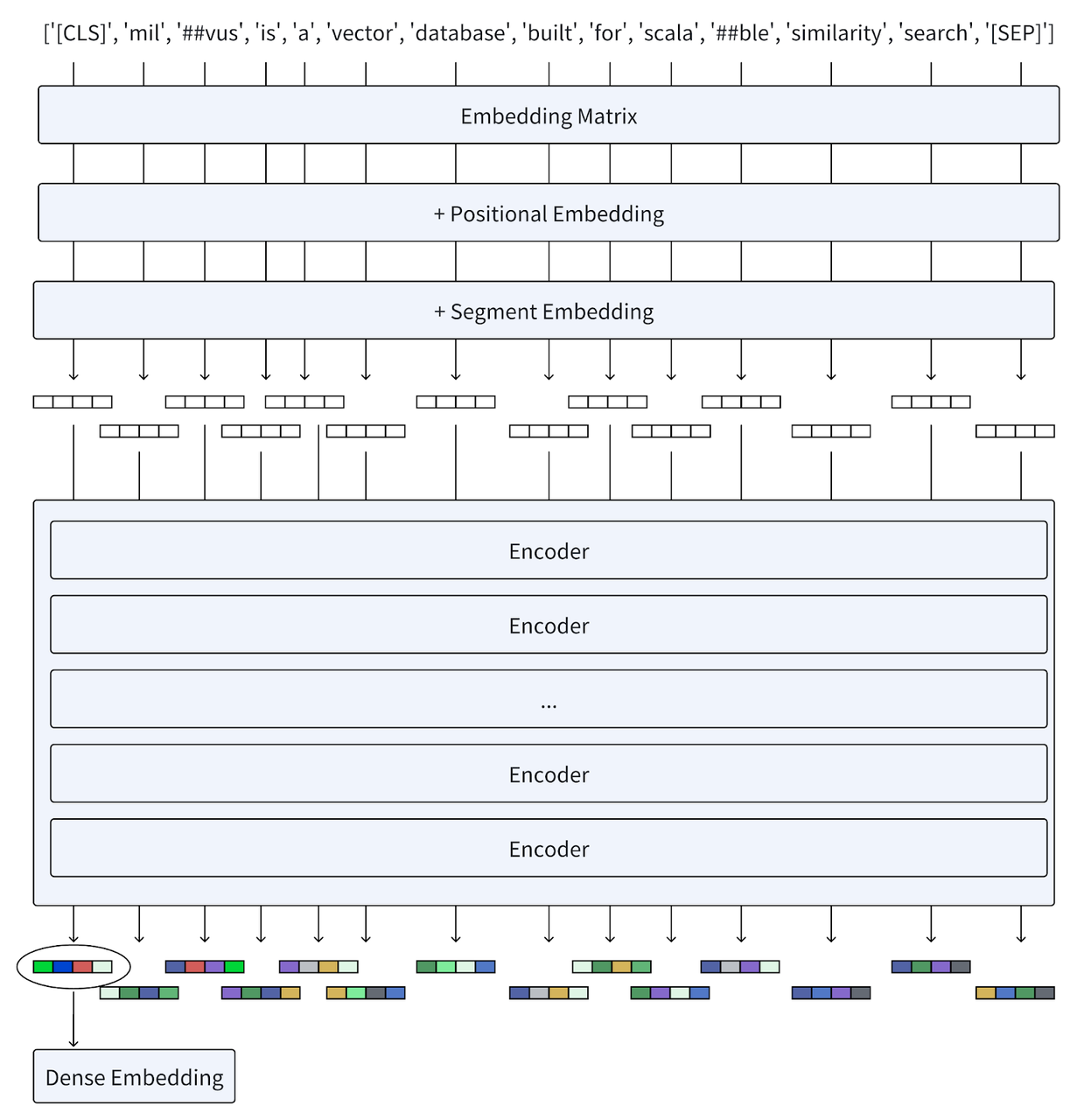
那么 BERT 是如何运作的呢?让我们使用 BERT 将以下这句话转换为 Embedding 向量。
用户查询:Milvus is a vector database built for scalable similarity search.
 mx1.PNG
mx1.PNG
 mx2.PNG
mx2.PNG
当我们将查询输入到 BERT 时,过程如下:
- 分词 (Tokenization):文本首先被分割成一连串的片段。对于句子级任务,在输入的开始处加入
[CLS]Token,并插入[SEP]Token 以分隔句子并标示结束。 - Embedding:每个token通过一个 Embedding Matrix 转化为向量,这与 Word2Vec 等模型类似。然后在这些 Token Embeddings 中加入位置 Embeddings,以保存词序信息;同时,Segment Embeddings也被加入,用以区别不同的句子。
- 编码器(Encoder):向量经过多层 Encoder,每层都包含 Self-attention 机制和前馈神经网络(Feed-forward neural network)。这些层根据序列中所有其他 Token 提供的上下文进行迭代,精细化每个 Token 的向量化表示。
- 输出:最终层输出一系列 Embeddings。通常情况下,对于句子级任务,
[CLS]Token的 Embeddings 代表了整个输入的向量表示。个别 Token 的 Embeddings 用于更细粒度的任务任务,或通过操作(如最大池化或求和池化)合成一个稠密向量。
BERT 生成的稠密向量可以捕捉单词间的含义及其在句子中相互之间的关系。这种方法适用于各种语言理解任务,为 NLP 性能测试设定了新标准。
现在我们已经理解了 BERT 如何生成稠密向量,接下来让我们深入探索 BGE-M3 和 Splade 是如何生成 Learned 稀疏向量的。
BGE-M3
BGE-M3 是一种先进的机器学习模型,它扩展了 BERT 的能力,注重通过多功能性(Multi-Functionality)、多语言性(Multi-Linguisticity)和多粒度性(Multi-Granularity)增强文本表示。该模型不仅仅用于生成稠密向量,还可以用于生成 Learned 稀疏向量,尤其适用于需要精准处理细微信息含义的信息检索任务。
BGE-M3 工作原理
BGE-M3 是如何生成 Learned 稀疏向量的呢?让我们使用同样的用户查询来展示 BGE-M3 的工作原理。
 mx3.png
mx3.png
同 BERT 一样,BGE-M3 生成 Learned 稀疏向量的第一步是分词并将输入文本编码为一系列包含上下文的 Embeddings ( H )。
 mx4.png
然而,BGE-M3 通过使用更精细的方法来创新这一过程,以捕捉每个 Token 的重要性:
mx4.png
然而,BGE-M3 通过使用更精细的方法来创新这一过程,以捕捉每个 Token 的重要性:
- Token 重要性评估:BGE-M3 不只是依赖 [CLS] token 的表征(H[0]),还评估了序列中每个 Token 的情境化嵌入(H[i])。
- 线性变换:在编码器栈的输出上添加了一个额外的线性层。通过此层计算每个 Token 的重要性权重,BGE-M3 得到了一组权重(W_{lex})。
- 激活函数:通过应用修正线性单元(ReLU)激活函数到(W_{lex})与(H[i])的乘积上,计算每个 Token 的词项权重(w_{t})。使用 ReLU 确保词项权重非负,有助于增强向量的稀疏性。
- Learned 稀疏 embedding:最终输出是一个稀疏的 embedding,其中每个 Token 都与一个表明其在整个文本中的重要性权重值相关联。
这种表达形式丰富了模型对语言细节的理解,并为那些需要同时关注语义和词汇要素的任务(如大规模数据库中的搜索和检索)定制了 Embeddings。BGE-M3 标志着我们在更精确、更高效地筛选和解读大量文本数据方面迈出了重要一步。
SPLADE
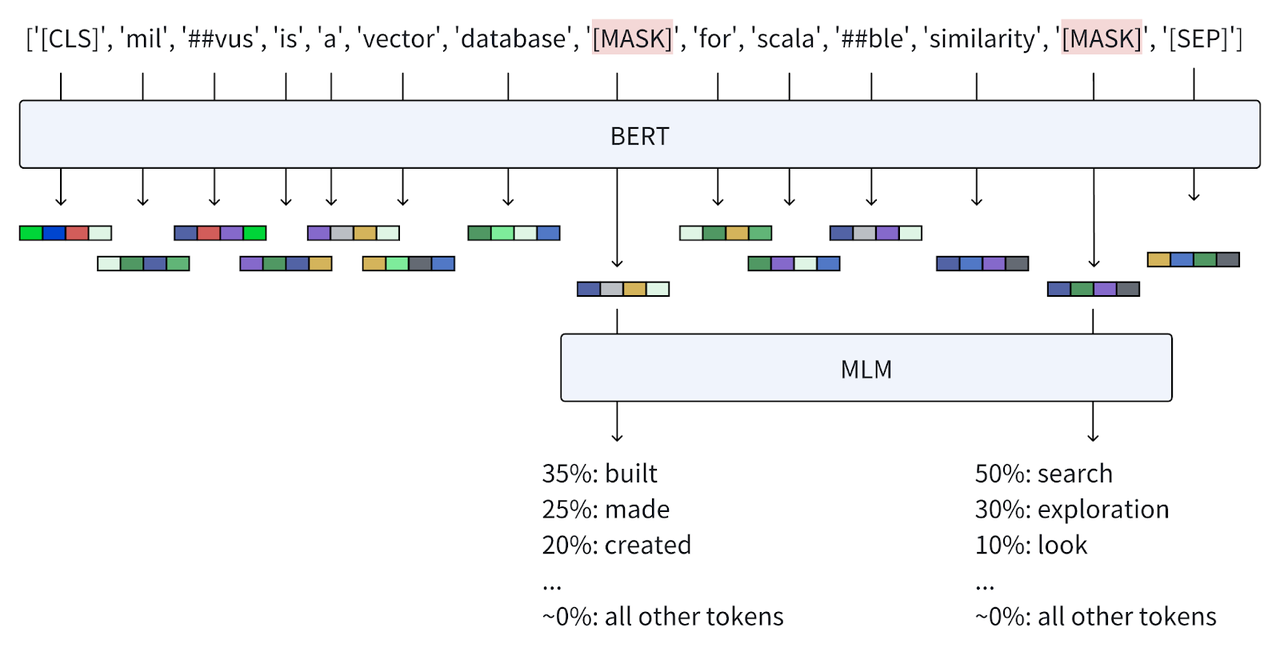
SPLADE 标志着在生成 Learned 稀疏向量方面的进步,它基于 BERT 架构增加了一种独特的方法来优化 Embedding 的稀疏性。让我们先回顾一下 BERT 训练机制的核心部分——MLM。
MLM 是一种强大的无监督学习任务,隐去了部分输入的 Tokens,要求模型仅依据其上下文推断这些隐藏的词汇。这种技术增强了模型对语言的理解能力及对语言结构的认知,因为它需要依赖周围的 Tokens 来正确填补这些空缺。
 mx5.png
mx5.png
在实际应用中,对于预训练阶段的每个掩码位,模型使用 BERT 的上下文化 Embedding ( H[i] )生成一个概率分布( w_i ),其中 w_{ij} 指的是特定 BERT 词库 Token 出现在掩码位的可能性。这个输出向量( w_i ),其长度与 BERT 庞大的词汇量(通常为 30,522 个单词)相匹配,为精细化模型的预测提供了关键的学习信号。
 mx6.png
注意:上方图表中的可能性数据并非真实数据仅作示意。
mx6.png
注意:上方图表中的可能性数据并非真实数据仅作示意。
SPLADE 在编码阶段利用 MLM 的强大功能。初始 Tokenization 和转换为 BERT 向量后,SPLADE 对所有标记位置应用 MLM,计算每个 Token 与 BERT 词汇表中每个单词的对应概率。接着,SPLADE 对每个词汇的这些概率进行聚合,并通过应用日志饱和效应的规范化方法来促进向量的稀疏性。得到的权重反映了每个词汇与输入 Token 的关联性,从而生成了一个 Learned 稀疏向量。
SPLADE 的 Embedding 技术的一个显著优势在于其固有的术语扩展能力。它能够识别并包含原始文本中未出现的相关术语。例如,在给出的示例中,虽然 "探索"(Exploration) 和 "创建"(Created) 未在初始句子中出现,但它们仍然在稀疏向量中出现。对于我们示例查询这样的简短输入而言,SPLADE 能通过扩展其包含 118 个 Token 的上下文来增强精确术语匹配的能力,显著提高了模型在检索任务中的精确度。
这个复杂的过程展示了 SPLADE 如何基于传统 BERT,衍生其颗粒度和适用性,使 SPLADE 特别适用于追求术语广泛度和精细度的搜索和检索任务中。
总结
我们通过这篇文章在错综复杂的 Embedding 向量世界中遨游,展现了如何从传统的稀疏和稠密向量向创新的 Learned 稀疏向量迈进,探索了生成创新型 Learned 稀疏向量的方法。我们深入剖析了两种 ML 模型——BGE-M3 和 Splade,介绍了这两个模型是如何生成向量的。
这些先进的 Embedding 技术能够改良搜索与查询系统,为打造直观且灵敏的平台注入了新动力。后续我们将发布更多文章,展示这些技术在实际应用中的影响力,敬请期待!



