



深度解读英伟达最新世界基础模型Cosmos:用AI数据训练AI算法,彻底闭环了?
 1.jpg
1.jpg
AI的下一个杀手级爆点是什么?
刚刚落幕的CES上,英伟达CEO黄仁勋给出的答案是物理AI。
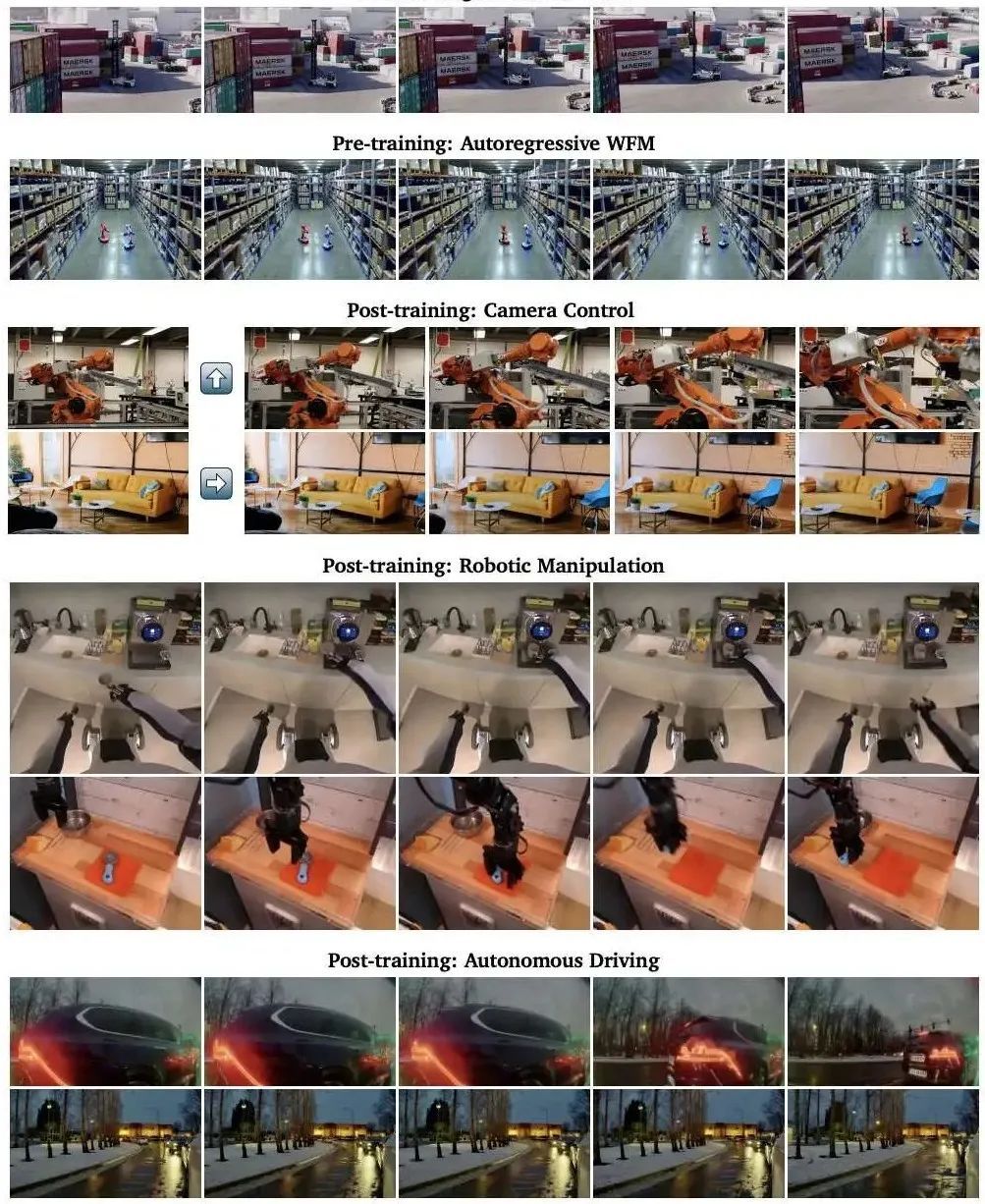
但何谓物理AI,通俗来说,就是世界模型,CES上,基于200万小时的视频,英伟达正式推出了一个名为Cosmos的用于加速物理AI开发的世界基础模型(WFM)平台,并抛出了一份75页的详细技术报告。紧接着,项目开源不到一天,GitHub 上的star数量就已经超过2000。
为什么如此受欢迎?简单来说,Cosmos可以很好的解决物理AI数据不够用的困境,其典型应用场景包括生成各种非常逼真的机器人以及无人驾驶场景下的视频。
随着智能化的发展,自动驾驶,机器人都需要更多的物理世界的数据来去标注,而Cosmos世界基础模型则可以生成大量基于物理学的逼真合成数据,去训练或者评估现有的模型。
 2.png
2.png
如何理解世界基础模型?
世界基础模型这个概念定义指的根据从真实视觉信息. (0到t时刻)以及条件信息 生成下一时刻的视觉预测,也即可以意味着根据当前的视觉输入,可以预测各种不同行动产生的后续结果。英伟达认为WFM可以用于:
策略评估:通过使用WFM,开发者可以在虚拟环境中评估物理AI的策略模型,而无需将其部署到现实世界中,从而节省成本和时间。WFM帮助快速筛选出无效策略,将资源集中在更有潜力的策略上。
策略初始化:WFM可以帮助初始化策略模型,尤其是在数据稀缺的情况下,通过模拟世界动态来提供更好的初始条件。
策略训练:在强化学习中,WFM与奖励模型结合,为策略模型提供反馈,使得物理AI系统能通过与WFM的互动提高任务解决能力。
规划与模型预测控制:WFM可用于模拟物理AI系统执行不同动作序列后的未来状态,并基于模拟结果选择最佳的动作序列,从而优化决策过程。
合成数据生成:WFM可用于生成合成数据,支持训练,同时可以根据渲染元数据(如深度图、语义图)进行调整,用于模拟到现实的迁移(Sim2Real)。
Cosmos如何实现的世界模型基础?
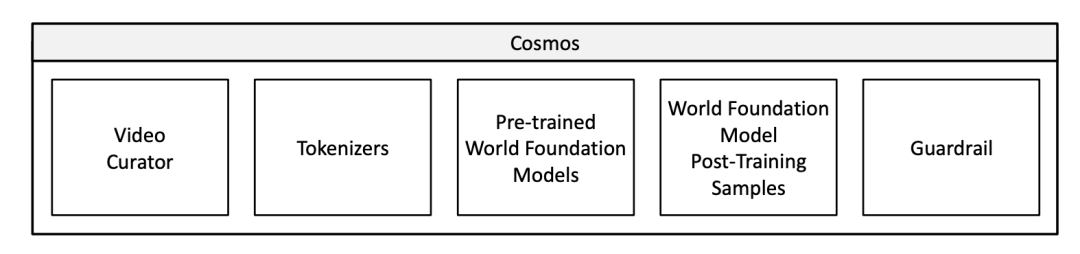
目前的Cosmos是一个框架,包含了五大组件,简要的介绍一下:
 3.png
3.png
视频数据管道(Video Curator):该系统通过分割视频成单独的镜头,然后进行一系列过滤步骤,找出高质量、富有信息的片段用于训练。之后,这些片段通过视觉语言模型(VLM)进行标注,并执行语义去重,构建多样化且紧凑的数据集。
视频标记化(Video Tokenization):开发了多个压缩比不同的视频标记化方法,采用因果设计,即当前帧的标记计算不依赖未来的帧。因果设计有助于模型同时训练图像和视频数据,适用于物理AI系统,这些系统需要基于过去的信息作出决策。
WFM预训练(WFM Pre-training):探索了两种可扩展的WFM预训练方法:扩散模型和自回归模型。扩散模型通过Text2World生成训练和Video2World生成训练,先基于文本生成视频世界,再基于过去的视频和文本生成未来世界。自回归模型通过Next Token生成训练和文本调控的Video2World生成训练,先生成未来的视频,再结合文本进行细化训练。
世界模型后训练(World Model Post-training):预训练后的WFM应用于多个物理AI任务,如通过相机姿态输入来进行自由导航,并在仿人类和自动驾驶等任务中进行微调。
护栏系统(Guardrail):为了确保模型的安全使用,开发了护栏系统来阻止有害的输入和输出。
 4.png
4.png
Cosmos有什么特殊之处?
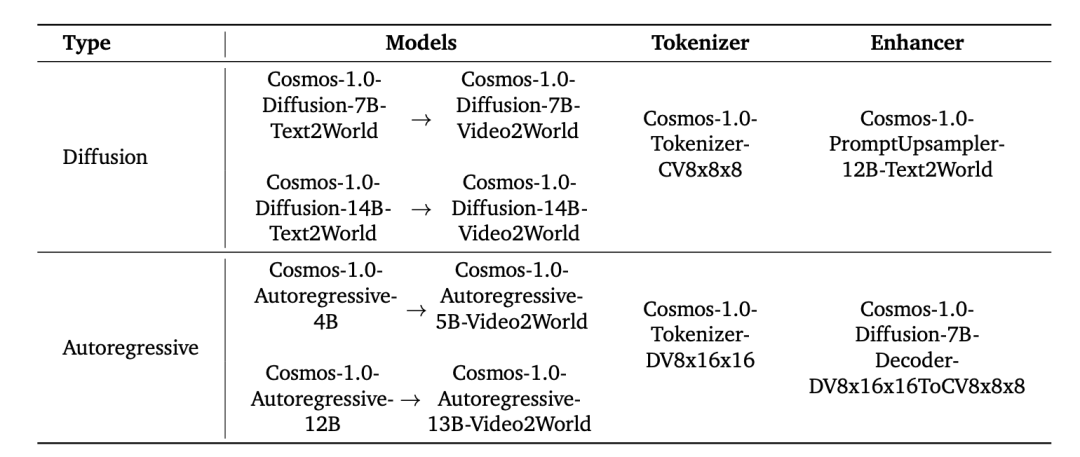
英伟达训练这个模型采取的是预训练后再微调的范式,其中将WFM分为预训练WFM和后训练WFM。为了构建预训练WFM,作者利用大规模的视频训练数据集,向模型展示多样化的视觉经验,使其成为一个通用模型。为了构建后训练WFM,使用从特定物理AI环境中收集的数据集对预训练WFM进行微调,从而得到针对特定物理AI设置的专用WFM。英伟达分别探索了两种可扩展的模型构造方法,一种基于Diffusion,一种基于自回归。Diffusion模型通过逐渐去除高斯噪声来生成视频,而自回归模型则是按照预设顺序逐片生成视频,且每一片都依赖于之前生成的内容。这两种方法将复杂的视频生成问题分解为更简单的子问题,使得问题更易于处理。
对于基于Diffusion的世界基础模型(WFM),预训练包括两个步骤:
Text2World生成预训练:训练模型基于输入的文本提示生成视频世界。
Video2World生成预训练:然后进一步微调模型,使其能够基于过去的视频和输入的文本提示生成未来的视频世界,即所谓的Video2World生成任务。
对于基于自回归的世界基础模型(WFM),预训练也包括两个步骤:
普通的下一个令牌生成:首先训练模型生成下一个视频令牌(即预测视频的下一个帧)。
文本条件的Video2World生成:然后微调模型,使其能够基于过去的视频和输入的文本提示生成未来的视频世界。
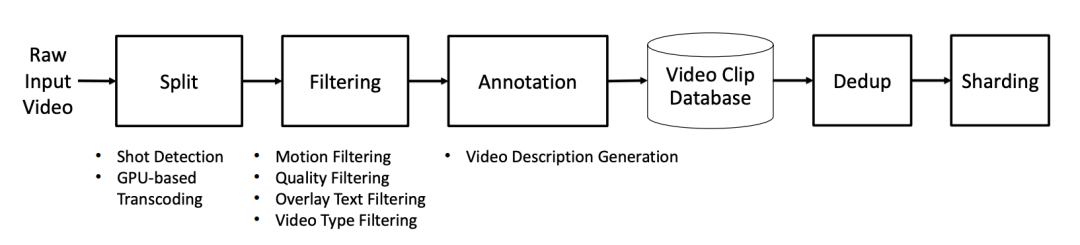
英伟达在长达75页的技术报告中,也专门详细描述了一下视频数据的处理,对于实际的视频生成业务,这一块是属于knowhow很多,但是又容易被一笔带过的内容。在现代以大规模数据驱动的模型训练中,数据的处理是决定模型效果的重要变量。推荐对这一部分感兴趣的读者阅读原文,大体流程是分割步骤将一个长视频划分为若干个镜头,并将其转录为视频片段。过滤步骤去除对世界基础模型构建价值较小的片段。标注步骤为每个片段添加视频描述。然后,这些片段被存储在一个视频片段数据库中。为了获得训练数据集,首先进行语义去重,然后根据分辨率和纵横比对视频片段进行分片处理。
 5.png
5.png
英伟达数据集的构成主要比例是
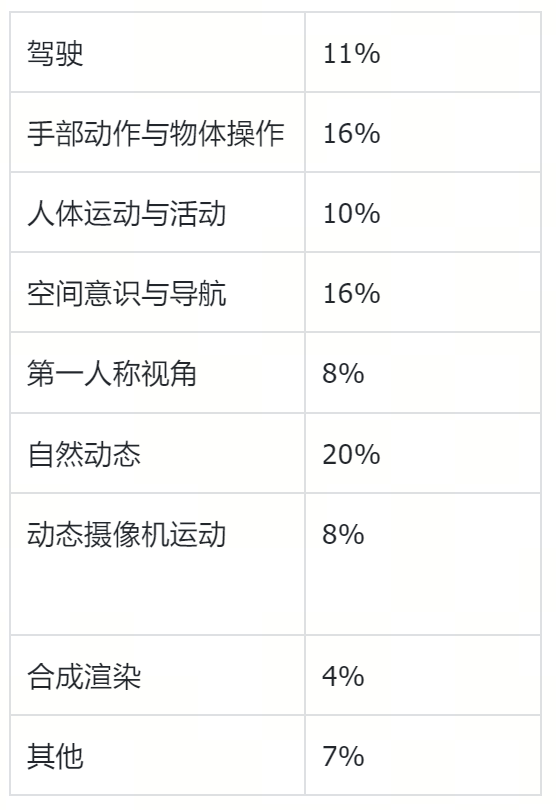 6.png
6.png
Cosmos是如何进行语义去重的?SemDeDup+DataCom
接下来,我们重点了解一下去重的步骤:
作者采用了SemDeDup和DataCom的方法进行可扩展的语义去重。具体来说使用了InternVideo2 Embedding,并使用多节点GPU加速的 k-means实现(RAPIDS)对这些Embedding进行聚类,设置𝑘=10,000。然后计算每个Embedding聚类内的成对距离,以识别重复项。当检测到重复视频时,选择分辨率最高的视频,以确保去重不会丢失质量。为了避免将整个成对距离矩阵存储在GPU内存中,作者实时计算必要的上三角矩阵,并在256个块中进行argmax简化。最终在去重过程中移除了大约30%的训练数据。
同时作者还利用提取的InternVideo2嵌入和聚类结果构建了一个视觉搜索引擎,支持通过自由文本和视频查询整个训练数据集。该搜索引擎对调试数据中的问题以及理解预训练数据集与下游应用之间的差距非常有帮助,如果某一个下游的具体数据表现差,那么它的embedding很有可能落在数据集一个比较稀疏的区域。
在大模型训练中,去重是一个改善数据分布,减少模型对某些数据过拟合风险,增加多样性的重要步骤。大规模模型的训练天然地需要适合大规模数据的基础设施,在这个背景下,Milvus作为一款云原生向量数据库,提供了出色的性能和可扩展性,成为解决这一问题的理想选择。Milvus支持快速处理大规模的向量数据,能够高效地进行相似性搜索和去重操作,适用于大规模训练数据集的处理需求。通过高效的索引和分布式架构,Milvus能够水平扩展以处理海量数据和高并发请求,显著提高处理速度,确保在大规模视频数据集的去重过程中实现实时、精准的相似性计算。相信高效的数据基础设施一定会为训练更加强大的模型打下坚实的基础。
 王翔宇
王翔宇


