




Jina AI / jina-embeddings-v2-small-en
 Milvus 已集成
Milvus 已集成
任务: Embedding
模态: 文本
相似度类型: 任何(归一化)
许可证: Apache 2.0
向量维度: 512
最大输入 Token 数量: 8192
定价: 免费
Jina Embedding v2 模型简介
Jina Embeddings v2 模型由 Jina AI 开发,旨在处理长文档,并扩展了最大输入 Token 数量,支持高达 8,192 个 Token。截至 2024 年 8 月,Jina AI Embedding V2 提供四种变体,每种都满足不同的 Embedding 需求:
- jina-embeddings-v2-small-en
- jina-embeddings-v2-base-en
- jina-embeddings-v2-base-zh
- jina-embeddings-v2-base-de
jina-embeddings-v2-small-en 简介
jina-embeddings-v2-small-en 是一款专用于处理英语单语种的 Embedding 模型,支持长达 8192 个 Token 。它是 Jina Embeddings v2 系列中最小的变体,经过训练,参数量为 3300 万,最终会生成 512 维的 Embedding 向量。
下表为 jina-embeddings-v2-small-en 和其他 Jina Embedding 模型的对比。
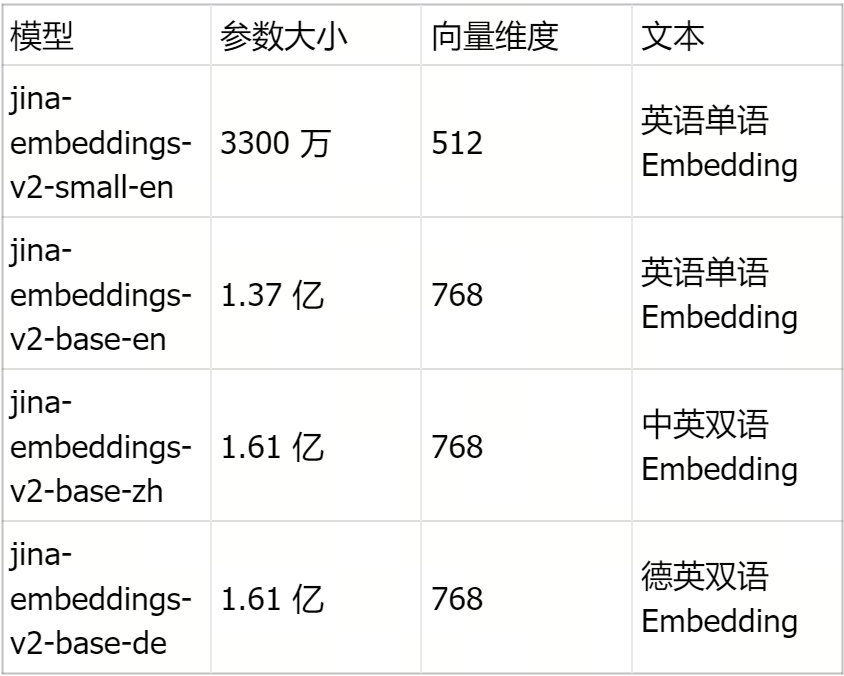 屏幕截图 2024-10-09 111616.png
屏幕截图 2024-10-09 111616.png
如何使用 jina-embeddings-v2-small-en 生成 Embedding 向量
生成 Embedding 向量的主要有两种方式:
- PyMilvus:Milvus 的 Python SDK,无缝集成了 jina-embeddings-v2-small-en 模型
- SentenceTransformer 库:Python 的 sentence-transformer 库
生成 Embedding 向量后,就可以将向量存储在 Zilliz Cloud(全托管的 Milvus 向量数据库服务)中,用于语义相似性搜索。以下是四个关键步骤:
- 免费注册 Zilliz Cloud 账号
- 创建 Serverless 集群并获取公共 Endpoint 和 API 密钥
- 创建 Collection 并插入向量数据
- 对存储的 Embedding 向量进行语义搜索
通过 PyMilvus 生成 Embedding 向量
from pymilvus.model.dense import SentenceTransformerEmbeddingFunction
from pymilvus import MilvusClient
ef = SentenceTransformerEmbeddingFunction("jinaai/jina-embeddings-v2-small-en", trust_remote_code=True)
docs = ["Artificial intelligence was founded as an academic discipline in 1956.","Alan Turing was the first person to conduct substantial research in AI.","Born in Maida Vale, London, Turing was raised in southern England."
]
Generate embeddings for documents
docs_embeddings = ef(docs)
queries = ["When was artificial intelligence founded","Where was Alan Turing born?"]
Generate embeddings for queries
query_embeddings = ef(queries)
Connect to Zilliz Cloud with Public Endpoint and API Key
client = MilvusClient(
uri=ZILLIZ_PUBLIC_ENDPOINT,
token=ZILLIZ_API_KEY)
COLLECTION = "documents"if client.has_collection(collection_name=COLLECTION):
client.drop_collection(collection_name=COLLECTION)
client.create_collection(
collection_name=COLLECTION,
dimension=ef.dim,
auto_id=True)
for doc, embedding in zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
results = client.search(
collection_name=COLLECTION,
data=query_embeddings,
consistency_level="Strong",
output_fields=["text"])
更多详情,请参考 PyMilvus Embedding 模型文档。
通过 sentence-transformer 生成 Embedding 向量
from sentence_transformers import SentenceTransformer
from pymilvus import MilvusClient
model = SentenceTransformer("jinaai/jina-embeddings-v2-small-en", trust_remote_code=True)
docs = ["Artificial intelligence was founded as an academic discipline in 1956.","Alan Turing was the first person to conduct substantial research in AI.","Born in Maida Vale, London, Turing was raised in southern England."
]
Generate embeddings for documents
docs_embeddings = model.encode(docs, normalize_embeddings=True)
queries = ["query: When was artificial intelligence founded","query: Wo wurde Alan Turing geboren?" ]
Generate embeddings for queries
query_embeddings = model.encode(queries, normalize_embeddings=True)
Connect to Zilliz Cloud with Public Endpoint and API Key
client = MilvusClient(
uri=ZILLIZ_PUBLIC_ENDPOINT,
token=ZILLIZ_API_KEY)
COLLECTION = "documents"if client.has_collection(collection_name=COLLECTION):
client.drop_collection(collection_name=COLLECTION)
client.create_collection(
collection_name=COLLECTION,
dimension=512,
auto_id=True)
for doc, embedding in zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
results = client.search(
collection_name=COLLECTION,
data=query_embeddings,
consistency_level="Strong",
output_fields=["text"])
更多详情,请参考 HuggingFace 文档。

