



为什么使用 **CNN?**

卷积神经网络(CNN)是一种专为图片、视频、音频文件等数据打造的深度学习模型。
CNN 为计算机视觉、图像处理、物体检测、自然语言处理(NLP)等领域带来了变革。
诸如多层感知器(Multi Layer Perceptron,MLP)或全连接网络(Fully Connected Network)之类的传统的神经网络通常将图片数据视作平面向量,在处理视觉数据中的空间信息时具有局限性。使用传统神经网络可能会导致错误的假设(归纳偏差),从而降低数据准确性。
相比之下,CNN 通过保留图像结构(例如:局部连接和像素内容),可以更高效识别图像数据中的规律和模式。
本文将介绍 CNN 的优势和架构,并提供一个简单示例展示如何设计 CNN 模型。
为什么使用 CNN?
CNN 优于传统的神经网络,能够高效提取原始视觉数据中的特征。使用 CNN 有以下好处:
- 参数共享:CNN 在不同输入区域共享同一组参数,这样有助于高效识别高维数据中的隐藏模式。
- 减少参数数量:CNN 使用池化和卷积技术,与全连接网络相比,显著减少了参数数量。
- 分层特征学习:CNN 模拟了人类视觉系统的分层结构。
- 最佳性能:CNN 在目标检测、图像处理、语音识别和图像分割等任务中始终优于传统的神经网络。近期,计算机视觉领域中最新引入了卷积和非卷积转换器(Transformer)。
CNN 架构及原理
CNN 能够快速准确地解读视觉诗句,发现数据中隐藏的模式。
人类神经系统分为多层,每一层负责执行不同的功能。CNN 具有类似的架构,每一层从输入图像中提取不同的特征。下文将详细说明 CNN 架构中包含的层次。
CNN 的前几层是卷积层,负责提取图像的基本特征,如边缘和形状。接下来的几层是池化层,负责缩小特征图(feature map)的大小。最后一层是全连接(Fully Connected,FC)层,负责将图像根据指定类别分类。几乎所有现有的纯卷积架构都只含有一个池化层,连接一个全连接层。
卷积层
卷积层能够找到数据中独特的模式,用于接收输入图像并使用一组滤波器处理图像,输出结果。
滤波器是一个小型权重矩阵,用于扫描输入图像并识别不同的模式。
卷积的输出称为特征图,其中包含卷积操作中由滤波器提取的所有特征,包括图片形状、大小、边缘、纹理等。
池化层
在图像通过卷积层后,可以通过控制卷积在图像上的步幅来对图像进行下采样。但推荐的方法是使用池化层来减小特征图的大小,同时保留最重要的特征。
池化层有助于减少 CNN 的计算复杂度,并避免过拟合问题。最大池化和平均池化等技术可以减小空间维度并防止网络过载。
全连接层
CNN 的最后一层是全连接层,用于对 CNN 的输出进行分类。
它类似于传统的神经网络层,接收来自上一层的输出并将其连接到一组神经元。这些神经元用于将图像根据指定类别分类。
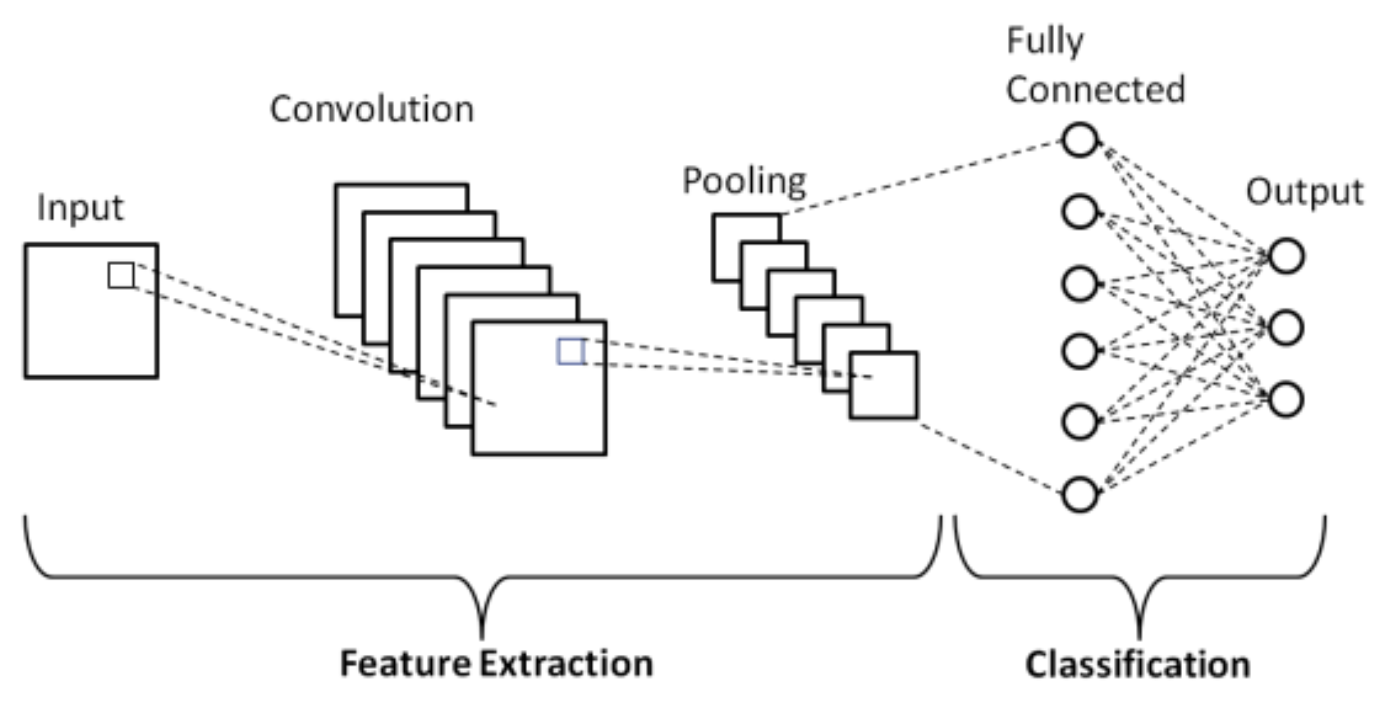 卷积神经网络的架构
卷积神经网络的架构
其他相关术语
学习 CNN 的过程中还需要了解其他一些相关的基本术语,在处理复杂问题陈述或数据非常庞大时,防止发生过拟合的问题。
- 步幅(Stride):卷积操作期间滤波器采用的步长大小。
- 填充(Padding):CNN 中的填充是在图像边界周围添加零以保留其空间维度,以防止图像在每次卷积操作后收缩,防止信息丢失。
- Epoch:训练时,所有训练数据集都训练过一次。
- 正则化(Dropout):通过随机丢弃训练中的神经元来防止过拟合,这能够迫使网络进行学习而不是依赖更多的神经元。
- 随机深度(Stochastic Depth) :在训练过程中通过随机丢弃残差块并通过跳过连接绕过它们的变换来缩短网络。同时,在测试时,使用整个网络进行预测,这样可以改善测试错误率和显著减少训练时间。
如何设计 CNN?
以下为设计 CNN 的基本步骤:
- 选择输入大小:输入大小表示 CNN 将训练的图像的大小。输入大小应保证足够大,以便网络能够提取分类对象的特征。
- 选择卷积层数:卷积层数决定了网络将能够学习的特征数量。神经网络的卷积层更多,可以学习的特征更复杂,但计算时间会增加。
- 选择滤波器的大小:滤波器的大小以及卷积的步幅决定从图像中提取的特征大小。滤波器维度越大,提取的特征越多。
- 选择每层的滤波器数量:滤波器数量决定了提取的特征数量。
- 选择池化方法:有两种常见的池化技术——最大池化和平均池化。最大池化从特征图的小区域中取最大值,而平均池化从特征图的小区域中取平均值。
- 选择全连接层数:这决定了网络分类的类别数。
- 选择激活函数:激活函数帮助神经网络从图像数据中学习更复杂的模式。对于二元分类问题,通常使用 sigmoid 函数。在多类分类问题陈述中,FC 层使用 softmax 激活函数。为了保持数据非线性,现在主要使用 GeLU 或 Swish 激活函数。
接着,本文将使用 Python 示例如何搭建一个简单的 CNN 模型,用于对交通标志进行分类。相关数据集请在此获取。
使用 PyTorch 搭建基础 CNN
如需使用 Python 搭建 CNN 模型,请安装 PyTorch、TensorFlow、Keras 等框架。
首先,导入所需的模块:
# 计算所需的依赖
import pandas as pd
import numpy as np
# 读取和展示图片所需的依赖
from cv2 import resize
from skimage.io import imread
import matplotlib.pyplot as plt
%matplotlib inline
# 创建验证数据集的依赖
from sklearn.model_selection import train_test_split
# 评估模型的依赖
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# PyTorch 库和模块
import torch
from torch.autograd import Variable
from torch.nn import (Linear, ReLU, CrossEntropyLoss,
Sequential, Conv2d, MaxPool2d, Module,
Softmax, BatchNorm2d, Dropout)
from torch.optim import Adam, SGD
接着,加载数据集和图像:
# 加载数据集
train = pd.read_csv('Data/train.csv')
# 加载训练图片
train_img = []
for img_name in tqdm(train['Path']):
# 定义图片路径
image_path = 'Data/' + str(img_name)
# 读取图片
img = imread(image_path, as_gray=True)
# 调整图片大小
img = resize(img, (28, 28))
# 将图片像素大小归一化
img /= 255.0
# 将像素大小类型转化为float 32
img = img.astype('float32')
# 将图像传入列表中
train_img.append(img)
# 将列表转化为numpy数组
train_x = np.array(train_img)
# 定义目标
train_y = train['ClassId'].values
train_x.shape
在完成加载训练数据后,使用 sklearn 的 train_test_split() 方法创建训练和验证数据集。
# 创建验证数据集
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
# 检查训练和验证数据集的图片形状
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
然后,调整 Torch 模型的数据形状:
# 将训练图像转化为 torch 格式
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# 将目标图像转化为 torch 格式
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# 将验证图像转化为 torch 格式
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# 将目标图像转化为 torch 格式
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
接着,定义 CNN 的多个层:
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定义一个 2 维卷积层
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# 定义另一个 2 维卷积层
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
# 最后一层用于预测
self.linear_layers = Sequential(
Linear(4 * 7 * 7, 43)
)
# 定义 forward pass
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
以上示例 CNN 包含 2 个卷积层,和一个 2×2 的最大池化层。
展平层(flatten layer)可以将交通标志的图像分类。
接下来,让我们设置优化器(optimizer)和损失函数(loss function),并定义训练过程。
# 定义模型
model = Net()
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.07)
# 定义损失函数
criterion = CrossEntropyLoss()
# 检查 GPU 是否可用
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
def train(epoch):
model.train()
tr_loss = 0
# 获取训练数据集
x_train, y_train = Variable(train_x), Variable(train_y)
# 获取验证数据集
x_val, y_val = Variable(val_x), Variable(val_y)
# 将数据转化为 GPU 格式
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# 清除模型参数梯度
optimizer.zero_grad()
# 为训练和验证数据集进行预测
output_train = model(x_train)
output_val = model(x_val)
# 计算训练和验证损失
loss_train = criterion(output_train, y_train)
loss_val = criterion(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# 反向传播并更新模型参数
loss_train.backward()
optimizer.step()
tr_loss = loss_train.item()
if epoch%2 == 0:
# 打印验证损失梯度反向传播
print('Epoch : ',epoch+1, '\\t', 'loss :', loss_val)
最后,对训练数据进行 25个 epoch 的训练:
# 设置 Epoch 数量
n_epochs = 25
# 清空列表存储训练损失
train_losses = []
# 清空列表存储验证损失
val_losses = []
# 训练模型
for epoch in range(n_epochs):
train(epoch)
每个模型都将用于对测试数据进行预测。更多详情,请阅读本文。
常见问题
CNN 和深度神经网络之间有什么区别?
CNN 是一种可以处理图像、语音、视频等数据的神经网络。深度神经网络(Deep Neural Network, DNN)是一种可以从数据中学习复杂模式的人工神经网络类型。
CNN 和 DNN 之间的主要区别在于:
- CNN 具有用于处理图像的特定架构,而 DNN 没有任何特定的架构,可以用于各种任务。
- CNN 通过使用卷积层从图像中学习特征,而 DNN 通过不同类型的层来学习特征。
- 与 DNN相比,CNN 更难训练,需要更多的数据,并且计算成本更高。
CNN 包含哪 3 层?
CNN 包含卷积层、池化层和全连接层 3 层。
- 卷积层:负责从图像中提取特征。卷积层通过使用滤波器(一种小型权重矩阵扫描图像。滤波器在图像上移动,并且权重与图像中的像素值相乘。最后,生成包含提取特征的特征图。
- 池化层 :池化层用于减小特征图的大小。有两种常见的池化技术——最大池化和平均池化。
- 全连接层:与传统的神经网络中的全连接层相同,用于对 CNN 的输出进行分类。全连接层中的神经元将图像分类。
深度学习中的 CNN 是什么?
CNN 是一种深度神经网络,用于处理图像、语音和视频等数据。使用 CNN 可以对数字化世界中不断增长的结构化或非结构化数据进行实际预测。
CNN 还能够轻松高效地预测人类情绪、行为、兴趣、喜好等。