



Zilliz 推出全新迁移服务,助您实现高效的跨平台非结构化数据传输
作为领先的向量数据库服务提供商,Zilliz 深知开发出色的 AI 应用离不开数据本身。然而,在有效处理 AI 应用中的非结构化数据时,我们常常会面临以下挑战:
- 数据碎片化:用户数据分散在多个平台中,如 S3、HDFS、Kafka、数仓和数据湖。
- 多样的数据格式:非结构化数据以各种格式存在,包括 JSON、CSV、Parquet、JPEG 等。
- 缺乏完整的解决方案:目前没有一款产品能够完全满足跨系统高效传输非结构化数据和向量数据的复杂需求。
在上述这些挑战中,最突出的就是,如何将转化来自各种数据源和以各种格式存在的非结构化数据,并导入向量数据库中。这一过程比处理传统的 SQL 关系型数据要复杂得多,大部分公司或组织都低估了这一点。
因此,许多公司或组织在搭建自定义的非结构化数据流水线(Pipeline)时,通常会面临性能、可扩展性和维护成本的问题。这些问题可能会影响数据质量和准确性,从而可能削弱应用的数据分析能力。
更糟糕的是,许多公司在选择向量数据库时都忽视或者低估了供应商锁定和数据容灾等因素。
供应商锁定带来的影响
供应商锁定是指一个组织过度依赖单一供应商的专有技术。在这种情况下,该组织会难以切换到另一种解决方案,或者切换方案的成本十分高昂。这个问题在向量数据库领域尤为重要,由于向量数据的特性和缺乏标准化数据格式可能使得跨系统数据迁移变得极具挑战性。
供应商锁定的影响远不止于此。它还限制了组织在面对业务需求变化时的灵活性,甚至可能随着时间的推移会进一步增加组织运营成本。此外,锁定单一供应商的生态系统还会限制技术创新。如果所选解决方案无法很好地随着组织需求的增长而扩展,还会影响应用系统的性能。
在选择向量数据库时,组织应优先考虑开放标准(open standards)和互通性,从而降低上述风险。在制定清晰的数据治理策略过程中,规划数据的可移植性至关重要。定期评估对供应商特定功能的依赖程度,可以帮助组织保持系统灵活性。
非结构化数据迁移的挑战
然而,即使有了上述预防措施,组织也必须准备好面对向量数据库带来的独特挑战。我们发现,向量数据库之间的数据迁移比传统的关系型数据库之间的数据迁移要复杂得多。这种复杂性凸显了选择合适的向量数据库的重要性,并解释了为什么需要注意避免供应商锁定。向量数据库迁移的主要挑战包括:
- 缺乏面向向量数据库的 ETL 工具:像 Airbyte 和 Seatunnel 之类的主流工具仅面向传统的关系型数据库,无法有效满足向量数据库之间的数据迁移需求。
- 向量数据库之间能力差异:
- 许多向量数据库不支持数据导出。
- 部分向量数据库的增量数据实时处理能力有限。
- 向量数据库之间的数据 Schema 不匹配。 为应对这些挑战,组织需要构建更具弹性、灵活性和且时俱进的 AI 应用,充分利用非结构化数据的力量,并保持适应未来技术的灵活性。
Zilliz 推出全新迁移服务
Zilliz 推出全新迁移服务(Migration Services)并将其开源,以帮助用户应对上述种种挑战。Zilliz 迁移服务是一款基于 Apache Seatunnel,专为向量数据迁移设计的工具。推动我们我们开发这款工具的背后原因包括:
- 满足日益增长的数据迁移需求:我们最初提供的 Milvus 迁移服务已成功帮助 100 多个组织实现 Milvus 集群之间的数据迁移。本次的迁移服务需求正是由此演变而来。用户需求不断扩展,演变为将数据从不同的向量数据库、传统的搜索引擎(如 Elasticsearch 和 Solr)、关系型数据库、数仓、文档数据库,甚至 S3 和数据湖迁移到 Milvus。
- 支持实时流数据流和离线导入:随着向量数据库能力的不断扩展,用户需要对实时流数据的支持和离线批量导入的能力。
- 简化非结构化数据转换流程:与传统 ETL 不同,转换非结构化数据需要借助 AI 模型的力量。迁移服务结合了 Zilliz Cloud Pipelines,能够将非结构化数据转换为 Embedding 向量并完成数据标记等任务,显著降低数据清洗成本和操作难度。
- 确保端到端的数据质量:数据集成和同步过程中容易出现数据丢失和不一致的问题。迁移服务通过强大的监控和告警机制解决了这些可能影响数据质量的问题。
迁移服务的核心能力
迁移服务基于 Apache Seatunnel 开发,提供以下特性:
- 丰富、可扩展的 Connector
- 统一的数据流式和批式处理,用于实时同步数据和离线批量导入
- 支持分布式数据快照,确保数据一致性
- 高性能、低延时、高度可扩展
- 实时监控和可视化管理
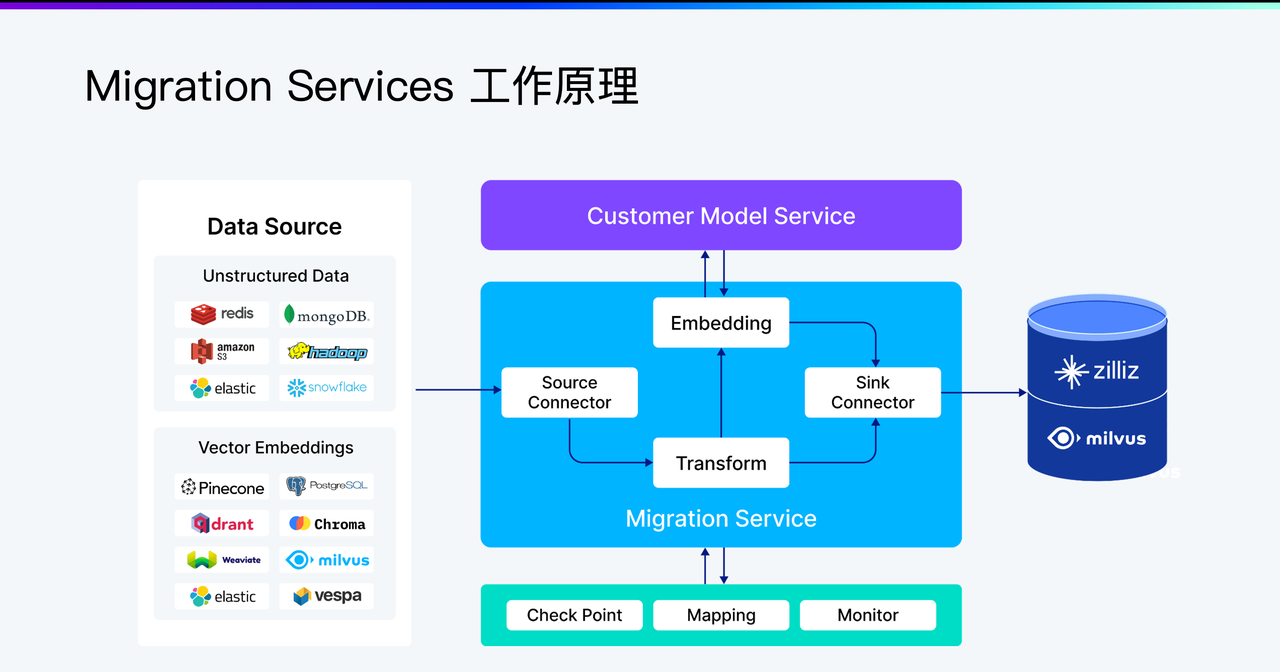 图1. 迁移服务工作原理
图1. 迁移服务工作原理
此外,迁移服务还包含针对向量数据的特定功能,如支持多种数据源、 匹配 Schema 和基本的数据验证等能力。后续将进一步支持增量数据同步、全量+增量迁移模式,以及更高级的数据转换能力。
为什么选择将迁移服务开源?
Zilliz 始终坚信开源的力量可以推动创新并为开发者提供最佳的解决方案。以下是我们选择将迁移服务开源的原因:
- 培养开放的向量数据生态系统:我们构建的生态系统能够有效避免供应商锁定的问题,允许您根据需要灵活选择和切换解决方案。
- 吸引贡献者:我们可以借助开发者社区中的专业知识,进一步增强迁移服务工具。我们欢迎您为这个项目添砖加瓦——增加更多 Connector、集成更多数据源和更多数据转换模型。
- 回馈开源社区:作为一家开源向量数据库公司,我们着眼于知识和资源共享,期望推进整个领域的发展。
- 提升云服务产品:您的反馈对于我们商业化产品至关重要。我们将基于您的反馈快速迭代和改进产品。开源能够让我们听到更多来自社区的宝贵建议。
我们始终坚持开源,这不仅仅体现在共享代码上。我们认为开发者只有在一个开放的生态系统中,才能始终拥有选择权。这驱使我们努力追求卓越,确保 Zilliz 始终是满足您需求的最佳决策。无论是通过快速迭代产品、提供全面支持还是扩展产品能力,我们的目标是通过持续提供价值,来赢得您的信任。
迁移服务路线图
展望未来,迁移服务将不断发展。通过开源迁移服务工具,我们不仅仅能够解决当前向量数据管理中的问题和挑战,我们还在为创新型 AI 应用开发铺平道路。
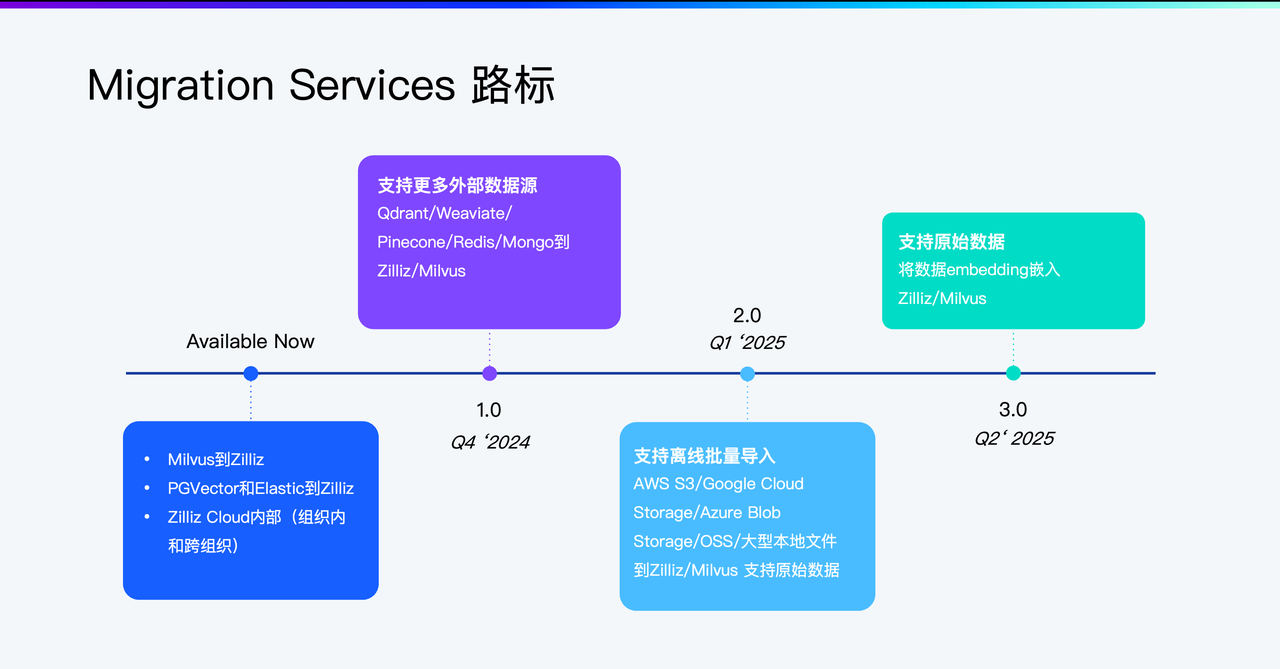 图2. 迁移服务 Roadmap
图2. 迁移服务 Roadmap
我们的愿景是开发工具,满足开发者需求。我们正不断努力,期望推动数据和 AI 技术发展,降低其使用门槛,提升这些技术的灵活性,满足真实应用场景的需求。我们邀请社区中的每一位成员加入这段旅程,为强大的非结构化数据处理工具做出贡献,并从中获益。让我们携手合作,塑造向量数据库的未来,共创一个更开放、高效和创新的 AI 生态系统。


