



Milvus Week | Kafka 很好, Pulsar也不错,但WoodPecker才是未来
前言
首先,官宣一件事情,在 Milvus 2.6 中,我们决定:重写 Milvus 的流处理架构**。
过去,我们爱过 Kafka,也用过 Pulsar,作为一款开源的向量数据库,Milvus 专为 AI 和搜索场景设计,其云原生架构从一开始就依赖外部消息队列来实现实时数据写入。
但时过境迁,需求已经变了:引入Kafka 和 Pulsar 这类系统需要独立部署不仅带来了新的运维复杂度与架构复杂性,成本也成为一大问题。
而这也是我们正式引入 Woodpecker ,设计一个专为对象存储优化、自研的云原生 WAL 组件的核心原因。
01
为什么我们要告别 Kafka 和 Pulsar?
Milvus 从设计之初就专为云而生。它利用 Kubernetes (K8s) 实现弹性伸缩与故障快速恢复,同时采用 Amazon S3、MinIO 等对象存储服务作为持久化底层。
然而,纯粹的云原生架构也带来了新的问题。虽然 S3 之类的对象存储拥有几乎无限的吞吐能力和极高的可用性,但单次请求延迟经常超过 100 毫秒。此外,这些服务的计费方式通常与访问频率和写入次数挂钩,这会在实时数据库场景中带来不小的成本压力与性能瓶颈。
引入共享日志架构(Shared Log Architecture)
传统的向量数据库通常只支持批处理模式,而在云原生环境中构建一个高效的流式系统则更为复杂。Milvus 选择采用“共享日志”架构,以确保数据的实时性与检索效率。
这个共享日志就像文件系统中的硬盘一样运作。通过这种设计,Milvus 避免了自己管理复杂的一致性协议,从而能够专注于核心功能:高性能的向量检索。
虽然 AWS Aurora、Azure Socrates 和 Neon 等数据库也采用类似架构,但开源领域依然缺乏一个低延迟、可扩展、易集成的分布式写前日志(WAL)组件。目前常见的 Bookie 等解决方案存在客户端太重、缺少 Golang 和 C++ 生产级 SDK 等问题,难以满足 需求。
消息队列方案及其局限
为填补这一空缺,Milvus 初期使用 Apache Pulsar 和 Kafka 来实现 WAL 功能。所有实时写入的数据都会先进入这些消息队列,在获得确认后再异步被 QueryNode 和 DataNode 处理。这样的设计在保证数据新鲜度的同时,也提供了较高的写入吞吐。
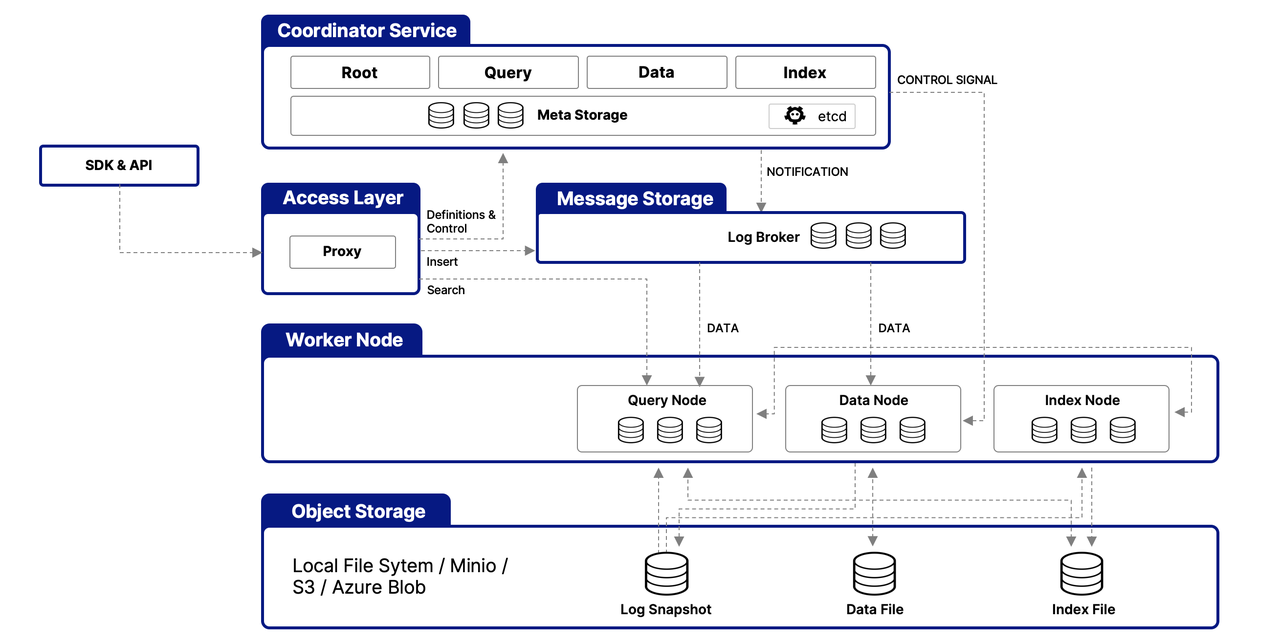
Milvus 2.0 架构
为什么我们放弃了 Kafka 和 Pulsar?
自 Milvus 2.6 起,我们开始用自研的云原生 WAL 系统 Woodpecker 来逐步替代外部消息队列。
并不是说 Kafka 和 Pulsar 技术不好,而是外部系统引入了额外的复杂性和运维负担,具体表现为:
运维复杂度
Kafka 和 Pulsar 这类系统需要独立部署,涉及多个节点、资源管理等,对日常运维带来极大挑战:
运维复杂度高
管理门槛高,学习成本大
配置错误和安全问题风险更高
架构复杂性
Kafka 本身支持的 topic 数有限,为此我们设计了 VShard 来支持 topic 共享。但这一设计在扩展性的同时,也引入了额外的系统复杂性,并影响日志回收等核心模块。
成本问题
Kafka/Pulsar 在实现高可用时通常对资源消耗巨大,不适合小集群轻量部署。同时,它们也无法跳过对临时信号(如 Milvus 的 Timetick)的持久化,导致大量不必要的 I/O 与存储开销。
02
Woodpecker:面向对象存储优化的 WAL 引擎
在 Milvus 2.6 中,我们正式引入了 Woodpecker —— 一个专为对象存储优化、自研的云原生 WAL 组件。
Woodpecker 采用 “ZeroDisk” 架构,所有日志数据存储于云对象存储(如 Amazon S3、GCS、阿里 OSS),元数据则由 etcd 等分布式 KV 系统管理。这种设计彻底消除了本地磁盘依赖,降低了运维压力,并提升了数据持久性和扩展能力。
核心设计目标:
跨可用区的高吞吐数据写入与强持久性
实时订阅所需的低延迟尾部读取与高吞吐补偿读取
可插拔式存储后端(支持 S3、GCS、NFS 等)
灵活部署:既可轻量独立部署,也可支撑多租户集群场景
架构组成:
Client:用于提交读写请求的接口层
LogStore:处理写缓冲、异步写入与日志压缩
Storage Backend:后端存储(支持 S3、GCS、EFS 等)
ETCD:管理元数据并协同分布式节点
两种部署模式:
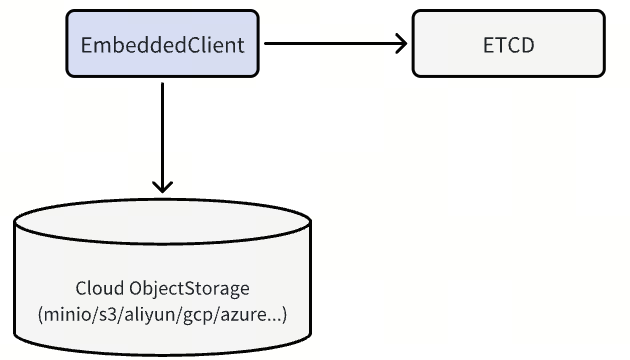
MemoryBuffer 模式(轻量且免维护)
该模式将日志写入缓存在内存中,并周期性地刷入对象存储,适合写延迟不敏感、以批处理为主的小规模场景。
 6.12.3.png
6.12.3.png
Woodpecker Embedded部署
QuorumBuffer 模式(低延迟 & 高容错)
此模式适用于对实时性和可用性要求高的生产环境。数据会同步写入 3 个节点中的任意两个即可认为写入成功(quorum),常在几毫秒内完成,并异步持久化到云存储。这样既保证强一致性,也避免了传统多副本架构中的复杂Anti Entrophy机制。
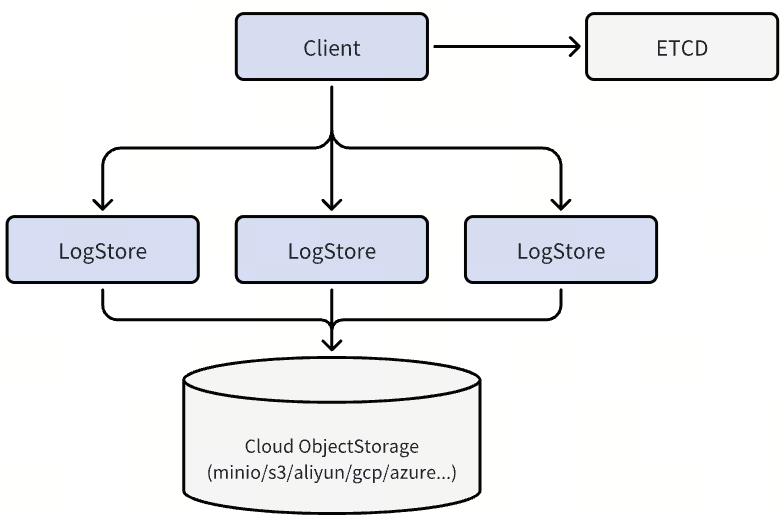
Woodpecker Quorum部署
03
Streaming Service:为实时流处理而生
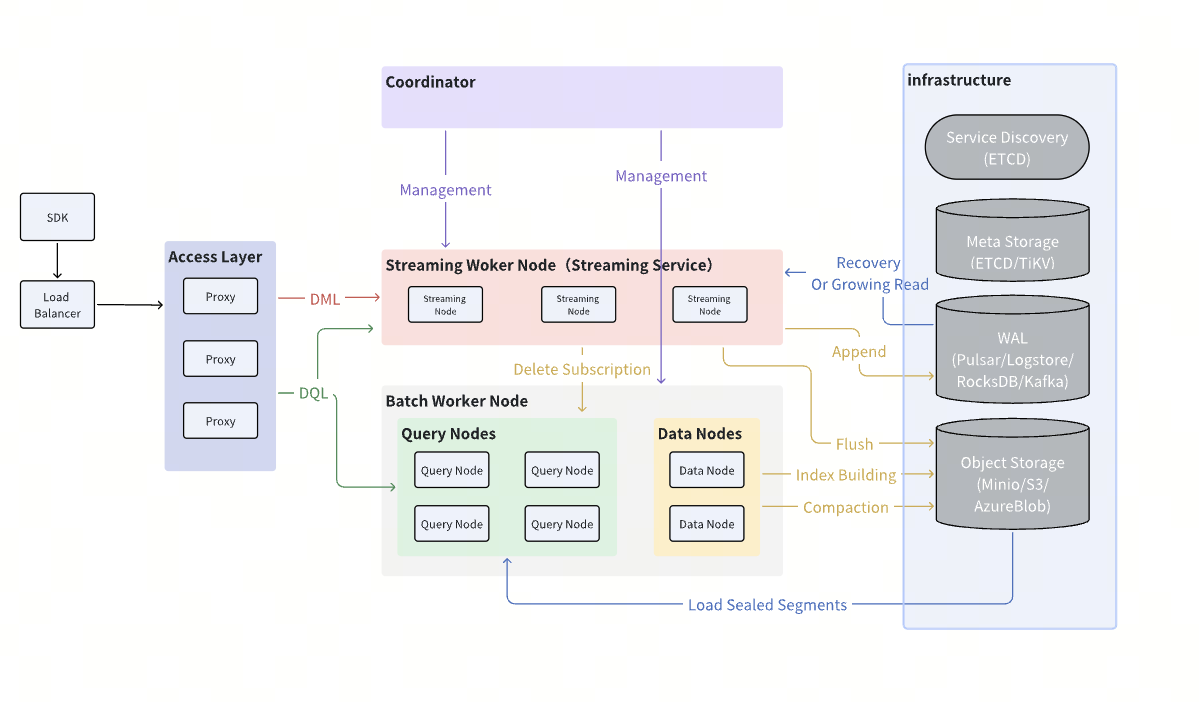
Milvus 2.6架构图
除了 Woodpecker,Milvus 2.6 还引入了 Streaming Service —— 一个专用于日志接入、增量写入与实时订阅的核心组件。它取代了 Kafka/Pulsar 在数据链路中的角色,成为真正意义上的实时数据流通引擎。
核心模块:
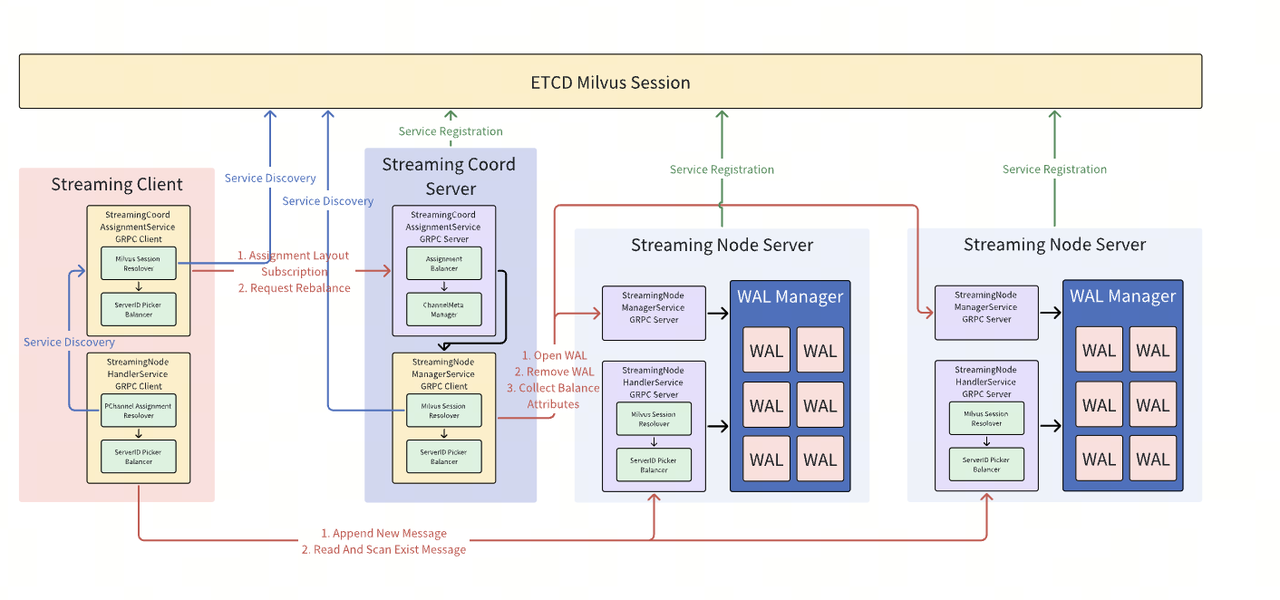
StreamService业务流程
▶ Streaming Coordinator
监控 ETCD 会话以发现 Streaming Node
通过 ManagerService 管理 WAL 状态和负载
▶ Streaming Client
通过 AssignmentService 获取 WAL 的分布情况
与目标节点交互进行读写操作
▶ Streaming Node
实际处理 WAL 写入,提供发布-订阅能力
管理节点状态、性能数据
通过 HandlerService 实现高效的订阅机制
通过 Streaming Service,Milvus 实现了原生的数据订阅能力,移除冗余缓存、降低内存消耗、提升一致性读取的延迟表现,同时极大增强了系统的可扩展性与容灾能力。
结语
管理状态是所有分布式系统中的难题。状态化系统往往难以弹性伸缩,而越来越多的云原生架构都在朝着“计算-存储解耦”的方向前进。
Milvus 选择不重复造轮子,而是将数据持久性的挑战交由 AWS S3、GCP GCS、MinIO 这些世界级团队打磨过的对象存储服务来解决。其中,S3 提供了几乎无限的容量、11 个 9 的持久性、99.99% 的可用性和近乎无限的吞吐能力。
当然,“ZeroDisk” 架构也并非万能:对象存储在小文件高频写入场景中仍面临延迟瓶颈。这也是我们自研 Woodpecker 和 Streaming Service 的根本动因。
对于向量数据库,尤其是在支撑 RAG、Agent 和低延迟搜索等新兴 AI 应用时,实时性至关重要。Milvus 架构的这一轮革新,不仅简化了整体系统设计,优化了成本结构,也提升了数据Freshness与故障恢复速度。
我们相信 Woodpecker 不仅是 Milvus 的内核组件,更有可能成为未来云原生数据库生态的重要基建。而随着 S3 Express 等新技术的推出,我们看到了更多可能性。未来对象存储或许真的能实现跨 AZ 高可用,毫秒级读写能力,让我们拭目以待。

keepReading

单agent落幕,双agent才能解决复杂问题!附LangGraph+Milvus实操
做agent简单,但是做能落地的agent难,做能落地的长周期agent更是难上加难!
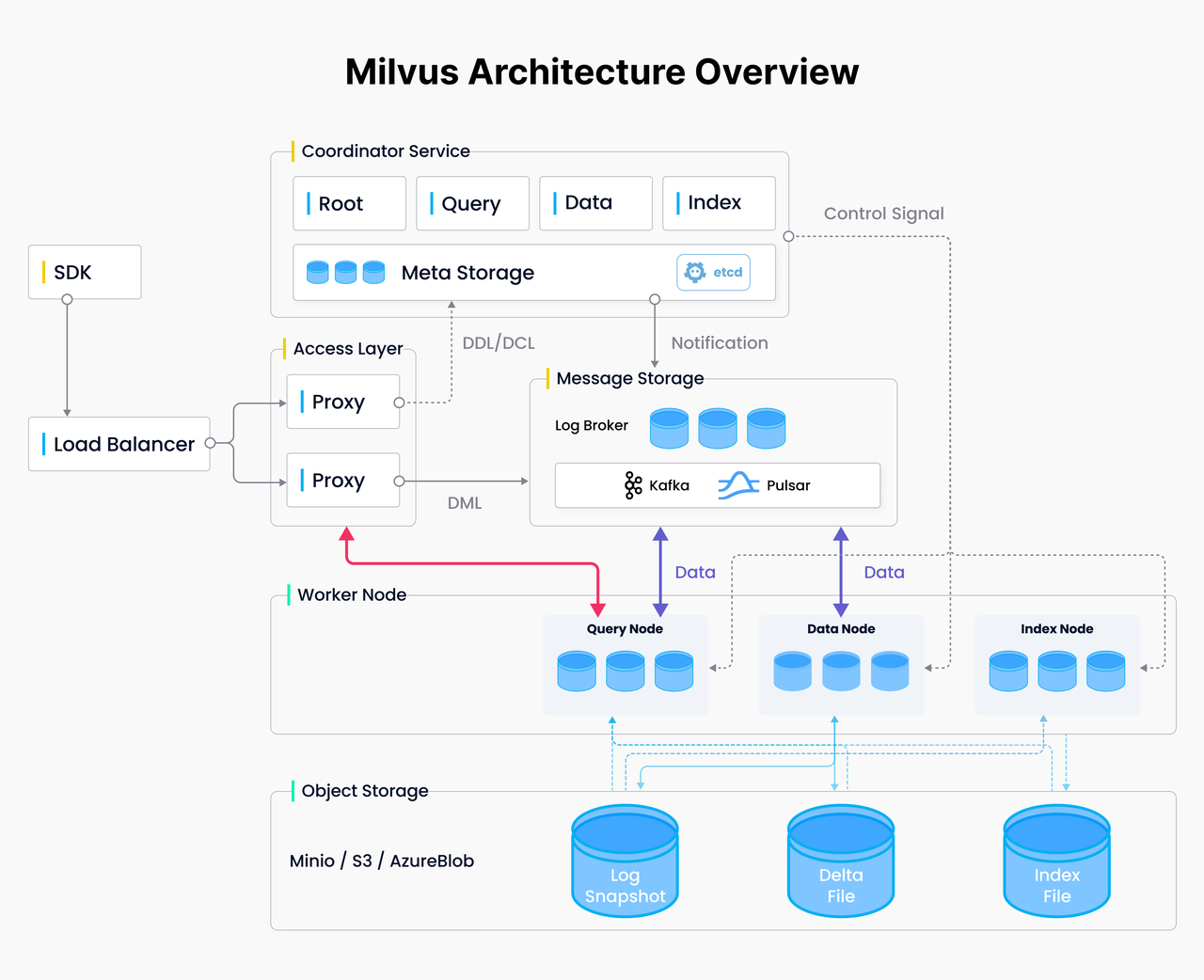
探索 Milvus 数据存储系统:如何评估和优化 Milvus 存储性能
Milvus 是一款支持水平扩展和具备出色性能的开源向量数据库。Milvus 的核心是其强大的存储系统,是数据持久化和存储的关键基础。该系统包括几个关键组成部分:元数据存储(meta storage)、消息存储(log broker)和对象存储(object storage)。

Langflow + Milvus,拖拉拽就能搞定的workflow教程来了
如果你想写个agent或者workflow,但是又不想在demo阶段投入太多精力去敲代码;