



使用Milvus对JSON数据进行向量化以进行相似性搜索

作者:David Wang 和 Rahul
引言
JSON,即JavaScript对象表示法,是一种用于服务器和Web应用程序之间数据存储和交换的文本格式。由于其简单性、灵活性和兼容性,开发者在各个行业和应用程序中使用JSON数据。例如,物联网(IoT)设备和传感器通过JSON与Web接口无缝通信。
然而,尽管JSON的层次结构很有用,但对于存储、检索和分析来说,处理起来可能会很麻烦。将JSON向量化可以将这些数据转换为一种优化的格式,以便于高效处理、存储、检索和分析,从而帮助提高性能和可用性。
本文探讨了Milvus向量数据库如何简化JSON数据的向量化、摄取和相似性检索。此外,我们提供了一个逐步指南,详细介绍了如何使用Milvus对JSON数据进行向量化、摄取和检索。
Milvus如何简化JSON数据向量化和检索
Milvus是一个高度可扩展的开源向量数据库,管理着大量高维向量数据。它适用于增强型检索生成(RAG)、语义搜索和推荐系统等用例。以下是Milvus如何促进高效的JSON数据处理和检索。
支持动态模式的JSON数据
Milvus支持在用户的集合中与向量数据一起无缝存储和查询JSON数据。有了这种能力,用户可以批量高效地插入JSON数据,并根据JSON字段中的值执行高级查询和过滤。这种能力对于需要动态模式更改的应用程序中详细数据分析和操作至关重要。
与主流嵌入模型集成
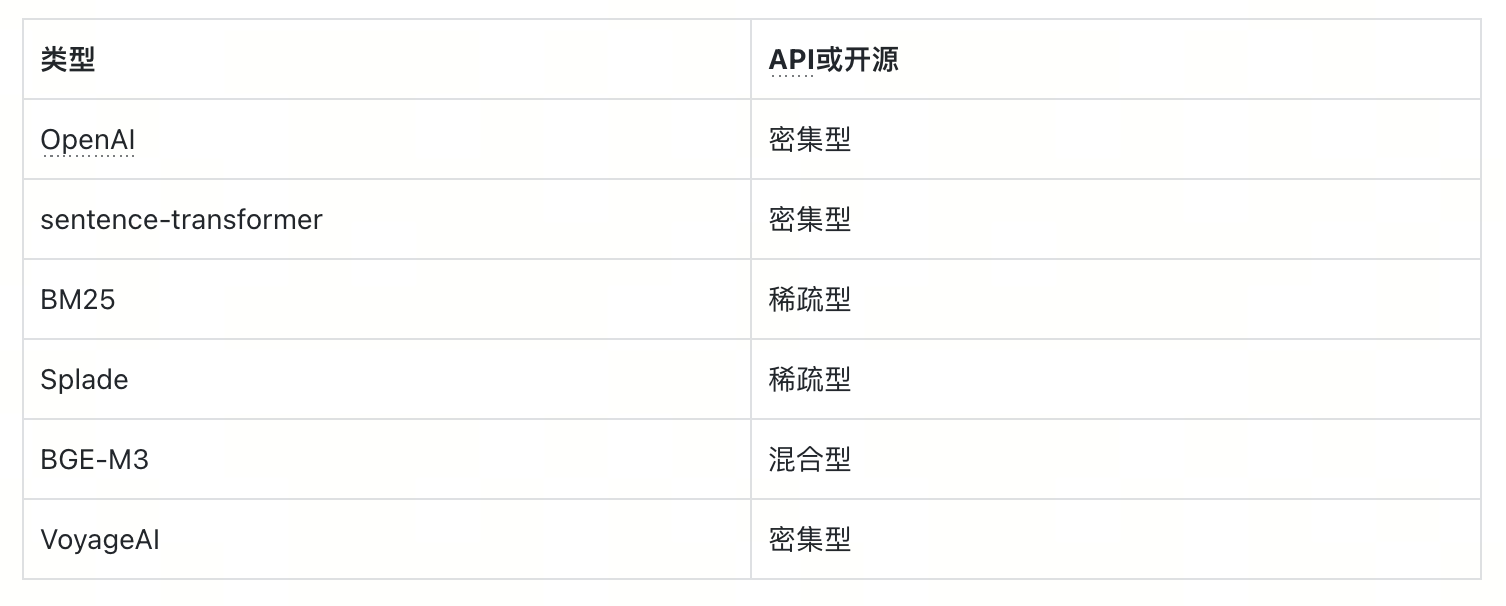
通过PyMilvus(Milvus的Python SDK),Milvus与主流嵌入模型集成,包括OpenAI嵌入API、sentence-transformer、BM25、Splade、BGE-M3和VoyageAI。这种集成简化了向量数据准备,并减少了整个数据管道的复杂性,而无需引入额外的数据堆栈。
嵌入函数
 85-1.png
85-1.png
如何使用Milvus进行嵌入生成和相似性搜索
在以下部分,我们将引导您通过与流行的嵌入模型集成来生成向量嵌入,并在JSON数据中进行相似性搜索。有关此逐步指南的完整代码,请参阅此处的笔记本。
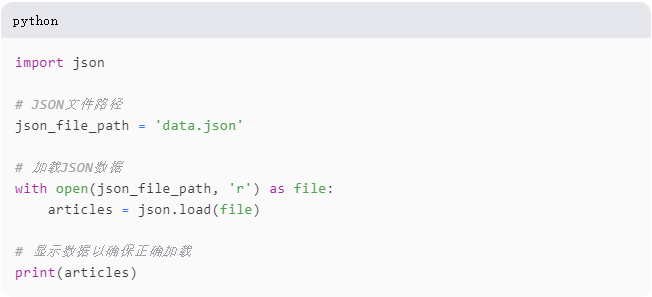
步骤1:导入JSON数据
 85-2.png
85-2.png
导入JSON库:这一行包括了Python内置的JSON库,用于处理JSON格式的数据。
设置JSON文件路径:它设置了您的JSON文件路径,假设它被命名为'data.json'。
加载并打印JSON数据:以读取模式打开JSON文件,将数据加载到一个文章变量中,并将其打印出来以验证是否正确加载。with语句确保文件在读取数据后自动关闭,使这种方法既高效又安全。
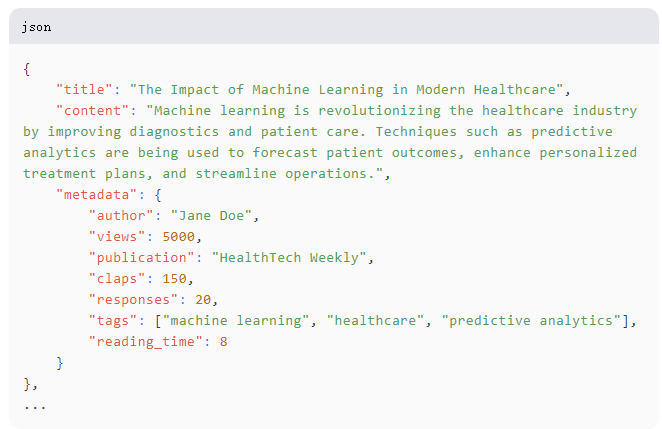
数据格式如下:
 85-3.png
85-3.png
步骤2:使用PyMilvus生成嵌入
Milvus通过PyMilvus与许多流行的嵌入模型集成,简化了开发过程。在这个例子中,我们将使用SentenceTransformerEmbeddingFunction,一个all-MiniLM-L6-v2句子变换器模型。
要使用这个嵌入函数,我们首先必须安装PyMilvus客户端库及其model子包,该子包封装了所有向量生成的实用工具。
 85-4.png
85-4.png
 85-5.png
85-5.png
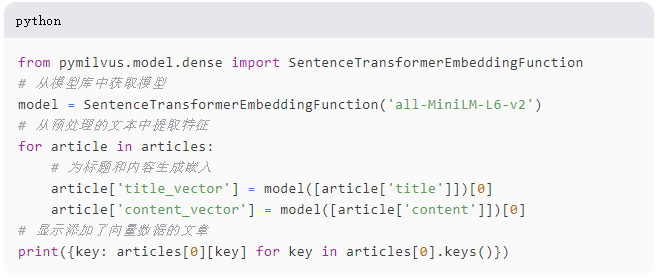
我们将只关注向量化“标题”和“内容”以保持简单。使用上述代码,我们已经向我们的数据中的两个字段添加了向量,并将其作为单独的字段保存。以下是步骤的分解:
model = SentenceTransformerEmbeddingFunction('all-MiniLM-L6-v2'):这一行加载了'all-MiniLM-L6-v2'模型,这是一个使用PyMilvus模型库的预训练模型。这个模型以生成文本输入的密集向量嵌入而闻名。article['title_vector'] = model.encode(article['title'])和article['content_vector'] = model.encode(article['content']):这些行应用加载的句子变换器模型将每篇文章的标题和内容编码为向量嵌入。encode函数将文本信息转换为高维空间,其中语义相似的文本向量更接近。这种转换对于许多依赖于理解文本背后语义的机器学习应用(如语义搜索、聚类和信息检索)至关重要。print({key: articles[0][key] for key in articles[0].keys()}):最后一行打印了第一篇文章的所有键值对,包括新添加的标题和内容的向量。
输出提供了文本数据如何通过数值表示增强的直观可视化,展示了为数据驱动应用丰富的数据结构。
步骤3:设置Milvus
现在,我们使用Milvus向量数据库来管理从文本数据派生的向量嵌入。
 85-6.png
85-6.png
让我们更深入地了解:
connections.connect(alias="default", host="localhost", port="19530"):这一行在本地机器(localhost)的19530端口上建立与Milvus服务器的连接。alias="default"参数意味着此连接是后续操作中的默认连接。这一步建立了应用程序与向量数据库之间的通信,允许进行数据插入、查询和管理等操作。FieldSchema和CollectionSchema:在Milvus中存储数据的字段使用FieldSchema定义。每个字段都有特定角色:- id:配置为整数字段,设置为主键,并自动分配唯一标识符给每个条目。
- title_vector 和 content_vector:这些字段存储浮点向量(FLOAT_VECTOR),分别表示文章标题和内容嵌入。dim=384指定了这些向量的维度,与嵌入模型的输出大小相匹配。
- 这些字段定义被分组到一个
CollectionSchema中,这基本上描述了集合将持有的数据的结构和类型,包括一个可读的描述。
步骤4:插入数据
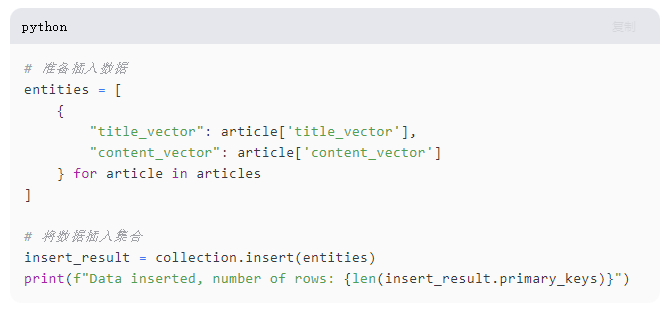 85-7.png
85-7.png
列表推导式 entities = [{"title_vector": article['title_vector'], "content_vector": article['content_vector']} for article in articles] 构建了一个字典列表,其中每个字典表示要插入到Milvus集合中的实体。这些向量以匹配Milvus集合模式中定义的字段(title_vector 和 content_vector)的格式准备。
insert_result = collection.insert(entities) 行将准备好的实体插入集合。这个操作对于用向量数据填充Milvus数据库至关重要,用于各种检索任务,如相似性搜索或机器学习模型输入。
print(f"Data inserted, number of rows: {len(insert_result.primary_keys)}"):在数据插入后,这一行打印出成功插入的行数(实体)。insert_result.primary_keys提供了每个插入记录的唯一标识符,反映了已添加的条目数量。这种反馈对于验证数据是否已正确且完整地存储在集合中很重要。
步骤5:创建索引
索引在任何数据库管理系统中都至关重要,因为它直接影响搜索查询的性能。对于AI应用,实时分析和响应能力至关重要,高效的索引可以显著增强用户体验。
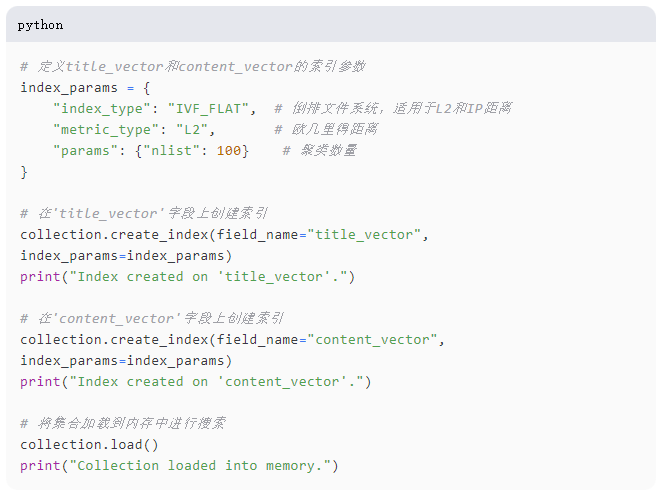 85-8.png
85-8.png
通过聚类向量空间,IVF_FLAT索引减少了查询的搜索空间,显著提高了搜索速度,尤其是随着数据集的增长。最终,我们将集合加载到内存中以提高操作效率。使用IVF_FLAT索引类型,我们将向量空间划分为100个聚类,并使用L2度量进行欧几里得距离计算,这提高了搜索效率和准确性。然后,我们在title_vector和content_vector字段上创建索引,以加速检索任务,并在每次创建后提供确认反馈,以确保成功设置。
步骤6:执行相似性搜索
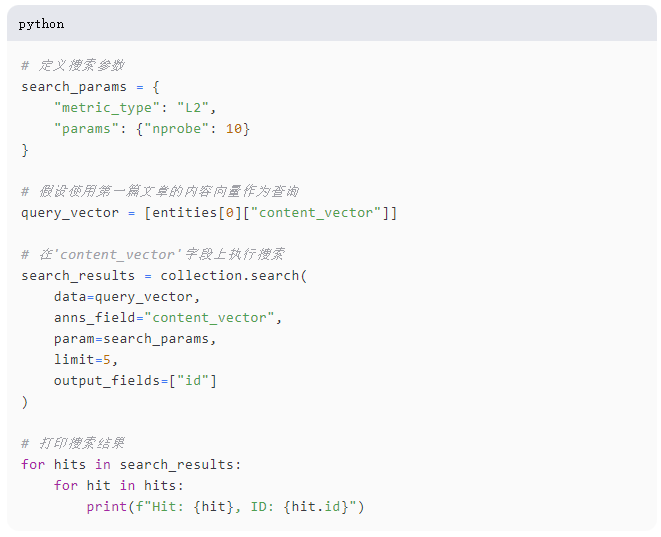 85-9.png
85-9.png
这个过程首先在search_params字典中定义搜索参数,使用L2度量来测量向量之间的欧几里得距离,nprobe设置为10,以确保在搜索速度和准确性之间取得平衡。使用第一篇文章的content_vector准备查询向量,旨在在集合中找到内容相似的文章。搜索使用这些参数在content_vector字段上,将结果限制为最接近的5个匹配项,并返回它们的ID。
最后,通过打印每个匹配项及其ID来迭代搜索结果,以展示查询的有效性,通过识别基于其向量化内容表示与初始查询最相似的文章。
结论
向量数据库优化了JSON数据的向量化和查询,使得相似性搜索、复杂模式识别和超越传统数据库限制的关系查询成为可能。Milvus向量数据库支持与向量数据一起存储和检索JSON数据,并与主流嵌入模型集成以生成向量。这种集成帮助开发者轻松地向量化他们的JSON数据,而无需添加额外的数据堆栈,显著简化了开发过程。
此外,当JSON数据中的不是所有键都包含在每个文档中时,会发生稀疏性,导致向量中有许多零值,表示缺失或空信息。这创建了一个复杂的高维向量空间,使得处理和查询变得具有挑战性。Milvus与嵌入模型的集成优化了数据结构和算法,以有效管理稀疏、高维数据。例如,它采用动态模式,能够适应不同的数据大小和类型,实现对复杂JSON结构的有效存储和查询,最小化预处理需求。

Rahul
Freelance Technical Writer


技术干货
重磅版本发布|三大关键特性带你认识 Milvus 2.2.9 :JSON、PartitionKey、Dynamic Schema
随着 LLM 的持续火爆,众多应用开发者将目光投向了向量数据库领域,而作为开源向量数据库的领先者,Milvus 也充分吸收了大量来自社区、用户、AI 从业者的建议,把重心投入到了开发者使用体验上,以简化开发者的使用门槛。
2023-6-5
技术干货
门槛一降再降,易用性大幅提升!Milvus 2.2.12 持续升级中
一句话总结 Milvus 2.2.12 :低门槛、高可用、强性能。
2023-7-27
技术干货
如何设计一个面向开发者全生命周期成本的全托管向量检索服务产品?
作为产品的设计者和开发者,必须始终以用户为中心,积极倾听他们的需求,并集中精力降低软件开发的全链路成本,而非过度追求极致性能或过分炫技。在这种背景下,降低开发者的综合使用成本已成为 Zilliz Cloud 和开发团队过去的主要使命。
2023-7-5