



文本转换:句子变换器在自然语言处理中的崛起
关于变换器模型,你需要知道的一切,探索其架构、实现和局限性。句子变换器模型是人工智能领域的一个重要突破,因为它使得生成句子级别的嵌入成为可能,与词级嵌入相比,这提供了更广泛的适用性。
自然语言处理(NLP)是人工智能中一个受欢迎的领域,因为它有众多的应用,从简单的情感分析到更复杂的聊天机器人。当我们遇到需要NLP的用例时,我们通常有文本作为输入,并希望一个深度学习模型执行特定任务。
然而,深度学习模型不能直接处理文本。我们需要将文本转换为一个高维向量,称为嵌入。这个嵌入是我们的深度学习模型可以理解的。在本文中,我们将探讨将文本转换为嵌入的不同方法的演变,并讨论句子变换器如何彻底改变文本嵌入技术。
Word2Vec和Glove:早期方法
在引入先进的深度学习模型之前,有两种常见的方法被用来将文本转换为嵌入:Word2Vec和Glove。Word2Vec是一个基本的前馈神经网络,只有一个隐藏层,被训练用来学习每个词的嵌入。相比之下,Glove是一种旨在捕捉文本语料库中词对共现的算法。
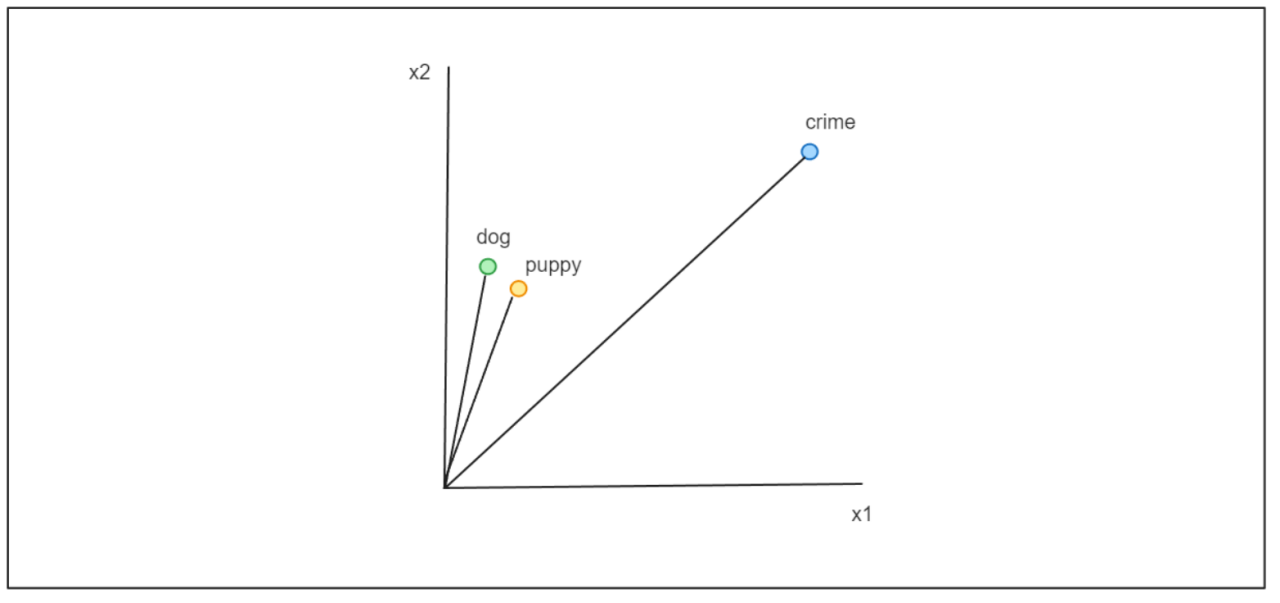
虽然这两种方法在训练方法上有所不同,但它们有一个共同的目标:将词转换为嵌入。这些嵌入不仅仅是随机向量;它们包含与相应词相关的语义信息。这意味着相似词的嵌入在向量空间中往往彼此接近。
 26-1.png
26-1.png
例如,单词“dog”的嵌入在向量空间中会接近“puppy”,而它们可能与单词“crime”的嵌入相距甚远,因为它们的语义含义不同。
然而,使用Word2Vec和Glove至少存在两个重大挑战。
首先,Word2Vec和Glove是词嵌入模型。需要特定的技术来获得句子级别的嵌入。一种常见的方法是使用简单方法或TF-IDF方法对词嵌入进行平均加权。不幸的是,这些方法通常会产生次优的结果。
其次,考虑这两个句子:“I walk my dog in the park”(我在公园遛狗)和“I park my car in the garage”(我把车停在车库里)。尽管“park”这个词在两个不同的环境中使用,但它在这两个句子中会有相同的嵌入。
这种局限性表明,Word2Vec和Glove都难以捕捉句子中每个词的上下文含义,导致各种任务中的不准确性。
这就是变换器发挥作用的地方。
变换器概述
变换器是人工智能领域最重要的突破之一,因为它们具有灵活的架构,使它们能够处理从文本分类到文本生成的各种任务。领先的NLP模型如BERT、XLM-Roberta和GPT都将其架构的核心集成了变换器。那么,究竟是什么使变换器如此强大呢?
 26-2.png
26-2.png
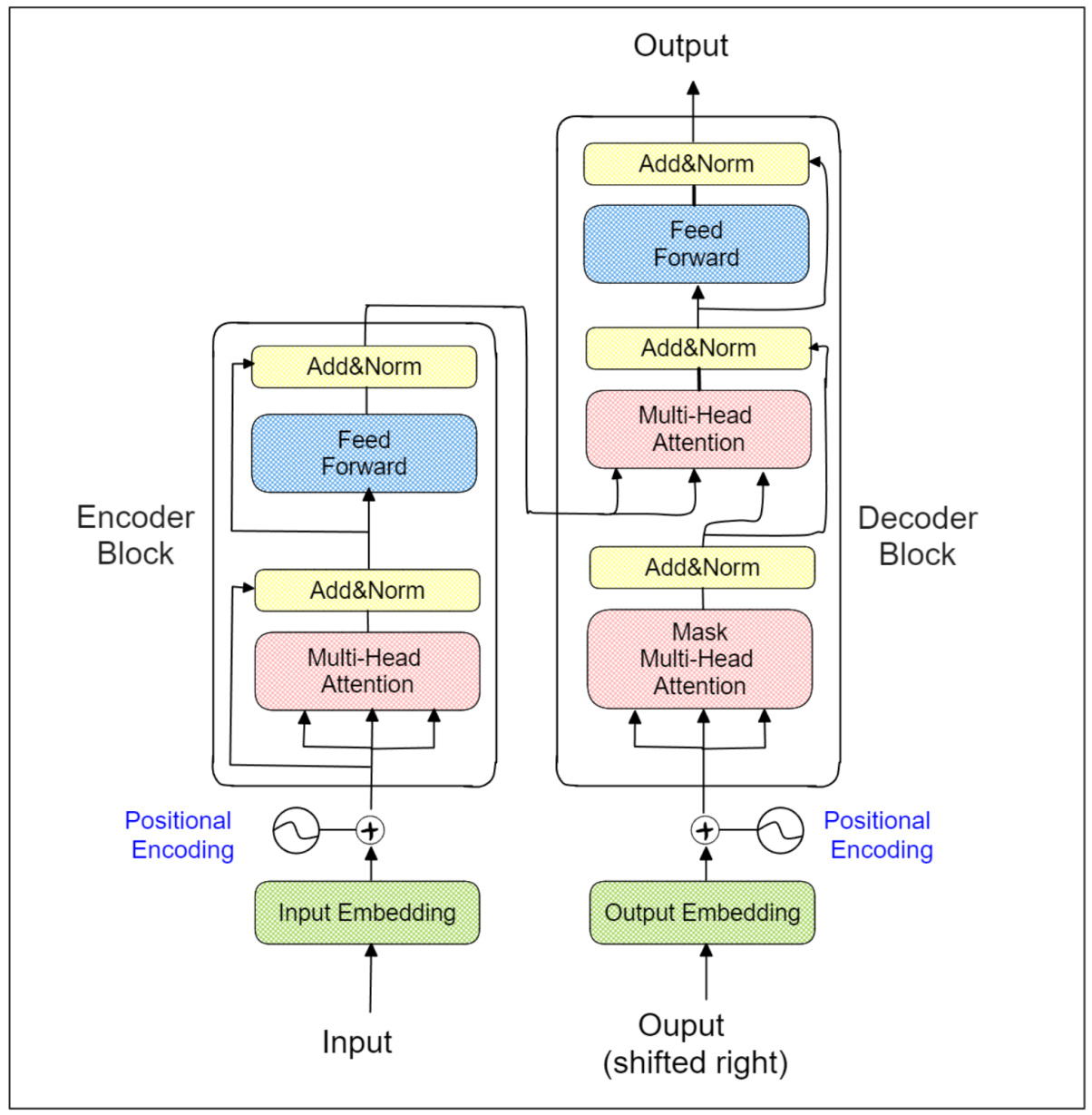
简而言之,变换器架构由多个编码器和解码器块组成。每个块包括一个专门的注意力层,使模型能够学习每个词(或标记)与整个句子的关系。因此,在句子“I walk my dog in the park”和“I park my car in the garage”中,“park”这个词将被不同地嵌入。
变换器的编码器组件主要用于分类任务,如情感分析、问答和命名实体识别。利用变换器编码器的最先进的模型包括BERT、DistilBERT和XLM-Roberta。另一方面,解码器组件通常用于序列生成。利用变换器解码器的一个主要例子是GPT家族,它是ChatGPT的基础。
句子变换器概述
句子变换器利用变换器的编码部分来生成句子的嵌入。本质上,你可以将其视为BERT、Roberta或XLM-Roberta等基于编码器的变换器模型的微调版本。
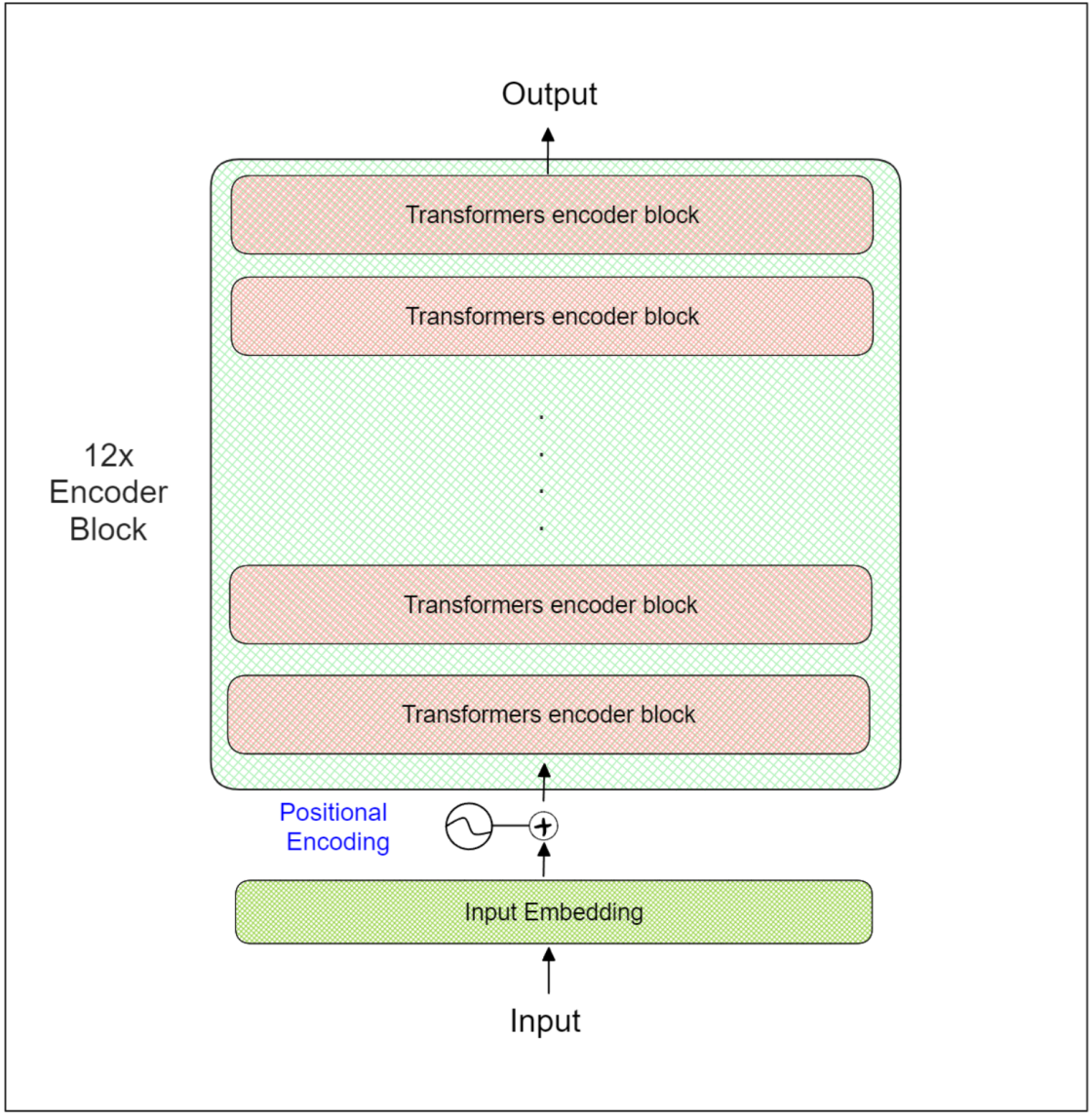
为了说明句子变换器的内部工作,让我们以BERT-base模型为例。BERT-base模型由总共12个变换器编码器块组成,如下图所示:
 26-3.png
26-3.png
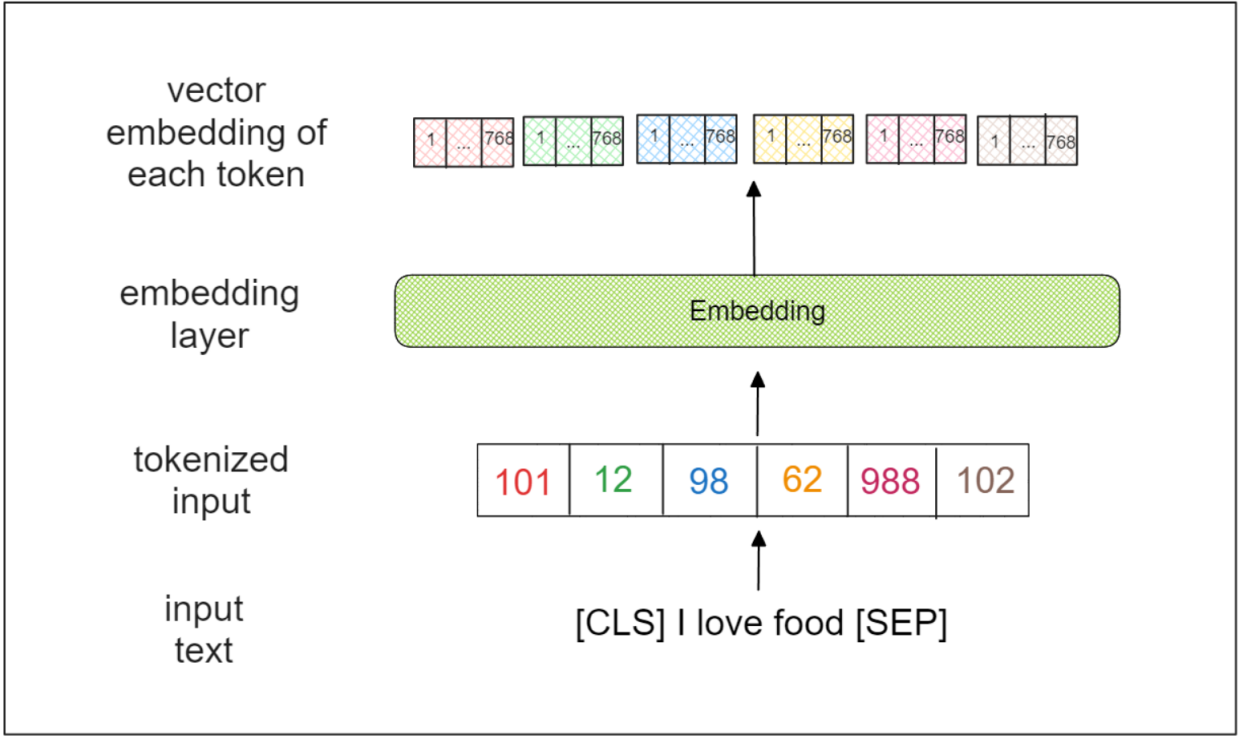
BERT-base模型接受整个序列作为输入。第一步涉及在输入序列的开头和结尾添加两个特殊标记,即[CLS]和[SEP]。例如,输入序列“I love food”将被转换为“[CLS] I love food [SEP]”。
接下来,输入序列被转换为一系列标记,每个标记代表一个词、一个子词甚至一个字符。在BERT的上下文中,每个标记代表一个子词。标记化的输入通过一个嵌入层,为每个标记输出一个768维向量。
 26-4.png
26-4.png
然后,每个标记的向量嵌入通过一系列12个变换器编码器块。在每个块中,注意力层学习每个标记与整个输入序列的关系。
我们在最后一个变换器编码器块中获得每个标记的学习向量嵌入。然而,向量嵌入仍然在标记级别。现在,问题是:我们如何获得句子级别的向量嵌入?
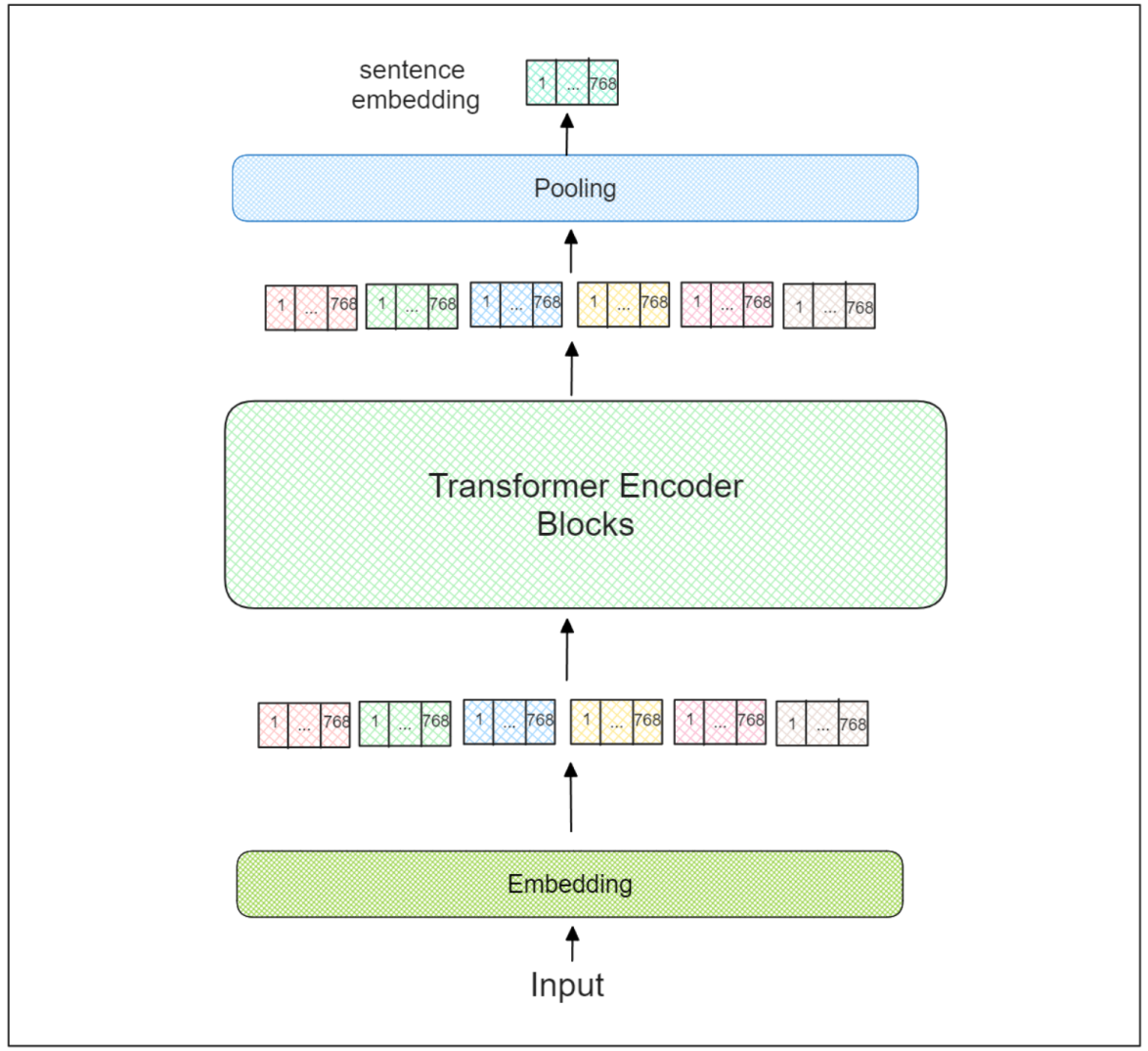
句子变换器在最后一个变换器编码器块上增加了一个额外的池化层。在使用句子变换器时,推荐使用三种池化策略:
直接使用[CLS]标记的向量嵌入。
利用所有标记嵌入的平均值。
使用所有标记嵌入的最大值。
 26-5.png
26-5.png
这个池化层的结果基本上代表了整个输入序列的嵌入向量。然后,这个嵌入可以用于各种任务,我们将在下一节中讨论。
句子变换器的实现
我们可以使用从句子变换器模型获得的句子级嵌入来完成多种任务,如文本相似性、文本情感分析、信息检索、文档摘要、聚类等。
在这些任务中,文本相似性和信息检索是句子变换器最常见的应用。因此,在本节中,我们将向您展示如何使用PyTorch中的sentence-transformers库实现这两个任务。
在以下示例中,我们将使用一个名为all-MiniLM-L6-v2的预训练句子变换器模型。假设我们希望获得句子“I love food”的向量嵌入。我们可以通过调用model.encode()方法轻松实现,如下所示:
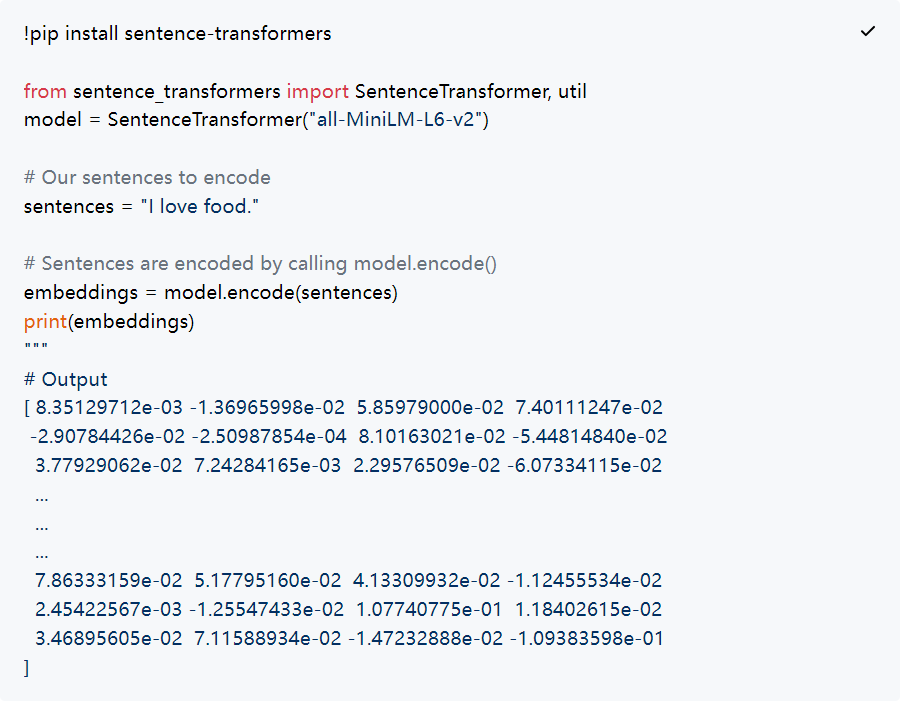 26-6.png
26-6.png
现在我们可以使用这个嵌入做多种事情。例如,我们可以将这个嵌入与其他文本的嵌入进行比较,以找到最相似的文本。
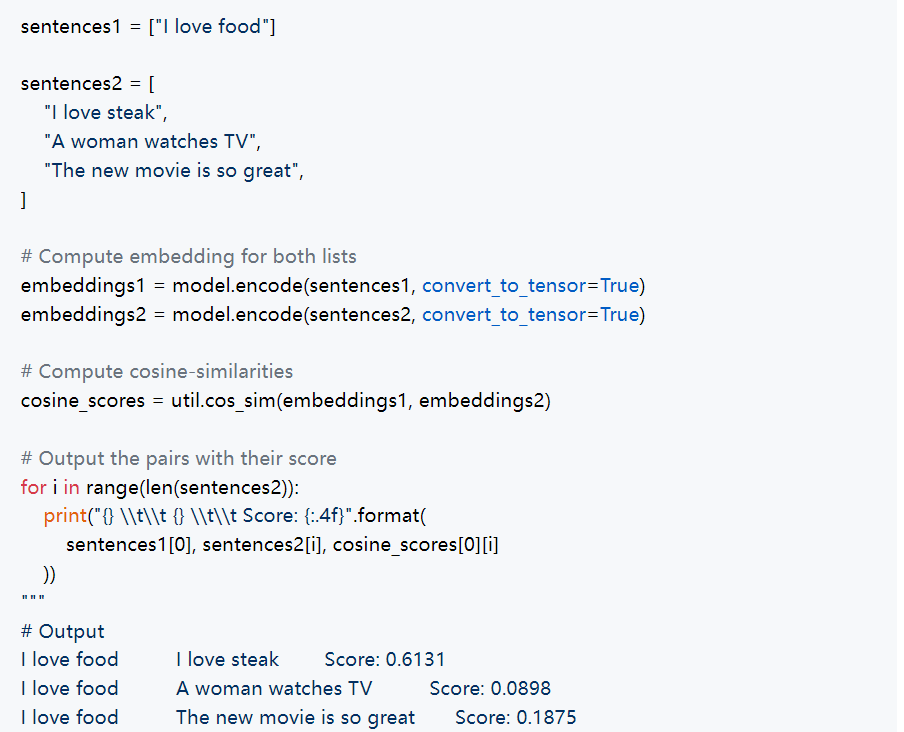 26-7.png
26-7.png
如你所见,文本“I love steak”与文本“I love food”的语义相似度最高,与其他示例相比。这个结果很合理,因为牛排是食物的一个子集,而其他文本与食物没有主题关联。
句子变换器的另一个常见用例是在信息检索领域。在这种情况下,我们通常会将单个文本的嵌入存储在专用数据库中,例如向量数据库。然后,当我们需要关于特定文本的信息时,我们会从数据库中获取嵌入。
例如,假设我们的数据库中包含以下文本:
 26-8.png
26-8.png
让我们考虑一个场景,我们有一个查询:“A man is sitting at the dinner table. What’s he doing?”(一个男人坐在餐桌旁。他在做什么?),我们的目标是从数据库中检索最可能的答案。为了实现这一点,我们可以计算我们的查询与数据库中每个条目的相似度。
query = "A man is sitting at the dinner table. What's he doing?"
# Find the closest 2 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(2, len(corpus))
query_embedding = model.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print("Query:", query)print("\\nTop 2 most similar sentences in corpus:")
for score, idx in zip(top_results[0], top_results[1]):
print(corpus[idx], "(Score: {:.4f})".format(score))"""
Output:Query: A man is sitting at the dinner table. What's he doing?
Top 2 most similar sentences in corpus:
A man is eating food. (Score: 0.4170)
A man is riding a horse. (Score: 0.2206)
从我们的角度来看,对我们的查询最合适的回应将是“A man is eating food”,这与嵌入相似性显示的结果一致。
在最近的进展中,句子变换器产生的嵌入可以用于提高检索增强生成(RAG)框架内GPT模型的准确性。这种方法使GPT模型能够更有效地检索内部信息,促进生成与上下文相关的答案。
句子变换器训练过程
如果你注意到,在上述实现部分,我们使用了预训练模型来生成文本嵌入。然而,如果预训练模型产生的嵌入不够好怎么办?或者在需要为没有可用预训练模型的外语文本生成嵌入的情况下怎么办?
这就是我们可能需要自己训练句子变换器模型的场景。
句子变换器模型的训练过程与常规孪生神经网络的训练过程完全相同。它接受两个输入,并基于它们的语义含义确定这两个输入之间的相似度。不相似对的嵌入被推得更远,而相似对的嵌入则被拉近。
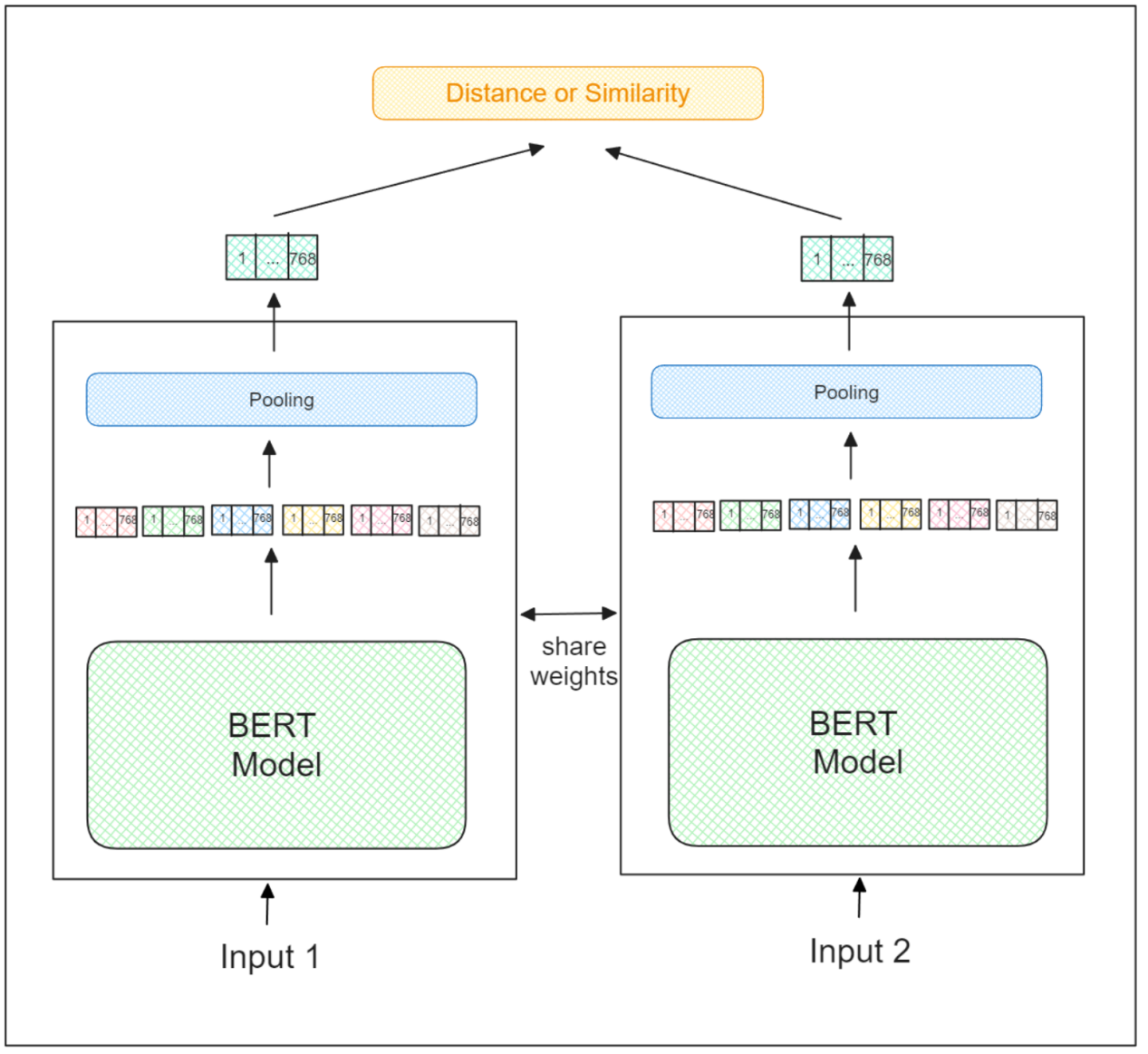 26-9.png
26-9.png
因此,需要大量的训练数据来训练句子变换器模型,其中每条数据包括两个句子作为输入和它们相应的相似度标签。
然而,并没有一种一成不变的方法来设置两个句子之间的相似度。这主要是因为它在很大程度上取决于你的目标和你数据的结构。
例如,你可能会在同一个报告中的两个句子之间设置更高的相似度,而不是来自不同报告的两个句子。同样,相邻句子之间的相似度可能会被设置得比非相邻句子之间的相似度更高。此外,你可以用二元相似度值标记训练数据;如果两个句子相互矛盾,相似度应为0,反之,如果它们一致,相似度应为1。
句子变换器的挑战和改进
总的来说,句子变换器在生成句子级嵌入方面的准确性超过了Word2Vec或Glove等更传统的方法,这得益于其先进的变换器架构。然而,正如前一节所示,训练句子变换器模型的过程需要在准备训练数据方面付出巨大的努力。你需要明确标记两个输入文本之间的相似度。为了应对这一挑战,目前有积极的研究旨在确定训练句子变换器的最佳无监督方法。
一个例子是TSDAE,一种基于去噪自编码器的无监督句子嵌入学习技术。在这种方法中,噪声被引入输入文本。然后,编码器将这种带噪声的输入映射到向量嵌入。解码器随后尝试通过消除噪声来重建原始文本。最后,我们使用编码器作为句子嵌入方法。
另一种方法是simCSE,一种直接的无监督句子嵌入学习技术,其中相同的输入文本被编码两次。由于变换器架构内的dropout机制,生成的向量嵌入会稍微不同。然后目标是最小化这两个嵌入之间的距离,同时最大化与同一批中其他输入文本的向量嵌入的距离。
然而,训练句子变换器模型的无监督学习领域的研究仍有很长的路要走,因为无监督方式训练的模型的性能仍然远远不如其监督版本。
结论
在本文中,我们学习了关于变换器模型的所有知识,探索了其架构、实现和局限性。总体而言,句子变换器模型是人工智能领域的一个重要突破,因为它使得生成句子级别的嵌入成为可能,与词级嵌入相比,这提供了更广泛的适用性。
句子级别的嵌入提供了更准确、更具上下文感知能力的文本表示。这使它们在包括语义相似性、信息检索、语义搜索、文本分类等在内的广泛的自然语言处理任务中变得非常宝贵。此外,将句子变换器嵌入与RAG场景中的GPT模型集成,已经显示出在提高生成答案的准确性和相关性方面的有希望的结果。
希望本文能帮助你开始使用句子变换器!
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer


