



2024年顶级 LLMs:唯有佼佼者
引言
在一个变化是唯一不变的世界中,大型语言模型(LLMs)代表了自然语言处理的最高水平进化。这些高度复杂的人工智能程序改变了我们与技术的关系,以及我们对语言理解、产生和应用的能力。
随着我们进入2024年,关于LLMs中改变游戏规则模型的许多说法存在。但不用担心!我们在这里为您提供一个有趣、真实、无废话的概述,介绍今年将发生的事情。让我们毫不犹豫地介绍2024年顶级LLMs。
OpenAI 的 GPT-4
OpenAI 的生成预训练变压器(GPT)模型点燃了人工智能发展的第一波兴奋。在这些模型中,GPT-4 作为 GPT 3.5 成功之后的显著进步脱颖而出。这个 GPT 系列迭代引入了许多增强功能,包括提高推理能力、先进的图像处理和扩展的上下文窗口,能够处理超过25,000个单词的文本。
除了其技术实力外,GPT-4 在情感智能方面也取得了显著进步,使其能够与用户进行富有同理心的互动。这种属性在客户服务互动等用例中非常有价值,超过了传统的搜索引擎或内容生成器。此外,GPT-4 可以生成更具包容性和无偏见的内容,解决了关于公平性和公正性的相关问题。它还纳入了强大的安全措施,以防范数据滥用或处理不当,促进用户信任并维护机密性。
OpenAI 还提供了多模态模型,如 GPT-4o,能够跨音频、视觉和文本进行推理。
Gemini:NLP中的黑马
谷歌的 Gemini 是一个以其独特的专家混合(MoE)架构而著称的语言模型。它解决了许多语言模型应用中的关键挑战,特别是关于能效和微调的必要性。它包括三个版本 —— Gemini Ultra、Gemini Pro 和 Gemini Nano —— 针对不同的规模和目标量身定制,每个版本都提供不同程度的复杂性和适应性,以有效满足特定要求。
Gemini 的 MoE 架构根据输入选择性激活相关组件,促进了加速收敛和提高性能,而不会带来巨大的计算开销。此外,Gemini 通过在每个训练步骤更新指定权重引入参数稀疏性,减轻了计算负担,缩短了训练时间,并减少了能源消耗 —— 这是促进环保和成本效益的大型 AI 模型训练过程的重要一步。
最新版本 Gemini 1.5 在其前身的基础上进行了优化,提供了如扩展上下文窗口(可跨越高达1000万个标记)和由于其 MoE 架构而减少训练计算需求的优化功能。在其成就中,它在管理长上下文多模态任务方面表现出熟练,并在基准评估如 1H-VideoQA 和 EgoSchema 中展示了改进的准确性。
Cohere:NLP的新宠
Cohere 是另一个创新的语言模型,为理解和生成类似人类的文本带来了新视角。它为解决现实世界的挑战提供了众多应用,如内容生成和情感分析。
Cohere 的一个突出特点是其能够基于提供的关键词、提示或结构化数据快速生成文章、博客或社交媒体帖子。这一功能对于时间紧迫、寻求及时吸引人内容的营销人员特别有益,因为 Cohere 熟练地制作标题、标题和描述,显著简化了手动工作。 此外,Cohere 在情感分析方面表现出色,利用自然语言处理(NLP)的能力来识别给定文本中的情感基调 —— 积极、消极或中立。这种能力使企业能够通过评论和反馈衡量客户对其产品或服务的情感。此外,它还使组织能够理解公众对政治或体育的情感,帮助在确保与主流偏好一致的情况下进行活动规划。
Falcon:速度与准确性的结合
由 Training Infrastructure Intelligence (TII) 开发的 Falcon 以其在各种应用中的速度和准确性而获得赞誉。它提供两种主要模型:Falcon-40B 和 Falcon-7B,这两种模型在 Open LLM Leaderboard 上都展示了令人印象深刻的性能。 Falcon 模型采用定制的变压器架构,专注于解码,同时整合了创新组件,如 Flash Attention、RoPE 嵌入(通过随机排列学习的位置编码)、多查询注意力头、并行注意力层和前馈层。这些增强功能显著提高了推理速度,在测试阶段,当单个示例按顺序处理时,速度超过了 GPT-3 达五倍。
尽管在预训练期间所需的计算能力比 GPT-3 少了75%,但 Falcon 40 仍然需要大约 90GB 的 GPU 内存。然而,对于微调或在消费级笔记本电脑上运行推理,需求减少到大约 15 千兆字节。值得注意的是,Falcon 在分类或摘要等任务中表现出色,优先考虑速度而不牺牲质量,使其成为在快速完成至关重要的情况下的首选。
Mixtral:多才多艺
由 Mistral AI 开发的 Mixtral 是一个语言模型,因其广泛的 NLP 应用而获得显著的流行。它的设计和功能使其成为企业和开发人员需要的全面解决方案,以解决语言问题。Mixtral 可以同时处理基于语言的任务,如写文章、生成摘要、翻译语言甚至编码,强调其在各种情境中的适用性。这个模型最令人印象深刻的是其能够适应不同的语言和情况,增强全球通信并为不同人群提供服务。
从技术角度来看,Mixtral 采用稀疏专家混合 (SMoE) 架构,通过为每个任务选择性激活模型内的组件来优化效率。这种有针对性的方法降低了计算成本,同时提高了处理速度。例如,Mixtral 8x7B 拥有 32k 标记的大量上下文窗口大小。这一功能使其能够熟练地管理长篇对话,并处理需要对上下文有细微理解的复杂文档,促进了详细的内容创建和高级检索增强生成的精度和效果。
尽管有许多参数,Mixtral 提供了类似于小型模型的成本效益推理,使其成为需要高级 NLP 能力但不希望承担高计算成本的企业的首选。支持多种语言,包括法语、德语、西班牙语、意大利语和英语,使 Mixtral 成为寻求全球通信渠道和内容生成能力的国际公司的宝贵资产。
Llama
人民的 LLM 由 Meta 开发的一系列开源语言模型 Llama 因其致力于可访问性和用户友好性而被誉为“人民的 LLM”。这种独特的关注点使 Llama 模型成为那些优先考虑数据安全并寻求独立于通用第三方选项开发定制 LLM 的人的首选。在其迭代中,Llama2 和 Llama3 特别突出。
Llama2 具有一套预训练和微调的 LLM,训练参数范围从 7B 到 70B。与其前身 Llama1 相比,Llama2 在 40% 更多的标记上进行了训练,并拥有显著扩展的上下文窗口。此外,Llama2 提供直观的界面和工具,最小化了非专家的入门障碍,并与 Hugging Face Model Hub 无缝集成,方便地访问预训练语言模型和数据集。
比 Llama2 有显著进步的 Llama3 是向前迈出的一大步。在参数范围从 8B 到 70B 的数据集上预训练和微调,Llama3 在上下文理解、推理、代码生成和各种复杂的多步骤任务中表现出增强的性能。此外,它完善了其后训练过程,导致误拒率显著降低,响应对齐性提高,并在模型答案中增加了多样性。Llama3 很快将在 AWS、GCP、Azure 和许多其他公共云上提供。
并排比较
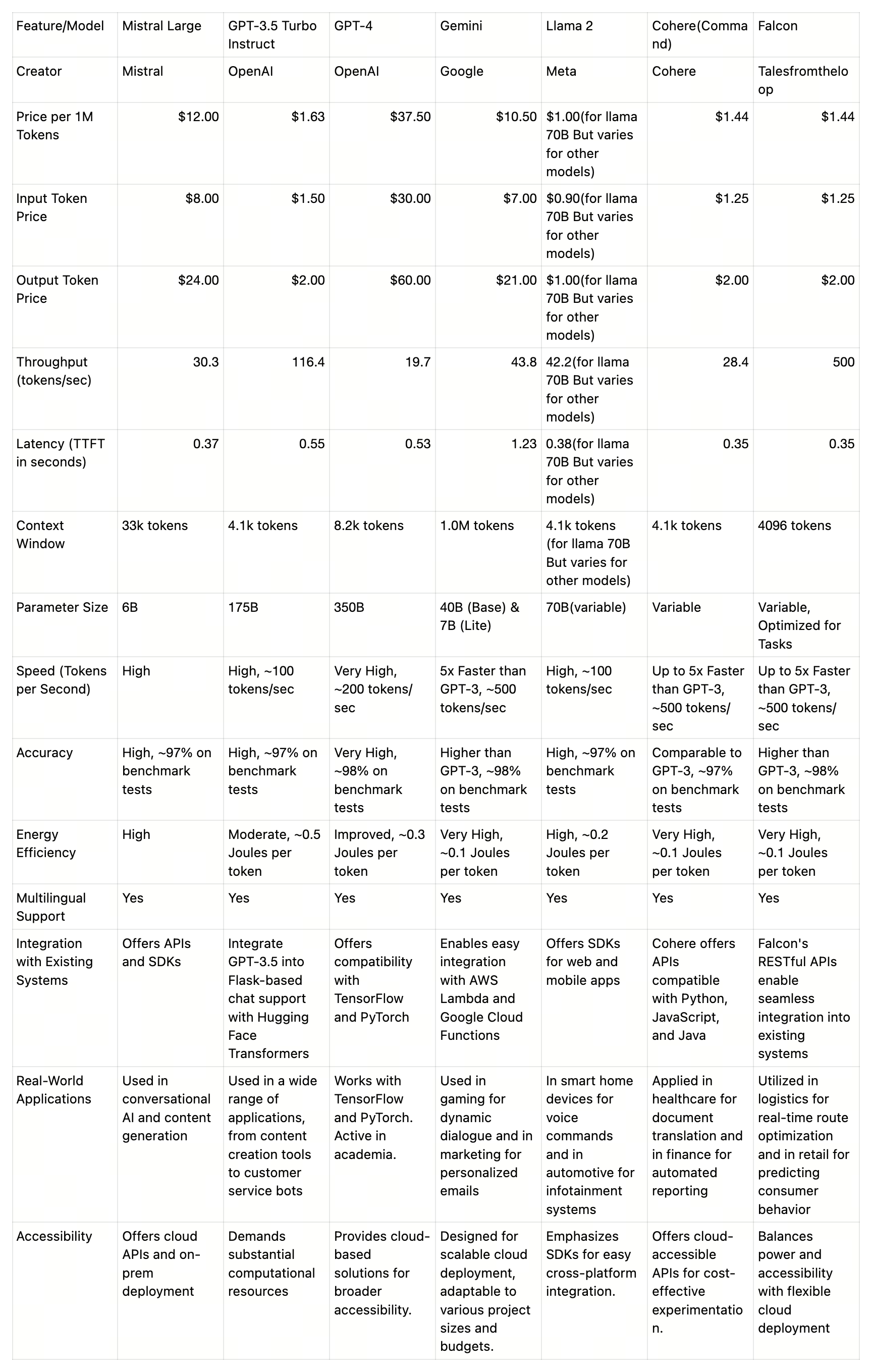 83-1.png
83-1.png
结论:选择你的冠军 我们今天突出的模型在 2024 年脱颖而出。从 OpenAI 的 GPT-4 及其多功能性到 Cohere 对连贯性的激光般聚焦,每个 LLM 都提供了独特且改变游戏规则的东西。 但真正的问题是,哪一个适合你?当您在 LLM 领域导航时,考虑您的特定需求和用例至关重要。您是否需要为时间敏感的应用程序提供闪电般的性能?Cohere 的连贯性可能是您最好的选择。或者您是否正在寻找一个高效的、资源轻的模型用于您的移动应用程序?Gemini 可能是完美的选择。 最终,选择权在你手中。但有一点是肯定的:有了这些顶级 LLMs,可能性是无限的。那么,你还在等什么呢?是时候释放语言处理的力量,将您的业务或项目提升到新的高度了。



