



LLM-Eval:评估 LLM 对话的简化方法
介绍
过去几年,大型语言模型(LLM)的快速增长需要一种强大的方法来评估它们的生成质量。正如您可能已经知道的,LLM 在核心上已经被预训练为给定先前令牌的情况下预测最可能的下一个令牌。这意味着这些 LLM 在生成对用户查询的响应时可能会产生幻觉。
幻觉现象是指 LLM 的响应看起来连贯且令人信服,但其真实性完全错误。当模型在预训练过程中获得的内部知识无法回答问题时,可能会发生这个问题。例如,如果我们询问 LLM 一个与我们的用例过于具体的问题,如涉及专有数据的查询,可能会发生幻觉。
问题是,除非我们是 LLM 响应所基于领域的主题专家,否则很难发现幻觉。因此,必须有一种方法来评估这些 LLM 生成的响应质量,这就是我们将在本文中讨论的。
在这篇文章中,我们将讨论一种名为 LLM-Eval 的方法,它用于评估 LLM 的响应质量。
什么是 LLM-Eval?
LLM-Eval 是一种旨在简化和自动化评估 LLM 对话质量的方法。与分别评估对话的每个方面(如其相关性或语法正确性)不同,LLM-Eval 将所有这些评估合并为一个简化的过程。LLM-Eval 的关键特点是它允许使用单个提示来评估生成的对话响应在多个维度(如适当性、内容、语法和相关性)上的表现。
LLM-Eval 评估指标
在更复杂的方法出现之前,ROUGE 和 BLEU 是评估 LLM 生成的响应质量的两个最受欢迎的指标。简而言之,这两个指标的作用如下:
- BLEU 分数计算我们的 LLM 生成的文本与参考文本之间的 n-gram 精确度。n-gram 中的 "n" 可以是您事先选择的任何整数。
- ROUGE 分数计算我们的 LLM 生成的文本与参考文本之间的相似性,使用重叠的 n-gram 和词序列。
这两个指标的问题在于它们无法捕捉文本的语义意义。语义意义在评估 LLM 的性能时至关重要,因为我们需要捕捉 LLM 对用户查询的响应的细微差别和本质。此外,许多高级方法依赖于人工注释和多个提示,这可能既耗时又容易出错。
 High_level_workflow_of_LLM_Eval_2508a00777.png
High_level_workflow_of_LLM_Eval_2508a00777.png
图 1:LLM-Eval 的高级工作流程。
LLM-Eval 旨在解决这些问题,并在 LLM 本身的帮助下提供一个简单的评估过程。通过 LLM-Eval,我们可以使用几种不同的指标获得 LLM 响应质量的评估结果,因此文章标题中使用了 "多维"。论文中 LLM-Eval 评估的核心指标包括内容、语法、相关性和适当性。
- 内容:这个指标衡量提供的信息的准确性、响应的完整性、展示的知识深度以及思想的连贯性和逻辑流程。
- 语法:这个指标衡量句子结构、时态的正确使用、主谓一致性、标点符号的适当使用以及拼写的一致性。
- 相关性:这个指标衡量响应与给定上下文或查询的对齐程度,即它是否保持话题、解决查询中提出的具体问题,并提供与请求的细节水平相匹配的响应。
- 适当性:这个指标衡量响应在各个方面的适宜性,如语言的语气和正式程度、文化敏感性和意识。
除了上述四个核心指标外,LLM-Eval 还可以用来评估特定数据集的指标。例如,ConvAI2 数据集评估响应的相关性和参与度。在这种情况下,我们可以调整 LLM-Eval 的提示来评估 ConvAI2 数据集上的这两个指标。我们将在下一节中看到用于评估指标的 LLM-Eval 的详细提示。
现在我们知道了使用 LLM-Eval 可以评估的指标,让我们讨论它实际上是如何工作的。
LLM-Eval 如何工作
如前一节简要提到的,LLM-Eval 使用 LLM 本身来评估其响应质量。这意味着我们为 LLM 提供一个预定义的提示,其中包含它需要的一切,以便为我们提供其响应质量的评估结果。
LLM-Eval 使用单个提示来获得我们想要调查的指标的最终得分。提示由几个组成部分构成,如模式、上下文、人类参考文本和 LLM 生成的文本响应。
模式是用自然语言编写的指令,定义任务和评估标准。在这里,您可以指定您希望 LLM 评估的任何指标。此外,您还可以定义评估分数的范围。LLM-Eval 使用两种不同的评估分数范围:0 到 5 和 0 到 100。以下是 LLM-Eval 用于评估四个指标(适当性、内容、语法和相关性)的模式模板:
Human: The output should be formatted as a
JSON instance that conforms to the JSON
schema below.
As an example, for the schema {"properties":
{"foo": {"title": "Foo", "description": "a
list of strings", "type": "array", "items":
{"type": "string"}}}, "required": ["foo"]}}
the object {"foo": ["bar", "baz"]} is a
well-formatted instance of the schema.
The object {"properties": {"foo": ["bar",
"baz"]}} is not well-formatted.
Here is the output schema:
{"properties": {"content": {"title":
"Content", "description": "content score
in the range of 0 to 5", "type":
"integer"}, "grammar": {"title": "Grammar",
"description": "grammar score in the range
of 0 to 5", "type": "integer"}, "relevance":
{"title": "Relevance", "description":
"relevance score in the range of 0 to 100",
"type": "integer"}, "appropriateness":
{"title": "Appropriateness", "description":
"appropriateness score in the range of 0 to
5", "type": "integer"}}, "required":
["content", "grammar", "relevance",
"appropriateness"]}
一旦我们有了上述定义的模式,我们可以构建其他提示组件:上下文、参考和响应。
- 上下文:包含先前的聊天对话,LLM 可以用来生成响应。
- 参考:包含由人类创建的上下文中的首选响应。
- 响应:包含 LLM 对上下文的响应。
如果数据集包含人类参考,完整的提示将如下所示:
{evaluation_schema}
Score the following dialogue response
generated on a continuous scale from
{score_min} to {score_max}.
Context: {context}
Reference: {reference}
Dialogue response: {response}
与此同时,对于没有人类参考的数据集,完整的提示将只包含上下文和 LLM 的响应,如下所示:
{evaluation_schema}
Score the following dialogue response
generated on a continuous scale from
{score_min} to {score_max}.
Context: {context}
Dialogue response: {response}
上述两个提示只考虑了 LLM 的单个响应。如果我们想在整个对话中评估 LLM 的响应质量,那么 LLM-Eval 使用以下提示:
{evaluation_schema}
Score the following dialogue generated
on a continuous scale from {score_min}
to {score_max}.
Dialogue: {dialog}
一旦我们创建了类似上述模板的提示,唯一剩下的就是将这个提示输入我们选择的 LLM(如 Llama、GPT、Claude、Mistral 等)。然后 LLM 将根据定义的模式为每个指标打分。
LLM-Eval 演示
在本节中,我们将实现 LLM-Eval 以评估 LLM 对用户查询的响应质量。虽然有众多 LLM 可供选择,但我们将使用 Meta 的 Llama 3.1,因为它是一个开源模型,可以免费使用。Llama 3.1 有三个变体:8B、70B 和 405B 参数,但我们将使用 8B 版本以确保我们可以在本地机器上加载它。
要加载 Llama 3.1 8B,我们将使用 Ollama,这是一个工具,使我们能够在自己的本地机器上使用 LLM。有关安装说明,请参考 Ollama 的最新安装页面。
安装 Ollama 后,您可以使用单个命令拉取任何所需的 LLM。要拉取 Llama 3.1,请使用此命令:
ollama pull llama3.1
在我们使用 Llama 3.1 8B 模型之前,我们需要调整其参数。
LLM-Eval 实现的一个重要方面是贪婪解码。这意味着参数设置使得 LLM 始终选择概率最高的令牌作为下一个令牌。为了模仿这种贪婪解码行为,我们需要调整以下参数:
- 温度:此参数的值范围在 0 到 1 之间,控制 LLM 在生成响应时的创造力。值越高意味着我们的 LLM 在生成响应时将更具创造力。如果我们将值设置为 0,我们就会迫使我们的 LLM 输出一个确定性结果。
- Top p:此参数从概率最高的令牌集合中采样,使得概率之和高于 p。它的值范围在 0 到 1 之间。较低的值专注于最可能的令牌,而较高的值则采样更多低概率令牌。我们将此参数设置为 0。
- Top k:此参数从最好的 k(数量)令牌中采样。值的范围可以从 1 到 LLM 词汇表中的总令牌数。我们将此参数设置为 1,因为我们希望我们的 LLM 选择概率最高的令牌。
要将这些参数设置为期望的值,我们首先必须创建一个 Modelfile。以下是 Modelfile 的样子:
FROM llama3.1
# sets the temperature
PARAMETER temperature 0
# sets top k
PARAMETER top_k 1
# sets top p
PARAMETER top_p 0
接下来,我们可以使用这个 Modelfile 通过执行此命令来调整我们的 Llama3.1 的参数:
ollama create <name_of_your_choice> -f ./Modelfile
ollama run <name_of_your_choice>
有关 Modelfile 的更详细解释,请参考此文档。
现在我们可以构建我们的提示,并使用这个模型进行指标评估。我们将使用前一节中提供的模板作为我们的模式,并使用 TopicalChat 数据集中的示例作为演示。TopicalChat 数据集是用于比较 LLM-Eval 与其他评估方法性能的几个基准数据集之一。您可以从这个网站下载 TopicalChat 数据集。
通常,TopicalChat 数据集中的一个示例包括上下文、响应、参考和注释。注释指的是人类注释的适当性、内容、语法和相关性的分数。
以下是我们将用于为适当性、内容、语法和相关性生成分数的提示模板,以及响应:
import ollama
prompt = """The output should be formatted as a
JSON instance that conforms to the JSON
schema below.
As an example, for the schema {"properties":
{"foo": {"title": "Foo", "description": "a
list of strings", "type": "array", "items":
{"type": "string"}}}, "required": ["foo"]}}
the object {"foo": ["bar", "baz"]} is a
well-formatted instance of the schema.
The object {"properties": {"foo": ["bar",
"baz"]}} is not well-formatted.
Here is the output schema:
{"properties": {"content": {"title":
"Content", "description": "content score
in the range of 0 to 5", "type":
"integer"}, "grammar": {"title": "Grammar",
"description": "grammar score in the range
of 0 to 5", "type": "integer"}, "relevance":
{"title": "Relevance", "description":
"relevance score in the range of 0 to 5",
"type": "integer"}, "appropriateness":
{"title": "Appropriateness", "description":
"appropriateness score in the range of 0 to
5", "type": "integer"}}, "required":
["content", "grammar", "relevance",
"appropriateness"]}
Score the following dialogue response
generated on a continuous scale from
0 to 5.
Context: "Hello! Do you like Football?nI do. Do you?nOf course! What's your favorite team. Mine is the New England Patriots, the Lannisters of the NFL!”
Reference: "I like the Broncos. Have you read the Indentured by Ben Strauss and Joe Nocera?”
Dialogue response: "I love the New England Patriots. They are the best team in the NFL!”"""
stream = ollama.chat(
model='llama3.1',
messages=[{'role': 'user', 'content': prompt}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
"""
Output:
"content": 2,
"grammar": 4,
"relevance": 1,
"appropriateness": 3
Here's a breakdown of the scores:
* Content: 2 (The response is relevant to the topic, but doesn't provide much new or interesting information.)
* Grammar: 4 (The grammar and spelling are mostly correct, with only minor issues such as using an exclamation mark instead of a question mark.)
* Relevance: 1 (The response is somewhat off-topic, as it starts talking about a different team and book.)
* Appropriateness: 3 (The tone of the response is enthusiastic and friendly, but also slightly sarcastic. It's not entirely suitable for all audiences.)
"""
我们将在下一节中看到基准数据集上的结果。
正如您所看到的,我们的 LLM 将为我们模式中指定的每个指标输出分数。然而,重要的是要注意,在上述演示中,我们使用的是已经被量化为 4 位的 8B 模型。因此,与原始模型相比,我们失去了一些性能,上述结果不太可靠。原始的 LLM-Eval 实现使用了像 OpenAI 的 ChatGPT 和 Anthropic 的 Claude 这样的专有、更强大的 LLM 来生成这些分数。我们将在下一节中看到原始 LLM-Eval 在基准数据集上的结果。
LLM-Eval 结果和性能
为了衡量 LLM-Eval 的有效性,这种方法已经过评估并与其他几种 LLM 评估方法进行了比较,例如:
- Deep-AM-FM:利用 BERT 嵌入来通过计算充分性指标(AM)和流畅性指标(FM)来衡量对话的质量。AM 衡量源文本在生成文本中保留的意义,而 FM 衡量输出文本的自然程度、流畅性和语法正确性。
- MME-CRS:从五个指标衡量响应质量:流畅性、相关性、参与度、特异性和连贯性。
- BERTScore:通过匹配人类参考和生成响应中的 BERT 令牌嵌入来衡量对话质量的 F1 分数。
- GPTScore:使用 GPT 模型评估生成的响应,通常在人类评分的示例上训练以符合人类判断。
除了上述四种方法外,LLM-Eval 的性能还与 DSTC10 Team 1、DEB、USR、USL-H、DynaEval、FlowScore 等方法以及 BLEU 和 ROUGE 等传统指标进行了比较。
LLM-Eval 在几个基准数据集上,无论是否有人类参考文本,都显示出与上述指标相比非常有竞争力的结果。下表显示了 LLM-Eval 在 TopicalChat 和 PersonaChat 等数据集上与其他方法相比的表现,评估指标包括适当性、内容、语法和相关性:
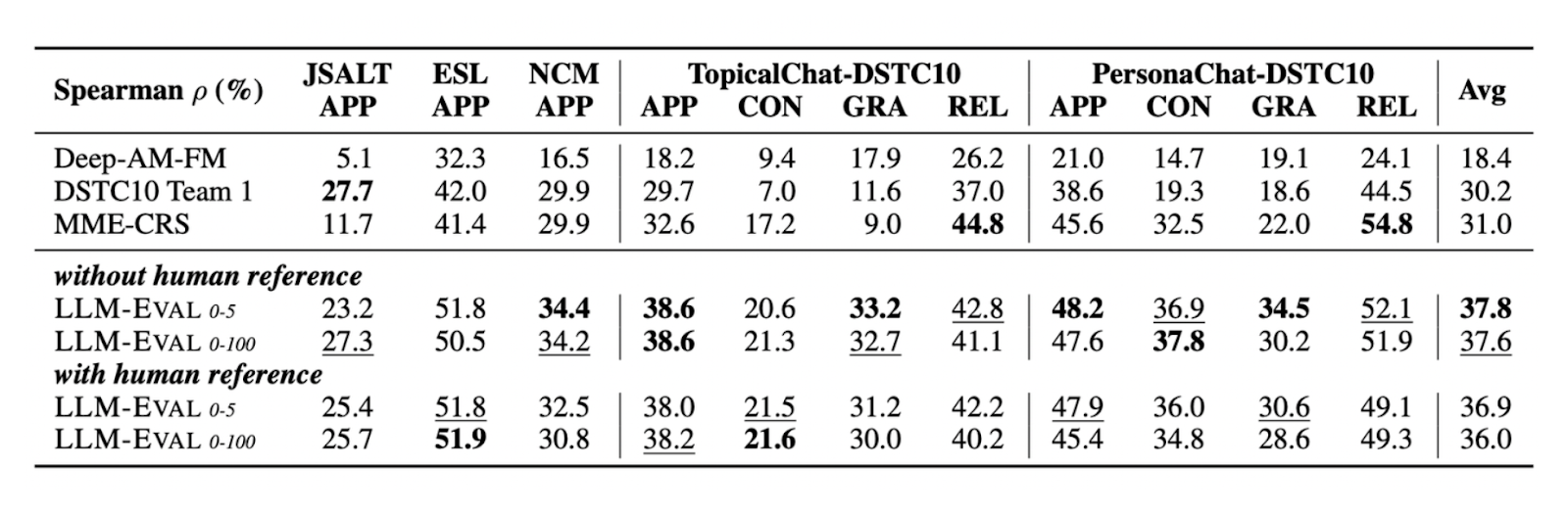 Comparison_of_LLM_Eval_s_performance_with_other_evaluation_methods_on_four_different_metrics_fa0712261c.png
Comparison_of_LLM_Eval_s_performance_with_other_evaluation_methods_on_four_different_metrics_fa0712261c.png
图 2:LLM-Eval 在四个不同指标上与其他评估方法的性能比较。
正如您所看到的,LLM-Eval 的结果在所有数据集上与人类注释分数的皮尔逊相关性最高,与其他评估方法相比。
除了评估这四个指标外,LLM-Eval 还可以评估特定数据集的指标。例如,ConvAI2 数据集评估响应的相关性和参与度,DailyDialog 评估日常对话上下文中的响应质量,EmpatheticDialogue 调查响应的同理心水平。下表显示了 LLM-Eval 在这些数据集上与其他方法的比较:
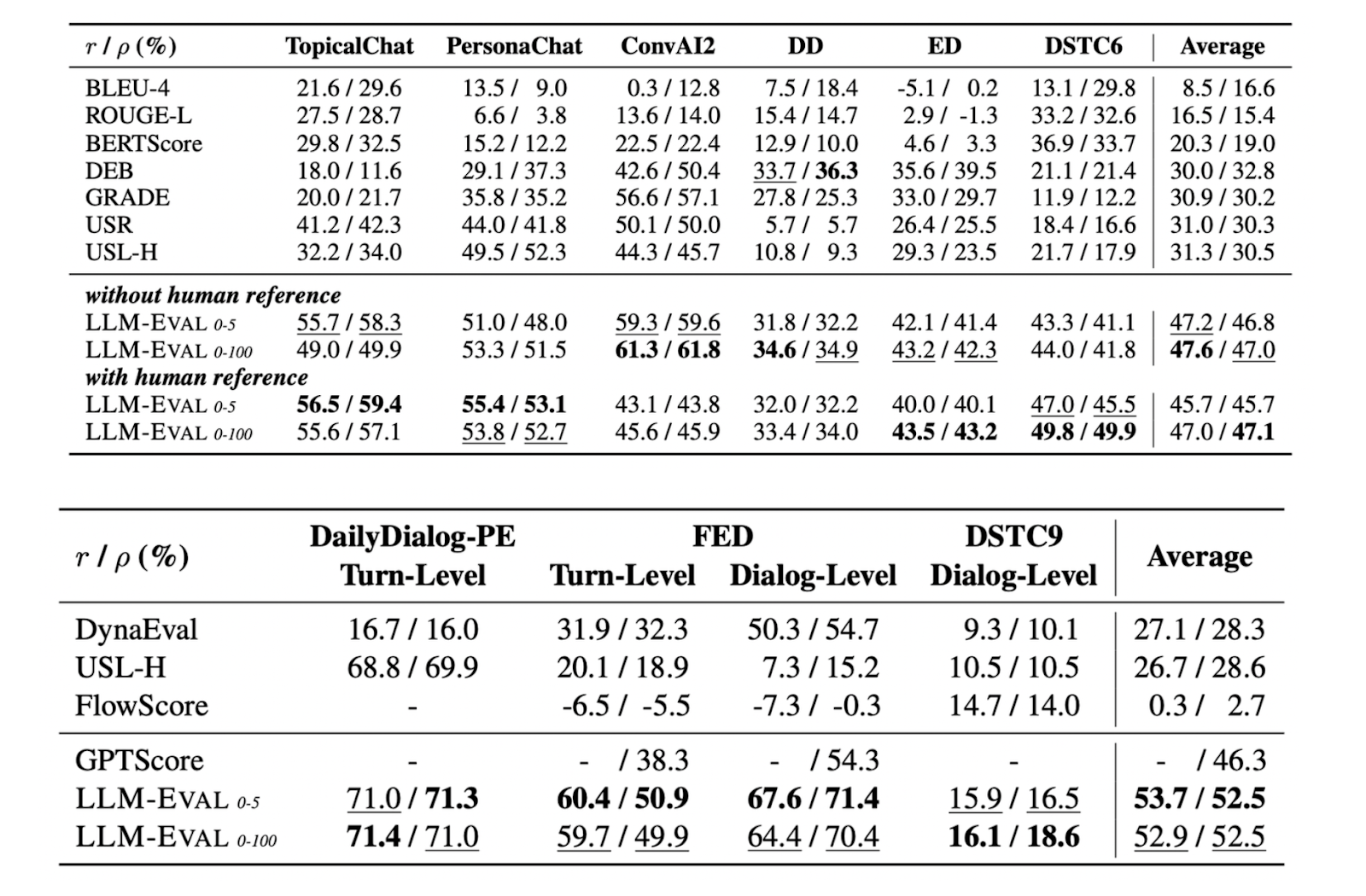 Comparison_of_LLM_Eval_s_performance_with_other_evaluation_methods_on_several_benchmark_datasets_4a038a501f.png
Comparison_of_LLM_Eval_s_performance_with_other_evaluation_methods_on_several_benchmark_datasets_4a038a501f.png
图 3:LLM-Eval 在几个基准数据集上与其他评估方法的性能比较。
再次,表格显示,LLM-Eval 在所有基准数据集上的斯皮尔曼和皮尔逊相关性方面优于其他评估方法。
无论我们使用 0 到 5 还是 0 到 100 的评分范围,或者无论数据集是否有人类参考,LLM-Eval 在所有数据集上的表现始终优于其他方法。这表明 LLM-Eval 非常适用于评估开放领域对话。
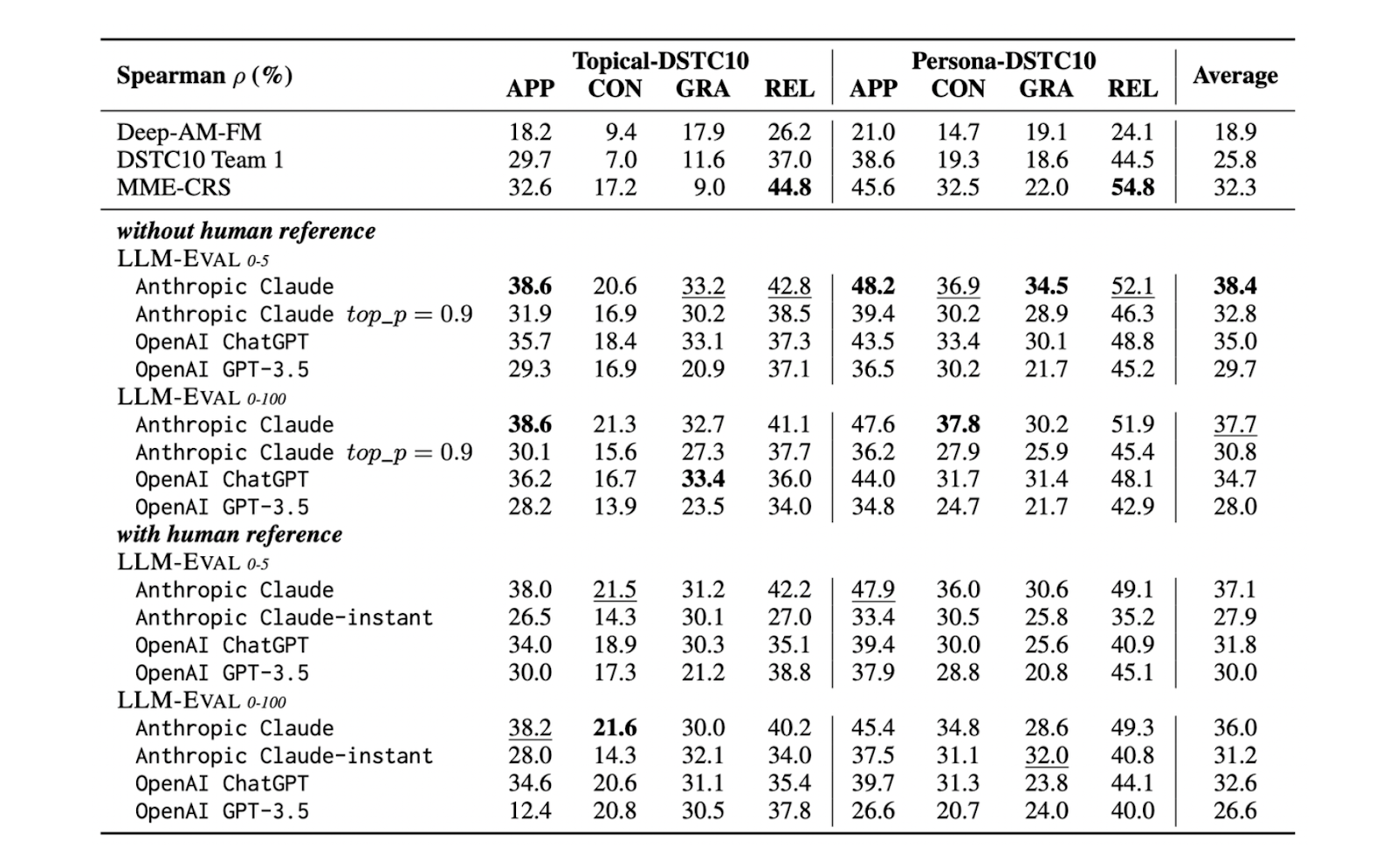 LLM_Eval_s_performance_on_benchmark_datasets_using_different_LL_Ms_b52d5579ed.png
LLM_Eval_s_performance_on_benchmark_datasets_using_different_LL_Ms_b52d5579ed.png
图 4:LLM-Eval 在使用不同 LLM 的基准数据集上的性能。
LLM-Eval 可以与任何 LLM 实现。然而,正如您从上表中看到的,当使用为聊天优化的 LLM 时,其性能在所有指标上最佳,即 ChatGPT 的表现优于基础 GPT 模型。此外,表格还显示,Claude 通常略优于 ChatGPT,表明我们选择的 LLM 将影响 LLM-Eval 的整体性能。
结论
在本文中,我们讨论了 LLM-Eval,这是一种用于评估 LLM 响应质量的多功能方法。LLM-Eval 的实用性在于其单提示评估过程,这减少了在评估 LLM 性能时对人工注释的依赖。
我们可以选择任何 LLM 来执行 LLM-Eval。然而,正如本文所示,LLM 的选择将直接影响整体评估质量。因此,最好使用为聊天优化的性能良好的 LLM,以实现不同指标的高质量评估。
注:本文为AI翻译,查看原文
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer


