20个流行的自然语言处理开放数据集
引言
自然语言处理(NLP)是机器学习的一个领域,其中的模型学习理解并从人类语言中提取意义。NLP将文本和语音等非结构化数据转化为可用于分类任务、摘要、机器翻译、情感分析等其他应用的结构化格式。
训练模型执行这些任务需要大量数据。您希望您的模型越能干,它就需要越多的数据。幸运的是,像Hugging Face、Kaggle、GitHub和Papers with Code这样的库提供了大量可供公众使用的多样化数据集。
在本文中,我们编译了20个最受欢迎的NLP数据集,分为通用NLP任务、情感分析、基于文本的任务和语音识别四大类别。我们还探讨了为您的项目选择理想数据集的关键标准。
选择NLP数据集的标准
在选择用于训练或微调模型的NLP数据集时,请考虑项目的具体目标、数据集的质量和大小、数据的多样性以及数据的易访问性和易用性。
目的
最关键的因素是数据集是否与您项目的目的是一致的。即使数据集质量高、数量大、多样化,如果与您的任务或领域无关,它也不会有用。例如,如果您正在构建一个针对电影评论的情感分析模型,那么一个IMDb电影评论的数据集比一个更大但不相关的数据集(如《纽约时报》的新闻文章)要有效得多。确保数据集适合您的特定目的是有效训练模型的必要条件。
数据质量
数据集的质量也至关重要,因为它直接影响模型的性能。质量差的数据可能导致预测不准确、输出不可靠,甚至可能产生误导性结果。例如,在充满拼写错误、语法错误和不一致标记的数据集上训练模型可能会导致模型复制这些错误。这可能导致文本生成任务中的“幻觉”,即模型自信地输出错误信息。因此,选择经过精心筛选以去除不准确、偏见和冗余的数据集,确保数据干净可靠,对于训练您的模型至关重要。
数据集大小
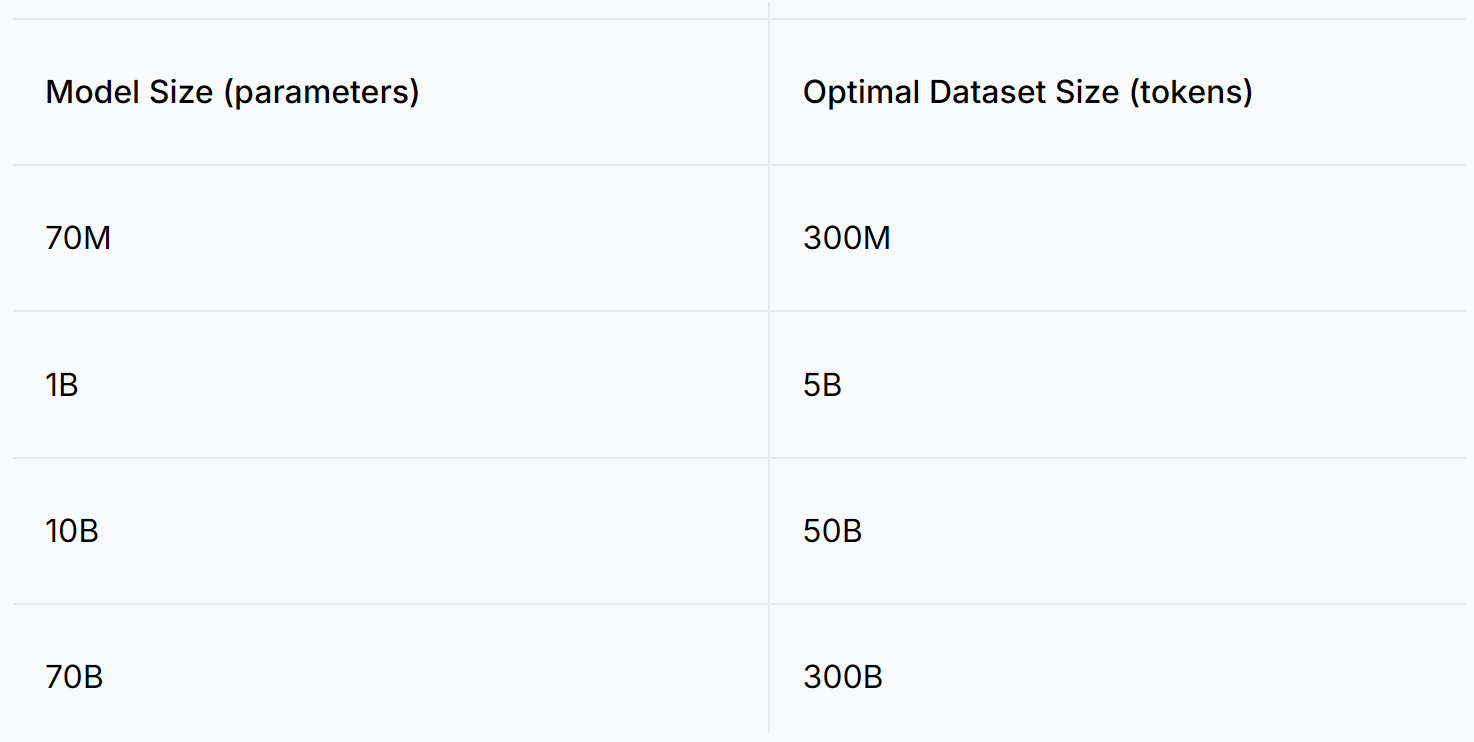
为了让模型有效地学习语言和语义关系,您需要大量的数据。通常,您的模型参数越多,它需要的数据集就越大。 研究论文《Training Compute-Optimal Large Language Models》由Hoffman等人(2022年)介绍了Chinchilla缩放法则,提出了训练模型的最佳参数与令牌比例约为0.2。例如,一个具有10亿参数的模型可能需要大约50亿令牌的数据集才能获得最佳性能。另一方面,如果它们准确代表目标任务的语言特征和领域,较小的数据集就足以微调情感分析模型。例如,一个具有1亿参数的情感分析模型可能只需要1000万个高质量的数据点。
下图展示了各种模型大小及其对应的最佳数据集大小的例子,由Chinchilla缩放法则确定:
 屏幕截图 2024-11-11 173420.png
屏幕截图 2024-11-11 173420.png
表:各种模型大小及其对应的最佳数据集大小的例子
多样性
多样化的数据集对于创建一个能够处理广泛任务并具有更高准确性的全面模型至关重要。正如多样化的经历丰富了一个人的个性,多样化的数据使NLP模型能够在不同的上下文中表现更好。例如,如果您正在训练一个语言翻译模型,仅依赖正式学术文本的数据集将限制模型翻译口语对话或俚语的能力。然而,通过整合各种语言的散文、学术写作、访谈和编码样本的混合,模型将更好地准备处理不同的语言环境并产生更准确的翻译。
可访问性
可访问性指的是您能够多容易地获得项目所需的数据。获得所需数据越容易,您的训练过程就越高效。像Hugging Face、Kaggle和Papers with Code这样的平台上可用的开放数据集通常是许多研究人员的首选,因为它们易于访问且文档齐全。
 Hugging_Face_has_a_huge_collection_of_easily_accessible_Open_Datasets_for_NLP_a29b14b945.png
Hugging_Face_has_a_huge_collection_of_easily_accessible_Open_Datasets_for_NLP_a29b14b945.png
HuggingFace拥有大量易于访问的NLP开放数据集
例如,从Hugging Face下载像Project Gutenberg这样的数据集是直接的——只需安装datasets库并使用load_dataset函数。这种级别的可访问性加速了开发过程,确保您拥有正确的数据来有效地训练您的模型。
pip install datasets
from datasets import load_dataset
training_dataset = load_dataset("manu/project_gutenberg")
20个流行的NLP开放数据集
在介绍了为您的NLP项目选择正确数据集的关键标准后,让我们探索20个最受欢迎的数据集。这些数据集分为四大类别:通用NLP任务、情感分析、基于文本的任务和语音识别。
通用NLP项目
对于通用NLP任务,数据集需要广泛且多样化,捕捉语言的复杂性和细微差别。这确保了模型能够在不同的语言环境中很好地泛化。
- 博客作者身份语料库:由Blogger.com上的19,000名作者撰写的近70万个帖子组成的数据集,总计1.4亿英文单词。这个数据集对于风格和作者身份分析很有价值,但要考虑与个人博客相关的隐私和伦理问题。
- 推荐系统和个性化数据集:这个集合包括来自亚马逊、谷歌、Twitch和Reddit等来源的大型数据集,包含用户互动、评论和各种格式的评级。这些数据集提供了多样化的来源,但可能需要聚合和预处理。
- 古腾堡计划:一个庞大的公共领域书籍集合,包含超过50,000本不同语言的书籍,为不同时期的语言建模提供了丰富的资源。数据集包括纯文本和HTML格式的文本。
- Yelp开放数据集:包括近7百万条针对超过15万家企业的评论,以及用户提示和企业属性等数据。虽然广泛,但其重点是商业评论,可能不包括除评论之外的更广泛的通用NLP任务。在这里访问数据集。
- SQuAD(斯坦福问答数据集):一个用于问答(QA)任务的大规模数据集,包含超过10万个问答对,其中答案是一个从相应段落中提取的文本片段。它已成为QA模型的标准基准,并包括引入无答案问题的SQuAD 2.0。在这里访问数据集。
情感分析
情感分析是一种NLP技术,用于识别和分类文本中表达的情感。主要目标是确定文本是否传达了积极、消极、中立或混合的情感。这项技术对于理解文本数据中的意见、情感和措辞的细微差别至关重要。
情感分析数据集对于捕捉意见、情感和措辞的细微差别至关重要。它们应包括多样化的标签和评级系统,帮助模型学习情感以不同方式表达。
- Sentiment 140:一个包含160万条推文的数据集,清除了表情符号,并按0(消极)到4(积极)的等级进行标记。包括极性、日期、用户和文本等字段。请注意,数据集可能反映Twitter数据中的偏见,如俚语和非正式语言。
- 多领域情感分析数据集:包含亚马逊不同类别的产品评论,星级评级可以转换为二元标签。确保数据集按比例涵盖类别,并与您的特定用例相关。
- SentimentDictionaries:两个字典,包含超过80,000个条目,专为情感分析量身定制,一个来自IMDb电影评论,另一个来自美国8-K文件。它们可能需要额外处理以用于特定应用。
- OpinRank数据集:包含来自Edmunds和TripAdvisor的30万辆汽车和酒店评论的数据集,按汽车型号或旅行目的地组织。确保它包括最近的评论,并考虑评论的真实性。
- 斯坦福情感树库:包含来自烂番茄评论的10,000多条条目的情感注释,按1(最消极)到25(最积极)的等级评定。数据集包括不同粒度级别的注释。
基于文本的任务
基于文本的NLP任务需要既大又多样化的数据集,支持机器翻译、文本摘要、文本分类、命名实体识别(NER)和问答(QA)等用例。
- 20新闻组:一个包含20个不同新闻组的20,000份文件的集合,通常用于文本分类和聚类任务。提供三个版本:原始、无重复项和去除日期。请注意,可能需要自定义预处理。
- 微软研究WikiQA语料库:适用于QA任务,包含来自Bing查询日志的3,000个问题和29,000个答案。确保数据集的质量和与您的特定QA模型的相关性。
- Jeopardy:一个包含来自电视节目“Jeopardy!”的20万个问题的的数据集,涵盖1964年至2012年的剧集。注意问题的性质和电视节目的背景可能带来的潜在偏见。
- 法律案例报告数据集:包括4,000多个澳大利亚法律案例的摘要,是训练模型进行文本摘要的优秀资源。确保它涵盖多样化的案例类型和管辖区。
- WordNet:一个大型英语词汇数据库,名词、动词、形容词和副词被归类为认知同义词或“同义词集”,并通过概念语义和词汇关系链接。它是词汇语义的优秀资源,并可以与各种NLP任务集成。
语音识别
语音识别数据集必须高质量,以捕捉口头交流的复杂性,包括最小化背景噪音并确保高信号质量。说话者、口音和上下文的多样性对于训练强大且适应各种现实世界场景的模型至关重要。
- Spoken Wikipedia语料库:一个由英语、德语和荷兰语叙述的维基百科文章的集合,每种语言都有数百小时的对齐音频。强调语言范围和数据集质量或覆盖范围的任何限制。
- LJ语音数据集:包含来自有声书的13,100个剪辑的人类验证转录,以单一说话者为特色,以清晰明了。注意单一说话者的限制及其对泛化到其他声音的影响。
- M-AI Labs语音数据集:来自LibriVox和古腾堡计划的近1,000小时音频和转录,按性别和语言组织。确保它包括多样化的说话者和上下文。
- Noisy Speech数据库:一个包含干净和嘈杂语音的并行数据集,适用于构建语音增强和文本到语音模型。提及包括的噪音类型及其对数据集实用性的影响。
- TIMIT:由德州仪器和麻省理工学院创建的声学-语音数据库,包含630名说话者阅读八种美国英语方言的语音丰富句子。指出随着语音技术的进步,它是否仍然相关。
想要进一步探索NLP和可用于开发深度学习模型的广泛数据集,请查看以下资源:
其他NLP数据来源
虽然公开可用的数据集对于机器学习开发和研究来说是非常宝贵的,但还有其他方法可以获得可能更适合特定需求或提供独特优势的NLP训练数据:
私有数据集
私有数据集是个人策划的数据集合,通常是在内部创建或从专业数据集提供商处购买。这些数据集是根据特定需求量身定制的,通常具有高质量,并仔细关注相关性、准确性和偏见。然而,获取私有数据集可能成本高昂,可能需要大量资源用于数据收集和管理。它们对于需要特定领域数据的项目或处理专有应用程序时特别有用。
直接从互联网获取
直接从网站上抓取数据是收集NLP数据的另一种方法。这种方法允许快速收集大量数据。然而,它也带来了重大挑战:抓取的数据通常是非结构化的,可能包含不准确或偏见,可能包括敏感或机密信息。此外,从网站上抓取数据可能会引发法律和道德问题,特别是如果数据受版权保护或没有获得适当的许可。
通过探索这些额外的来源,您可以补充公开可用的数据集,并可能找到更符合项目需求的数据。
总结
选择正确的数据集对于开发有效的NLP模型至关重要。考虑数据集与项目目的的相关性、质量、大小、多样性和可访问性,以确保最佳性能。本文涵盖了各种NLP任务的20个流行开放数据集,提供了它们特定应用和好处的见解。
除了公开可用的数据集外,私有数据集和网络抓取提供了替代数据来源。虽然私有数据集可以提供高质量、特定领域的数据,但它们可能很昂贵。从网络上抓取数据允许大规模收集,但伴随着数据质量问题和法律问题。
 Tim Mugabi
Tim MugabiFreelance Technical Writer