



基于指标开发的RAGs
在最近一次Zilliz非结构化数据 meetup的演讲中,Ragas的维护者Jithin James和Shahul Es分享了如何利用基于指标的开发来评估检索增强生成(RAG)系统的见解。开发者可以根据评估结果调整他们的系统以获得更好的性能。
在他们的演讲中,Jithin和Shahul讨论了RAG系统评估的理论基础和实际应用。他们解释了理解评估代码背后的理论可以提供对其功能的更深入的见解。在此之后,他们使用由Milvus驱动的实际RAG系统演示了评估过程,Milvus是一个领先的开源向量数据库,以其在相似性搜索和AI应用中的效率而闻名。
如何评估RAG系统的性能
Shahul谈到了Ragas如何计算RAG系统生成的答案的真实性。这是一个关键的评估指标,因为答案是最终用户所看到的。让我们放慢一点,深入研究。Ragas使用以下公式计算答案的真实性:
 Fig_1_Ragas_answer_truthfulness_metric_computation_formula_d691ad34df.png
Fig_1_Ragas_answer_truthfulness_metric_computation_formula_d691ad34df.png
图1 - Ragas答案真实性指标计算公式
在检索增强生成(RAG)系统中计算答案正确性
这个过程涉及两个主要指标:事实相似性和语义相似性。这些指标有助于确定生成的答案与真实情况相比的质量和相关性。
关键指标
- 事实相似性:这个指标通过比较真实情况和生成答案中的事实信息的存在来衡量生成答案的事实正确性。
- 语义相似性:这个指标衡量生成的答案与真实情况在语义上的相似性,确保生成的答案所传达的含义与真实情况一致。
计算答案正确性的步骤
- 识别真阳性(TP)、假阳性(FP)和假阴性(FN):
- 真阳性:在真实情况和生成答案中都正确出现的陈述。
- 假阳性:在生成答案中出现但不在真实情况中的陈述。
- 假阴性:在真实情况中出现但不在生成答案中的陈述。
- 计算F1分数:
- F1分数是精确度和召回率的平均值,两者之间取得平衡。F1分数的公式在图1中显示。
实际示例
考虑一个真实情况陈述和一个生成的答案:
- 真实情况:“艾伦·图灵开发了图灵机的概念。”
- 生成答案:“艾伦·图灵以开发图灵机和人工智能的概念而闻名。”
步骤1:识别TP、FP和FN
- 真阳性(TP):“艾伦·图灵开发了图灵机的概念。”
- 假阳性(FP):“艾伦·图灵以开发人工智能而闻名。”
- 假阴性(FN):无(因为生成的答案包含了真实情况的所有元素)。
步骤2:计算F1分数
- TP = 1
- FP = 1
- FN = 0 F1 = 1 / (1 + 0.5 * (1 + 0)) = 1 / 1.5 ≈ 0.67
解释
- 事实相似性:生成的答案在事实上是正确的,因为它包含了来自真实情况的基本信息。
- 语义相似性:生成的答案与真实情况保持语义一致,尽管它包含了额外的信息。
F1分数结合了这些方面,提供了衡量答案正确性的方法,平衡了精确度和召回率。这种方法有助于评估生成的答案在事实内容和整体含义方面与真实情况的匹配程度。
但是,答案真实性并不是您可以用来评估您的RAG系统的唯一指标。其他指标包括忠实度、答案相关性、上下文召回率和上下文精确度。让我们实际看看如何评估和改进由Milvus驱动的RAG系统。
评估和改进Milvus驱动的RAG系统
现在您已经了解了评估RAG系统的理论基础,让我们深入一个由Milvus向量数据库构建的实际RAG示例。我们将逐步进行设置、实施和评估RAG系统。根据结果,我们将查看如何改进系统。
设置环境
首先,我们需要设置我们的开发环境。首先,安装所有必需的库:
!pip install pymilvus[model] ragas langchain langchain_openai python-dotenv nest_asyncio pypdf langchain_community
让我们分解代码中每个库的用途:
- Pymilvus[model]将帮助您连接到Milvus,创建集合,插入数据和执行相似性搜索。
- Ragas将提供评估指标,生成合成测试集,并评估RAG管道。
- Langchain将加载文档,将它们分割成块,并为嵌入和查询准备文本数据。
- Langchain_openai将与OpenAI模型接口,生成嵌入,并使用API调用来回答问题。
- Python-dotenv将从.env文件中加载环境变量,以管理敏感信息,如API密钥。
- Nest_asyncio将启用同步环境中的嵌套异步操作。特别是如果您使用Jupiter笔记本。
- Pypdf将加载PDF文档,提取内容,并为处理准备文本。
- Langchain_community将提供额外的文档加载器和实用程序,用于集成社区贡献的资源。安装库后,将它们导入到您的代码中并配置您的API密钥:
import os
import pandas as pd
import nest_asyncio
import openai
from pymilvus import MilvusClient, model
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
answer_correctness,
)
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_community.document_loaders import DirectoryLoader
from langchain.document_loaders import PyPDFLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from dotenv import load_dotenv
from datasets import Dataset
# Load environment variables
# Apply nest_asyncio to allow nested event loops
nest_asyncio.apply()
# Set up OpenAI API key
os.environ["OPENAI_API_KEY"] = "Your API Key"
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
将库和模块导入到代码中将允许您调用和使用它们的函数。OpenAI密钥将帮助您在进行API调用时对OpenAI进行身份验证。如果您没有,请前往OpenAI API页面并生成一个。
加载和准备文档
接下来,我们将加载我们的文档并为处理做准备:
# Load PDF documents from a directory
pdf_loader = DirectoryLoader("/content/data", loader_cls=PyPDFLoader)
documents = pdf_loader.load()
# Ensure each document has a filename in its metadata
for document in documents:
document.metadata['filename'] = document.metadata['source'
代码使用PyPDFLoader类从目录中加载PDF文档。然后创建一个DirectoryLoader实例,加载文档,并遍历每个文档为其元数据添加filename属性。这确保每个文档都被正确识别和管理,并且具有相应的文件名。这一步至关重要,因为它构成了我们RAG系统的知识库。在这个例子中,我们使用的是PDF文档,但您可以根据需要将其适应为其他类型的文档。
生成测试集
现在您已经加载了数据,您需要一组多样化的测试问题来帮助有效地评估我们的RAG系统。我们将使用Ragas框架生成合成测试集。
# Initialize OpenAI models for test set generation
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
# Create a TestsetGenerator
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Generate synthetic test set with 10 samples
testset = generator.generate_with_langchain_docs(documents, test_size=10, distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25})
# Convert test set to Pandas DataFrame
testset_df = testset.to_pandas()
print(testset_df)
此代码初始化两个语言模型(用于生成测试集的gpt-3.5-turbo-16k和用于评估的gpt-4)和OpenAI的嵌入模型。然后使用这些模型创建一个TestsetGenerator实例。生成器从加载的PDF文档中生成了10个样本的合成测试集,并指定了不同类型问题的分布。这个测试集将帮助您评估RAG系统性能的各个方面,包括其处理简单查询、推理任务和需要多个上下文的问题的能力。以下是一个生成的测试集的示例。
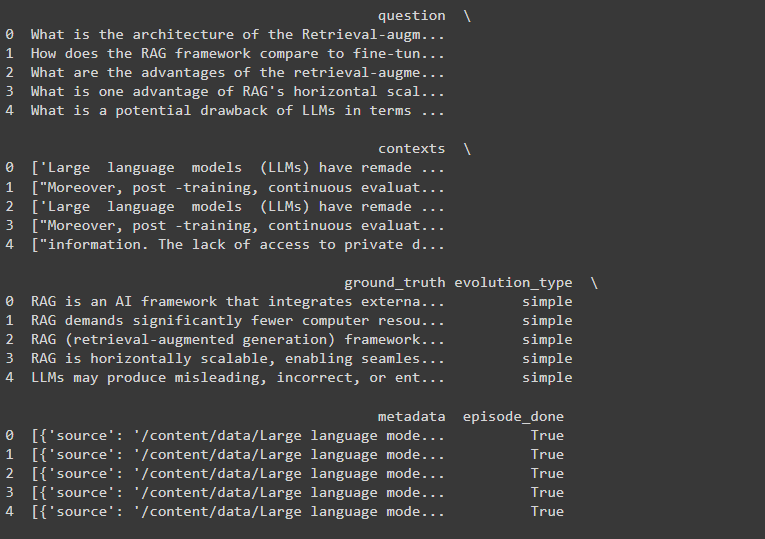 Fig_2_Test_set_generated_using_Ragas_5f358eb210.png
Fig_2_Test_set_generated_using_Ragas_5f358eb210.png
图2 - 使用Ragas生成的测试集
真实情况是给定问题的实际答案。我们稍后将使用它来衡量我们的RAG系统的表现,通过将其输出与这些真实答案的接近程度来衡量。正如Shahul在演讲中所指出的,使用Ragas生成合成测试集并不意味着您要盲目使用它。您必须过滤并使用您需要的样本。
既然您有了测试集,让我们构建一个由Milvus驱动的简单RAG系统,然后使用上述测试集进行评估。
设置Milvus并插入文档嵌入
现在,让我们设置我们的Milvus向量数据库并插入我们的文档嵌入。确保您已安装并运行Milvus。如果没有,请按照Milvus安装综合指南操作。
# Connect to Milvus instance
milvus_client = MilvusClient(uri="http://localhost:19530")
# Define collection name
collection_name = "pdf_collection"
# Drop the collection if it already exists
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
# Create a new collection
milvus_client.create_collection(
collection_name=collection_name,
dimension=768, # Dimension of vectors
overwrite=True
)
# Initialize the embedding function
embedding_fn = model.DefaultEmbeddingFunction()
# Extract document texts and generate embeddings
expanded_docs = [doc.page_content for doc in documents]
expanded_vectors = embedding_fn.encode_documents(expanded_docs)
# Prepare data for insertion
expanded_data = [
{"id": i, "vector": expanded_vectors[i], "text": expanded_docs[i], "subject": "pdf_documents"}
for i in range(len(expanded_vectors))
]
# Insert expanded data into the collection
milvus_client.insert(data=expanded_data, collection_name=collection_name)
上述代码连接到Milvus实例并设置一个名为pdf_collection的集合,用于存储文档向量。如果集合已经存在,它会删除并重新创建一个维度为768的向量集合。它初始化一个嵌入函数,从加载的文档中提取文本,并生成它们的嵌入。然后代码准备带有嵌入和相关文本的数据,并将其插入到Milvus集合中。这一步是Milvus真正闪耀的地方,因为它允许您对存储的数据嵌入执行快速高效的相似性搜索,这对于RAG系统的检索部分至关重要。
执行相似性搜索
有了在Milvus中索引的文档,您现在可以执行相似性搜索以检索我们问题的相关上下文:
# Define the search parameters
search_params = {"metric_type": "COSINE", "params": {"nprobe": 20}} # nprobe for better recall
# Perform the search
query_vectors = embedding_fn.encode_queries(testset_df['question'].tolist())
results = milvus_client.search(
collection_name=collection_name,
data=query_vectors,
anns_field="vector", # specify the vector field name
search_params=search_params,
limit=3, # number of top results to retrieve
output_fields=["id", "text"]
)
上述代码为Milvus集合设置了搜索参数,使用余弦相似度和nprobe值为20以获得更好的召回率。它将测试集问题编码成查询向量,并在pdf_collection集合中执行搜索,检索每个查询最相似的前三个向量。搜索结果包括匹配文档的ID和文本。
使用大型语言模型生成答案
有了检索到的相关上下文,您现在可以使用语言模型生成答案。在这种情况下,我们将使用GPT 3.5 turbo。
# Function to generate answers using OpenAI
def generate_answer(question, contexts):
context_text = " ".join(contexts)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Context: {context_text}nnQuestion: {question}nAnswer:"}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens=100,
temperature=0.7,
)
return response.choices[0].message.content.strip()
# Extract contexts and generate answers using OpenAI
contexts = []
answers = []
for i, result in enumerate(results):
context = [match['entity']['text'] for match in result]
contexts.append(context)
question = testset_df['question'].iloc[i]
answer = generate_answer(question, context)
answers.append(answer)
代码定义了一个generate_answer函数,该函数使用OpenAI的gpt-3.5-turbo模型根据给定的问题和上下文生成答案。它为API调用准备消息,连接上下文,并查询模型。然后它提取并返回生成的答案。随后的循环遍历搜索结果,并使用generate_answer函数为测试集中的每个问题生成答案,将上下文和答案存储在列表中。循环中用于生成答案的问题与测试集中生成的问题相同。
既然您现在有了RAG系统生成的答案和真实情况答案,让我们评估RAG系统的表现如何。
评估RAG系统
最后,我们将使用前面讨论的指标来评估我们的RAG系统的性能:
# Ensure all lists are the same length
min_length = min(len(testset_df['question']), len(testset_df['ground_truth']), len(answers), len(contexts))
questions = testset_df['question'][:min_length]
ground_truths = testset_df['ground_truth'][:min_length]
answers = answers[:min_length]
contexts = contexts[:min_length]
# Create the dataset with correct column names
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
from datasets import Dataset
# Convert dict to dataset
dataset = Dataset.from_pandas(pd.DataFrame(data))
# Evaluate using RAGAS
metrics = evaluate(
dataset=dataset,
metrics=[
answer_correctness,
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
raise_exceptions=False #handle async issues
)
# Convert result to DataFrame for better readability
result_df = metrics.to_pandas()
print(result_df)
代码通过将所有相关列表裁剪到相同的最小长度,确保评估过程中的一致性。这可以防止长度不匹配,这可能会导致评估期间出现错误。然后它创建一个包含这些裁剪列表的字典,将其转换为Pandas DataFrame,然后将其转换为Hugging Face数据集。这个结构化的数据集允许使用RAGAS框架进行系统评估,该框架比较生成的答案与真实情况。评估指标(答案正确性、上下文精确度、上下文召回率、忠实度和答案相关性)提供了RAG管道性能的评估。
查看以下评估结果:
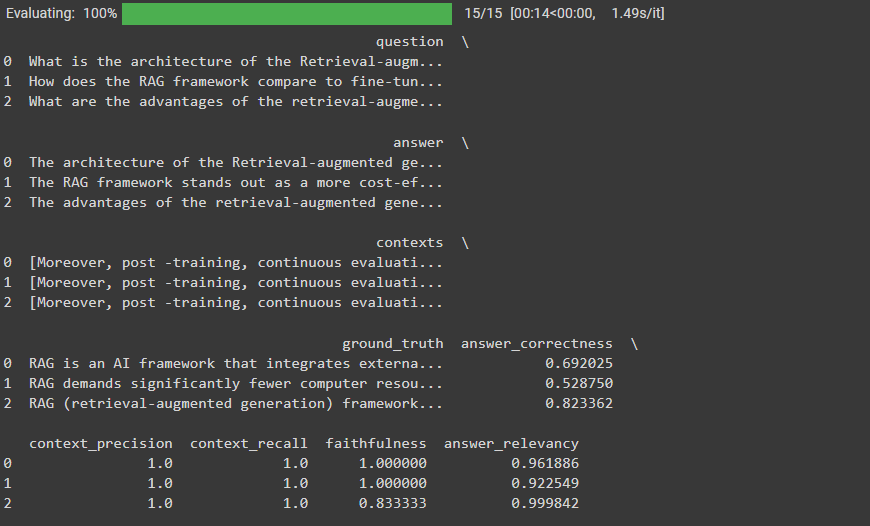 Fig_3_Ragas_RAG_system_evaluation_results_dccebbe289.png
Fig_3_Ragas_RAG_system_evaluation_results_dccebbe289.png
图3 - Ragas RAG系统评估结果
我们的RAG系统的上下文精确度和召回率非常好,答案相关性也值得称赞。但答案正确性相当低。
由于上下文召回率和精确度都很好,我们可以得出结论,生成部分可能影响了我们的答案正确性。要改进这一点,您可以使用更强大的答案生成模型,如GPT-4。
结论
评估和改进检索增强生成(RAG)系统是AI驱动信息检索领域中一个微妙但至关重要的任务。通过利用Jithin James和Shahul Es演示的基于指标的方法,您可以系统地完善您的RAG系统,以确保它们提供准确、相关和可信的信息。
注:本文为AI翻译,查看原文
 Denis Kuria
Denis KuriaFreelance Technical Writer

