套娃嵌入:如何优化向量搜索成本,并兼顾延迟与召回
什么是套娃嵌入?
在构建高效的向量搜索系统时,一个关键挑战是如何在存储成本可控的情况下,同时保持延迟和召回率在可以接受的范围。
通常来说, embedding模型可以生成数百甚至上千维度的向量,使得原始向量和索引在创建过程中产生了显著的存储和计算成本。
对此,我们可以在构建索引之前,通过量化或降维的方法来减少存储需求。例如,我们可以通过使用乘积量化(PQ)降低精度或使用主成分分析(PCA)的方式,来降低维度数量进而节省存储,同时保持向量之间的语义关系。
但以上方法,仅适用于在单一尺度上一次性降低精度或维度。如果我们要保持多尺度细节,构建起一个类似金字塔的层级结构时,我们要怎么办?
套娃嵌入应运而生。
这个方法以俄罗斯套娃命名(见插图),其特点是在单个向量中嵌入了多尺度的表示。
俄罗斯套娃嵌入模型的这一特点允许我们截断模型产生的原始 (长) 嵌入,同时仍保留足够的信息以在下游任务上保持不错的性能。
并且,与传统的后处理方法不同,套娃嵌入在初始训练过程中就学习了这种多尺度结构。它主要通过这种工作方式:模型可以将更重要的信息存储在前面的维度中,将不太重要的信息存储在后面的维度中,而且每个嵌套的子集前缀(前一半、前四分之一等)都是一个性能不错的嵌入,当然长度越长,性能更好。
 640.webp
640.webp
图:具有多层细节的套娃嵌入的可视化
这种方法与传统嵌入形成鲜明对比,后者只能以原始长度进行使用,将其截断使用会导致其完全无法使用。有了套娃嵌入,我们就可以选择对于场景合适的长度,以平衡特定任务的精度和计算成本。
比如需要快速完成相似性搜索,就使用最小的“娃娃”。需要最大精度,就使用完整嵌入。这种灵活性使得它们对于适应不同性能要求或资源限制的系统特别有价值。
推理
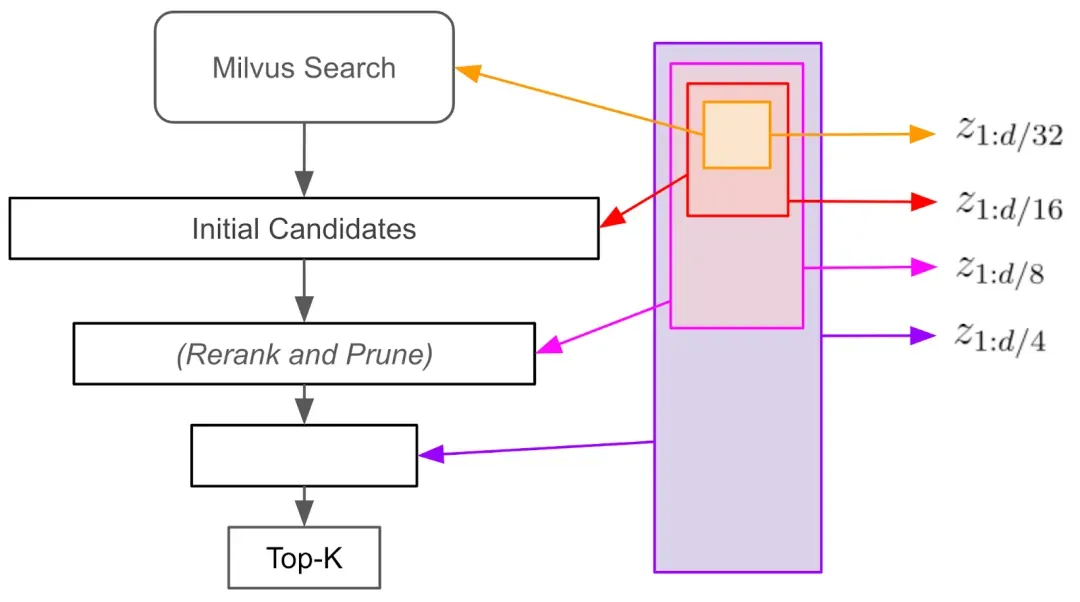
套娃嵌入的一个典型应用场景是在不牺牲召回率的情况下加速相似性检索。通过查询数据库嵌入的较小子集(例如其维度的前1/32),我们可以在这个删繁就简的空间中构建索引,并保留大部分相似性信息。并且,这个较小嵌入空间的初始结果依然是可以直接使用的。
 640 (1).webp
640 (1).webp
图:漏斗搜索如何与套娃嵌入一起工作
此外,关于如何保持准确性的同时加速相似性搜索,我们可以使用“漏斗搜索”方法。首先,我们仅使用嵌入维度的前1/32执行初始相似性搜索,生成广泛的候选项目池。然后,我们使用前1/16个维度根据它们与查询的相似性重新排名这些候选项,进一步缩小候选项目池。这个过程不断重复迭代,我们使用的嵌入维度子集(1/8、1/4等)也随之越来越精细。
这么操作的意义在于,每一次的漏斗过程都缩小了候选范围,比直接在全维空间中搜索更快、更高效,可以显著加速相似性搜索,同时保留强大的召回率。
训练
接下来我们对技术细节进行展开讲述。
其实方法非常简单。我们可以使用微调BERT模型来进行句嵌入(Sentence Embedding)。为了将已在 masked-token 损失上进行预训练的 BERT 模型转换为句子嵌入模型,我们可以将句子嵌入变成最后一层的平均值,即每个 token 上下文化嵌入的平均值。
通常我们可以将句子嵌入的损失函数记作。它输入一对sentence embeddings,,,以及它们期望的相似性得分(公式请参见上面的链接)。现在,为了学习套娃嵌入,我们对训练目标进行了小的修改:
其中,总和是通过计算前一个项输入的一半继续的,直到达到维度下限。作者建议设置
简单来说,套娃损失是原始损失在输入的递归子集上的加权和。
上述方程的一个关键洞见是,套娃损失通过在嵌入模型之间共享权重(同一模型用于编码,例如, 和 )以及在尺度之间共享维度( 是 的子集)来实现多尺度表示的有效学习。
套娃嵌入和Milvus
Milvus可以无缝支持任何可以通过标准库(如pymilvus. model、sentence-transformers或其他类似工具)加载的套娃嵌入模型。从系统的角度来看,常规嵌入模型和专门训练以生成套娃嵌入的模型之间没有功能差异。
流行的套娃嵌入模型包括:
OpenAI的text-embedding-3-large
Nomic的nomic-embed-text v1
有关在Milvus中使用套娃嵌入的完整指南,请参阅blog使用套娃嵌入的漏斗搜索。
总结
套娃嵌入允许开发人员在不牺牲语义完整性的情况下创建更精巧的嵌入,使它们成为更高效搜索和存储的理想选择。您可以修改现有模型,也可以使用预训练选项,例如来自OpenAI和Hugging Face的选项。
准备好简化您的搜索功能了吗?立即开始使用Milvus+套娃嵌入!
资源
 王翔宇
王翔宇 Stefan Webb
Stefan Webb