



使用自定义AI模型扩展RAG的基础设施挑战
检索增强生成(RAG)系统通过提供更准确和上下文相关的响应,显著增强了AI应用。然而,随着这些系统变得更加复杂并融入自定义AI模型,它们的扩展和生产部署提出了相当大的挑战。
在Zilliz最近主办的非结构化数据 meetup 上,BentoML的创始人兼首席执行官Chaoyu Yang分享了在扩展带有自定义AI模型的RAG系统时基础设施方面的障碍,并强调了像BentoML这样的工具如何简化这些组件的部署和管理。本文将回顾Chaoyu Yang的关键点,并探讨高级推理模式和优化技术。这些策略将帮助您构建不仅功能强大而且高效和成本效益的RAG系统。
RAG如何增强AI应用
检索增强生成(RAG)系统已经出现,以解决GenAI应用中的“幻觉”问题。通过将向量数据库(如Milvus和Zilliz Cloud)的向量相似性检索功能与大型语言模型(LLMs)的生成能力相结合,RAG系统使AI模型能够产生:
- 更准确的响应
- 上下文相关
- 信息量极大
- 没有幻觉
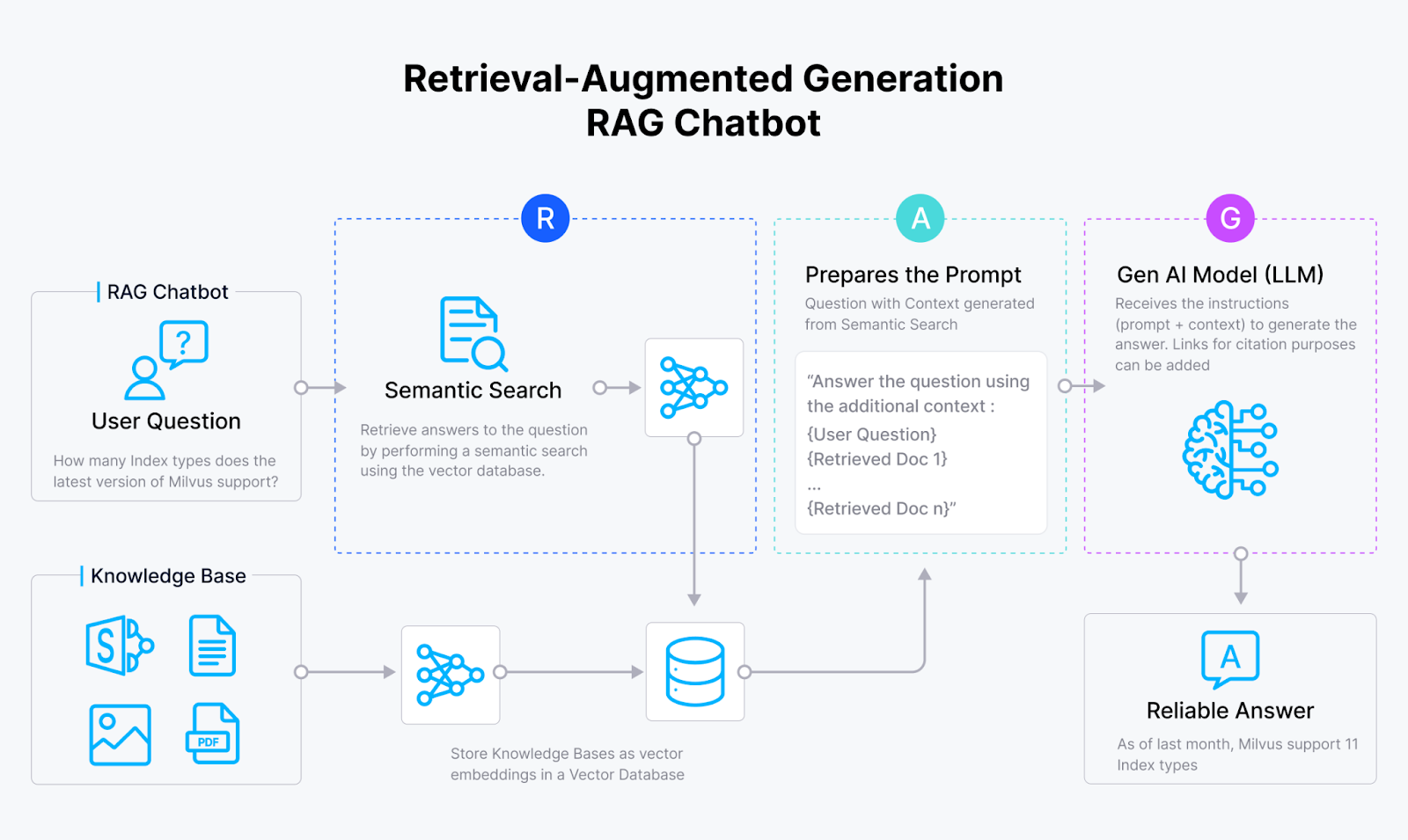 RAG_chatbot_2f1ff9ec07.png
RAG_chatbot_2f1ff9ec07.png
RAG聊天机器人的工作原理
这些系统有潜力转变广泛的领域,包括:
- 问题回答
- 文档摘要
- 个性化内容生成
RAG系统通过利用外部源中隐藏的庞大知识库来实现这一目标,就像一些AI图书管理员一样!
在生产环境中部署RAG系统的挑战
在RAG系统能够在生产环境中拯救世界之前,它们需要克服自己的挑战。最大的障碍之一是确保一流的检索性能,这涉及到:
- 优化召回率:确保检索到所有相关信息
- 优化精确度:最小化不相关信息的数量
使事情更有趣的是,RAG系统通常必须处理复杂的非结构化数据源。想象一下,理解一个布局、表格和图像比漫画书还要多的PDF,这个问题需要一些非常复杂的文档处理和理解技术。
RAG系统面临的另一个挑战是生成准确、上下文适当且与用户意图一致的响应。这就像只用不同书籍的片段编写一个连贯的故事一样!
此外,确保生成内容的安全性和可信度也至关重要,特别是当风险很高时。我们不希望我们的AI系统失控并传播错误信息!
自定义AI模型是这个故事中的可靠助手。通过微调和适应特定领域和数据集的AI模型,开发人员可以赋予他们的RAG系统所需的超能力,以直面这些挑战。
利用自定义AI模型提高RAG性能
要释放RAG系统的全部潜力,利用为我们特定用例量身定制的自定义AI模型至关重要。通过微调和优化这些模型,我们可以显著提高它们的性能。让我们探索自定义AI模型可以产生重大影响的一些关键领域。
文本嵌入模型:RAG成功的基础
默认的文本嵌入模型,如“text-embedding-ada-002”,通常无法捕捉我们特定领域的细微差别。这个模型在MTEB排行榜上排名第57位,表明有很大的改进空间。
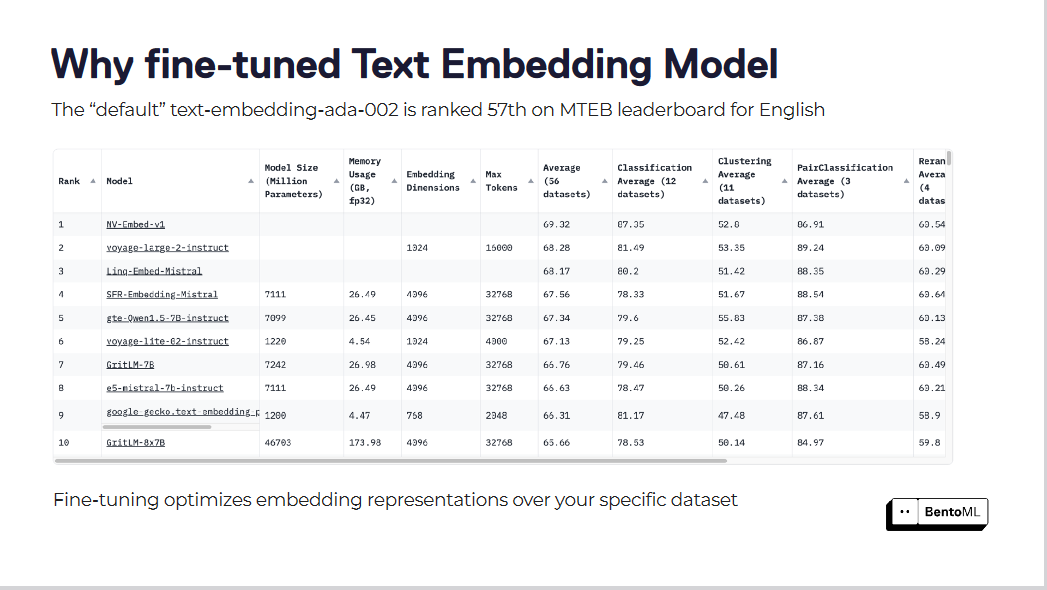 Fine_tuning_d7112c36ba.png
Fine_tuning_d7112c36ba.png
在特定数据集上微调可以优化嵌入表示
微调这些嵌入模型可以在检索分数上带来显著改进。通过为特定数据集优化嵌入模型,RAG系统已经看到了性能的大幅提升。
托管我们的LLMs:掌控控制权
专有LLMs提供了便利,但可能不总是满足我们的需求或限制。开源LLMs允许我们自定义和适应模型以满足我们的要求。在托管我们的LLMs时,我们应该考虑以下关键因素:
- 安全性和数据隐私
- 延迟和性能
- 需要的特定能力
- 成本和可扩展性
- 维护和支持
文档处理和理解:从非结构化数据中提取洞察
RAG系统通常需要处理和理解复杂的非结构化文档,如PDF、图像等。集成各种模型和技术可以帮助提取有价值的洞察。例如,我们可以进行:
- 使用LayoutLM进行布局分析
- 使用Table Transformers TATR进行表格检测
- 使用EasyOCR或Tesseract进行OCR
- 使用LayoutLM v3或Donut进行视觉文档QA
为您特定的文档类型微调这些模型可以大大提高它们的性能。
提高检索准确性的高级技术
为了进一步提高检索准确性,我们可以考虑实施以下技术:
- 上下文感知分块和全局概念感知分块:这些方法通过考虑文档中的上下文和总体概念,帮助识别检索中最相关的信息。
- 元数据提取:从文档中提取元数据可以提供额外的上下文,以增强检索和响应合成。
- 重新排名模型:在自定义数据集上微调重新排名模型,可以比通用模型提高10-30%的性能。
通过在这些关键领域利用自定义AI模型,我们可以显著提高我们的RAG系统的性能。
然而,有效地部署和提供这些模型带来了自己的一系列挑战。在下一节中,我们将讨论在扩展带有自定义模型的RAG时的基础设施挑战。
扩展带有自定义模型的RAG的基础设施挑战
随着RAG系统变得更加复杂并融入多个自定义模型,对计算资源的需求以及对高效部署和管理的需求显著增加。扩展带有自定义AI模型的检索增强生成(RAG)系统已成为迫切需求,但带来了一套独特的基础设施挑战。
高效提供自定义模型推理API
主要挑战之一是高效提供自定义模型推理API。RAG系统通常需要集成多个模型,例如:
- 文本嵌入模型
- 大型语言模型(LLMs)
- 文档处理模型
每个模型可能具有不同的计算需求和性能特征。部署这些模型作为能够处理实时请求并根据需求扩展的推理API是复杂的。
为了应对这一挑战,必须拥有一个健壮且可扩展的基础设施,以提供模型推理API。这个基础设施应该能够处理每个模型的具体需求,例如GPU分配、内存管理和延迟限制。像Docker这样的容器化技术可以帮助封装模型依赖项,并在不同系统之间提供一致的运行时环境。
高效的扩展机制
然而,仅仅容器化模型是不够的。基础设施还必须支持高效的扩展机制来处理不同的工作负载。这包括根据传入请求流量自动扩展模型实例的数量,确保资源的最优利用,并最小化响应时间。
模型服务的优化
另一个关键挑战是优化模型服务以提高性能和成本效率。自定义AI模型,特别是大型语言模型,可能计算成本高昂。简单的部署策略可能导致资源利用不佳和成本增加。像动态批处理这样的技术,通过将多个请求组合起来利用GPU的并行性,可以显著提高吞吐量并减少响应时间。
除了动态批处理,还可以应用其他优化技术,如量化、剪枝和模型蒸馏,以减少自定义模型的内存占用和计算需求。然而,实施这些优化需要仔细考虑模型性能和资源效率之间的权衡。
高效的资源分配和自动扩展
高效的资源分配和自动扩展也是扩展带有自定义模型的RAG系统的关键方面。基础设施应该能够根据每个模型的工作负载需求动态分配资源。这种方法涉及监控GPU利用率、内存使用量和请求延迟等关键指标,以做出明智的扩展决策。自动扩展机制应该能够处理流量的突然激增,并相应地扩展资源以维持最佳性能。
多个模型的组合和编排
此外,基础设施必须支持RAG系统中多个模型的组合和编排。RAG系统通常涉及复杂的管道,其中一个模型的输出作为另一个模型的输入。基础设施应该提供定义和管理这些管道的工具和框架,确保数据流的无缝性和高效执行。
监控和可观察性
监控和可观察性对于维护带有自定义模型的RAG系统的健康和性能至关重要。基础设施应该提供全面的监控能力,以跟踪所有系统组件的关键指标、日志和跟踪。这使得能够快速检测和诊断问题,并根据现实世界的性能数据优化和微调系统。
持续集成和部署(CI/CD)
最后,基础设施应该支持自定义模型的持续集成和部署(CI/CD)。随着模型的更新和完善,应该建立一个简化的流程来部署新版本,而不会影响整个系统。这需要强大的版本控制、测试和回滚机制,以确保RAG系统的稳定性和可靠性。
解决这些基础设施挑战需要结合工具、框架和最佳实践。在下一节中,我们将探讨BentoML,这是一个用于服务和部署机器学习模型的平台,如何帮助应对这些挑战并简化带有自定义AI模型的RAG系统的扩展。
使用BentoML为自定义模型构建推理API
BentoML简化了在RAG系统中为自定义模型构建和部署推理API的过程。它提供了从模型开发到生产就绪API的无缝过渡,使快速迭代和与现有系统集成更加容易。让我们看看它如何帮助我们克服扩展RAG的基础设施挑战。
从推理脚本到服务端点
只需几行代码,您就可以轻松地使用BentoML将推理脚本转换为服务端点。让我们看看一个为微调文本嵌入模型创建BentoML服务的示例:
import torchfrom sentence_transformers import SentenceTransformer, models
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
sentences: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
这段代码定义了SentenceTransformers类来封装嵌入模型及其相关方法。在__init__方法中,SentenceTransformer模型使用微调模型初始化,并设置在“cuda”设备上运行。encode方法接受一个句子列表作为输入,并返回它们作为NumPy数组的嵌入。
要将其转换为BentoML服务,您可以添加@bentoml.service和@bentoml.api装饰器:
import bentoml
@bentoml.serviceclass SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
sentences: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
要提供模型,您可以使用BentoML CLI:
bentoml serve .
此命令启动BentoML服务器并提供当前目录中定义的模型。CLI输出显示该服务正在监听http://localhost:3000。
然后,您可以使用BentoML客户端向提供模型发出请求:
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
result: np.NDArray = client.encode(
sentences=["sample input sentence"],
)
服务优化
BentoML提供了多种开箱即用的服务优化。最强大的优化之一是动态批处理。通过向您的API定义添加batchable=True参数,BentoML自动对传入请求进行批处理,优化GPU利用率,并提高模型服务的吞吐量。
@bentoml.api(batchable=True)def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
动态批处理通过将传入请求分组、拆分大批次并自动调整批次大小,智能地形成小批次。这种优化可以将响应时间加快高达3倍,吞吐量提高约200%。
部署和基础设施
BentoML提供了灵活且可扩展的部署和基础设施,用于提供服务。它支持多种部署选项,包括使用Docker进行容器化和使用Kubernetes进行编排。您可以轻松指定资源需求,例如GPU的数量和类型,并配置并发性和外部队列等流量设置。
import bentoml
@bentoml.service(
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
traffic={
"concurrency": 512,
"external_queue": True
})class SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
BentoML的自适应微批处理和弹性扩展功能确保了资源的最优利用,并根据传入流量自动扩展。它还提供了一个用户友好的部署仪表板,提供请求率、响应时间和资源利用情况的洞察。接下来,让我们看看如何使用BentoML扩展LLM推理服务。
使用BentoML扩展LLM推理服务
BentoML提供了全面的功能和优化,帮助您高效扩展LLM推理服务。
自动扩展策略
自动扩展确保您的LLM推理服务能够处理不同的工作负载并保持最佳性能。然而,像GPU利用率和每秒查询数(QPS)这样的传统自动扩展指标可能无法准确反映LLM服务所需的副本数量
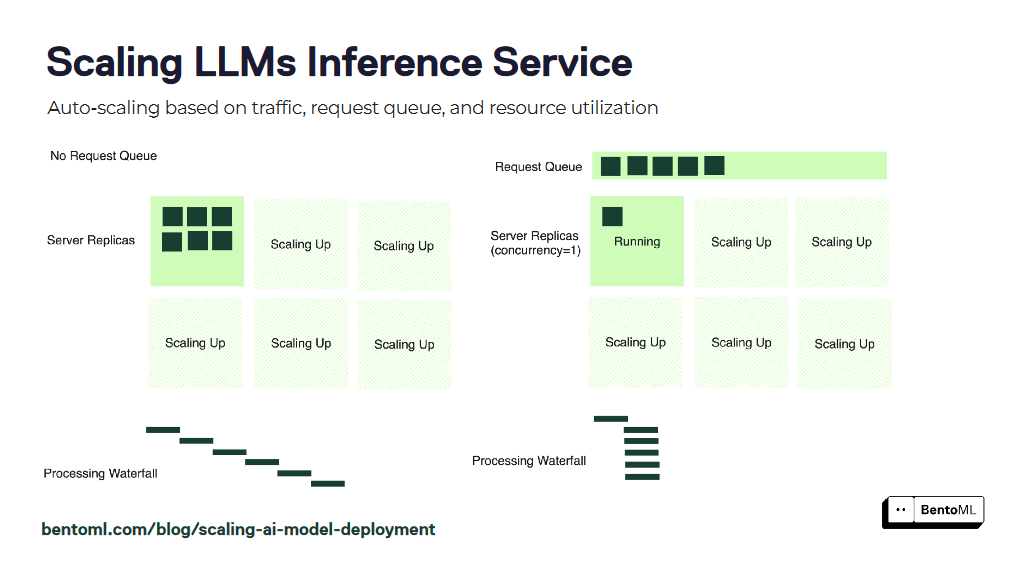 Sclaing_LL_Ms_6657800356.png
Sclaing_LL_Ms_6657800356.png
BentoML引入了基于并发性的自动扩展,这是一种更有效的LLM推理服务扩展方法。基于并发性的自动扩展考虑了每个模型副本可以处理的并发请求数量,提供了对服务容量的更准确表示。
冷启动优化
冷启动在扩展LLM推理服务时可能是一个重大挑战,特别是对于大型容器映像和模型文件。BentoML提供了几种优化技术来减轻冷启动延迟。
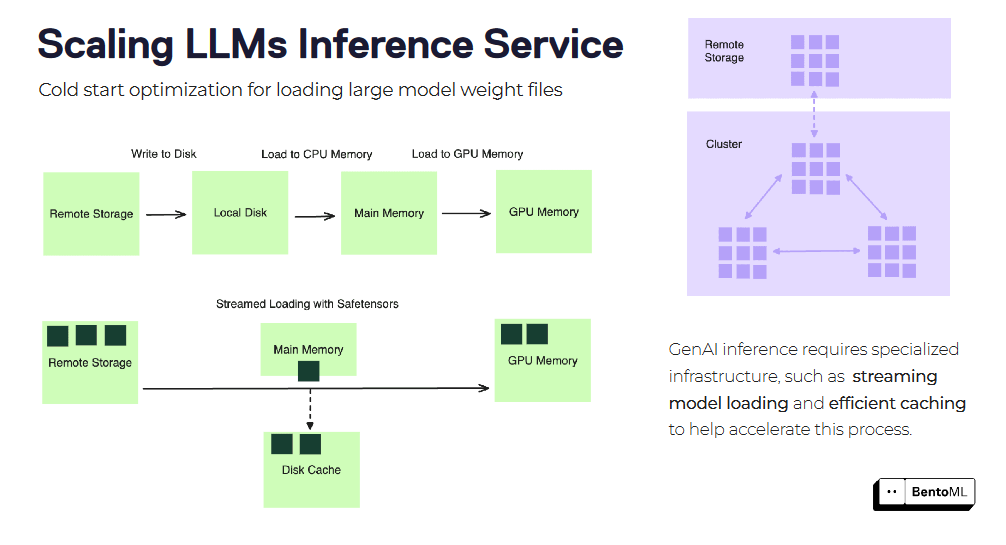 cold_start_optimization_ebe56f6a1c.png
cold_start_optimization_ebe56f6a1c.png
一种这样的技术是流式加载容器映像。BentoML可以在启动服务之前流式加载映像,按需获取仅必要的文件。这可以显著减少新副本的启动时间。
另一种优化是高效的模型权重文件加载和缓存。BentoML可以在副本之间缓存已加载的模型权重,减少为每个新请求加载模型所需的时间。这对于具有大量权重文件的大型语言模型特别有益。
通过利用BentoML的自动扩展策略和冷启动优化,您可以有效地扩展LLM推理服务以满足您的RAG系统的需求。BentoML抽象了基础设施管理的复杂性,使您能够专注于开发和迭代模型,同时确保最佳性能和可扩展性。
RAG系统的高级推理模式
RAG系统通常需要高级推理模式来处理复杂工作流程并优化性能。BentoML提供了一个灵活且可扩展的框架,支持这些模式,使创建复杂的RAG系统变得轻松。
可以通过组合多个模型和处理步骤(如布局分析、表格提取和OCR)来构建文档处理管道。
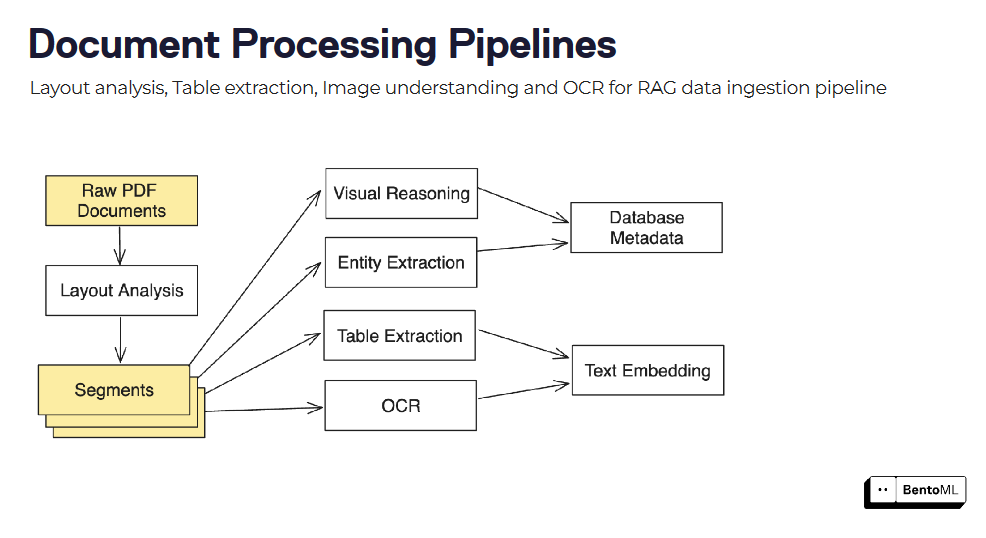 document_processing_pipelines_457a80ae13.png
document_processing_pipelines_457a80ae13.png
BentoML的异步推理接口高效地处理长时间运行的任务,而其批量推理支持利用并行性和优化来处理大型数据集。
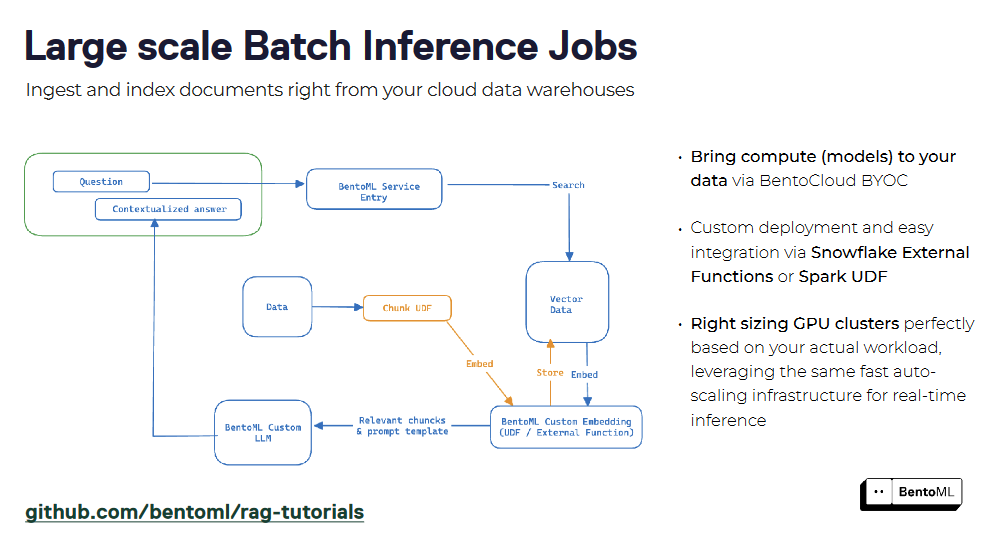 large_scale_batch_9593b94854.png
large_scale_batch_9593b94854.png
RAG系统可以作为服务使用BentoML进行打包,为查询和交互创建统一的接口。通过封装检索器和生成器组件,您可以轻松部署RAG服务并将其与其他应用程序集成。BentoML对容器化和编排的支持简化了生产环境中RAG服务的扩展和管理。
这些高级推理模式展示了BentoML在构建功能强大且高效的RAG服务方面的灵活性和可扩展性,这些服务可以处理各种任务和工作负载。
除了提供LLM服务的基础设施外,我们还需要一个强大的向量数据库来存储我们的向量嵌入并执行相似性搜索。这就是Milvus向量数据库对我们的帮助。在下一节中,我们将看看如何使用BentoML和Milvus构建一个简单的RAG应用。
集成BentoML和Milvus向量数据库
Milvus是一个为高性能相似性搜索而设计的开源向量数据库,是构建检索增强生成(RAG)的关键基础设施组件。
Milvus与BentoML集成,使构建可扩展的RAG应用变得更加容易。本节将指导您使用BentoML和Milvus向量数据库构建RAG应用。在这个示例中,我们将使用Milvus Lite,Milvus的轻量级版本,进行快速原型设计。
我们使用的数据集可以在这里找到:城市数据。
步骤1:设置环境
首先,安装以下所示的必需库:
# Install required libraries
pip install -U pymilvus bentoml
步骤2:准备您的数据
让我们下载并处理城市数据。
import osimport requestsimport urllib.request
# Set up the data source
repo = "ytang07/bento_octo_milvus_RAG"
directory = "data"
save_dir = "./city_data"
api_url = f"https://api.github.com/repos/{repo}/contents/{directory}"
# Download files from GitHub
response = requests.get(api_url)
data = response.json()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Process the downloaded datadef chunk_text(filename):
with open(filename, "r") as f:
text = f.read()
sentences = text.split("\n")
return [s for s in sentences if len(s) > 7]
cities = os.listdir("city_data")
city_chunks = []for city in cities:
chunked = chunk_text(f"city_data/{city}")
city_chunks.append({
"city_name": city.split(".")[0],
"chunks": chunked
})
步骤3:设置BentoML客户端
现在我们将设置嵌入模型和LLM的BentoML客户端,如下所示。
import bentoml
# Set up endpoints and API token
EMBEDDING_ENDPOINT = "YOUR_EMBEDDING_MODEL_ENDPOINT"
LLM_ENDPOINT = "YOUR_LLM_ENDPOINT"
API_TOKEN = "YOUR_API_TOKEN"
# Initialize BentoML clients
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
用您实际的BentoML部署端点和API令牌替换占位符端点和令牌。这些客户端将允许我们生成嵌入并使用语言模型进行文本生成。
步骤4:生成嵌入
在生成嵌入之前,让我们创建一个如下所示的嵌入函数:
创建嵌入函数
def get_embeddings(texts):
# Handle large batches of texts
if len(texts) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
for split in splits:
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
return embeddings
# Handle small batches directly
return embedding_client.encode(sentences=texts)
这个函数处理大批量文本的批处理,因为嵌入模型可能有输入大小限制。
为所有块生成嵌入。
entries = []for city_dict in city_chunks:
# Get embeddings for each city's text chunks
embedding_list = get_embeddings(city_dict["chunks"])
# Create entries with embeddings and metadata
for i, embedding in enumerate(embedding_list):
entry = {
"embedding": embedding,
"sentence": city_dict["chunks"][i],
"city": city_dict["city_name"],
}
entries.append(entry)
在这里,我们创建了一个条目列表,每个条目包含嵌入、原始句子和城市名称。当您将数据插入Milvus时,这种结构将非常有用。
步骤5:设置Milvus
现在我们将使用Milvus初始化向量数据库并添加嵌入。
初始化Milvus客户端并创建模式
from pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # This should match your embedding model's output dimension
# Initialize Milvus client
milvus_client = MilvusClient("milvus_demo.db")
# Create schema
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
我们在这里使用Milvus Lite,它嵌入在应用程序中。模式定义了我们在Milvus中的数据结构,包括自动生成的ID和嵌入向量。
准备索引参数并创建一个集合
# Prepare index parameters
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Create or recreate collectionif milvus_client.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
collection_name=COLLECTION_NAME, schema=schema, index_params=index_params
)
我们使用AUTOINDEX,它基于数据自动选择最佳索引类型。余弦相似度用作向量比较的距离度量。
将数据插入Milvus
现在,我们将数据插入Milvus如下所示
# Insert preprocessed data into Milvus
milvus_client.insert(collection_name=COLLECTION_NAME, data=entries)
这一步将所有预处理的数据(嵌入和元数据)插入Milvus集合。
步骤6:实施RAG
为了高效实施RAG,我们将创建三个函数来生成RAG响应、检索集合中的相关上下文,并如下所示生成答案:
为LLM生成答案的函数
def generate_rag_response(question, context):
# Prepare prompt for the LLM
prompt = (
f"You are a helpful assistant. Answer the user question based only on the context: {context}. \n"
f"The user question is {question}"
)
# Generate response using the LLM
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
这个函数使用检索到的上下文和用户的问题构建提示,然后使用LLM生成响应。
创建检索相关上下文的函数
def retrieve_context(question):
# Generate embedding for the question
embeddings = get_embeddings([question])
# Search for similar vectors in Milvus
res = milvus_client.search(
collection_name=COLLECTION_NAME,
data=embeddings,
anns_field="embedding",
limit=5,
output_fields=["sentence"],
)
# Extract and combine relevant sentences
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits]
return ". ".join(sentences)
这个函数嵌入用户的问题,在Milvus中搜索相似的向量,并检索相应的文本块作为上下文。
结合上述函数创建RAG管道
def ask_question(question):
# Retrieve relevant context
context = retrieve_context(question)
# Generate answer based on context and question
return generate_rag_response(question, context)
这个函数将所有内容整合在一起,创建我们的RAG管道。
步骤7:使用您的RAG系统
现在我们可以使用我们的RAG系统回答如下所示的问题:
# Example usage
question = "What state is Cambridge in?"
answer = ask_question(question)print(f"Question: {question}")print(f"Answer: {answer}")
这个示例演示了如何使用RAG系统回答有关城市的特定问题。
重要说明:
- 在运行此代码之前,请确保您的嵌入和大型语言模型已正确部署在BentoML上。
- 您的嵌入维度(本例中为384)应与您的嵌入模型的输出维度相匹配。
- 此设置使用Milvus Lite,适用于较小的数据集。对于更大规模的应用,考虑在Docker或K8s上使用完整的Milvus部署。
- RAG系统的有效性取决于您最初的城市数据的质量和覆盖范围。确保您的数据集全面准确,以获得最佳结果。
BentoML和Milvus的这种集成创建了一个功能强大的RAG系统,能够根据提供的城市信息回答问题。您可以通过添加更多数据或针对特定用例进行微调来扩展此系统。
结论
构建和扩展带有自定义AI模型的检索增强生成(RAG)系统带来了独特的挑战。开发人员可以通过利用自定义模型的力量,优化部署和服务基础设施,并采用高级推理模式,创建高性能且可扩展的RAG系统。
BentoML是这一旅程中的宝贵工具。它简化了构建和部署推理API的过程,优化了服务性能,并实现了无缝扩展。
通过将BentoML与Milvus向量数据库集成,组织可以构建更强大、可扩展的RAG系统。这种组合使高效检索相关信息和生成上下文感知的响应成为可能,为各个领域和行业的高级AI应用开辟了可能性。
注:本文为AI翻译,查看原文
 Uppu Rajesh Kumar
Uppu Rajesh KumarFreelance Technical Writer


