



信息检索指标
信息检索(IR)系统旨在使用相关输入查询遍历广泛的、密集的数据集。这些系统使用统计算法将输入查询与参考文档匹配,并使用排名指标检索最相关的信息。IR在像谷歌这样的流行搜索引擎中使用。它也被部署在本地组织中,以检索与公司相关的文档。
在部署之前,必须使用信息检索指标适当评估IR系统。这些指标根据输入查询与检索结果之间的搜索相关性来判断IR系统。这篇博客将讨论关键的信息检索指标以及它们是如何应用于IR系统的。
关键信息检索指标
一些流行的基本信息检索指标包括:
- 精确度@k:精确度评估检索结果中的真实正例。它分析返回的结果中有多少与搜索查询相关。指标后面的“@k”描述了在评估期间分析的前k个结果。例如,精确度@5意味着前五个输出的精确度。
- 召回率@k:召回率通过分析返回的结果与数据库中所有相关项目的数量来评估IR系统。由于k值的影响很大,如果k等于整个数据集,召回率将是1。必须根据应用要求设置k值。
- F1分数@k:F1是精确度和召回率之间的调和平均值。它提供了两个指标之间的平衡,并在上述两个评估都相关时使用。
这些指标是不考虑顺序的,也不会受到返回结果顺序的影响。
然而,排名指标受到检索结果顺序的影响。一些流行的排名指标包括:
- 平均精度均值(MAP):MAP有两个部分。首先,它计算单个查询的多个k值(从1到N)的平均精度。第二部分取所有可能查询的平均精度的平均值。
- 归一化折扣累积增益(NDCG):NDCG考虑与数据库中每个元素相关联的两个排名。第一个排名是用户分配的,并且根据与用户查询相关的元素的值而具有更高的值。IR系统提供了第二个排名。NDCG比较真实情况和系统生成的排名进行评估。
理解召回率和精确度
在信息检索的背景下,召回率和精确度直接分析返回结果的相关性。它们有类似的工作原理但不同的范围。精确度仅根据结果集中返回的项目来判断检索系统。其公式是
 14.1.PNG
14.1.PNG
真实正例是子集(由k定义)内的所有相关结果,而假正例是不相关的。给定一个包含10张图片的数据集,假设我们想评估前5个结果(k=5)。其中三个与查询相关,而两个不相关。这个系统的精确度将是
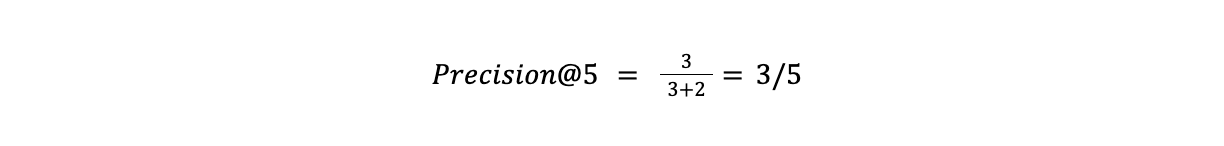 14.2.PNG
14.2.PNG
召回率基于数据库中所有相关结果评估返回结果的相关性。其公式是
 14.3.PNG
14.3.PNG
公式中的假负例描述了最终结果集中未包含的所有相关项目。继续我们之前的例子,如果我们在数据集的其余部分中有四个相关结果,其召回率将是
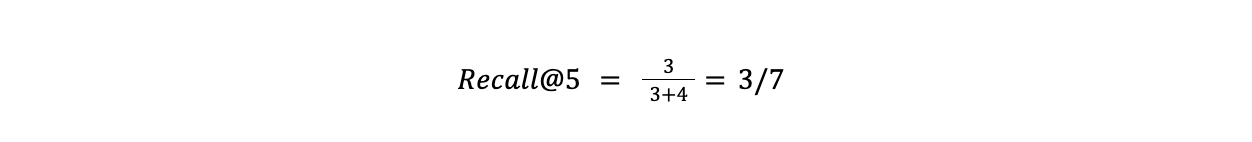 14.5.PNG
14.5.PNG
开发者经常面临精确度-召回率权衡,他们必须找到平衡。这两个指标是对比的,因为精确度根据检索到的真实标签展示系统,而召回率判断遗留的真实标签。一个有效的IR系统必须显示两个指标的合理值。
高级指标:NDCG和MAP
高级指标,如NDCG和MAP,是考虑顺序的,这意味着指标值会根据检索项的顺序受到影响。
MAP(平均精度均值)
MAP以精确度指标为核心。然而,MAP不是使用单个k值,而是对不同k值计算的多个精确度值取平均值。
如果k设置为5,精确度将计算1、2、3、4和5的值,然后平均以给出平均精度(AP)。然而,一个强大的信息检索系统应该适用于各种用户输入。MAP对多个查询计算AP,然后取所有值的平均值。最终的MAP值更好地代表了系统对不同输入的性能。
NDCG(归一化折扣累积增益)
NDCG使用与数据库中每个元素相关联的真实排名。排名的范围可以由用户定义。例如,一个用户查询“带有红色扰流板的白色跑车”将有几张与它相关的图片。与描述相匹配的图片可能会被赋予5的排名,而完全不相关的图片将有1的排名。任何在某些部分与描述匹配的图片都会有中间排名(2、3、4)。
NDCG首先取所有检索图片的排名之和。如果结果集包含更多相关图片,这个总和会更高,但无论结果顺序如何,都会保持不变。这个结果通过引入基于对数的惩罚来抵消。惩罚因子根据其值和在结果中的排名惩罚每个图片排名。在最终集中排名较低的值会受罚更多。这样,如果系统首先输出不相关的图片,系统将获得较低的分数。
这个指标的最后一个问题是,分数没有上限。通过将最终分数标准化并限制在0和1之间来解决这个问题。通过首先计算理想情况下的分数,即系统将所有相关图片排在顶部。然后,实际分数除以理想值以获得最终的标准化值。
将指标应用于评估系统
在应用部署之前,IR指标用于开发者级别的测试和改进整体搜索框架。测试人员通常有一个框架,使用预定义的查询和标记文档自动评估IR系统。该框架突出显示表现不佳的查询。
信息检索的最主要用途是在谷歌和必应等搜索引擎中。这些引擎使用统计算法和向量数据库从数十亿的数据集中检索相关文档。评估指标有助于根据输入查询提高搜索相关性并提高用户满意度。
结论
信息检索指标评估用于检索文档与用户查询的统计算法。这些评估指标检查检索文档与提供的查询的相关性。有两种类型的评估指标:不考虑顺序和考虑顺序的。
不考虑顺序的指标包括精确度、召回率和F1分数。这些指标不关心检索文档的顺序,只关注最终子集的整体相关性。 考虑顺序的指标包括MAP和NDCG。这些排名指标稍微高级,汇总了对多个搜索窗口和查询的评估。考虑顺序的指标还考虑检索顺序,并惩罚将不相关文档排在相关文档之上的系统。
我们在这篇文章中讨论的只是冰山一角。大型企业采用更复杂的检索和评估框架来创建强大的搜索机制。我们鼓励您进一步探索检索机制,如向量相似性搜索和向量数据库,以更好地理解现代信息检索评估。


