



向量数据库正在革新人工智能应用中的非结构化数据搜索
向量数据库已经成为革新人工智能应用中非结构化数据搜索的重要工具。它们被广泛认识的角色之一是在检索增强型生成(RAG)中,这是一个将相关文档与大型语言模型(LLM)连接起来的过程。然而,它们的应用和能力远远超出了RAG;它们更广泛地适用于各种不同类型的非结构化数据,即任何不符合预定义数据模型的数据类型,如文本、图像、音频、分子和图。
在最近的巴西非结构化数据聚会上,Zilliz的人工智能和机器学习负责人Frank Liu谈到了向量数据库是如何改变人工智能应用中非结构化数据搜索的格局的。他的见解揭示了这些数据库广泛而深远的能力。
什么是向量?
在讨论向量数据库及其在人工智能应用中的作用之前,理解向量是什么是很重要的,因为它们是向量数据库的构建块。向量是一系列数字,以计算机可以处理的方式编码信息。想象你有一张图片,如下所示:
 Fig_1_An_image_represented_in_vector_format_4cd966af15.png
Fig_1_An_image_represented_in_vector_format_4cd966af15.png
Fig 1- 以向量格式表示的图像
对你来说,它是一朵美丽的花,但对计算机来说,这张图片需要转换成它能理解的格式。这就是向量嵌入发挥作用的地方。
上述花朵的图像被转换成了一个向量嵌入——一个结构化的数字数组。向量中的每个数字代表图像的特定特征,如颜色、纹理或形状。这些数字的组合提供了一种紧凑且高效的图像表示,计算机可以用于各种任务,如搜索类似图像、分类对象,甚至生成新图像。以下是如何在像Milvus这样的向量数据库中生成和存储向量嵌入的可视化。
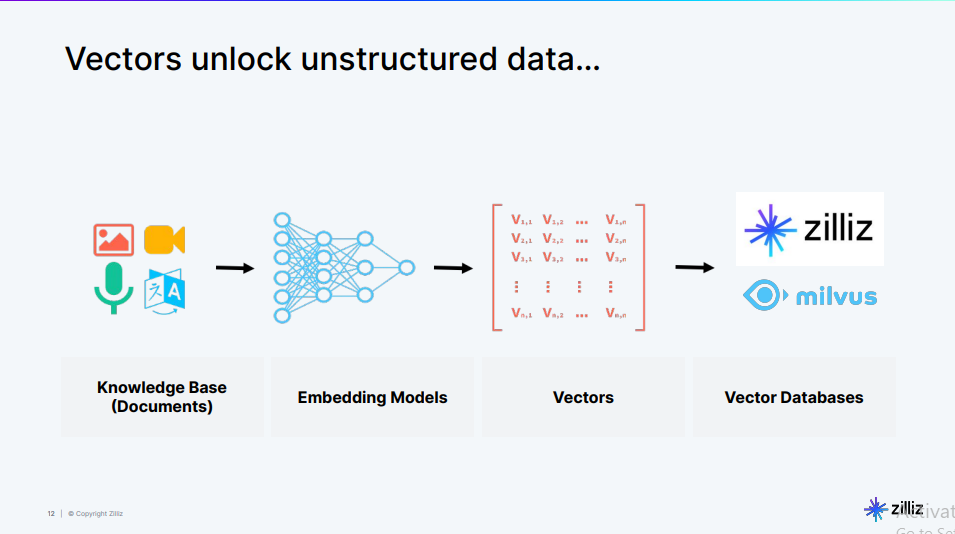 Fig_2_Vector_embedding_generations_and_storage_process_7c0cffa5b8.png
Fig_2_Vector_embedding_generations_and_storage_process_7c0cffa5b8.png
Fig 2- 向量嵌入生成和存储过程
这个过程始于包含各种类型数据的知识库。然后数据被嵌入模型处理,将其转换成向量。最后,向量被存储在像Milvus这样的向量数据库中,准备检索。
数据嵌入不仅限于图像。文本、音频甚至更复杂的数据类型,如分子和图,都可以被转换成向量嵌入。通过将数据表示为向量,我们可以利用向量数据库的强大功能执行高效准确的搜索。
让我们看看向量数据库在不同领域中的应用。
由向量数据库驱动的不同用例
向量数据库正在改变我们处理和搜索非结构化数据的方式,在多种应用中都是如此。从增强人工智能系统的能力到做出更有效的推荐,可能性是广泛而深远的。让我们深入了解一些由向量数据库驱动的具体用例。
检索增强型生成(RAG)
向量数据库正在通过实现更有效和语义上有意义的检索来革新RAG。传统的基于关键词的搜索方法在处理复杂查询或细微的上下文时常常力不从心。向量数据库通过基于语义相似性而不是精确匹配来存储和搜索数据,从而解决了这一局限性。
在RAG中,文档被转换成高维向量,捕捉它们的语义含义。当收到查询时,它也被转换成向量,向量数据库可以快速找到语义上最相似的文档。这种方法允许更细腻和上下文感知的信息检索,这对于生成准确和相关的响应至关重要。
考虑一个科技公司的客户支持聊天机器人。当用户询问,“我的设备无法打开,我该如何排查故障?”向量数据库可以检索到相关文档,即使它们不包含这些确切的词汇。它可能会提取有关电源问题、电池问题和一般故障排除步骤的信息。然后,大型语言模型使用这些检索到的信息生成一个全面且与上下文相关的回应,显著提高了客户支持的质量。
推荐系统
向量数据库正在通过实现更复杂和高效的相似性计算来革新推荐系统。传统的推荐系统在处理大型数据集时常常面临“冷启动”问题,并且计算成本高昂。向量数据库通过允许在高维空间中进行快速的近似最近邻搜索来解决这些问题。
在由向量数据库驱动的推荐系统中,用户和项目都表示为共享嵌入空间中的向量。这些嵌入捕捉复杂的特征和偏好,允许更细致的推荐。向量数据库可以快速找到相似的用户或项目,即使在处理大型数据集时也能实现实时个性化。
例如,像Spotify这样的音乐流媒体服务使用向量数据库来驱动其推荐引擎。每首歌都被表示为一个向量,捕捉各种属性,如流派、节奏、情绪和收听模式。用户偏好也被编码为向量。当用户听一首新歌时,系统可以快速在向量空间中找到相似的歌曲,允许发现与用户口味一致的新音乐,即使它来自不熟悉的艺术家或流派。
分子相似性搜索
向量数据库正在通过实现更高效和准确的识别相似化合物来革新药物发现中的分子相似性搜索。传统方法常常依赖于2D结构相似性,这可能会错过重要的3D构象相似性或功能团关系。
有了向量数据库,分子的图像被表示为高维向量,捕捉复杂的结构和化学属性。这允许研究人员搜索具有相似属性或潜在生物活性的分子,即使它们的2D结构看起来不同。向量数据库的速度还允许快速筛选大型化学库。
以一家制药公司寻找新的抗生素候选药物为例。他们有一个已知的抗生素分子效果很好,但副作用严重。使用向量数据库,他们可以快速搜索数百万种化合物,找到具有相似抗菌特性但可能具有不同副作用概况的分子。向量表示可能捕捉到电荷分布、潜在结合位点和3D形状等功能,允许发现结构多样但功能相似的分子,这些是传统的2D相似性搜索可能会错过的。
多模态相似性搜索
向量数据库正在通过提供统一的方式来表示和搜索不同类型的数据(文本、图像、音频等)来革新多模态搜索。传统的搜索系统常常难以处理跨模态查询或找到不同数据类型之间的关系。
在由向量数据库驱动的多模态系统中,所有数据类型都被投影到一个共享的高维空间中,可以计算相似性,无论原始数据类型如何。这允许更灵活和强大的搜索能力,使我们能够跨不同模态找到相关内容。
例如,一个电子商务平台使用向量数据库实现了一个多模态搜索系统。用户可以上传他们喜欢的家具图片,并提供描述所需颜色和材料的文本描述。系统将图像和文本都转换为共享空间中的向量。然后,它搜索向量数据库,找到既符合图像的视觉风格又符合文本描述中特定属性的产品。这使用户能够找到他们确切想要的东西,即使他们不能完全用语言表达,大大增强了购物体验。 这些只是被向量数据库革新的一些用例。Frank分享了以下幻灯片,其中包含更多用例。
 Fig_3_Vector_databases_use_cases_844c77fd20.png
Fig_3_Vector_databases_use_cases_844c77fd20.png
Fig 3- 向量数据库用例
上述列表并不全面。它只是代表了通过向量数据库增强人工智能应用中数据搜索的可能性。
既然你现在已经了解了向量数据库在各个领域的重要性。让我们实现其中一个用例,让你看到它们在行动中的样子。我们将使用Milvus,因为它是GitHub上最受欢迎的向量数据库。
使用Milvus、Radient、ImageBind和Meta-Chameleon-7b实现多模态相似性搜索系统
要使用上述工具实现多模态相似性搜索系统,你需要在环境中安装它们并导入它们。
设置你的环境
首先安装所需的库并下载必要的模型。
!pip install -U radient
!pip install -U yt-dlp
!pip install pymilvus
!pip install -U git+https://github.com/facebookresearch/chameleon.git@main
!git clone https://huggingface.co/eastwind/meta-chameleon-7b
!yt-dlp "https://www.youtube.com/watch?v=wwk1QIDswcQ" -o ~/google_io_preshow.mp4
!pip install git+https://github.com/fzliu/ImageBind@main
以上每个库的作用如下:
- Radient:创建并执行处理和分析多模态数据的工作流程,集成各种数据处理步骤。
- yt-dlp:一个命令行工具,用于从YouTube下载视频。在本文中,我们将使用这个来自谷歌预展的视频。
- PyMilvus:与Milvus向量数据库和Milvus Lite交互的Python SDK,实现大规模数据的高效相似性搜索和检索。
- Chameleon:由Meta AI开发的视图-语言模型,能够根据视觉输入理解和生成文本,适用于集成多模态数据输入。
- Meta-Chameleon-7b:Chameleon系列中的一种特定模型,专为高级视图-语言任务设计,通过集成视觉和文本数据提供上下文感知的响应。
- ImageBind:一个多模态嵌入模型。
安装完库后,我们需要将它们导入到你的代码中,以便使用它们的功能。
from pathlib import Path
from radient import make_operator
from radient import Workflow
注意我们只导入了radient。这是因为Radient处理嵌入模型和PyMilvus在其工作流中的集成和利用。因此,我们不需要手动导入它们。
make_operator函数允许我们创建各种操作符,这些操作符将形成我们工作流的构建块。Workflow类将这些操作符按逻辑顺序连接在一起。
导入后,你准备好实现多模态相似性搜索系统了。
创建操作符
首先指定工作流将执行的具体任务。
path = Path('/content/google.mp4') // pass the youtube downloaded video path here
read = make_operator(optype="source", method="local", task_params={"path": str(path)})
demux = make_operator(optype="transform", method="video-demux", task_params={"interval": 5.8})
vectorize = make_operator (optype="vectorizer", method="imagebind", modality="multimodal", task_params={})
store = make_operator (optype="sink", method="milvus", task_params={"operation": "insert"})
让我们详细分解每个操作符:
- read:这是一个源操作符,用于读取本地视频文件。它接受文件路径作为参数,负责将视频数据加载到我们的工作流中。
- demux:这是一个转换操作符,将视频分离成5.8秒间隔的帧。这一步对于将连续的视频流分解成可以单独处理的离散图像至关重要。
- vectorize:此操作符使用ImageBind模型为多模态数据创建向量嵌入。ImageBind是一个强大的模型,可以为不同模态(如图像、文本和音频)创建统一的嵌入,允许我们在高维向量空间中表示我们的视频帧。
- store:这是一个接收操作符,将向量化的数据插入到Milvus Lite中。Milvus的轻量级版本。
创建操作符后,下一步是使用它们创建一个工作流。
构建插入工作流
接下来,我们构建一个工作流,将我们处理过的视频数据插入到Milvus数据库中:
insert_wf = (Workflow()
.add(read, name="read")
.add(demux, name="demux")
.add(vectorize, name="vectorize")
.add(store, name="store")
)
insert_wf()
这个工作流首先读取视频文件,然后将视频分离成单独的帧。每个帧随后使用ImageBind模型进行向量化。生成的向量存储在Milvus数据库中。
如果一切运行顺利,你应该看到一个类似于下面的输出:
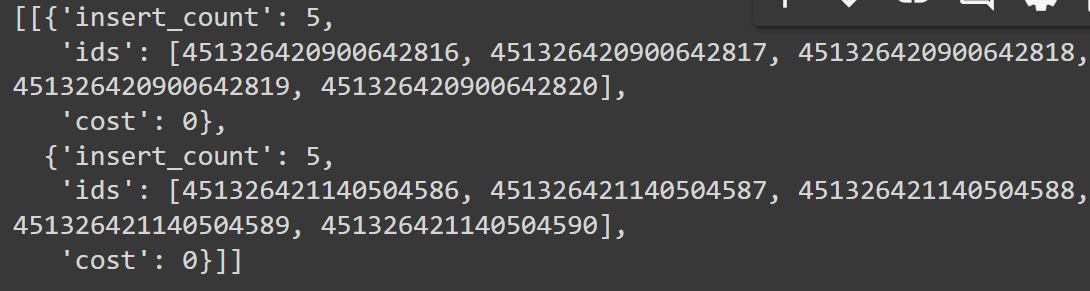 Fig_4_Results_of_the_insertion_operation_b4cf66c082.png
Fig_4_Results_of_the_insertion_operation_b4cf66c082.png
Fig 4- 插入操作的结果
输出显示你的视频已处理并插入到Milvus中。它显示了插入操作的结果,指示插入的记录数量、它们的ID和计算成本。
设置搜索工作流
插入我们的数据后,我们需要设置一个搜索工作流。这个工作流将允许我们根据文本查询找到相关的视频帧:
vectorize = make_operator("vectorizer", "imagebind", modality="text")
search = make_operator("sink", "milvus", task_params={"operation": "search", "output_fields": None})
search_wf = (Workflow()
.add(vectorize, name="vectorize")
.add(search, name="search")
)
这个搜索工作流由两个主要步骤组成:
- vectorize操作符接受文本输入,并使用ImageBind将其转换为向量嵌入。这允许我们将文本查询表示为与我们的视频帧相同的向量空间。
- search操作符随后使用这个向量在Milvus数据库中执行相似性搜索,找到与我们查询最相似的视频帧。
既然我们有了搜索工作流,让我们执行一个搜索。
执行多模态搜索
这是一个多模态搜索,因为我们正在使用文本搜索视频。更准确地说,我们正在搜索视频帧。
prompt = "What was unusual about the coffee mug?"
search_wf(data=prompt)
search_vars = {
"limit": 1, # top-k limit
"output_fields": ["*"] # output fields
}
results = search_wf(
extra_vars={"search": search_vars},
data=prompt
)
results[0][0][0]["entity"]["data"]
在这里,我们定义了一个搜索提示,询问关于一个不寻常的咖啡杯。search_vars字典指定我们想要顶部1个结果和所有输出字段。 然后我们用这些输入执行搜索工作流。工作流将我们的文本提示向量化,在Milvus中搜索相似的向量,并返回结果。嵌套索引[0][0][0]访问第一个(也是唯一一个)搜索结果,["entity"]["data"]检索与此结果相关联的实际数据。
上述代码返回了与我们查询最匹配的帧的路径。
/root/.radient/data/video_demux/6bc783e9-c789-4340-b45c-204621145f2b/frame_0001.png
让我们可视化这个返回的帧,看看杯子有什么不寻常之处.
from PIL import Image
image_path = "/root/.radient/data/video_demux/6bc783e9-c789-4340-b45c-204621145f2b/frame_0001.png"
image = Image.open(image_path)
import matplotlib.pyplot as plt
plt.imshow(image)
plt.show()
这段代码使用PIL(Python Imaging Library)打开对应于我们搜索结果的图像文件,并使用matplotlib显示它。这种视觉表示帮助我们理解系统对我们关于不寻常咖啡杯的查询的响应。
这是输出:
 Fig_5_A_person_coming_out_of_a_Mug_7ff945d854.png
Fig_5_A_person_coming_out_of_a_Mug_7ff945d854.png
Fig 5- 从杯子里出来的人
如你所见,这个帧显示了一个不寻常的杯子,因为你不能把一个人放进一个普通的杯子里。不寻常的活动是有人从杯子里出来。
利用Meta-Chameleon-7b进行图像描述
为了进一步增强我们的多模态搜索系统,我们可以使用Meta-Chameleon-7b模型来生成图像的描述:
from chameleon.inference.chameleon import ChameleonInferenceModel
import os
# Verify the file path and existence
image_path = '/root/.radient/data/video_demux/6bc783e9-c789-4340-b45c-204621145f2b/frame_0001.png'
print(f"Image path: {image_path}")
print(f"File exists: {os.path.exists(image_path)}")
print(f"File size: {os.path.getsize(image_path)} bytes")
# Initialize the model
model = ChameleonInferenceModel(
"./meta-chameleon-7b/models/7b/",
"./meta-chameleon-7b/tokenizer/text_tokenizer.json",
"./meta-chameleon-7b/tokenizer/vqgan.yaml",
"./meta-chameleon-7b/tokenizer/vqgan.ckpt",
)
try:
tokens = model.generate(
prompt_ui=[
{"type": "image", "value": f"file:{image_path}"}, # Remove the space after 'file:'
{"type": "text", "value": prompt},
{"type": "sentinel", "value": "<END-OF-TURN>"},
]
)
result = model.decode_text(tokens)[0]
print("Generated description:")
print(result)
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
这段代码初始化了Meta-Chameleon-7b模型,这是一个视图-语言模型,能够理解和描述上下文中的图像。我们为它提供了图像和我们原始的文本提示,允许它生成与我们查询相关的描述。
generate方法接受一个输入列表,包括图像文件路径、我们的文本提示和一个哨兵标记来标记输入的结束。然后模型生成一系列标记,我们将其解码成人类可读的文本。以下是输出应该是什么样子的示例:
 Fig_6_Output_of_describing_and_image_using_a_vision_language_model_687ad9f912.png
Fig_6_Output_of_describing_and_image_using_a_vision_language_model_687ad9f912.png
Fig 6- 使用视图-语言模型描述图像的输出
这个实现展示了如何将像Milvus这样的向量数据库集成到更大的人工智能系统中,实现跨不同模态的高效相似性搜索。
结论
Frank在向我们展示向量数据库如何作为人工智能和机器学习领域的一种变革性技术,特别是在处理非结构化数据方面做得很好。正如所演示的,它们的应用远远超出了简单的检索增强型生成(RAG)系统,革新了包括客户支持、推荐系统、药物发现和多模态搜索在内的各个领域。继续实现更多复杂的向量数据库驱动的人工智能应用。
注:本文为AI翻译,查看原文
 Denis Kuria
Denis KuriaFreelance Technical Writer


