



如何在亚马逊EKS上部署开源Milvus向量数据库
这篇文章最初发表在AWS网站上,经允许后在这里翻译、编辑和转载。
向量嵌入和向量数据库概述
生成性人工智能(GenAI)的兴起,特别是大型语言模型(LLMs),极大地激发了人们对向量数据库的兴趣,确立了它们在GenAI生态系统中作为重要组成部分的地位。结果,向量数据库在越来越多的用例中被采用。
一份IDC报告预测,到2025年,超过80%的商业数据将是非结构化的,存在于文本、图像、音频和视频等格式中。理解、处理、存储和大规模查询这些大量的非结构化数据是一个重大挑战。在GenAI和深度学习的常见做法是将非结构化数据转换为向量嵌入,在像Milvus或Zilliz Cloud(完全托管的Milvus)这样的向量数据库中存储和索引它们,以进行向量相似性或语义相似性搜索。
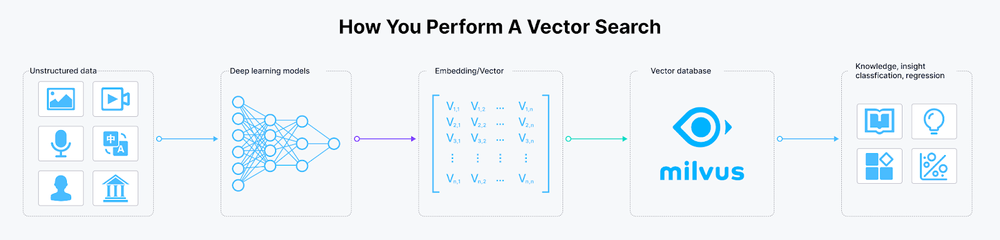
但什么是向量嵌入呢?简单地说,它们是高维空间中浮点数的数值表示。两个向量之间的距离表明了它们的相关性:它们越接近,就越相关,反之亦然。这意味着相似的向量对应于相似的原始数据,这与传统的关键词或精确搜索不同。
 Figure_2_How_to_perform_a_vector_search_f38e8533a2.png
Figure_2_How_to_perform_a_vector_search_f38e8533a2.png
图1:如何执行向量相似性搜索
存储、索引和搜索向量嵌入的能力是向量数据库的核心功能。目前,主流的向量数据库分为两类。第一类扩展了现有的关系数据库产品,如带有KNN插件的Amazon OpenSearch Service和带有pgvector扩展的Amazon RDS for PostgreSQL。第二类包括专门的向量数据库产品,包括一些知名的例子,如Milvus、Zilliz Cloud(完全托管的Milvus)、Pinecone、Weaviate、Qdrant和Chroma。
嵌入技术和向量数据库在各种AI驱动的用例中都有广泛的应用,包括图像相似性搜索、视频去重和分析、自然语言处理、推荐系统、定向广告、个性化搜索、智能客户服务和欺诈检测。
Milvus是在众多向量数据库中最受欢迎的开源选项之一。这篇文章介绍了Milvus,并探索了在AWS EKS上部署Milvus的实践。
什么是Milvus?
Milvus是一个高度灵活、可靠且极快的云原生开源向量数据库。它支持向量相似性搜索和人工智能应用,并努力使向量数据库对每个组织都易于访问。Milvus可以存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的超过十亿个向量嵌入。
Milvus在2019年10月根据开源Apache License 2.0发布。目前,它是LF AI & Data Foundation的一个毕业项目。在撰写这篇博客时,Milvus的Docker拉取下载量已经超过5000万次,被许多客户使用,如NVIDIA、AT&T、IBM、eBay、Shopee和Walmart。
Milvus关键特性
作为云原生向量数据库,Milvus拥有以下关键特性:
- 针对十亿规模向量数据集的高性能和毫秒级搜索。
- 多语言支持和工具链。
- 即使在中断事件中也具有水平可扩展性和高可靠性。
- 通过将标量过滤与向量相似性搜索配对实现的混合搜索。
Milvus架构
Milvus遵循数据流和控制流分离的原则。系统分为四个层次,如下图所示:
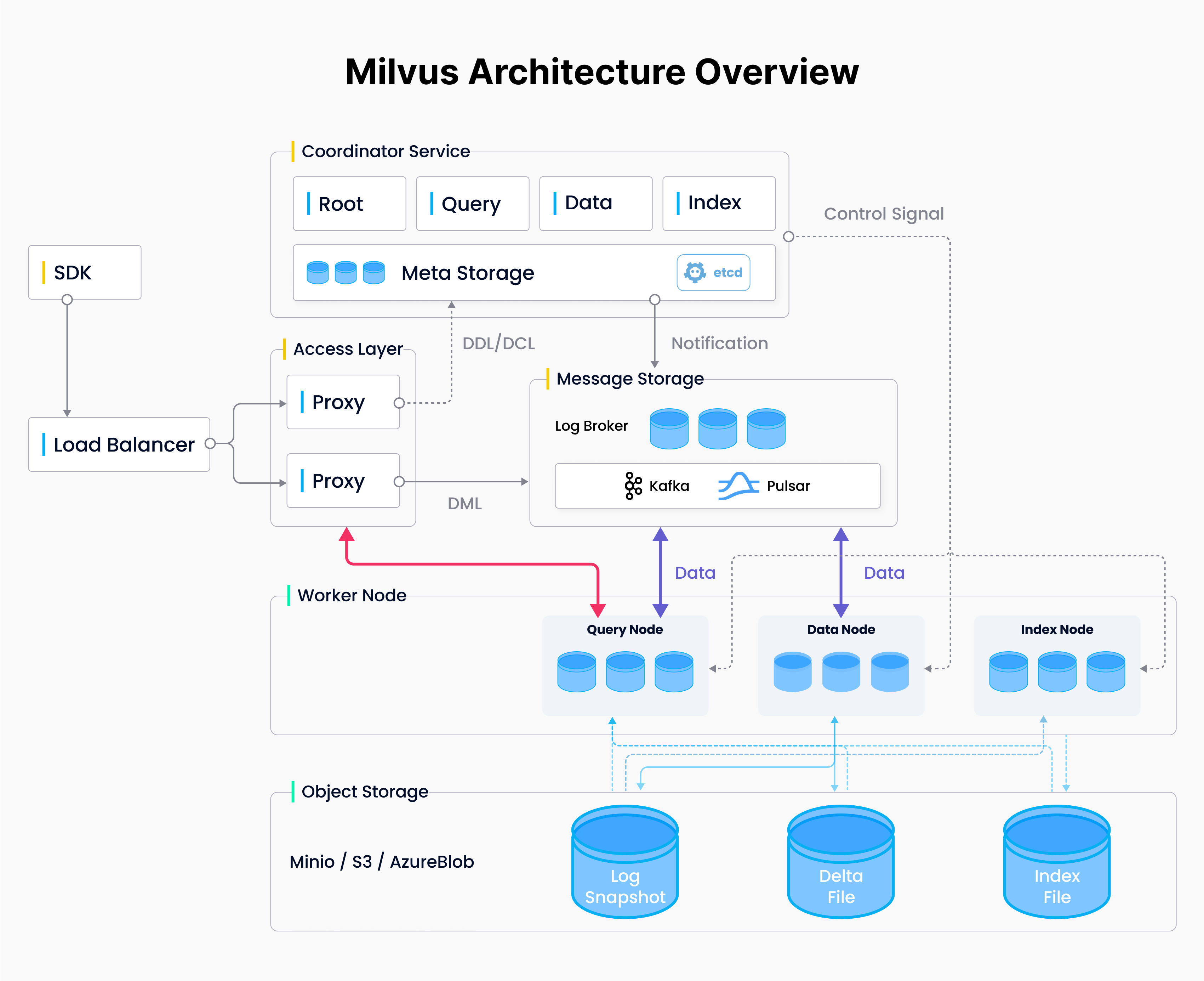 Milvus_Architecture_Overview_fd10aeffb8.png
Milvus_Architecture_Overview_fd10aeffb8.png
图2 Milvus架构
- 访问层:访问层由一组无状态代理组成,作为系统的前端和用户端点。
- 协调服务:协调服务分配任务给工作节点。
- 工作节点:工作节点是遵循协调服务指示并执行用户触发的DML/DDL命令的哑执行器。
- 存储:存储负责数据持久性。它包括元存储、日志代理和对象存储。
Milvus部署选项
Milvus支持三种运行模式:Milvus Lite、Standalone和Distributed。
- Milvus Lite是一个可以导入到本地应用程序中的Python库。作为Milvus的轻量级版本,它非常适合在Jupyter Notebooks中快速原型设计或在资源有限的智能设备上运行。
- Milvus Standalone是单台机器服务器部署。如果您有生产工作负载但不想使用Kubernetes,那么在单台具有足够内存的机器上运行Milvus Standalone是一个很好的选择。
- Milvus Distributed可以部署在Kubernetes集群上。它支持更大的数据集、更高的可用性和可扩展性,更适合生产环境。
Milvus从一开始就被设计为支持Kubernetes,并且可以轻松地在AWS上部署。我们可以使用Amazon Elastic Kubernetes Service(Amazon EKS)作为托管的Kubernetes、Amazon S3作为对象存储、Amazon Managed Streaming for Apache Kafka(Amazon MSK)作为消息存储,以及Amazon Elastic Load Balancing(Amazon ELB)作为负载均衡器来构建一个可靠、弹性的Milvus数据库集群。
接下来,我们将提供使用EKS和其他服务部署Milvus集群的逐步指导。
在AWS EKS上部署Milvus
先决条件
我们将使用AWS CLI来创建一个EKS集群并部署Milvus数据库。需要以下先决条件:
- 一台安装有AWS CLI的PC/Mac或Amazon EC2实例,并配置有适当的权限。如果您使用Amazon Linux 2或Amazon Linux 2023,AWS CLI工具将默认安装。
- 安装了EKS工具,包括Helm、Kubectl、eksctl等。
- 一个Amazon S3存储桶。
- 一个Amazon MSK实例。
创建MSK时的考虑事项
Milvus的最新稳定版本(v2.3.13)依赖于Kafka的autoCreateTopics功能。因此,在创建MSK时,我们需要使用自定义配置,并将auto.create.topics.enable属性从默认的false更改为true。此外,为了提高MSK的消息吞吐量,建议增加message.max.bytes和replica.fetch.max.bytes的值。有关详细信息,请参见自定义MSK配置。
auto.create.topics.enable=true
message.max.bytes=10485880
replica.fetch.max.bytes=20971760
Milvus不支持MSK的IAM基于角色的认证。因此,在创建MSK时,在安全配置中启用SASL/SCRAM认证选项,并在AWS Secrets Manager中配置用户名和密码。有关详细信息,请参见使用AWS Secrets Manager进行登录认证凭证认证。
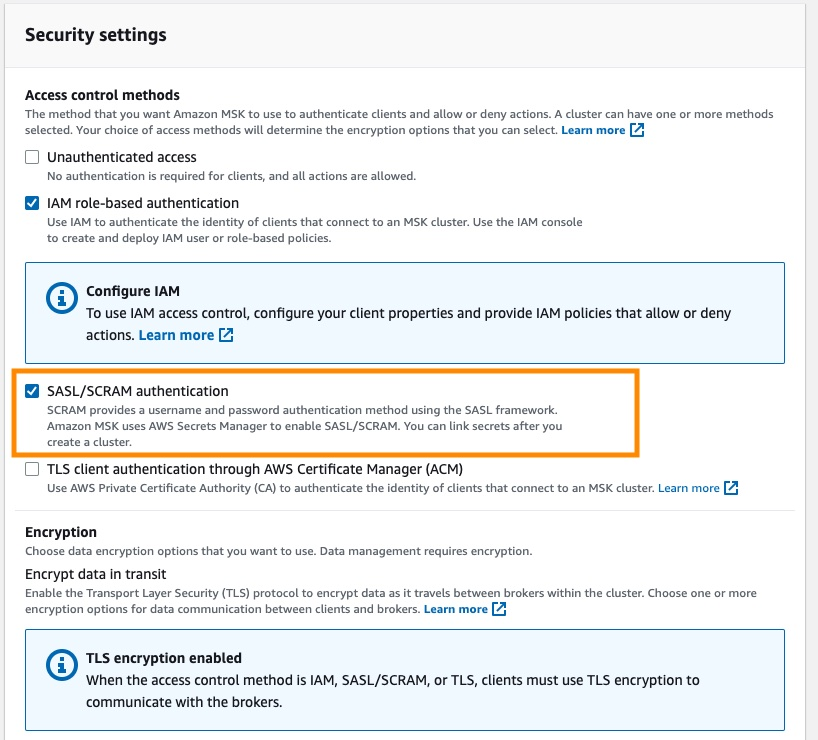 Figure_3_Security_settings_enable_SASL_SCRAM_authentication_9cf7cdde00.png
Figure_3_Security_settings_enable_SASL_SCRAM_authentication_9cf7cdde00.png
图3:安全设置:启用SASL/SCRAM认证
我们需要从EKS集群的安全组或IP地址范围启用对MSK安全组的访问。
创建EKS集群
有多种方法可以创建EKS集群,例如通过控制台、CloudFormation、eksctl等。本文将展示如何使用eksctl创建EKS集群。
eksctl是一个简单的命令行工具,用于在Amazon EKS上创建和管理Kubernetes集群。它提供了创建新集群和Amazon EKS节点的最快、最简单的方法。有关更多信息,请参见eksctl的网站。
首先,使用以下代码片段创建一个eks_cluster.yaml文件。将<cluster-name>替换为您的集群名称,将<region-code>替换为您想要创建集群的AWS区域,并替换<private-subnet-idx>为您的私有子网。注意:此配置文件通过指定私有子网在现有VPC中创建EKS集群。如果您想要创建一个新的VPC,请删除VPC和子网配置,然后eksctl将自动创建一个新的。
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: <cluster-name>
region: <region-code>
version: "1.26"
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: aws-load-balancer-controller
namespace: kube-system
wellKnownPolicies:
awsLoadBalancerController: true
- metadata:
name: milvus-s3-access-sa
# if no namespace is set, "default" will be used;
# the namespace will be created if it doesn't exist already
namespace: milvus
labels: {aws-usage: "milvus"}
attachPolicyARNs:
- "arn:aws:iam::aws:policy/AmazonS3FullAccess"
vpc:
subnets:
private:
us-west-2a: { id: <private-subnet-id1> }
us-west-2b: { id: <private-subnet-id2> }
us-west-2c: { id: <private-subnet-id3> }
managedNodeGroups:
- name: ng-1-milvus
labels: { role: milvus }
instanceType: m6i.2xlarge
desiredCapacity: 3
privateNetworking: true
addons:
- name: vpc-cni # no version is specified so it deploys the default version
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- name: coredns
version: latest # auto discovers the latest available
- name: kube-proxy
version: latest
- name: aws-ebs-csi-driver
wellKnownPolicies: # add IAM and service account
ebsCSIController: true
然后,运行eksctl命令创建EKS集群。
eksctl create cluster -f eks_cluster.yaml
此命令将创建以下资源:
- 一个指定版本的EKS集群。
- 一个带有三台m6i.2xlarge EC2实例的管理节点组。
- 一个IAM OIDC身份提供者和一个名为aws-load-balancer-controller的ServiceAccount,我们将在稍后安装AWS Load Balancer Controller时使用。
- 一个名为milvus的命名空间和一个在此命名空间内的ServiceAccount milvus-s3-access-sa。这个命名空间将在后面配置Milvus作为对象存储的S3时使用。注意:为了简单起见,这里的milvus-s3-access-sa被授予了完整的S3访问权限。在生产部署中,建议遵循最小权限原则,仅授予对Milvus使用的特定S3存储桶的访问权限。
- 多个插件,其中vpc-cni、coredns、kube-proxy是EKS所需的核心插件。aws-ebs-csi-driver是AWS EBS CSI驱动程序,允许EKS集群管理Amazon EBS卷的生命周期。
现在,我们只需要等待集群创建完成。
等待集群创建完成。在集群创建过程中,kubeconfig文件将自动创建或更新。您也可以通过运行以下命令手动更新它。确保将<region-code>替换为您的集群正在创建的AWS区域,并将<cluster-name>替换为您的集群名称。
aws eks update-kubeconfig --region <region-code> --name <cluster-name>
一旦集群创建完成,您可以通过运行以下命令查看节点:
kubectl get nodes -A -o wide
创建一个配置为GP3存储类型的ebs-sc StorageClass,并将其设置为默认的StorageClass。Milvus使用etcd作为其元存储,并且需要这个StorageClass来创建和管理PVC。
cat <<EOF | kubectl apply -f -
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ebs-sc
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
EOF
然后,将原始的gp2 StorageClass设置为非默认:
kubectl patch storageclass gp2 -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
安装AWS Load Balancer Controller。我们稍后将为Milvus服务和Attu Ingress使用此控制器,因此让我们提前安装它。
首先,添加eks-charts仓库并更新它。
helm repo add eks https://aws.github.io/eks-charts
helm repo update
接下来,安装AWS Load Balancer Controller。将<cluster-name>替换为您的集群名称。在之前的步骤中创建EKS集群时,已经创建了名为aws-load-balancer-controller的ServiceAccount。
helm install aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=<cluster-name> \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controller
验证控制器是否成功安装。
kubectl get deployment -n kube-system aws-load-balancer-controller
输出应该如下所示:
NAME READY UP-TO-DATE AVAILABLE AGE
aws-load-balancer-controller 2/2 2 2 12m
部署Milvus集群
Milvus支持多种部署方法,如Operator和Helm。Operator更简单,但Helm更直接、更灵活。我们将在本例中使用Helm部署Milvus。
使用Helm部署Milvus时,您可以通过values.yaml文件自定义配置。点击values.yaml查看所有选项。默认情况下,Milvus在集群内创建minio和pulsar作为对象存储和消息存储。我们将做一些配置更改,使其更适合生产。
首先,添加Milvus Helm仓库并更新它。
helm repo add milvus https://zilliztech.github.io/milvus-helm/
helm repo update
创建一个milvus_cluster.yaml文件,包含以下代码片段。此代码片段自定义了Milvus的配置,如配置Amazon S3作为对象存储和Amazon MSK作为消息队列。我们将在后面提供详细的解释和配置指导。
serviceAccount:
create: false
name: milvus-s3-access-sa
minio:
enabled: false
externalS3:
enabled: true
host: "s3.<region-code>.amazonaws.com"
port: "443"
useSSL: true
bucketName: "<bucket-name>"
rootPath: "<root-path>"
useIAM: true
cloudProvider: "aws"
iamEndpoint: ""
pulsar:
enabled: false
externalKafka:
enabled: true
brokerList: "<broker-list>"
securityProtocol: SASL_SSL
sasl:
mechanisms: SCRAM-SHA-512
username: "<username>"
password: "<password>"
service:
type: LoadBalancer
port: 19530
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: external #AWS Load Balancer Controller fulfills services that has this annotation
service.beta.kubernetes.io/aws-load-balancer-name : milvus-service #User defined name given to AWS Network Load Balancer
service.beta.kubernetes.io/aws-load-balancer-scheme: internal # internal or internet-facing, later allowing for public access via internet
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip #The Pod IPs should be used as the target IPs (rather than the node IPs)
attu:
enabled: true
name: attu
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb # Annotation: set ALB ingress type
alb.ingress.kubernetes.io/scheme: internet-facing #Places the load balancer on public subnets
alb.ingress.kubernetes.io/target-type: ip #The Pod IPs should be used as the target IPs (rather than the node IPs)
alb.ingress.kubernetes.io/group.name: attu # Groups multiple Ingress resources
hosts:
-
rootCoordinator:
replicas: 2
activeStandby:
enabled: true # Enable active-standby when you set multiple replicas for root coordinator
resources:
limits:
cpu: 1
memory: 2Gi
indexCoordinator:
replicas: 2
activeStandby:
enabled: true # Enable active-standby when you set multiple replicas for index coordinator
resources:
limits:
cpu: "0.5"
memory: 0.5Gi
queryCoordinator:
replicas: 2
activeStandby:
enabled: true # Enable active-standby when you set multiple replicas for query coordinator
resources:
limits:
cpu: "0.5"
memory: 0.5Gi
dataCoordinator:
replicas: 2
activeStandby:
enabled: true # Enable active-standby when you set multiple replicas for data coordinator
resources:
limits:
cpu: "0.5"
memory: 0.5Gi
proxy:
replicas: 2
resources:
limits:
cpu: 1
memory: 4Gi
queryNode:
replicas: 1
resources:
limits:
cpu: 2
memory: 8Gi
dataNode:
replicas: 1
resources:
limits:
cpu: 1
memory: 4Gi
indexNode:
replicas: 1
resources:
limits:
cpu: 4
memory: 8Gi
代码包含六个部分。按照以下说明更改相应的配置。
第1部分:将S3配置为对象存储。serviceAccount授予Milvus访问S3的权限(在这种情况下,是milvus-s3-access-sa,我们在创建EKS集群时创建了它)。确保将<region-code>替换为您的集群所在的AWS区域。将<bucket-name>替换为您的S3存储桶名称,将<root-path>替换为您的S3存储桶前缀(此字段可以留空)。
第2部分:将MSK配置为消息存储。将<broker-list>替换为与MSK的SASL/SCRAM认证类型相对应的端点地址。将
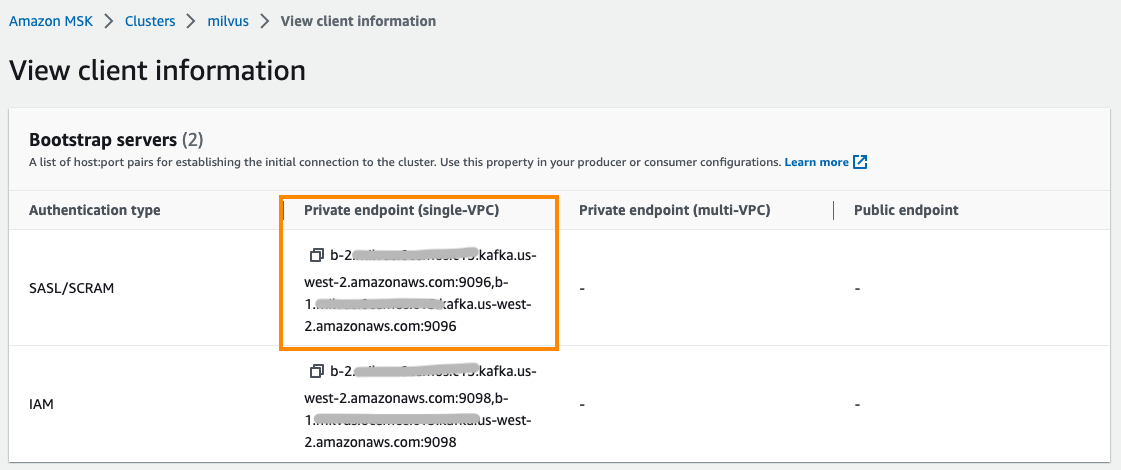 Figure_4_Configure_MSK_as_the_Message_Storage_of_Milvus_a9e602e0b9.png
Figure_4_Configure_MSK_as_the_Message_Storage_of_Milvus_a9e602e0b9.png
图4:将MSK配置为Milvus的消息存储
第3部分:将Milvus服务暴露并启用从集群外部访问。Milvus端点默认使用ClusterIP类型服务,仅在EKS集群内部可访问。如果需要,您可以将其更改为LoadBalancer类型以允许从EKS集群外部访问。LoadBalancer类型服务使用Amazon NLB作为服务负载均衡器。根据安全最佳实践,默认配置aws-load-balancer-scheme为内部模式,这意味着只允许Milvus的内部网络访问。点击查看NLB配置说明。
第4部分:安装并配置Attu,一个开源的Milvus管理工具。它具有直观的GUI,允许您轻松地与Milvus交互。我们启用Attu,使用AWS ALB配置入口,并将其设置为internet-facing类型,以便通过互联网访问Attu。点击此文档为ALB配置指南。
第5部分:启用Milvus核心组件的HA部署。Milvus包含多个独立且解耦的组件。例如,协调服务充当控制层,处理根、查询、数据和索引组件的协调。访问层中的Proxy充当数据库访问端点。这些组件默认只有1个pod副本。部署这些服务组件的多个副本特别需要提高Milvus的可用性。
注意:根、查询、数据和索引协调器组件的多副本部署需要启用activeStandby选项。
第6部分:调整Milvus组件的资源分配以满足您的工作负载要求。Milvus网站还提供了一个大小工具,根据数据量、向量维度、索引类型等生成配置建议。它还可以一键生成Helm配置文件。以下配置是该工具为100万1024维向量和HNSW索引类型给出的建议。
使用Helm在命名空间milvus中创建Milvus(部署)。注意:您可以将
helm install <demo> milvus/milvus -n milvus -f milvus_cluster.yaml
运行以下命令以检查部署状态。
kubectl get deployment -n milvus
以下输出显示Milvus组件全部可用,并且协调组件启用了多个副本。
NAME READY UP-TO-DATE AVAILABLE AGE
demo-milvus-attu 1/1 1 1 5m27s
demo-milvus-datacoord 2/2 2 2 5m27s
demo-milvus-datanode 1/1 1 1 5m27s
demo-milvus-indexcoord 2/2 2 2 5m27s
demo-milvus-indexnode 1/1 1 1 5m27s
demo-milvus-proxy 2/2 2 2 5m27s
demo-milvus-querycoord 2/2 2 2 5m27s
demo-milvus-querynode 1/1 1 1 5m27s
demo-milvus-rootcoord 2/2 2 2 5m27s
访问和管理Milvus
到目前为止,我们已经成功部署了Milvus向量数据库。现在,我们可以通过端点访问Milvus。Milvus通过Kubernetes服务暴露端点。Attu通过Kubernetes入口暴露端点。
访问Milvus端点
运行以下命令以获取服务端点:
kubectl get svc -n milvus
您可以看到几个服务。Milvus支持两个端口,端口19530和端口9091:
- 端口19530用于gRPC和RESTful API。当您使用不同的Milvus SDK或HTTP客户端连接到Milvus服务器时,这是默认端口。
- 端口9091是用于指标收集、pprof分析和Kubernetes内健康探针的管理端口。
demo-milvus服务提供了一个数据库访问端点,用于从客户端建立连接。它使用NLB作为服务负载均衡器。您可以从EXTERNAL-IP列获取服务端点。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo-etcd ClusterIP 172.20.103.138 <none> 2379/TCP,2380/TCP 62m
demo-etcd-headless ClusterIP None <none> 2379/TCP,2380/TCP 62m
demo-milvus LoadBalancer 172.20.219.33 milvus-nlb-xxxx.elb.us-west-2.amazonaws.com 19530:31201/TCP,9091:31088/TCP 62m
demo-milvus-datacoord ClusterIP 172.20.214.106 <none> 13333/TCP,9091/TCP 62m
demo-milvus-datanode ClusterIP None <none> 9091/TCP 62m
demo-milvus-indexcoord ClusterIP 172.20.106.51 <none> 31000/TCP,9091/TCP 62m
demo-milvus-indexnode ClusterIP None <none> 9091/TCP 62m
demo-milvus-querycoord ClusterIP 172.20.136.213 <none> 19531/TCP,9091/TCP 62m
demo-milvus-querynode ClusterIP None <none> 9091/TCP 62m
demo-milvus-rootcoord ClusterIP 172.20.173.98 <none> 53100/TCP,9091/TCP 62m
使用Attu管理Milvus
如前所述,我们已经安装了Attu来管理Milvus。运行以下命令以获取端点:
kubectl get ingress -n milvus
您可以看到名为demo-milvus-attu的入口,其中ADDRESS列是访问URL。
NAME CLASS HOSTS ADDRESS PORTS AGE
demo-milvus-attu <none> * k8s-attu-xxxx.us-west-2.elb.amazonaws.com 80 27s
在浏览器中打开入口地址,看到以下页面。点击连接以登录。
 Figure_5_Log_in_to_your_Attu_account_bde25a6da5.png
Figure_5_Log_in_to_your_Attu_account_bde25a6da5.png
图5:登录您的Attu账户
登录后,您可以通过Attu管理Milvus数据库。
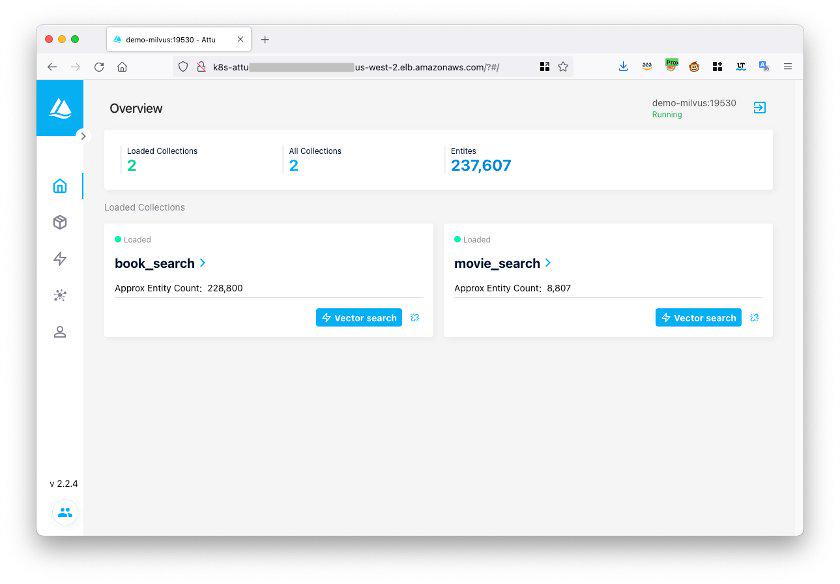 Figure_6_The_Attu_interface_3e818e6833.png
Figure_6_The_Attu_interface_3e818e6833.png
图6:Attu界面
测试Milvus向量数据库
我们将使用Milvus的示例代码来测试Milvus数据库是否正常工作。首先,使用以下命令下载hello_milvus.py示例代码:
wget https://raw.githubusercontent.com/milvus-io/pymilvus/master/examples/hello_milvus.py
将示例代码中的主机修改为Milvus服务端点。
print(fmt.format("start connecting to Milvus"))
connections.connect("default", host="milvus-nlb-xxx.elb.us-west-2.amazonaws.com", port="19530")
运行代码:
python3 hello_milvus.py
如果系统返回以下结果,则表示Milvus正常运行。
=== start connecting to Milvus ===
Does collection hello_milvus exist in Milvus: False
=== Create collection `hello_milvus` ===
=== Start inserting entities ===
Number of entities in Milvus: 3000
=== Start Creating index IVF_FLAT ===
=== Start loading ===
结论
本文介绍了Milvus,这是最受欢迎的开源向量数据库之一,并提供了在AWS上使用Amazon EKS、S3、MSK和ELB等托管服务部署Milvus的指南,以实现更大的弹性和可靠性。
作为各种GenAI系统的核心组件,特别是检索增强型生成(RAG),Milvus支持并与各种主流GenAI模型和框架集成,包括Amazon Sagemaker、PyTorch、HuggingFace、LlamaIndex和LangChain。今天就开始您的GenAI创新之旅,使用Milvus!

AWS


技术干货
我决定给 ChatGPT 做个缓存层 >>> Hello GPTCache
我们从自己的开源项目 Milvus 和一顿没有任何目的午饭中分别获得了灵感,做出了 OSSChat、GPTCache。在这个过程中,我们也在不断接受「从 0 到 1」的考验。作为茫茫 AI 领域开发者和探索者中的一员,我很愿意与诸位分享这背后的故事、逻辑和设计思考,希望大家能避坑避雷、有所收获。
2023-4-14
技术干货
艾瑞巴蒂看过来!OSSChat 上线:融合 CVP,试用通道已开放
有了 OSSChat,你就可以通过对话的方式直接与一个开源社区的所有知识直接交流,大幅提升开源社区信息流通效率。
2023-4-6
技术干货
LLM 快人一步的秘籍 —— Zilliz Cloud,热门功能详解来啦!
此次我们在进行版本更新的同时,也增加了多项新功能。其中,数据迁移(Migration from Milvus)、数据的备份和恢复(Backup and Restore)得到了很多用户的关注。本文将从操作和设计思路的层面出发,带你逐一拆解 Zilliz Cloud 的【热门功能】。
2023-4-10