



如何元数据湖赋能下一代AI/ML应用
随着大型语言模型(LLMs)和检索增强型生成(RAG)等AI技术的不断发展,对灵活高效数据基础设施的需求也在增长。组织正在寻求能够支持这些新工具的数据架构,同时最小化技术债务并实现无缝扩展。
元数据湖作为解决方案应运而生。它们是集中存储组织中各种来源元数据的仓库,提供统一的数据管理方法。元数据提供了存储数据的上下文和理解,包括数据源、质量、血统、所有权、内容、结构和上下文。
Datastrato的产品经理Lisa N. Cao在Zilliz主办的非结构化数据聚会上发表了演讲,讨论了元数据湖在下一代AI/ML开发中的重要作用。凭借她作为数据工程师的经验,Lisa分享了元数据湖如何简化数据管理和与向量数据库、深度学习模型以及AI驱动环境中的LLMs等不同技术的集成。
 DSC_0118_6e085bf1bb.jpg
DSC_0118_6e085bf1bb.jpg
Lisa在帕洛阿尔托举行的六月非结构化数据聚会上发言
本文回顾了Lisa的关键观点,并探讨了将RAG管道部署到生产环境的挑战。但首先,我们简要介绍一下RAG以及RAG开发和部署中的挑战。
RAG(检索增强型生成)快速介绍
RAG,或检索增强型生成,是一个通过结合检索和生成模块来增强LLM响应的高级框架。检索模块包括像Milvus或Zilliz Cloud(完全托管的Milvus)这样的向量数据库和嵌入模型,生成模块通常是像ChatGPT这样的LLM。
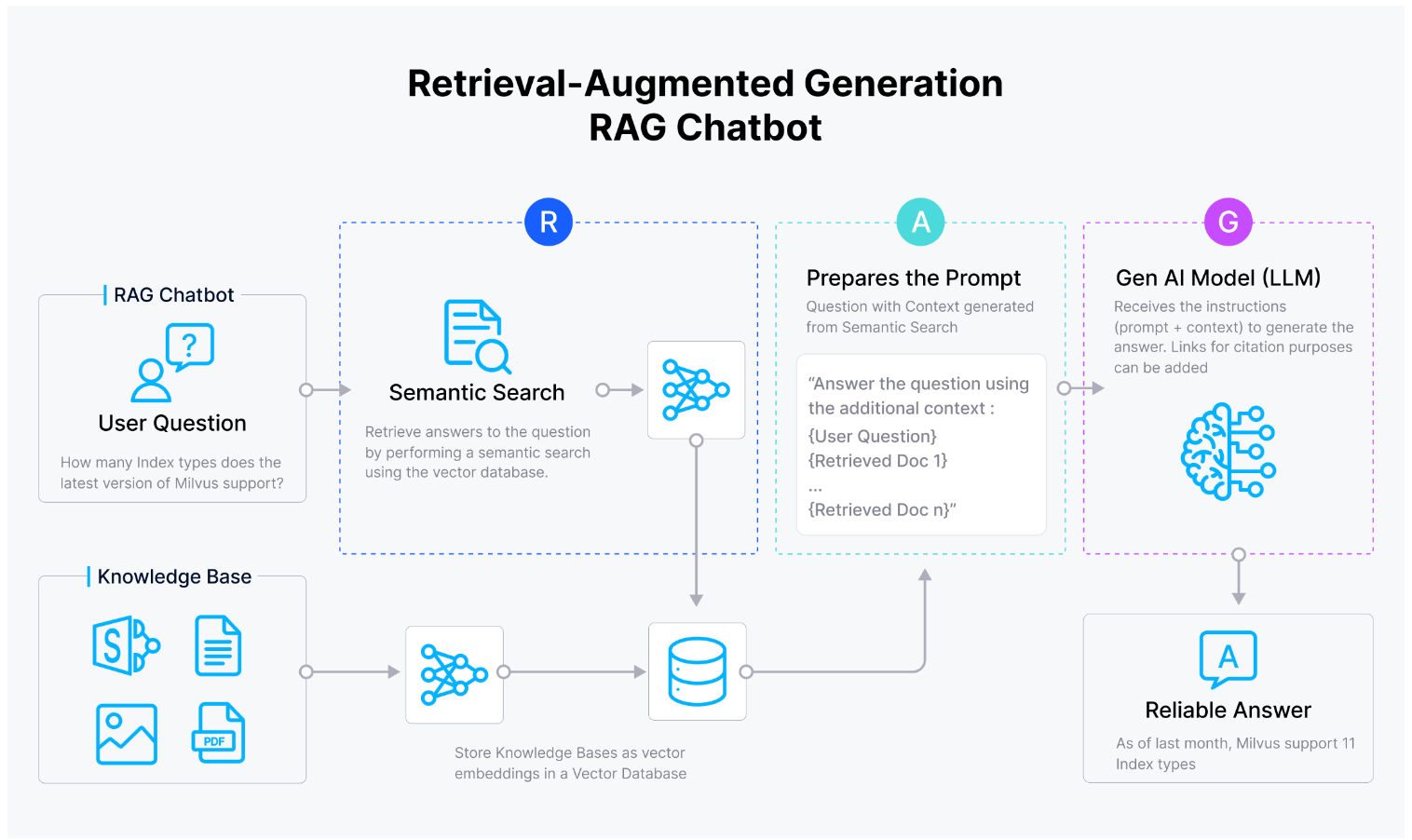 Figure_Vector_database_facilitating_RAG_chatbot_1a87eb1206.png
Figure_Vector_database_facilitating_RAG_chatbot_1a87eb1206.png
图1 RAG工作原理
当用户向RAG应用输入查询时,检索模块中的向量数据库从大型文本语料库中提取最相关的文档。这些检索到的文档被称为“顶级候选文档”,它们被送入LLM作为用户查询上下文,以生成更准确的响应。RAG在问答、聊天机器人和知识管理系统等应用中特别有用。
RAG开发当前的挑战
最近,许多先进技术被引入RAG管道,以增强准确性和性能,包括基于重排和递归检索的复杂检索方法,以及基于嵌入和LLM的微调技术。此外,还引入了旨在增强RAG能力的路由和查询规划的代理框架。
然而,这些进步也带来了新的复杂性。Lisa讨论了许多AI团队在开发和部署RAG到生产环境时面临的挑战:
- 低可观测性:监控RAG管道中文档摄取速度和数据分布变化具有挑战性。由于RAG应用中的向量数据库通常存储数十亿份文档,跟踪数据变化和更新对于知识管理变得困难。
- 生命周期管理:有效的版本控制和生命周期管理对于跟踪数据变化和更新至关重要。团队需要强大的工具来透明且可审计地追溯数据血统,以确保合规性。
- 延迟和优化:虽然先进的微调和递归检索可以提高生成输出的准确性,但它们也可能增加响应时间,导致更高的延迟和用户满意度降低。
- 对查询的上下文响应:复杂的用户查询可能难以被LLM准确解释,导致缺乏上下文或细微差别的响应。
- 数据隐私:AI治理是另一个挑战,特别是在训练中使用的数据添加掩码或加密时。
- 持续学习机制:Lisa强调了保持RAG应用与新鲜数据更新的重要性。“访问持续更新数据的模型与依赖过时数据的模型之间存在巨大差异,”她指出。然而,实施持续学习机制在技术上可能具有挑战性。
- 供应商锁定:严重依赖单一云服务提供商的管道需求可能导致供应商锁定,使得转移到另一个生态系统变得困难且成本高昂。
导致这些挑战的根本问题之一是组织中数据孤岛的存在。
组织中的数据孤岛:RAG挑战的关键因素
数据孤岛是组织中的一个常见问题,由于结构或技术障碍,数据在不同团队或部门之间不易访问。这些孤岛可能存在于运营层面、不同团队之间,或由于使用的工具和应用程序的复杂性而产生。
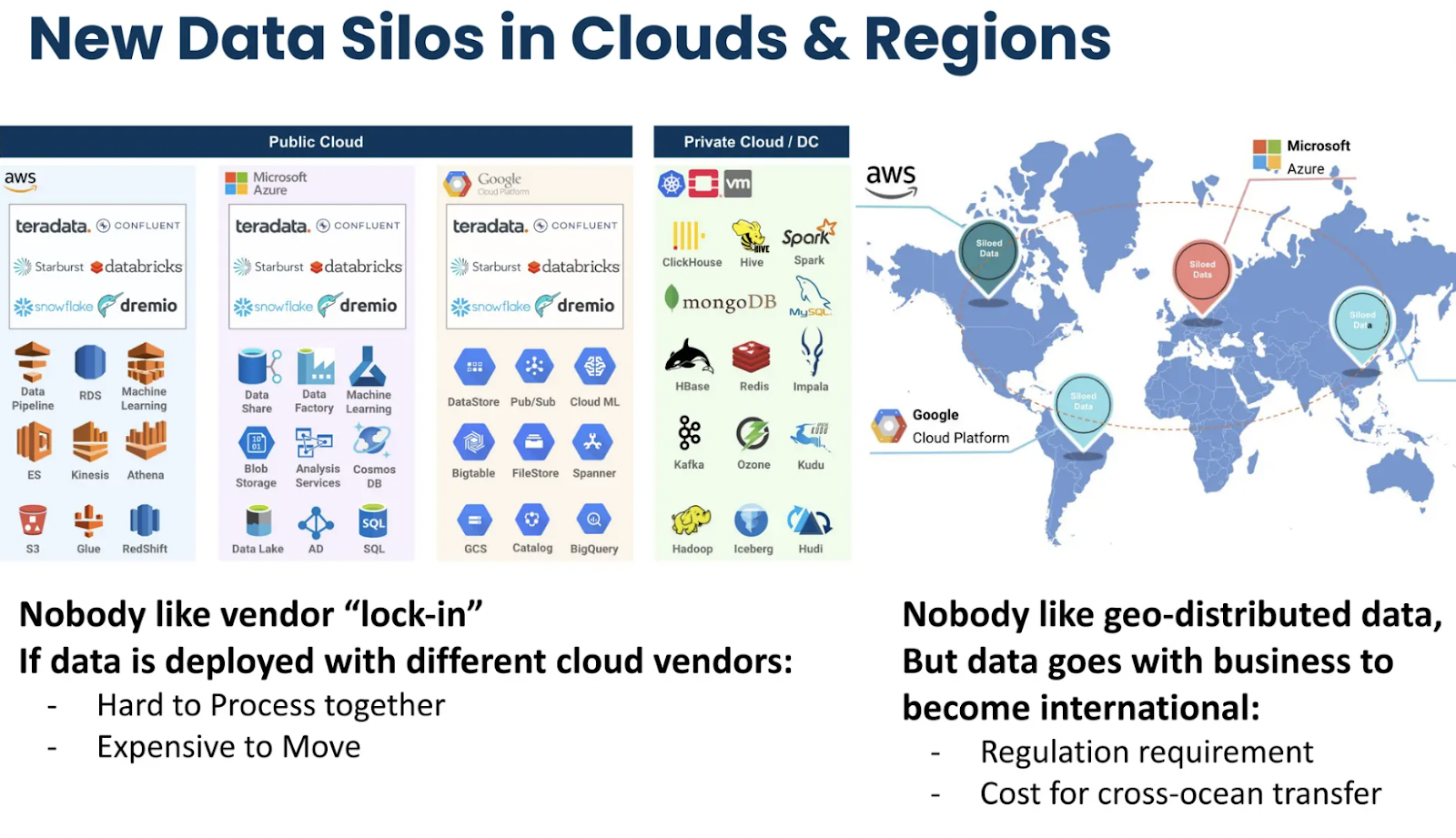 Figure_2_Data_Silos_Impacting_Efficiency_in_Organizations_5ff111f699.png
Figure_2_Data_Silos_Impacting_Efficiency_in_Organizations_5ff111f699.png
图2 数据孤岛影响组织效率
Lisa强调了数据孤岛的普遍问题,指出:“每家公司都在试图解决这个问题:‘我们如何在组织中创建数据的运营一致性?’”当团队全球分布并与不同的数据存储工作时,这尤其具有挑战性。
不同团队之间也存在孤岛。例如,BI分析师和数据工程师经常使用不同的工具,可能缺乏有效的沟通。一些团队可能没有访问和处理可用数据的编程知识或技术技能。例如,DevOps工程师可能难以理解ML工程师的代码库。
数据孤岛直接影响构建和维护有效的RAG管道的能力,因为它们阻止了组织内数据的无缝流动。这种缺乏整合可能导致数据源的碎片化、数据使用不一致,最终导致部署依赖全面和当前数据的RAG系统的挑战。
元数据湖:弥合统一数据管理的差距
为了解决上述RAG挑战,企业需要数据架构解决方案来统一、标准化和运营化组织内的数据。元数据湖提供了一个灵活的架构,用于存储和管理元数据——关于数据源、结构、格式、使用、血统等的信息。
什么是元数据湖?
元数据湖,或数据湖元数据管理,是一个集中存储组织中各种来源元数据的仓库。元数据是提供数据湖中数据上下文和理解的描述性信息。它通常包括数据源、质量、血统、所有权、内容、结构和上下文等详细信息。
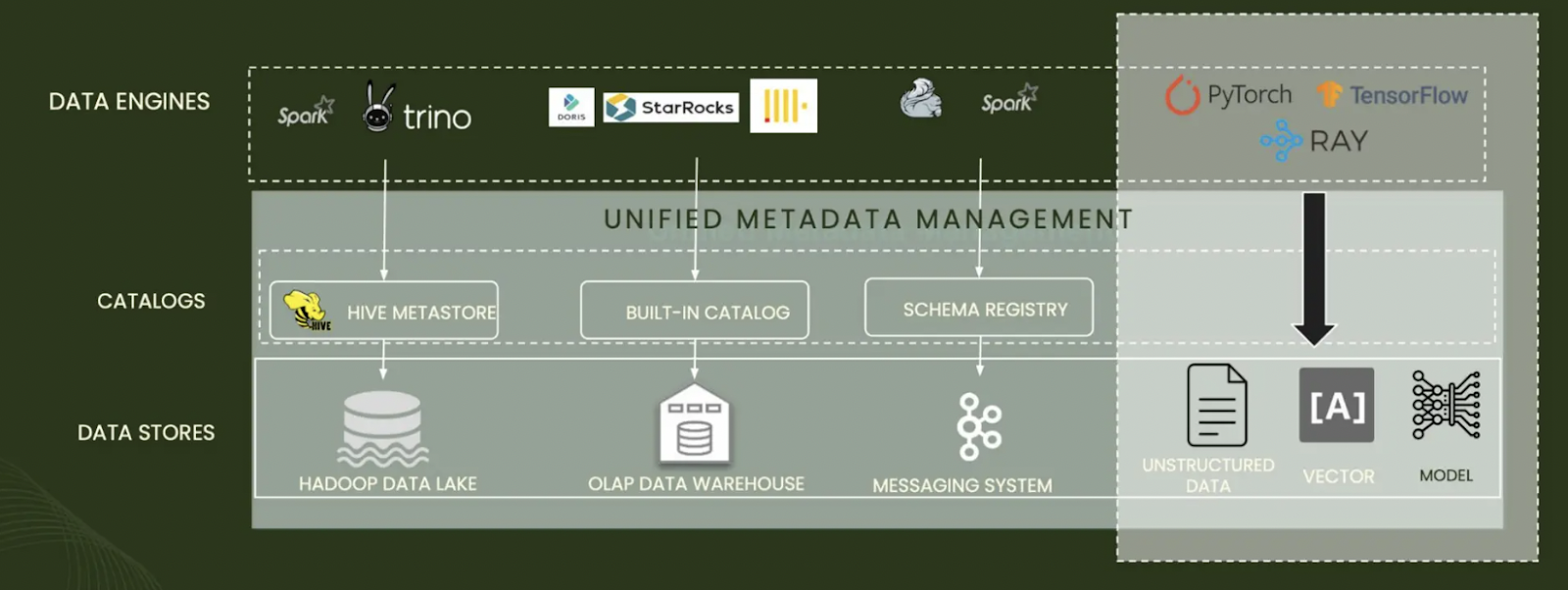 Figure_3_A_unified_metadata_management_db08079599.png
Figure_3_A_unified_metadata_management_db08079599.png
图3 统一元数据管理
与传统数据湖存储原始数据不同,元数据湖专注于管理、组织和使不同系统、数据库和应用程序中的数据资产相关的元数据可访问。
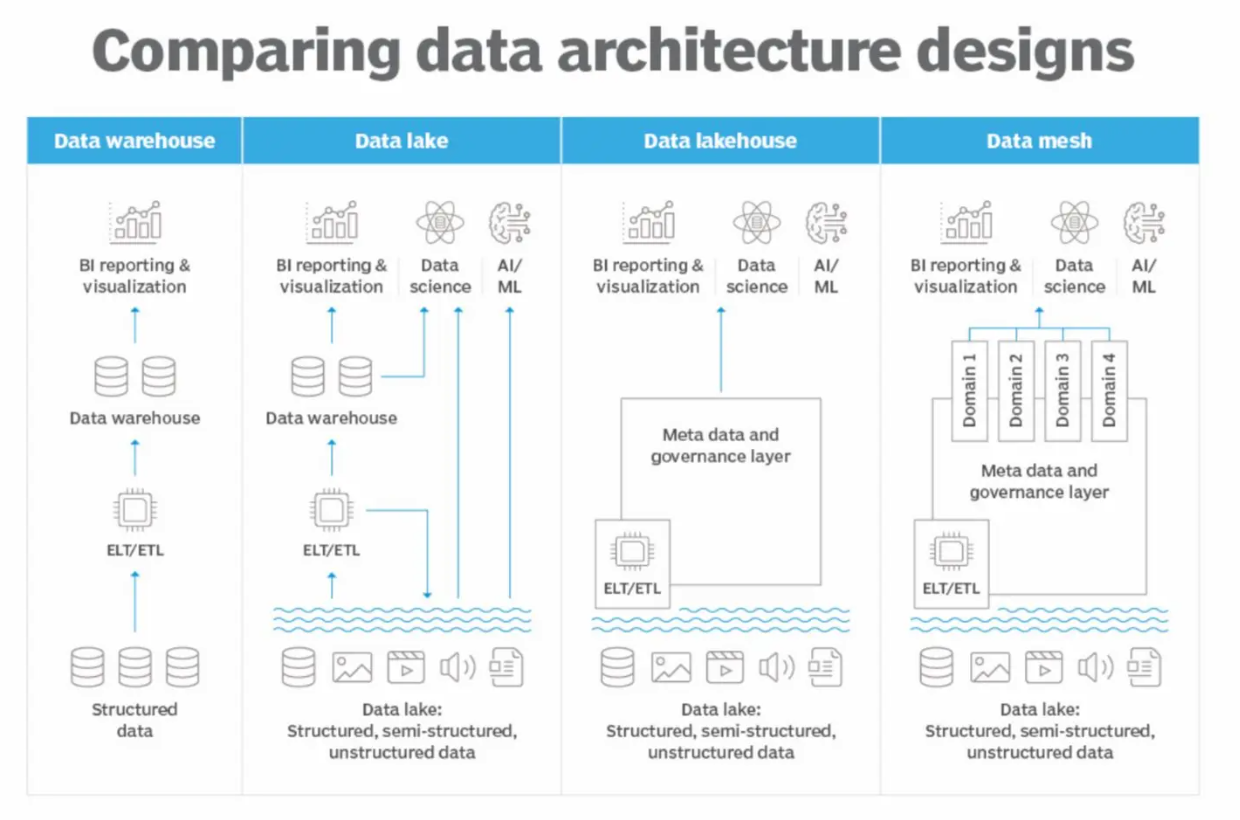 Figure_4_Comparing_different_data_architecture_designs_b38dff5a67.png
Figure_4_Comparing_different_data_architecture_designs_b38dff5a67.png
图4 不同数据架构设计的比较
元数据湖的好处
- 改善数据发现性:元数据湖作为集中目录,存储所有元数据,使团队和用户更容易在组织中发现数据资产。
- 活跃元数据:这些湖泊启用活跃元数据,可以触发操作并与编排管道集成,自动化任务并减少手动干预的需求。
- 嵌入式元数据:元数据可以嵌入不同的应用程序中,促进数据生态系统中的无缝集成和交互。
- 增强AI治理:集中元数据管理使得实施一致的治理政策更容易,确保合规性和数据质量。元数据湖还支持详细的数据血统跟踪、访问控制和审计能力。
- 丰富的元数据利用:统一的元数据管理允许更丰富的元数据利用,如丰富、数据掩码和分类,增强数据质量、安全性和可用性。
总体而言,元数据湖简化和自动化了数据生命周期管理,使技术团队之间的协作更容易,并帮助消除阻碍RAG开发的数据中心。
演示:使用Gravitino构建元数据湖
Lisa分享了她在一个开源项目中的经验,该项目使用Gravitino开发了元数据湖。该项目旨在创建一个支持多个云服务提供商的数据目录,包括AWS、Azure和GCP。它允许用户将各种数据源注册到元数据湖中,如S3存储桶、Milvus向量数据库、HiMetastores和其他数据存储。Gravitino还提供访问控制和工具,用于跟踪数据血统和促进审计。
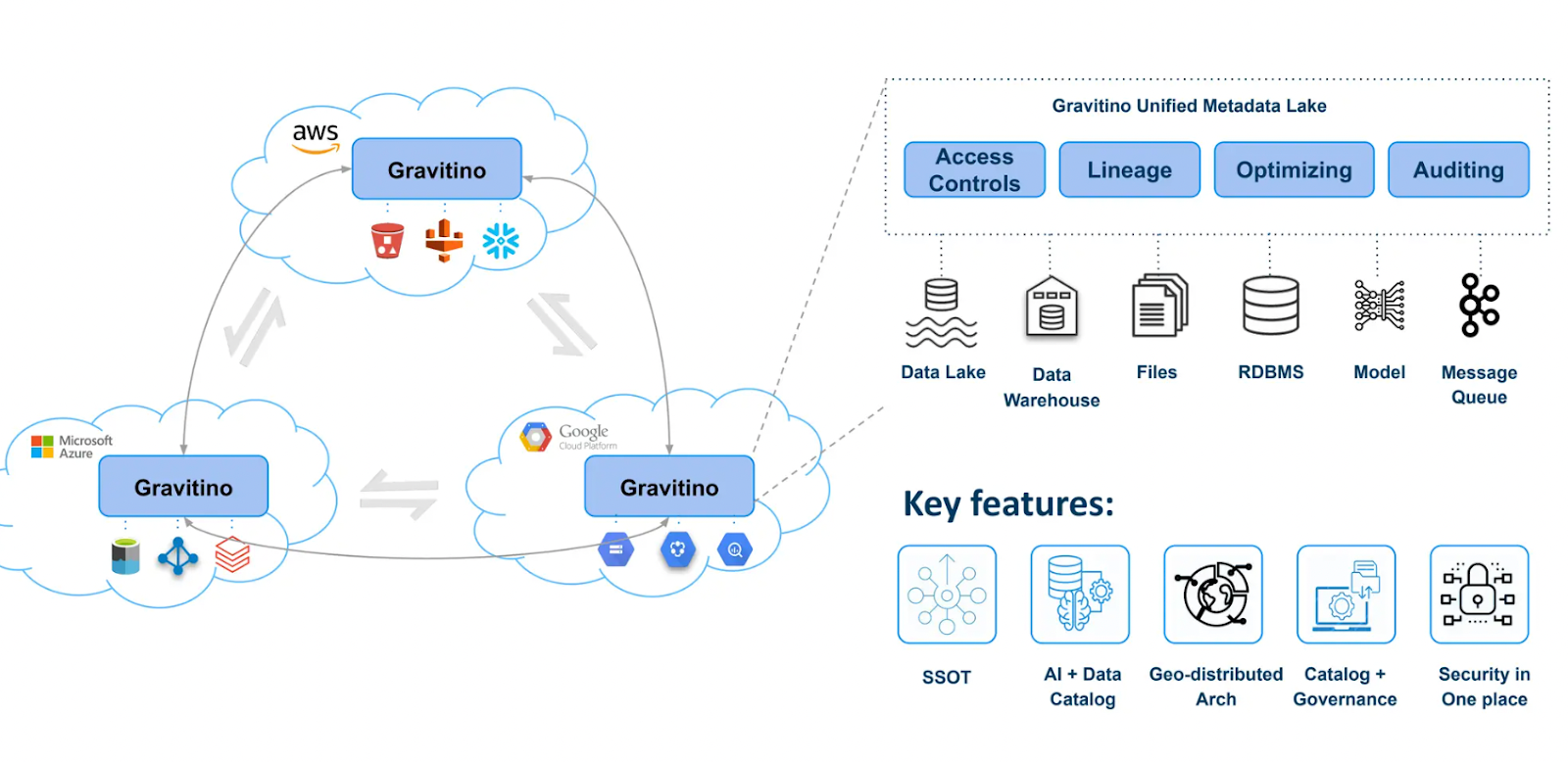 Figure_5_The_metadata_lake_architecture_built_with_Gravitino_0b2e70f765.png
Figure_5_The_metadata_lake_architecture_built_with_Gravitino_0b2e70f765.png
图5 使用Gravitino构建的元数据湖架构
该架构使用REST API为不同应用程序提供元数据。连接层在将所有数据存储到元数据湖之前,将其转换为通用模式。Gravitino支持表格和非表格数据格式,并允许基于标签的掩码以确保数据安全。
AI团队还可以在元数据管理框架内集成知识图谱和向量存储,创建统一目录。由于目录的联合性质,查询可以访问元数据而不需要移动源数据。联接操作发生在内存中或在定义的位置,优化性能并维护分布式环境中的数据完整性。
结论
元数据湖正在发展成为管理元数据并与AI和ML工作流程集成的AI目录。这些湖泊可以协助RAG开发、模型注册、AI治理和实施高级分析。通过为数据操作提供统一的平台,元数据湖使团队能够保持元数据分析的可观测性,确保在不同云环境和数据源(如Milkus向量数据库)之间平滑过渡,并无缝维护治理框架。随着AI技术的推进,元数据湖将在支持下一代AI/ML应用中发挥关键作用。
 Fendy Feng
Fendy FengTechnical Marketing Writer
- ShriVarsheni R
Freelance Technical Writer


