探索构建高效检索增强生成(RAG)的三大关键策略
检索增强生成(RAG)是一种有用的技术,可让您在AI驱动的聊天机器人中使用自己的数据。在这篇博客文章中,我将向您介绍三种关键策略,以充分利用RAG:
- 智能文本分块 📦:第一步是将您的文本数据分解成有意义、可管理的块。这一步确保您的向量数据库能够快速准确地检索到最相关的信息。
- 尝试不同的嵌入模型 🔍:迭代嵌入模型至关重要。嵌入模型决定了您的数据如何以向量的形式表示。向量是AI的通用语言,增强了向量数据库检索正确信息片段的能力。
- 尝试不同的LLM或生成模型 🧪:每个语言模型(LLM)API的成本、延迟和准确性都不同。测试它们可以让您选择最适合您工作负载的模型。
让我们深入探索这些策略如何工作,以及您如何通过评估来确定最适合您实际RAG应用的最佳配置!🚀📚
智能文本分块
文本分块就像将一个长故事切成更小的、易于消化的片段,这样计算机在回答问题或协助任务时可以轻松找到并使用最重要的部分。
下面,我将解释一些不同的技术。这些技术在Greg Kamradt的这篇原创文章中有很好的深入解释。
- 递归字符文本分割 🔄:根据字符数将文本分解成块,确保每个片段都是可管理且连贯的。
- 从小到大的文本分割 📏:从较大的块开始,逐步将它们分解成较小的块。使用小的进行搜索,但使用大的进行检索。
- 语义文本分割 🧠:根据含义划分文本,使每个块代表一个完整的想法或主题,确保上下文得以保留。
这些方法将帮助您有效地组织和检索各种应用的文本。深入了解每种技术的工作方式!
递归字符文本分割 🔄
首先使用LangChain的RecursiveCharacterTextSplitter将文本分割成固定大小的块,具有固定大小的重叠。
from langchain.text_splitter import RecursiveCharacterTextSplitter
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)print(f"chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# The splitter to use to create smaller (child) chunks.
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap,
length_function = len, # use built-in Python len function
separators = ["\n\n", "\n", " ", ". ", ""], # defaults
)
# Child docs directly from raw docs
sub_docs = child_text_splitter.split_documents(docs)
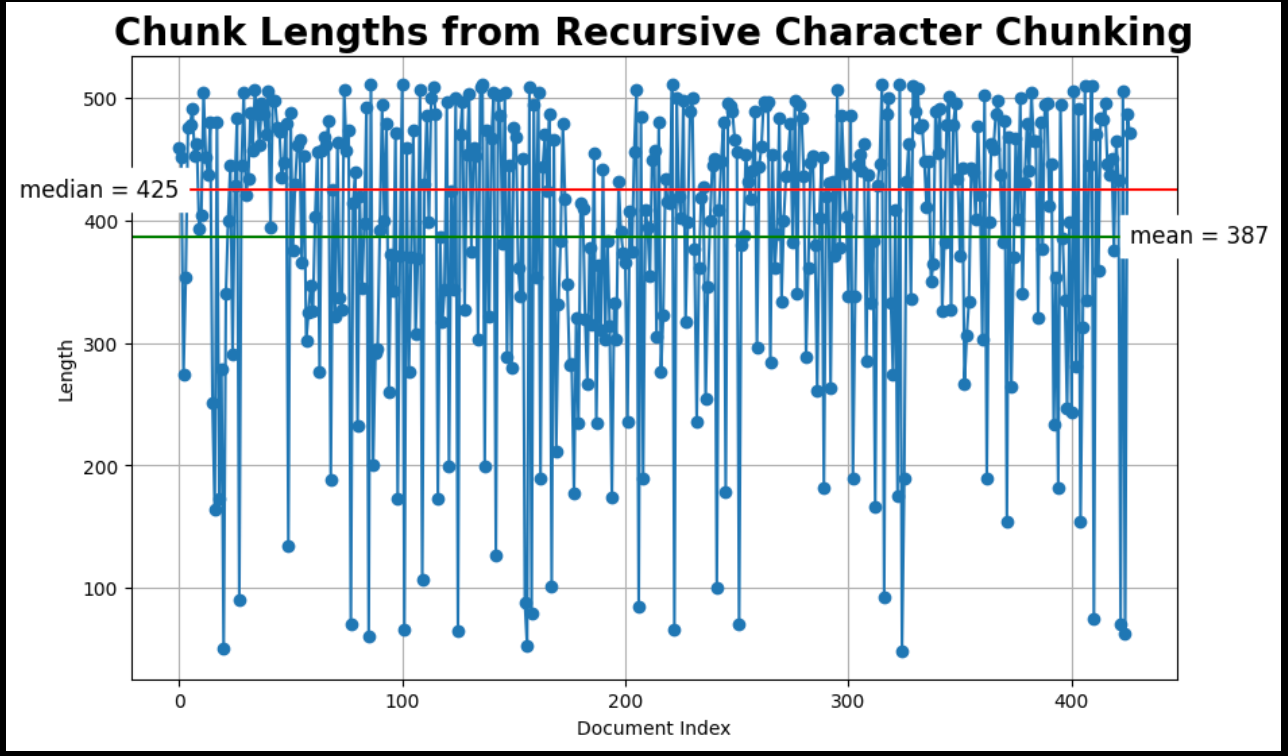
# Inspect chunk lengthsprint(f"{len(docs)} docs split into {len(sub_docs)} child documents.")
plot_chunk_lengths(sub_docs, 'Recursive Character')
 chunk_size_ce4ab84ab0.png
chunk_size_ce4ab84ab0.png
 chunk_lengths_from_recursive_character_chunking_6a5d5592f6.png
chunk_lengths_from_recursive_character_chunking_6a5d5592f6.png
从小到大的文本分割 📏
这种技术使用小(子)块进行搜索,但使用大(父)块进行文本检索。使用两个存储库:1)文档存储和2)向量存储。下面的代码使用了LangChain的MultiVectorRetriever。
from langchain_milvus import Milvus
from langchain.text_splitter import RecursiveCharacterTextSplitter
import uuid
from langchain.storage import InMemoryByteStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
# Create doc storage for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"
# Create vectorstore for vector index and retrieval.
COLLECTION_NAME = "MilvusDocs"
vectorstore = Milvus(
collection_name=COLLECTION_NAME,
embedding_function=embed_model,
connection_args={"uri": "./milvus_demo.db"},
auto_id=True,
# Set to True to drop the existing collection if it exists.
drop_old=True,
)
# The MultiVectorRetriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
PARENT_CHUNK_SIZE = 1586
# The splitter to use to create bigger (parent) chunks
parent_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=PARENT_CHUNK_SIZE,
length_function = len, # use built-in Python len function
# separators=["\n\n"], # split at end of paragraphs
)
# Parent docs directly from raw docs
parent_docs = parent_text_splitter.split_documents(docs)
doc_ids = [str(uuid.uuid4()) for _ in parent_docs]
# Inspect chunk lengths
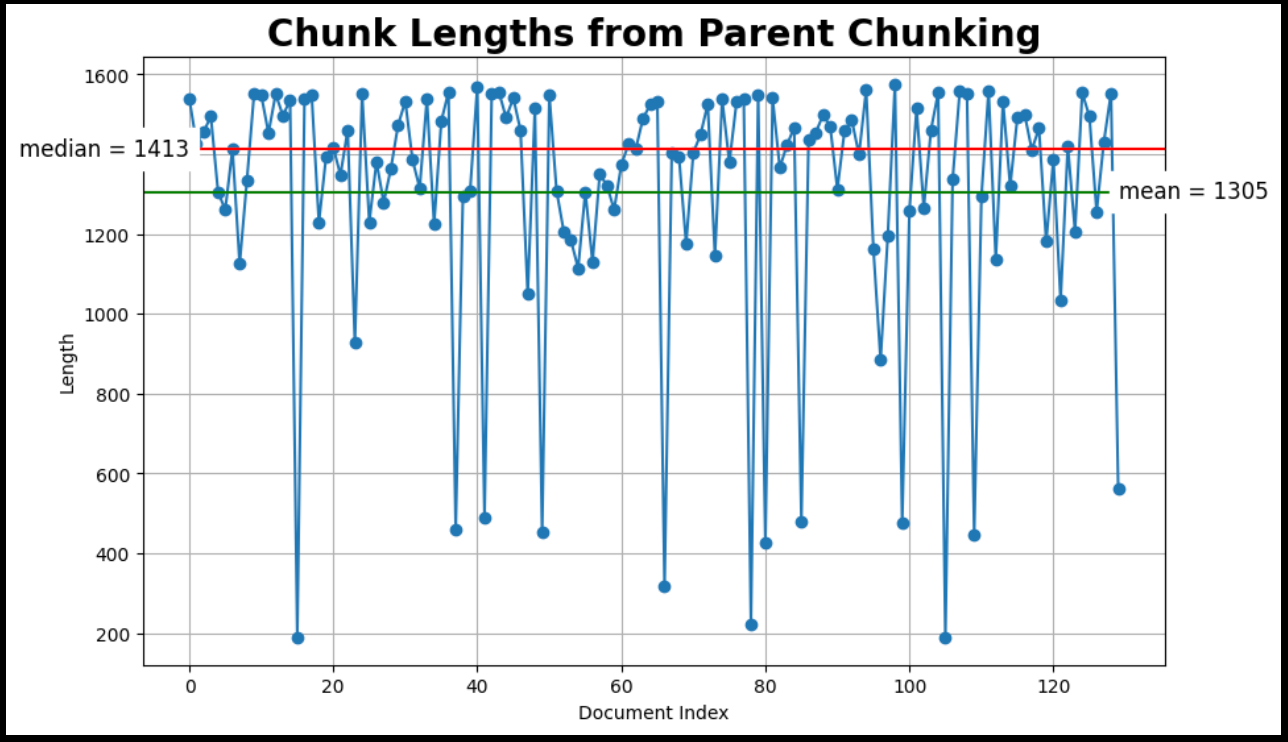
print(f"{len(docs)} docs split into {len(parent_docs)} parent documents.")
plot_chunk_lengths(parent_docs, 'Parent')
 22_docs_split_ced250c9a9.png
22_docs_split_ced250c9a9.png
 chunk_lengths_from_parent_chunking_4238efa928.png
chunk_lengths_from_parent_chunking_4238efa928.png
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f"chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# The splitter to use to create smaller (child) chunks.
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap,
length_function = len, # use built-in Python len function
separators = ["\n\n", "\n", " ", ". ", ""], # defaults
)
# Child docs directly from parent docs
sub_docs = child_text_splitter.split_documents(parent_docs)
# Inspect chunk lengths
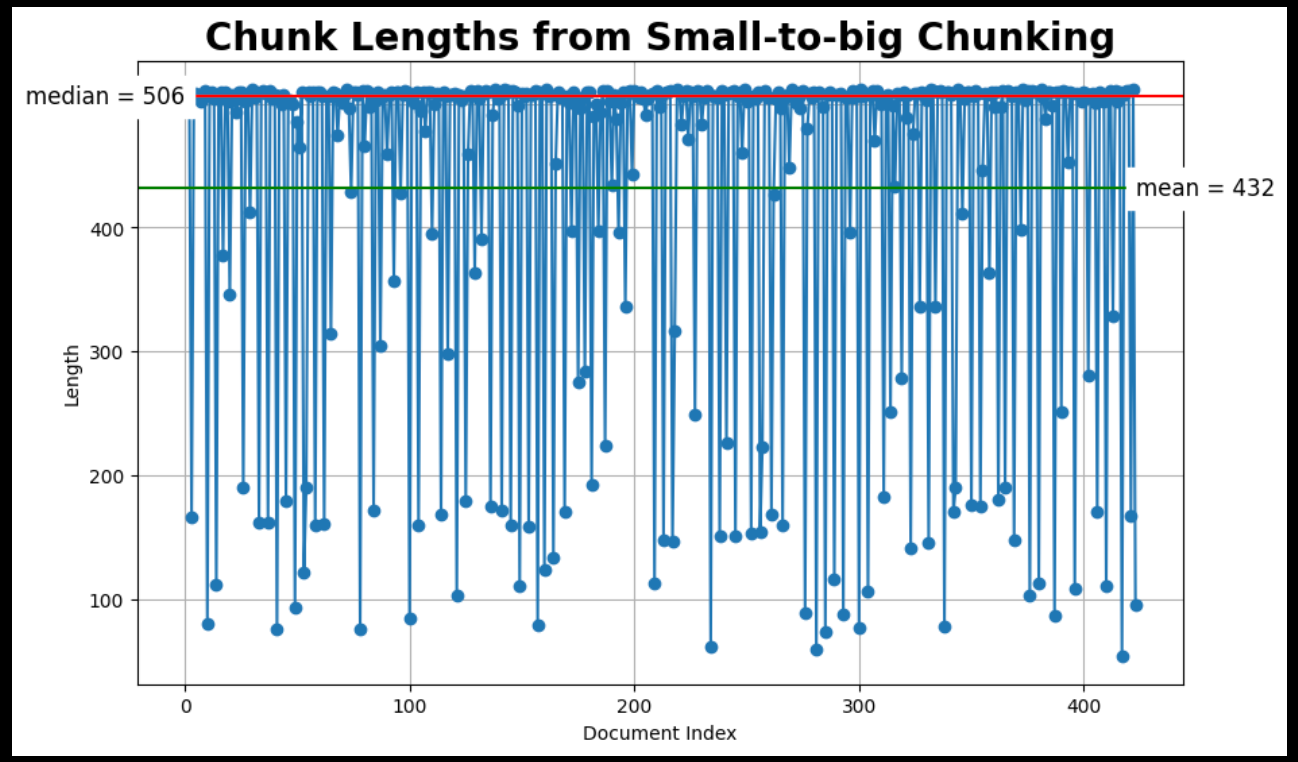
print(f"{len(docs)} docs split into {len(sub_docs)} child documents.")
plot_chunk_lengths(sub_docs, 'Small-to-big')
 512_chunk_size_1c74ee0b0a.png
512_chunk_size_1c74ee0b0a.png
 small_to_big_chunking_a83dd6f5c7.png
small_to_big_chunking_a83dd6f5c7.png
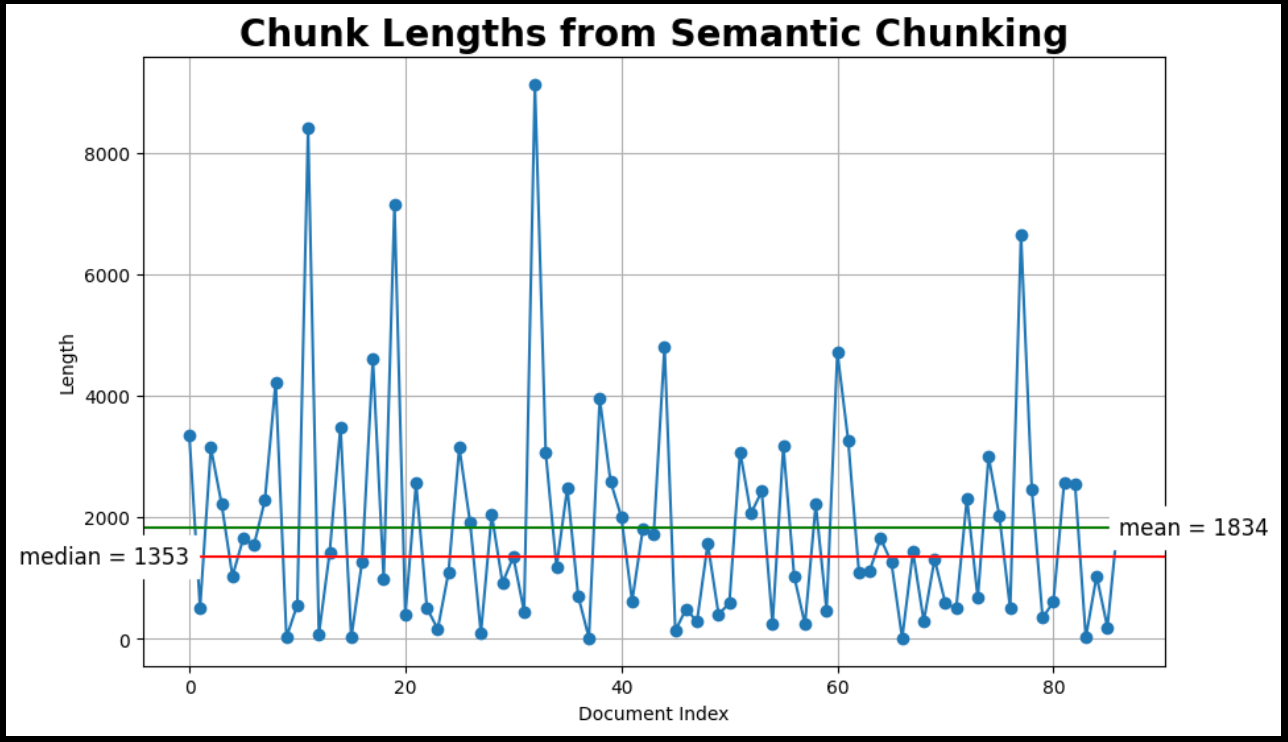
语义文本分割 🧠
这种分块器通过确定何时“拆分”句子来工作。它通过计算相邻句子之间的余弦距离来完成这项任务。在查看所有这些余弦距离时,它寻找超过某个阈值的异常距离。这些异常距离决定了块何时被拆分。
确定阈值有几种方法,这些方法由breakpoint_threshold_type关键字参数控制。
from langchain_experimental.text_splitter import SemanticChunker
semantic_docs = []for doc in docs:
# Extract and clean document content.
cleaned_content = clean_text(doc.page_content)
# Initialize the SemanticChunker with the embedding model.
text_splitter = SemanticChunker(embed_model)
semantic_list = text_splitter.create_documents([cleaned_content])
# Append the list of semantic chunks to semantic_docs.
semantic_docs.extend(semantic_list)
# Inspect chunk lengthsprint(f"Created {len(semantic_docs)} semantic documents from {len(docs)}.")
plot_chunk_lengths(semantic_docs, 'Semantic')
 87_semantic_docs_5b4339396f.png
87_semantic_docs_5b4339396f.png
 chunk_lengths_from_semantic_chunking_f74c90deb0.png
chunk_lengths_from_semantic_chunking_f74c90deb0.png
我们将使用Milvus文档作为我们的数据,并使用Ragas作为您的RAG评估方法。阅读我的博客,了解如何使用RAGAS。
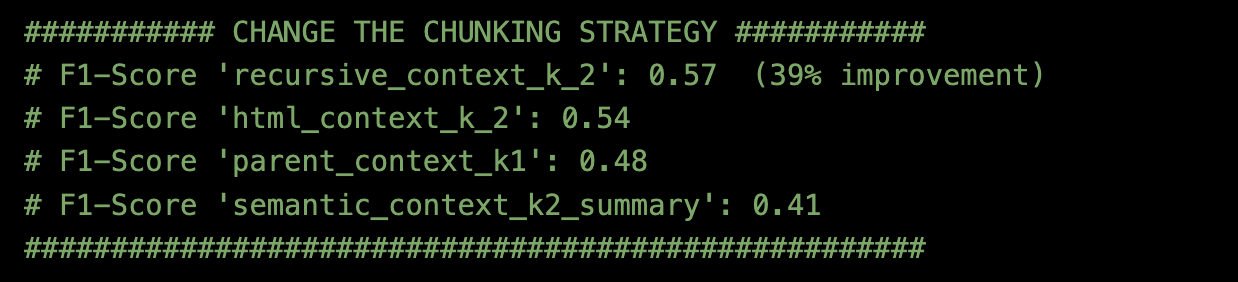
结果是:
分块方法 = 使用top_k=2的递归字符文本分割器是最好的。
 change_chunking_strategy_441b0bb82c.png
change_chunking_strategy_441b0bb82c.png
不同的嵌入模型
将分块方法固定为使用top_k=2的递归字符文本分割器,我尝试了两种不同的嵌入模型。
- BAAI/bge-large-en-v1.5
- Text-embedding-3-small with embedding-dim = 512
使用Milvus文档和评估方法Ragas,结果是:
嵌入模型 = BAAI/bge-large-en-v1.5是最好的。
change_chunking_strategy_441b0bb82c.png
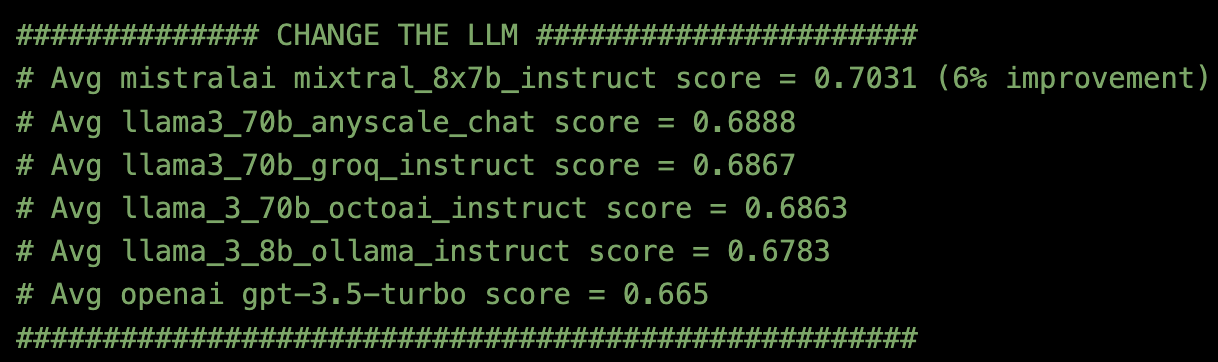
不同的LLM
在将分块方法固定为使用top_k=2的递归字符文本分割器,并将嵌入模型设置为BAAI/bge-large-en-v1.5之后,我尝试了六个不同的LLM API端点。
 change_the_llm_102a4531d7.png
change_the_llm_102a4531d7.png
使用Milvus文档和评估方法Ragas,结果是:
LLM = 使用Anyscale端点的MirstralAI mixtral_8x7b_instruct是最好的。
结论
RAG管道评估将根据您的特定数据和用例而有所不同。根据个人经验和文献,最关键的一点改进通常来自于完善您的检索策略。🛠️
使用Milvus文档数据和Ragas评估,本博客观察到:
- 通过改变分块策略提高了35%的性能 📦
- 通过改变嵌入模型提高了27%的性能 🔍
- 通过改变LLM模型提高了6%的性能 🤖
迭代这些元素可以帮助优化您的RAG管道,以获得更好的结果!
注:本文为AI翻译,查看原文
 Christy Bergman
Christy Bergman