



人工智能中的密集向量:在机器学习中最大化数据潜力
密集向量简介
机器学习需要数据以适合算法处理的格式存在,通常将原始输入转换为数值向量。将原始数据转换为向量,这些向量是高维数组,因此成为ML算法的一个重要组成部分。在这方面,我们看到两种常见的向量表示:稀疏和密集。而稀疏向量主要由零填充,侧重于元素的缺失,密集向量则紧凑且提供丰富的表示。
密集向量是将复杂数据编码为高维数值表示的基础。本文聚焦于密集向量,揭示了它们相比稀疏向量的优势以及它们如何在各个领域的ML算法中被广泛使用。
理解密集向量
在机器学习中,密集向量是每个元素都持有重要值的数组。例如,“国王”可能代表一个3维的密集向量[0.2, -0.1, 0.8]。这个数组中的每个元素(例如,0.2, -0.1, 0.8)编码了从数据中学习到的语义和上下文特征。与大多数元素为零的稀疏向量不同,密集向量中的每个元素都是有意义的,并且对表示有所贡献。
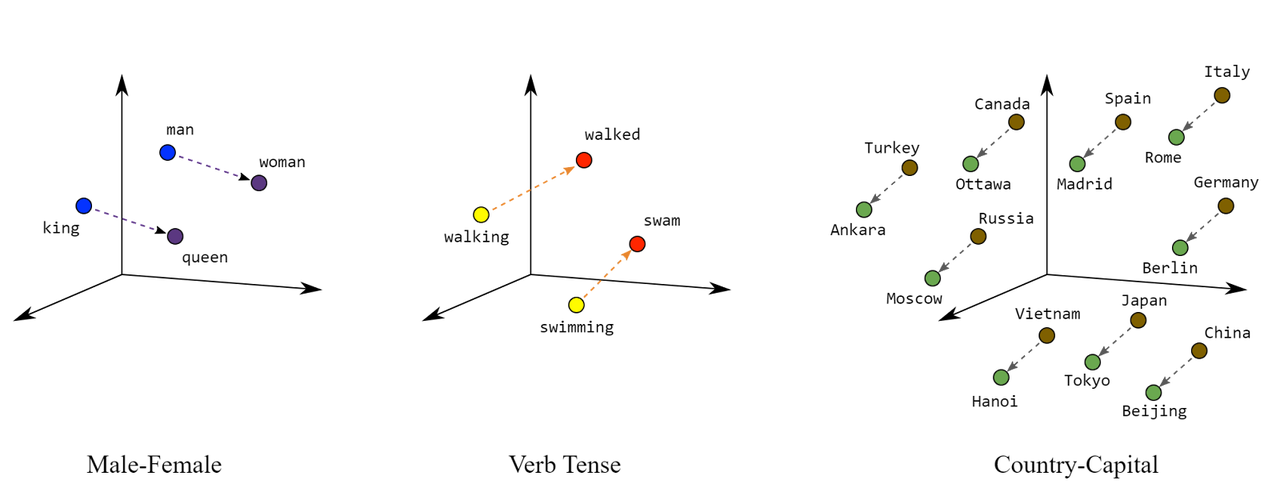
从数学上讲,密集向量占据高维空间,对这些数组进行向量加法或点积等操作可以捕捉数据之间的关系。在这个广阔的空间内,密集向量能够精确测量相似性和不相似性,从而促进了聚类、分类和回归等任务的准确性。例如,由于密集向量的存在,单词“国王 - 男人 + 女人 = 女王”的向量操作成为可能。
 18.1.PNG
18.1.PNG
图:密集向量可以捕捉各种语义关系。来源:Google Developers。
密集向量在AI中的作用
密集向量将复杂数据转化为丰富、详细的格式,AI模型可以轻松处理。无论是理解图像中的复杂模式还是预测聊天机器人中的下一个单词,密集向量都帮助AI系统变得更智能、更直观。在计算机视觉中,像视觉变换器(ViT)这样的模型利用密集向量将图像和文本编码到同一个向量空间中,实现了高相似性向量的图像-文本匹配。
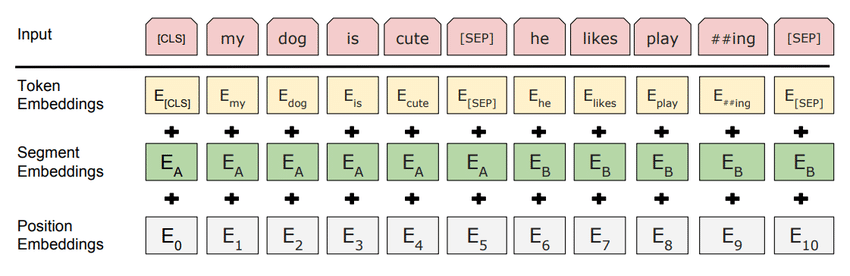
在自然语言处理(NLP)中,考虑Word2Vec:单词被转换为密集向量,因此“国王”和“女王”在向量空间中可能位置相近,准确反映了它们的语义关系。BERT进一步通过生成上下文感知嵌入来实现这一点。例如,“河岸”中的“银行”和“银行账户”将具有不同的向量,这些向量捕捉了单词的上下文含义,对于情感分析或语言翻译等任务至关重要。
 18.2.PNG
18.2.PNG
图:BERT嵌入利用密集向量转换文本输入。来源:BERT论文。
应用和用例
密集向量正在全面改变AI应用。在文本分类中,谷歌的T5模型采用密集向量,显著提高了搜索结果和语言理解的准确性。在文本生成中,像OpenAI的GPT-4这样的工具使用通过其神经网络处理的密集向量来理解和创造细腻的文本。推荐系统中的密集向量代表用户和项目在同一个向量空间中,使得高效的相似性计算成为可能,从而根据用户偏好和项目特性推荐产品。例如,Spotify的推荐系统利用密集向量来个性化音乐播放列表。
使用密集向量进行优化
使用密集向量嵌入优化AI模型涉及几个最佳实践。降维是关键;像PCA这样的方法有助于减少向量大小并保持基本信息,同时提高计算效率。向量归一化将向量标准化为一致的长度,这对于依赖距离计算的模型尤其重要。
微调嵌入使它们适应特定任务,在特定领域的上下文中特别有效。这里可以应用迁移学习,你可以将预训练的嵌入适应新数据,并以更经济、更快捷的方式提高模型准确性。
然而,计算效率挑战是显著的,特别是在高维向量和大型数据集的情况下。高效的算法和向量数据库可以减轻这个问题。虽然密集向量比稀疏向量更好地解决了数据稀疏性问题,但确保模型专注于相关特征仍然至关重要,避免过拟合。在这种情况下,像dropout和正则化这样的技术可以提供帮助。
未来趋势和创新
新兴的AI和机器学习趋势表明在利用密集向量方面取得了重大进展。我们正在见证创新的嵌入技术,这些技术增强了向量的表示能力。例如,从像Word2Vec这样的静态模型演变而来的上下文和动态嵌入,可以更准确地捕捉语言的细微差别。
像变换器模型(BERT、GPT)这样的技术已经彻底改变了密集向量理解上下文和语义的方式。
未来,我们可能会看到更复杂的嵌入技术,这些技术捕捉语言的细微差别并整合多模态数据,结合文本、图像和音频。这可能导致对复杂数据集更深入、更全面的理解。此外,未来的密集向量模型可能在跨不同领域和语言的知识转移方面变得更好。这将是创建需要较少特定领域训练数据的多功能AI系统的重要一步。
另一方面,在不丢失重要信息的情况下降低密集向量维度的进步可以使AI模型更高效,并使它们能够在资源受限的环境中部署。
总结密集向量
密集向量已经成为AI的基石,并显著提高了机器学习解决方案的有效性。这些向量捕捉数据中的复杂模式和细微差别,提供了从自然语言处理到医疗保健分析等各个领域的更全面理解。它们在推动创新和促进更细腻的AI算法方面的作用不容忽视。
对于寻求增强其AI举措的读者来说,整合密集向量嵌入至关重要。通过利用这项技术,你可以从原始、混乱的数据中解锁更深入的洞察力,并将你的项目推向新的表现高度。
 Nuri Tas
Nuri TasFreelance Technical Writer


