



揭秘 Transformer 模型:Transformer 架构和底层原理的研究
Transformer 模型的出现标志着现代自然语言处理(NLP)技术的一次重大进步。这个概念最初是针对机器翻译等任务而提出的,Transformer 后来被拓展成各种形式——每种形式都针对特定的应用,包括原始的编码器-解码器(encoder-decoder)结构,以及仅编码器(encoder-only)和仅解码器(decoder-only)等变体结构,满足不同的 NLP 任务。
本文将从基础的 encoder-decoder 架构开始介绍 Transformer 模型及其机制和能力。通过探索模型精巧的设计和计算过程,我们将揭秘为什么 Transformer 成为了现代 NLP 进步的基石。
Transformer 简介
自问世以来,Transformer 模型在 NLP 领域一直是一个颠覆性的存在。它以三种变体出现:encoder-decoder、encoder-only 和 decoder-only。最初的模型是 encoder-decoder 形式,这为我们提供了探索 Transformer 模型基础设计的全面视图。
自注意力机制(Self-attention mechanism)是 Transformer 架构的核心,最初主要是为语言翻译而开发的。以下是它的工作原理:一个句子被分解成片段,又称为 Token。这些 Token 通过 encoder 中的多个层进行处理。每一层都从其他 Token 中提取信息,通过自注意力机制丰富信息,使其富有更多的上下文线索,从而细化这些 Token。这个过程产生了更深层次、更有意义的 Token 表示或者称为 Embedding。
增强后,就可以将这些 Embedding 传递给 decoder。Decoder 的结构与 encoder 类似,使用自注意力和另一种称为交叉注意力(cross-attention)的额外组件。交叉注意力机制使得 decoder 访问并整合 encoder 输出中的相关信息,确保翻译的词对齐源上下文。
在实践中,翻译一个词需要从源句子中确定相关细节——特别是与目标词密切相关的 Token。然后解码器一次生成目标语言中的一个词,使用正在构建的句子的上下文作为指导,直到它遇到一个表示句子结束的特殊 Token。这种基于注意力的方法使模型能够产生不仅准确而且能够把握上下文中细微差别的翻译文本。
Transformer 模型架构
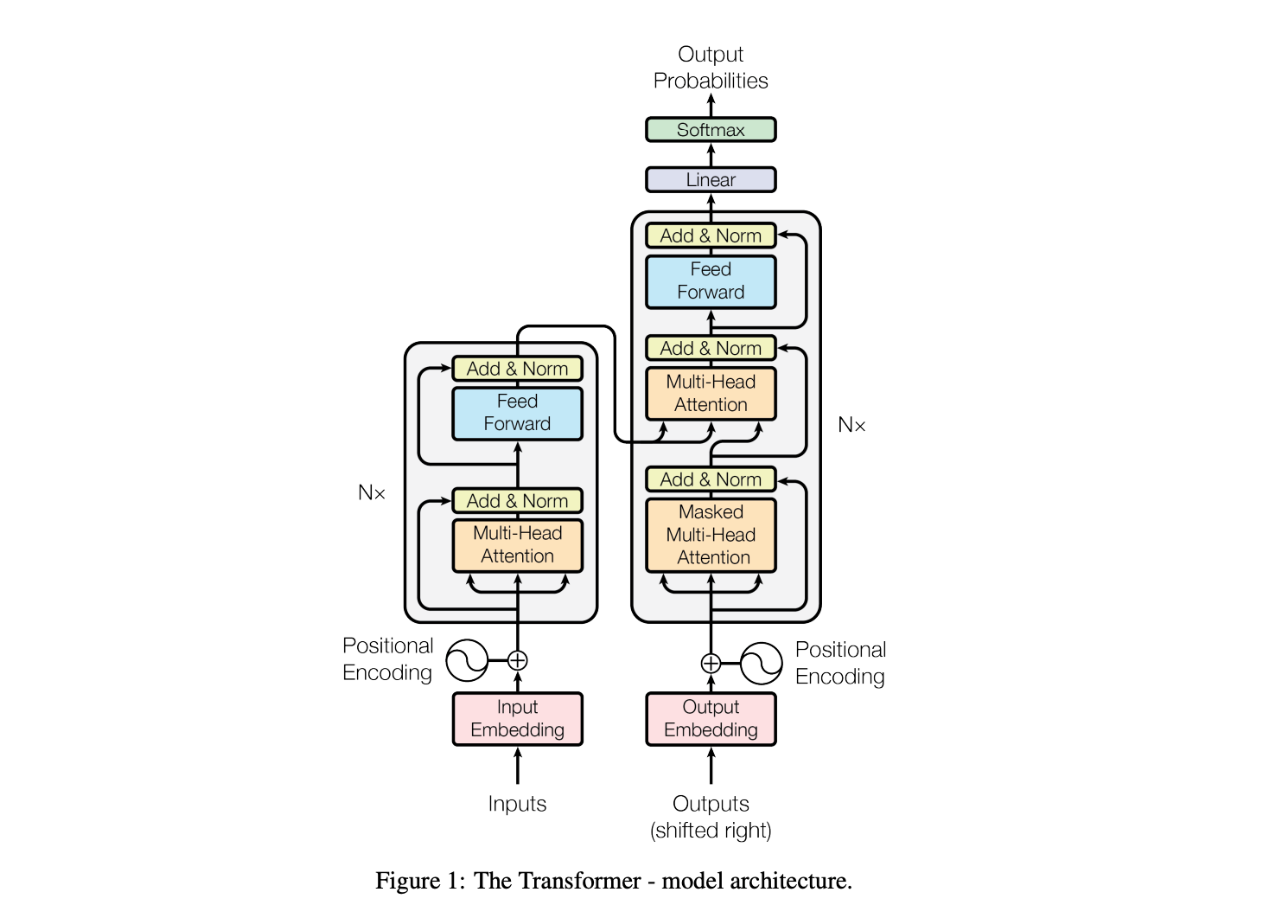
下图展示了 Transformer 模型的架构。
 the_architecture_of_a_Transformer_model_8c59616a06.png
the_architecture_of_a_Transformer_model_8c59616a06.png
在图片的左下角,Input 代表输入的源文本,通过一个 embedding 层转换成输入 embedding。这个 embedding 层就像一个字典,为每个 token 查找一个对应的向量。获得 token embedding 之后,会加上位置编码(positional encoding)。这个位置编码帮助模型理解 token 的相对位置。这对于注意力机制至关重要,因为模型本身并不天生感知 token 顺序,而token顺序是处理语言的一个关键因素。
接下来,token embedding 和位置编码进入多头注意力(Multi-Head Attention)模块。这个模块允许模型同时关注输入序列的不同部分。在注意力机制之后应用了残差连接(residual connection)和 Add & Norm 层。这些结构和技术能够有效防止梯度消失从而帮助模型训练收敛,使得能够进行更深层的网络训练。你会注意到这些结构在模型的其他部分也同样出现。
多头注意力的输出随后通过前馈(Feed-Forward)模块。这个前馈网络对每个 embedding 单独地应用相同的非线性激活层,使 embedding 的表达能力更强,更适应当前处理的任务。 Encoder 网络左侧的 "N×" 符号表示这是一个多层架构——每一层的输出成为下一层的输入。
在图片的右侧是 decoder,它与 encoder 采用类似的架构。然而,这里也有一些关键的不同点。decoder 包括一个遮蔽多头注意力(Masked Multi-Head Attention)层,确保每个 embedding 只能关注更早的位置,防止来自未来 token 的信息泄露到当前位置。此外,decoder 利用交叉注意力机制关注 encoder 输出的 embedding,从而对齐源语言的上下文与生成的目标语言。
最后,经过 decoder 后,输出 embedding 通过 softmax 层转换成概率,预测目标序列中的下一个词。这个生成过程一直重复生成一个个token,直到生成一个通常标志着句子结束的特殊 token。
理解 Encoder 的核心概念
Encoder 中包含多个模块,让我们了解一下这些模块。
缩放点积注意力(Scaled Dot-Product Attention)
多头注意力(Multi-Head Attention, MHA)的核心是缩放点积注意力机制。为了更好地理解 MHA,我们需要先解释 Scaled Dot-Product Attention 这个概念。
从字面意义上,注意力意味着每个 embedding 需要关注相关的 embedding 从而收集上下文信息。在注意力计算中有三个角色:查询(Queries, Q)、键(Keys, K)和值(Values, V)。假设你有 N 个查询 embedding 和 M 对键值对。以下是注意力机制的计算方式:
相关性计算:计算每个查询 embedding 与每个键 embedding 的相关性。这通常是通过查询embedding和每个键embedding之间的点积(dot product)来完成的。
归一化:然后对这些计算结果进行归一化。这一步确保所有相关性得分的总和为一,从而得到比例表示,其中每个得分反映了查询与键之间的相关程度。
上下文表示:最后,每个查询 embedding 被重新组合成一个新的带有上下文信息的表示。这是通过结合与每个键相对应的值 embedding 来实现的,权重由归一化的相关性得分决定。
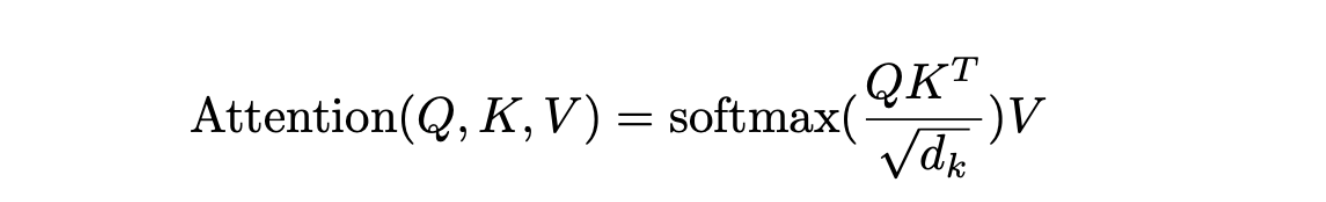 Scaled_Dot_Product_Attention_formula_968559b130.png
Scaled_Dot_Product_Attention_formula_968559b130.png
上述公式定义了缩放点积注意力(Scaled Dot-Product Attention):所有 N 个查询 embedding(维度为 d)被堆叠成一个 N×d 的矩阵 Q。同样,K 和 V 分别是 M×d 的矩阵,代表 M 个键 embedding 和值 embedding。通过矩阵乘法,我们得到一个 N×M 的矩阵,其中每一行对应于一个查询 embedding 与所有 M 个键 embedding 的相关性。然后我们通过 softmax 操作来归一化这些行,确保每个查询的相关性得分总和为 1。接下来,我们将这个归一化的得分矩阵与 V 矩阵相乘,以获得上下文化的表示。
另外,需要注意的是,注意力得分通过 √dk 进行缩放。原作者解释说,维度越高,点积得分越大,这可能会使 softmax 函数不平均地给单个键分配过高的注意力。为了缓解这个问题,点积通过 √dk 进行缩放,从而得到更平衡的注意力权重。
多头注意力(Multi-Head Attention)
 Multi_Head_Attention_0a27f16f44.png
Multi_Head_Attention_0a27f16f44.png
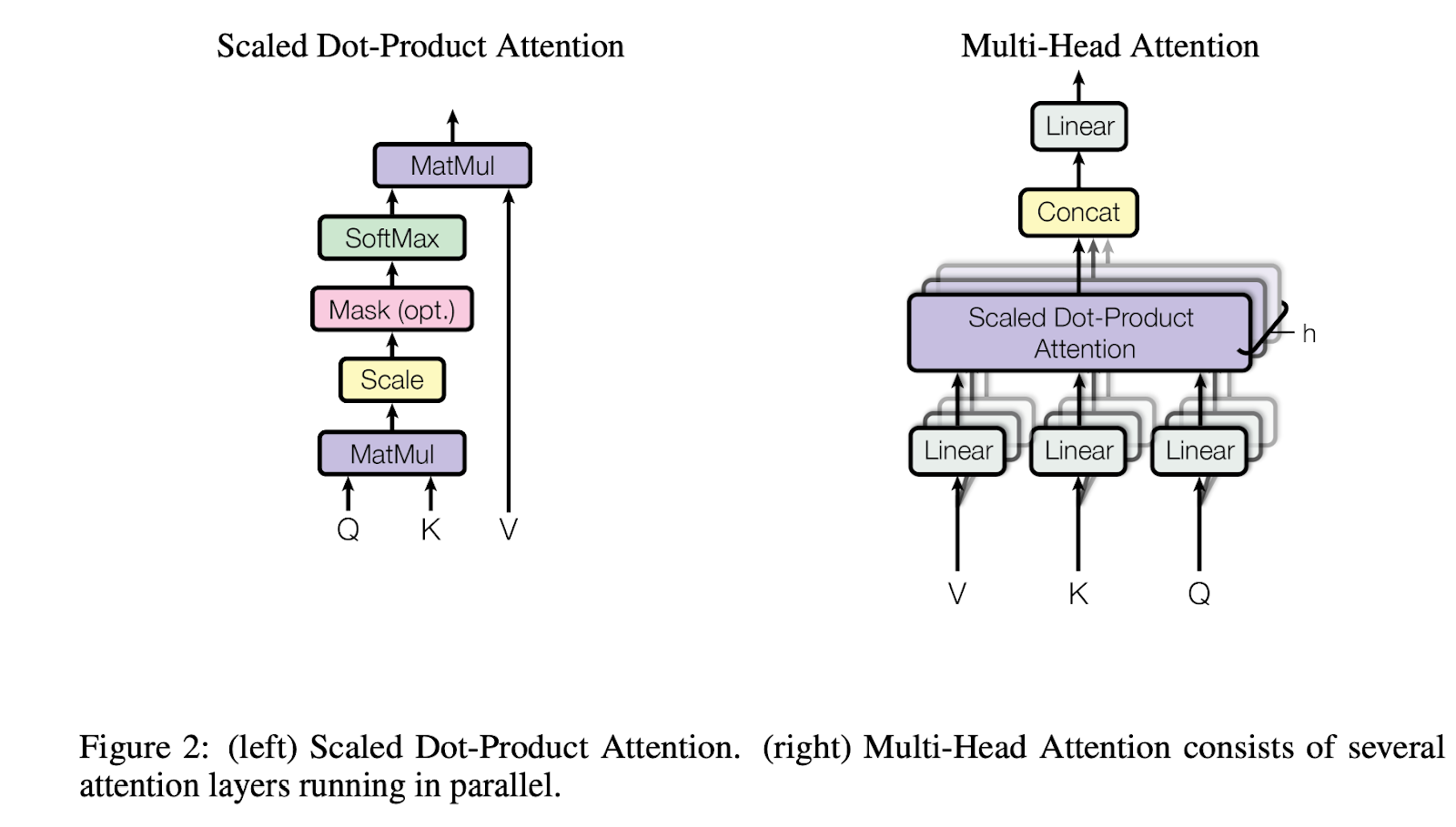
Transformer 模型采用了一种称为多头注意力的技术来增强其处理能力。这种机制首先通过线性层来转换注意力的组成部分——查询(Queries, Q)、键(Keys, K)和值(Values, V)。这种转换引入了额外的参数,增强了模型从更多数据中学习的能力,从而提高了其整体能力。
在多头注意力机制中,这些转换后的 Q、K 和 V 元素会经历缩放点积注意力(Scaled Dot-Product Attention)过程。原始设计规定了多个(通常是8个)并行的线性层和注意力层实例。这种并行处理不仅加快了计算速度,还引入了更多参数,进一步细化了 embedding。
每个并行实例为每个查询生成一个单独的转换后的 embedding,称为“头”(head)。有8个这样的头,假设每个头的维度为 ,所有头的输出组合结果在总维度上为 。为了将这些结果能够重新映射成为下一层的输入,另一个线性层使用投影矩阵 投影这个连接(concatt)的输出,将其调整为模型指定的维度,。这种结构化的方法允许 Transformer 同时利用多个视角,显著增强了其识别和解释复杂数据的能力。
 Multi_Head_Attention_formula_a3522a6505.png
Multi_Head_Attention_formula_a3522a6505.png
在 Transformer 的多头注意力机制中,层 、 和 (其中 i 表示 8 个实例中的一个)是三个线性层,专门用于转换注意力计算的查询(Queries, Q)、键(Keys, K)和值(Values, V)。这些层将 embedding 投影到维度 、 和 ,通常这些维度是相同的。
注意力机制的核心思想是通过整合周围单词的上下文信息来增强每个单词的 embedding。例如,在将英语句子“Apple company designed a great smartphone.”翻译成法语时,单词“Apple”需要吸收来自相邻单词“company”的上下文。这帮助模型理解“Apple”是一个商业公司实体,而不是水果,从而不会翻译成为“pomme”,即字面上的苹果。这个过程被称为自注意力(self-attention)。
另一方面,在 Transformer 的 decoder 部分,使用了一种称为交叉注意力的技术。其中 decoder 关注来自 encoder 输出的不同信息片段,从而将源文本中相关上下文信息整合到翻译输出中。这种交叉注意力机制帮助 Transformer 模型有效理解翻译的细微语境区别,从而帮助更好的翻译。
位置编码(Positional Encoding)
一旦你熟悉了 Transformer 模型中的注意力机制,位置编码的概念就会变得更加直观。多头注意力的一个关键挑战是它本身并不考虑句子中单词的顺序。
以一个简单的句子为例:“Tim gives Sherry a book.” 在 MHA 中,对于“Sherry”的查询(Q)embedding 与其对应的键(K)和值(V)embedding 进行交互时,并没有意识到其在句子中的位置,从而导致“Tim gives Sherry a book”与“Sherry gives Tim a book”从注意力计算角度上来说是一致的。因此,单词出现的顺序对于理解它们的含义至关重要。
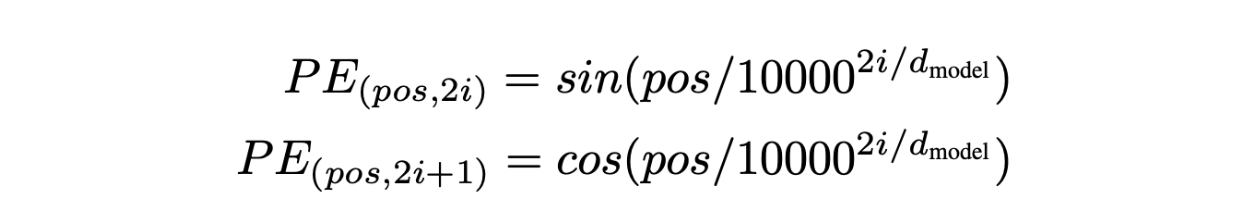 Positional_Encoding_formula_30d0acc74c.png
Positional_Encoding_formula_30d0acc74c.png
为了解决这个问题,作者修改了注意力计算,并引入了位置信息。例如,我们希望点积计算 能够反映它们的位置,变成 。
这种调整可以让模型识别并利用单词在句子中的位置。
位置编码是通过向每个 token 的 embedding 加上一个特殊的 embedding 来实现的。这个位置 embedding 具有相同的维度 ,并且为句子中的每个位置分配一个独特的编码。余弦和正弦函数分别为位置embedding的奇数和偶数索引的维度生成对应的值。这种方法确保了位置信息能够无缝地集成到基础 embedding 中,增强了模型根据单词顺序解释和生成文本的能力。
前馈网络(Feed Forward Network)
在多头注意力阶段之后,embedding 通过交互被精炼成包含上下文的表示,然后这些 embedding 会通过前馈网络(FFN)进行处理,以进一步增强它们的表示能力。
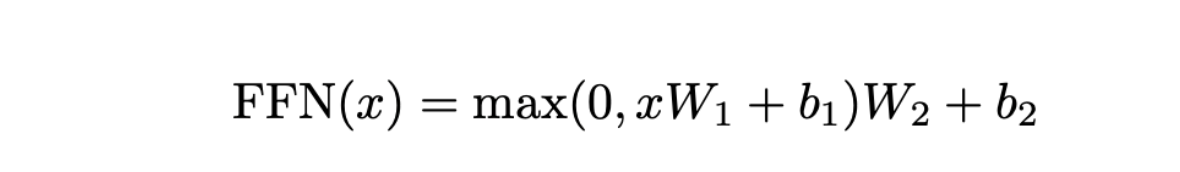 Feed_Forward_Network_formula_e78569e5e0.png
Feed_Forward_Network_formula_e78569e5e0.png
前馈网络(FFN)以一个输入开始,记作 ,这是一个维度为 的 embedding,通常设置为 512。FFN 的第一个组成部分是一个线性层,其特征参数为 和 。这个层将 embedding 从 512 维扩展到一个 2048 维的空间。在这个扩展之后,应用了 ReLU 激活函数,定义为 。ReLU 是引入非线性的主流选择,这对于增强模型捕捉数据中的复杂规律至关重要。
接下来,是另一个线性层,配备有参数 和 ,将 embedding 投影回原始的 512 维。这个两个包含非线性的过程是必不可少的,否则整个操作将是线性的,从而可以融合进前面的 MHA 层,从而失去模型的灵活性。
通过这个前馈层后,embedding 被转换成一个具有高度表达能力的、富含上下文的表示。当几个(通常是6个)Transformer 层堆叠时,每一层都以这种方式丰富 embedding,最终为原始 token embedding 提供更深度、丰富的抽象表示。这些增强的 embedding带有了细粒度而又全面的上下文信息, 之后将被解码成目标语言。
Decoder
Transformer 模型中的解码器也由多个层组成,与编码器的主要区别在于包含了一个遮蔽的多头注意力(masked Multi-Head Attention, MHA)机制。与编码器不同,解码器中的这个 MHA 模块与交叉注意力模块配对,后者与编码器的输出进行交互,这对于将输入序列翻译成目标语言至关重要。
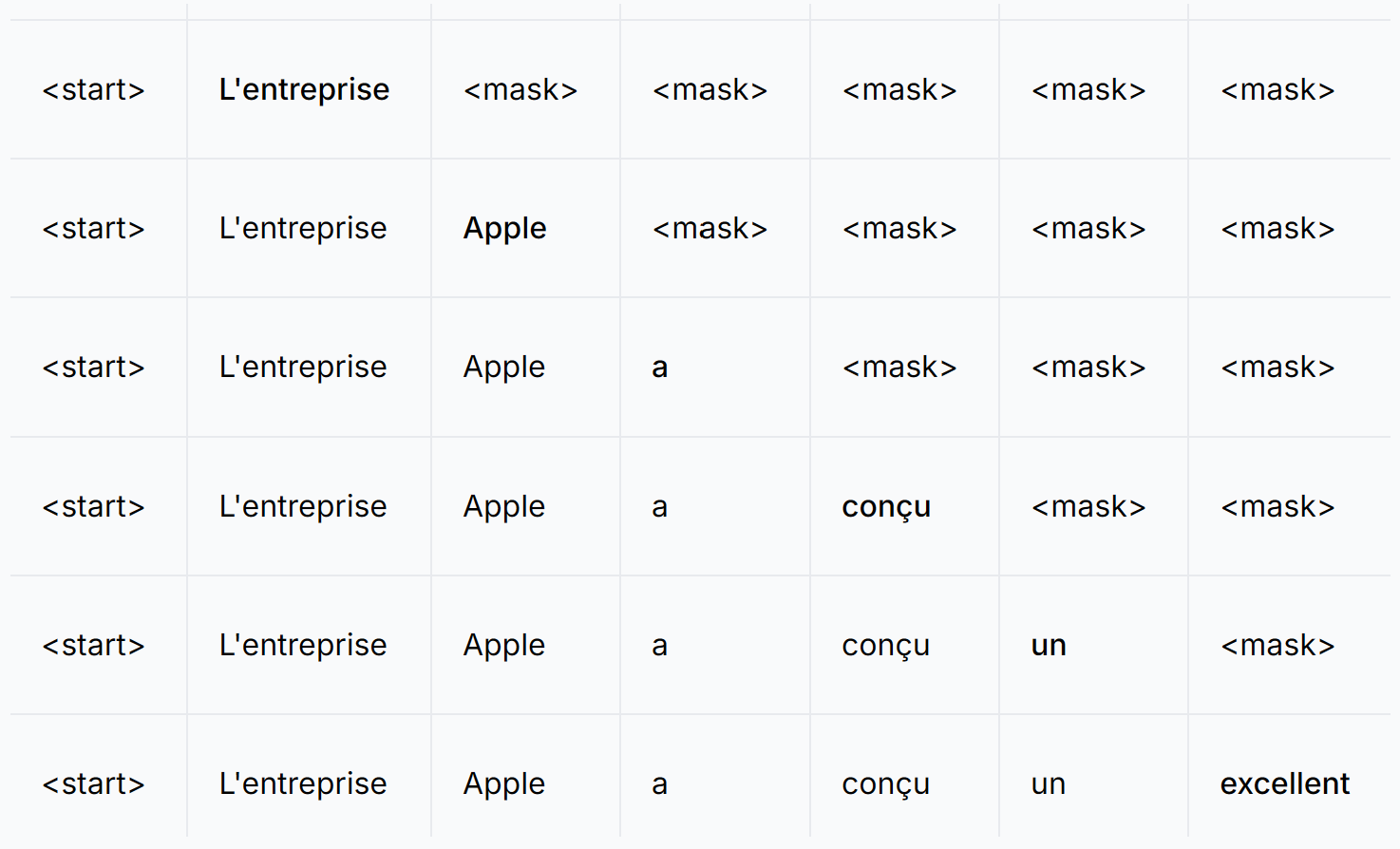
解码过程以一个特殊的 token 开始,标志着目标序列翻译的开始。以一个英语句子为例,“Apple company designed a great smartphone.”被翻译成法语为“L'entreprise Apple a conçu un excellent smartphone。”
解码器的第一个任务是预测紧随其后的 token。在这种情况下,token “L'entreprise” 应该具有最高的概率,这由编码器对英语句子 embedding 提供的上下文线索引导。这种预测能力源于模型在大量双语文本语料库上的训练。
从初始 token “L'entreprise” 开始,解码器继续预测后续的 token。例如,在“L'entreprise”之后,预测的下一个 token 具有最高概率的是“Apple”。这种逐步的 token 生成持续进行,直到解码器生成一个 特殊的结束token。在我们的例子中,这个过程涉及按顺序预测每个法语单词,直到句子完全形成,并在第七个 token 后结束。
解码器还包含一个最终层,该层计算潜在下一个 token 的概率,有效地确定序列每一步最可能延续出来的 token。这个层对于确保最终输出至关重要,因为对于翻译任务不仅需要生成语法正确的句子,同时也要根据编码器的输出产生语义一致的句子。
遮蔽多头注意力(Masked Multi-Head Attention)
解码和编码在收集每个 embedding 的上下文信息方面的最大区别在于如何进行这个过程。在编码过程中,每个 embedding 都可以访问所有其他 embedding(这意味着它从整个序列中收集上下文的相关信息)。然而,在解码过程中,模型只能从前面的文本中收集信息,而不能提前获取尚未生成的未来信息。这在语言模型中被称为因果关系。
 屏幕截图 2024-11-15 105342.png
屏幕截图 2024-11-15 105342.png
....
在遮蔽多头注意力过程中,高亮的 token 是查询 embedding,同一行中的 token 代表其注意力范围。"L'entreprise" 不应该使用 "Apple" 的信息;否则,这将导致解码过程中的不一致性。这确保了每个生成的 token 都基于它所接收到的信息是具有最高概率的 token。否则,如果一个生成的 token 后来变成了中间 token 并且能够接收到在它之后生成的 token 的信息,那么它可能会做出与最初生成时不同的选择,这可能会导致解码过程变得混乱。实际的方法是对每个 token 应用一个遮蔽。例如,在多头注意力机制中,从序列 "L'entreprise Apple a conçu un excellent" 生成 token "smartphone" 时,会应用一个遮蔽到查询上,使得所有查询 token 之后的 token 都不能与之交互。每个查询 token 将有不同的遮蔽,确保维持因果关系(查询 token 只能关注它之前的键 token)。
多头交叉注意力(Multi-Head Cross Attention)
为了确保解码器准确地将英语句子转换为连贯的法语翻译,它采用了多头交叉注意力。如果没有这个机制,解码器可能只会生成无关的法语短语,缺乏对原始英语的语义一致性。交叉注意力通过将编码器的输出(也就是编码后的英语句子 embedding) 整合到解码过程中来解决这个问题。
交叉注意力机制类似于自注意力(self-attention),序列中的每个法语 token 从之前生成的法语 token 中构建上下文,允许这些 token 也访问编码后的整个范围内的英语 token 。但与自注意力机制不同的地方在于,注意力机制中的键(keys)和值(values)来自这些最终编码的英语 embedding,并且不需要遮蔽,因为整个英语句子都是可用且相关的。
这种架构确保每个生成的法语 token 都受到对应英语句子的丰富上下文的影响,从而保持翻译的语义完整性和逻辑一致性。
此外,这种方法体现了生成式 AI 的一个广泛原则:将特定条件(比如指令、遮蔽或标签)嵌入到潜在 embedding 中,并利用交叉注意力将这些条件整合到生成模型的工作流程中。这种方法提供了一种基于预定义条件控制和引导数据生成过程的方式,从而根据给定的条件控制生成式模型的输出。由于不同类型的数据都可以表示为 embedding,交叉注意力是跨各种数据类型连接和整合信息的有效工具,增强了模型生成感知上下文和控制输出的能力。
最终预测头(Final Prediction Head)
经过 Nx 个解码器处理后,我们需要将 embedding 解码回法语 token。最终预测头接收解码器生成的序列中的最后一个 embedding,并将其转换为法语词汇表上的概率分布。这是通过一个线性层后跟一个 softmax 函数来完成的。线性层为每个可能的下一个 token 打分,而 softmax 将这些分数转换为概率,来让模型预测序列中下一个最可能的词。
使用 Transformer 模型推理的示例
我们已经描述了 Transformer 中涉及的模块。为了说明 Transformer 模型的工作原理,让我们从数据流的角度,梳理一下将英语句子 "Apple company designed a great smartphone." 翻译到法语的过程:
Tokenization 和 Embedding:
句子被标记成离散的元素——单词或短语——这些元素从一个预定义的词汇表中索引。
每个 token 随后被转换成一个向量,使用 embedding 层将单词转换成模型可以处理的形式。
位置编码:
- 为每个 token 生成位置编码,以提供模型关于句子中每个单词位置的信息。这些编码信息被添加到 token embedding 中,从而让注意力机制感知到单词的顺序关系。
编码器处理:
与位置编码相加后的 embedding 进入编码器,首先通过一个自注意力多头注意力(MHA)层,其中多个并行的线性变换将输入转换成查询(Q)、键(K)和值(V)的embedding序列。它们经过注意力计算进行交互,从而为每个 token 提供丰富的上下文信息。
这种交互的输出随后通过一个前馈网络(FFN)处理,引入非线性和额外的参数,进一步增强 embedding 表示信息的能力。
多层计算:
- 一个编码器层的输出进入下一个层,逐步增强 embedding 的上下文信息。经过几个层后,编码器输出一组高度信息化的 embedding,每个 embedding 对应输入句子中的一个 token。
解码器初始化:
翻译开始于解码器接收一个起始 token "
"。这个 token 也被转换成 embedding 并编码位置信息。 解码器处理这个初始输入,首先通过一个遮蔽 MHA。在这个阶段,由于 "
" 是唯一的 token,它基本上只关注自己。
顺序解码:
- 随着更多 token 被生成(例如 "L'entreprise Apple a"),解码器中的每个新 token 只能关注之前生成的 token,以保持语言的逻辑顺序。
解码器中的交叉注意力:
- 交叉注意力 MHA 层使解码器中的每个新 token 也能关注所有编码器产生的 embedding。这一步至关重要,因为它能够让解码器访问原始英语句子的全部上下文,确保翻译在语义和句法上对齐。
预测和标记生成:
最终的解码器层输出下一个 token 的概率。在这种情况下,选择概率最高的 token "L'entreprise" 并追加到已解码的序列中。
重复这个过程,基于已产生的法语 token 和全部英语输入生成一个个新 token,直到最终生成一个终止 token "
",标志着翻译的完成。
这个示例详细展示了 Transformer 如何整合复杂的机制,如自注意力和交叉注意力,逐步高效地进行语言翻译。
总结
Transformer 论文是深度学习研究中的一个里程碑。更重要的是,与此前的 RNN 方法相比,它能够引入更多的参数和进行高效的训练,从而实现进一步扩展,催生了如今的大语言模型(LLM)。它的 encoder-decoder 和自注意力、交叉注意力机制的设计也启发了我们使用一系列 embedding 以统一的形式表示不同模态的数据,从而实现多模态学习。希望这篇文章能够帮助您充分了解相关概念。此外,我们还提供了一系列资源供您深度阅读。
更多资源
 王翔宇
王翔宇


