



类激活映射:揭示视觉故事

深度学习模型在复杂任务中的表现通常优于传统机器学习方法。然而,它们有一个显著的限制:可解释性。
深度学习模型的预测出了名的难以解释。这种缺乏透明度使得理解模型决策背后的原因变得具有挑战性,从而降低了其可信度。研究人员提出了几种方法来解决这个问题,包括类激活映射(CAM)。CAM在卷积神经网络(CNNs)中的应用广泛,CNN是计算机视觉任务的首选架构。
在本文中,我们将探讨CAM在CNN中的重要性,学习CAM背后的理论,并学习如何在代码中实现它。那么,让我们开始吧!
为什么我们需要类激活映射?
 23-1.png
23-1.png
CNN是神经网络,通常应用于解决各种计算机视觉任务,包括图像分类、图像分割、目标检测和姿态估计。
然而,CNN通常被视为黑盒。我们向它们输入数据,它们根据它们被训练的任务产生预测。理解它们的决策过程可能非常具有挑战性,因为CNN通常由具有复杂交互的多个层组成。
另一方面,可解释性在所有机器学习模型中都至关重要,以确保其可信度。在CNN的背景下,重要的是要验证模型在进行预测时是否关注图像的正确区域。
假设我们开发了一个自动驾驶车辆系统。假设我们构建了一个图像分类模型来识别街道上的对象。然后,车辆将根据模型预测的对象采取行动。在这种情况下,确保模型在进行预测时正确识别图像的相关区域非常重要;否则,车辆可能会出现故障。
CAM是一种早期设计来解决这个问题的方法。它允许我们调查影响模型预测的图像区域。
 23-2.png
23-2.png
如上图所示,实现CAM突出显示了斑马和汽车周围的区域比其他图像部分更重要。热图中的强度对应于该区域对模型预测的重要性。因此,这种方法提高了模型的透明度和可信度。
类激活图解释
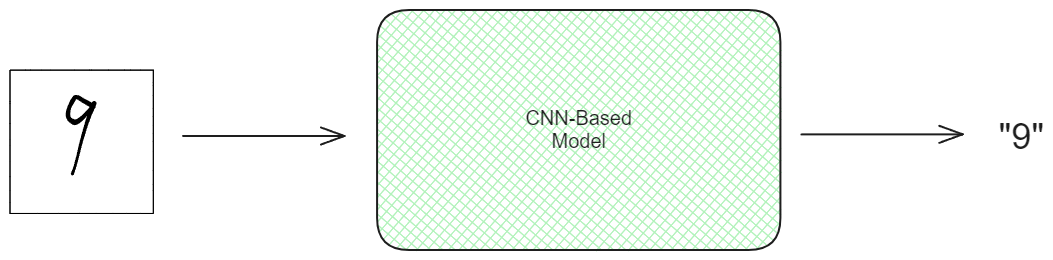
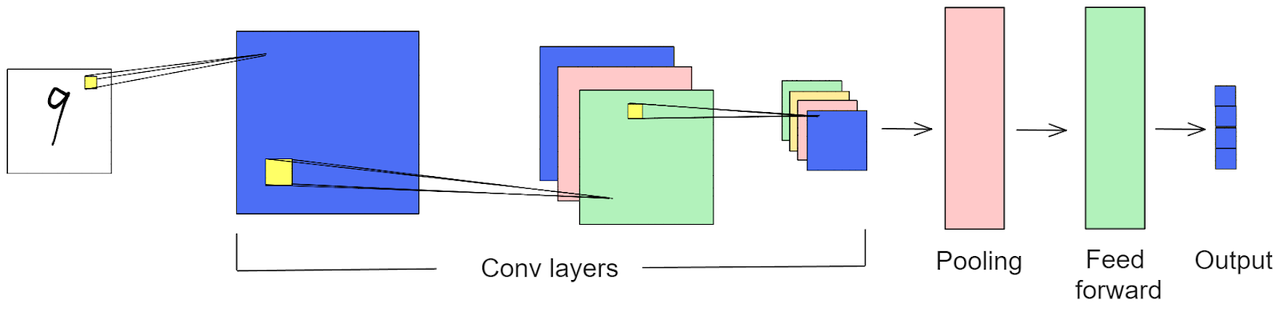
在深入研究CAM的工作原理之前,让我们回顾一下基于CNN的模型的典型架构。基于CNN的模型由多个卷积层组成,如下图所示。当输入图像通过每个卷积层时,其尺寸减小,而特征数量增加。
 23-3.png
23-3.png
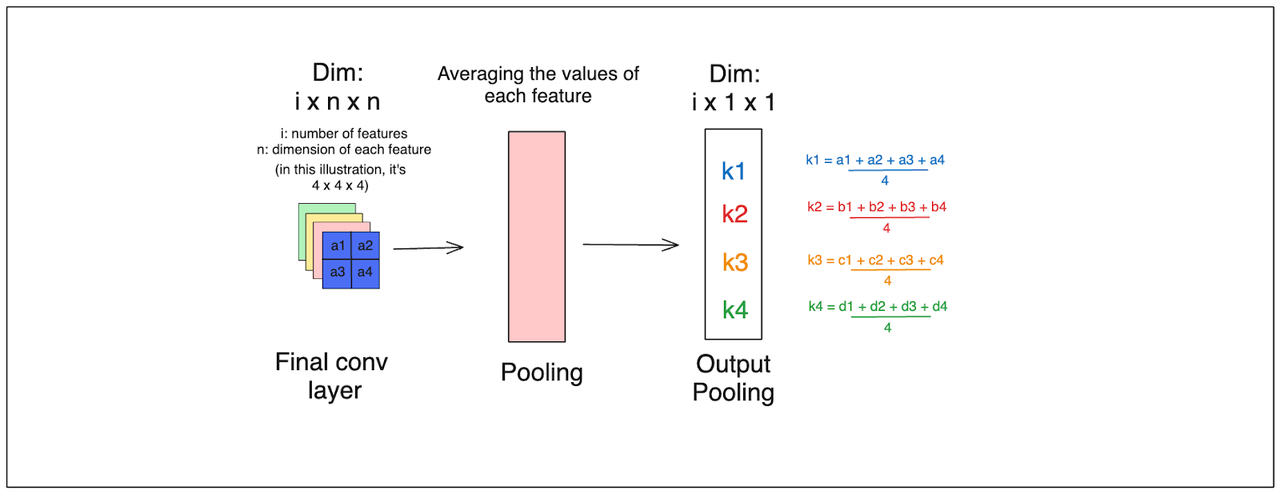
在通过最终卷积层后,每个特征图中的值使用全局平均池化层(GAP)进行聚合。在GAP层之后,每个特征图由一个单一的标量值表示。接下来,这些值被送入最终的前馈层以产生模型的预测。
 23-4.png
23-4.png
那么,我们是如何从这个过程中推导出CAM的呢?
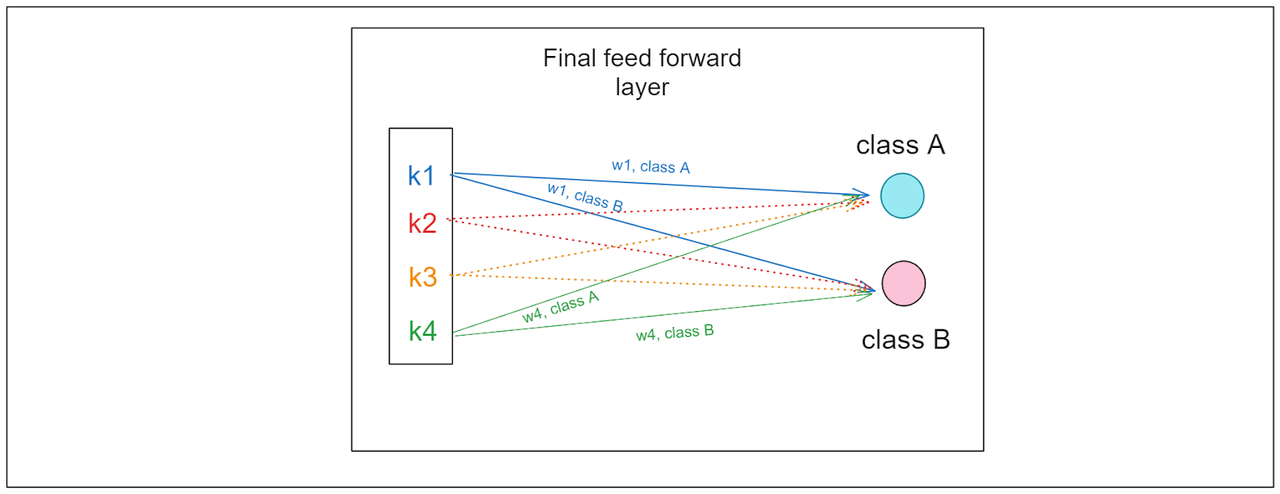
基于CNN的模型的预测是在最终前馈层中生成的。在这一层中,每个特征图的值乘以其对应特定类别的权重,然后求和,以得出该类别的最终值。以下是每个特征图权重背后的直觉:
如果权重 > 0,相应的特征增加了我们的输入图像属于特定类别的可能性。
如果权重 = 0,相应的特征没有影响。
如果权重 < 0,相应的特征减少了我们的输入图像属于特定类别的可能性。
因此,我们模型的预测对应于具有最高加权特征和的类别。
 23-5.png
23-5.png
这里的想法是:如果我们能够获得预测类别的每个特征图的权重,我们就可以评估它在CNN模型预测中的重要性!
一旦我们获得了预测类别的每个特征图的权重,接下来的步骤就很简单了。首先,我们必须从最终卷积层(在GAP层之前)获取特征图。其次,我们将每个特征图乘以其相应的权重。最后,我们将这些乘法结果求和,以获得一个与最终卷积层中的特征图尺寸相匹配的单一矩阵。
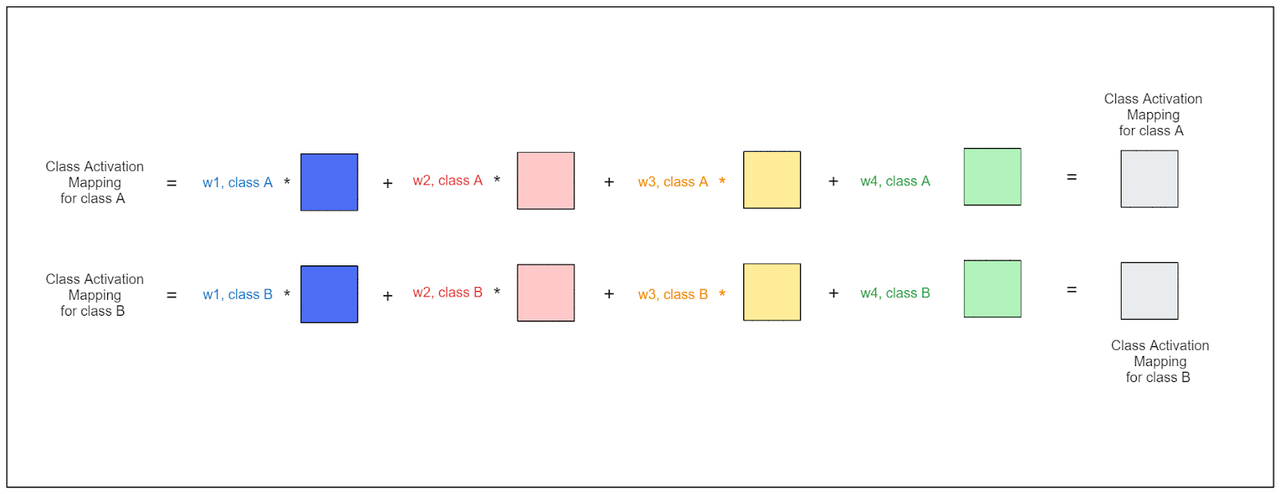
让我们使用上面的插图来澄清。假设我们的模型预测输入图像属于类别A。我们的目标是确定影响这一预测的图像区域。
计算CAM:
我们检索类别A的每个特征图的权重,表示为(w1,类别A),(w2,类别A),(w3,类别A)和(w4,类别A)。
我们还需要从最后一个卷积层获取特征图(在上面的插图中,这对应于尺寸为4 x 4 x 4的特征)。
最后,我们计算每个特征图的加权和,结果如下所示:
 23-6.png
23-6.png
矩阵中值高的区域对模型的预测至关重要。最后一步是将这个矩阵放大到我们输入图像的原始尺寸。在可视化中,值高的区域将更加突出,如前一节所示。
类激活映射实现
在本节中,我们将使用PyTorch从头开始实现CAM。这意味着我们不会依赖任何抽象整个生成CAM过程的高级库。当然,你也可以使用TensorFlow。但是,如果你愿意,你需要根据他们的API调整以下教程中的几件事情。
首先,让我们导入实现所需的所有必要库。
 23-7.png
23-7.png
numpy库用于计算特征图的加权和以获得最终的CAM。同时,OpenCV将用于图像预处理,torchvision是一个库,我们可以在其中访问计算机视觉任务的常见预训练模型。
我们用于此实现的模型是ResNet18。顾名思义,它由18个卷积层组成,并已经在ImageNet数据库的超过一百万张图像上进行了训练,其中包括1,000个不同类别。现在让我们加载预训练模型。
 23-8.png
23-8.png
 23-9.png
23-9.png
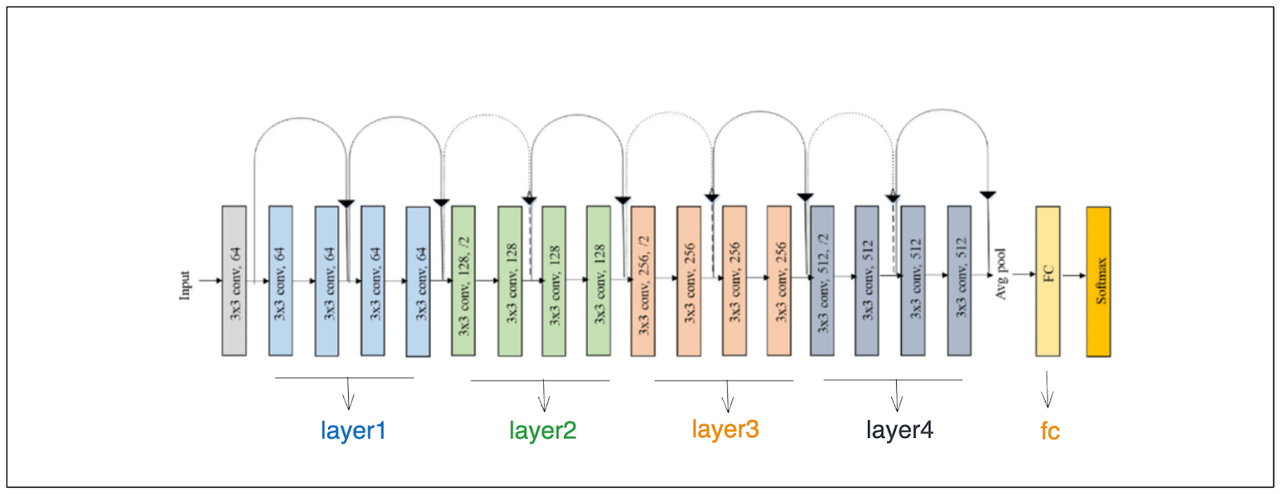
正如你从上面的插图中看到的,ResNet18的18个卷积层在GAP层和最终前馈层之前被分成了四个块。正如你在前一节中已经知道的,我们需要在GAP层之前存储最终卷积层的特征图,以便计算CAM。
我们想要存储的特征图本质上是第四个块的输出,名为'layer4'。存储'layer4'输出的一种方法是使用PyTorch的register_forward_hook方法。这个方法将在前向传递期间存储特定层的中间结果。
 23-10.png
23-10.png
接下来,让我们通过提供图像的路径来加载我们的输入图像。
 23-11.png
23-11.png
 23-12.png
23-12.png
我们将使用一张丝毛梗犬的图像作为这个示例。我们的目标是找出模型对这张图像的预测,并识别图像内影响模型预测的区域。需要注意的一点是,ResNet18已经在尺寸为224 x 224的图像上进行了预训练,并具有特定的均值和标准差值。因此,我们需要首先调整图像的大小,然后根据ImageNet数据集的均值和标准差对其进行归一化。
此外,当我们使用OpenCV加载图像时,默认的图像通道是BGR格式。因此,我们还需要将其转换为RGB。
 23-13.png
23-13.png
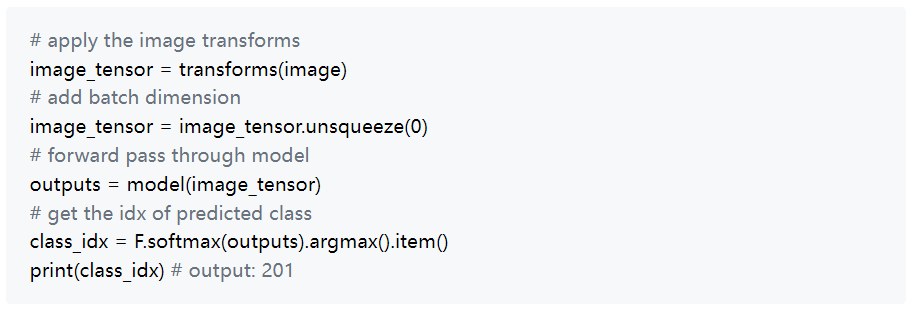
现在让我们使用我们的ResNet18模型对我们的输入图像进行前向传递。最后,我们获取预测类别的索引。
 23-14.png
23-14.png
如果你参考ImageNet数据的标签映射,你可以在这里找到,你会看到索引201对应于丝毛梗犬。这意味着模型的预测是正确的。CAM的作用是突出显示图像中对模型预测为丝毛梗犬至关重要的区域。
正如前一节提到的,为了计算CAM,我们需要检索两件事:
最终卷积层的特征图。
最终前馈层学习到的每个特征图的权重。
从最终卷积层获取特征图是直接的,因为我们已经实现了register_forward_hook。同样,获取最终前馈层的每个特征的权重也很简单。我们所需要做的就是指定相应的前馈层的名称,在ResNet18中被称为'fc'。
 23-15.png
23-15.png
现在,是时候计算CAM了。为了获得CAM,我们需要计算特征图的加权和,这本质上是权重和特征图之间的点积。
之后,我们需要对CAM进行去规范化,并将其上采样以匹配输入图像的尺寸。通过这样做,我们可以将CAM结果叠加在原始图像上,生成热图可视化。
 23-16.png
23-16.png
最后,让我们为模型可视化创建一个函数,即CAM和原始输入图像之间的叠加,使用以下方法:
def visualize_cam(class_activation_map, width, height, orig_image):
heatmap = cv2.applyColorMap(cv2.resize(class_activation_map,(width, height)), cv2.COLORMAP_JET)
result = heatmap * 0.3 + orig_image * 0.5
cv2.imshow(result)
cv2.waitKey(0)
# visualize resultvisualize_cam(class_activation_map, width, height, orig_image)
 23-17.png
23-17.png
类激活映射的改进
CAM是一种早期方法,它启动了人工智能可解释性,特别是计算机视觉任务的快速发展。目前,已经提出了许多基于CAM的方法来提高其准确性和灵活性,如GradCAM和GradCAM++。
正如你可能已经知道的,要使用CAM,我们需要使用具有特定架构的模型。具体来说,我们需要使用GAP(全局平均池化)层从最后一个卷积层聚合特征图。如果我们的模型在最后没有GAP层,实现CAM将需要修改模型的架构。
GradCAM推广了这种方法,消除了模型中GAP层的需求,允许我们使用任何基于CNN的架构生成CAM。
最近,提出了一种称为GradCAM++的方法作为GradCAM的增强。这种方法提供了模型预测的更好的视觉解释,特别是在单个图像中多个对象影响预测的情况下。
如果你想更多地了解GradCAM或GradCAM++,我们建议参考他们的官方研究论文。
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks.
结论
在本文中,我们涵盖了你需要了解的关于CAM的所有内容。首先,我们讨论了能够解释我们深度学习模型的预测的重要性以及CAM如何在这方面帮助我们。然后,我们学习了CAM生成热图的底层过程,可视化显著影响模型预测的区域。最后,我们从头开始实现了CAM,没有依赖任何高级库,以确保对CAM生成过程的全面理解。
我们希望本文对你开始使用CAM或一般的可解释人工智能有所帮助。CAM是一种直观的方法,用于解释基于CNN的模型的预测,使其成为你刚开始接触可解释人工智能的完美起点。

Ruben Winastwan
Freelance Technical Writer


技术干货
Milvus Lite 已交卷!轻量版 Milvus,主打就是一个轻便、无负担
总体而言,无论用户是何种身份(研究人员、开发者或者数据科学家),Milvus Lite 都是一个不错的选择,尤其对于那些想要在受限的环境中使用 Milvus 功能的用户而言,更是如此。
2023-6-8
技术干货
OpenAI 上线新功能力捧 RAG,开发者真的不需要向量数据库了?
虽然 OpenAI Assistants 的内置检索工具令人眼前一亮,但它仍旧存在诸多存储限制,如:可扩展性较差,无法满足多样的、定制化的用户需求等。
2023-11-15
技术干货
LlamaIndex 联合创始人下场揭秘:如何使用私有数据提升 LLM 的能力?
如何使用私有数据增强 LLM 是困扰许多 LLM 开发者的一大难题。在网络研讨会中,Jerry 提出了两种方法:微调和上下文学习。
2023-5-18