使用Spark和Milvus构建生产就绪的搜索管道
在生产中构建一个可扩展的向量搜索管道并不像构建其原型那么简单。在处理原型时,我们通常只处理少量的非结构化数据。然而,当将原型迁移到生产环境时,我们通常需要处理数百万甚至数十亿的非结构化数据和高查询量。因此,需要一个健壮的解决方案来有效执行常见的向量搜索管道操作,如数据摄取和信息检索。
在最近的一次演讲中,Zilliz的生态系统和AI平台负责人Jiang Chen提出了一个逐步构建高效且生产就绪的向量搜索管道的过程。本文将讨论演讲的主要要点,包括三个主题:
- 传统和检索增强生成(RAG)设置中的信息搜索工作流程。
- 使用Milvus和Spark在RAG系统中构建可扩展的向量搜索管道。
- 提高您的RAG系统质量的建议。
话不多说,让我们来谈谈第一个主题,从传统环境中的信息搜索工作流程开始。
传统信息搜索的工作流程
在深度学习的进步之前,传统的信息检索或搜索系统严重依赖于标签和手动标记。以在线商店为例:它们依赖于产品标签,以根据客户的需求提供最合适的产品。因此,在线商店需要一个可扩展且高效的搜索管道,使其能够每天处理大量客户查询。
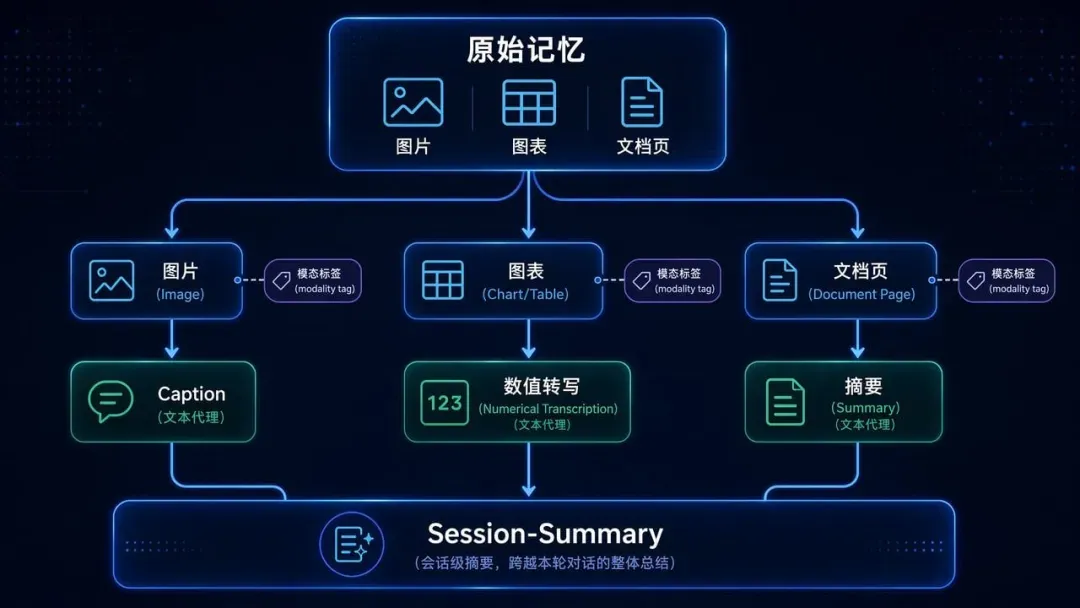
为了满足这一需求,传统搜索系统的架构通常分为两个组件:一个用于离线数据摄取,一个用于在线查询服务。
离线数据摄取
离线数据摄取的主要目标是将所有数据加载到数据库中。作为这个过程的第一步,数据从一个或多个来源(如内部文档或互联网)中收集。一旦我们可以获取数据,我们可以继续进行数据标记。最后,标记后的数据可以被索引并加载到数据库中。
让我们使用在线商店的例子来说明工作流程。我们可以通过网络爬虫从互联网上获取产品描述。接下来,一旦我们有了描述,我们就创建代表这些产品描述的标签,如“服装”、“连衣裙”、“正装”、“派对礼服”等。然后,我们在将标签、产品描述、价格和其他元数据加载到非结构化数据库之前,构建标签的索引。最后,我们将这个数据库推送到服务环境。
 Two_components_of_a_traditional_information_search_architecture_7a2cdae76d.png
Two_components_of_a_traditional_information_search_architecture_7a2cdae76d.png
传统信息搜索架构的两个组件
在线查询服务
第二个组件的主要目标是服务客户的查询并从我们在前一个工作流程中创建的数据库中执行信息检索。
这个过程从前端和查询编译器开始,将用户的查询合成一组标签。接下来,系统将使用生成的标签作为相似性搜索的输入。数据库中与查询标签最相似的前k个条目将被检索并使用根据用例变化的算法进行排名。最后,排名结果将返回给用户。
传统信息检索和搜索系统的主要缺点是缺乏语义理解。标签或手动创建的标签无法捕捉用户查询的语义含义和意图,这可能导致搜索结果不准确。此外,如果我们有大量数据,手动标记每个条目将非常繁琐。
RAG作为新的信息搜索的工作流程
深度学习的快速发展显著改变了信息检索流程的格局。借助嵌入模型和大型语言模型(LLMs),如GPT、Claude、LLAMA和Mistral,可以有效捕获用户查询的语义含义,消除了为每个数据条目手动创建标签或标记的需要。
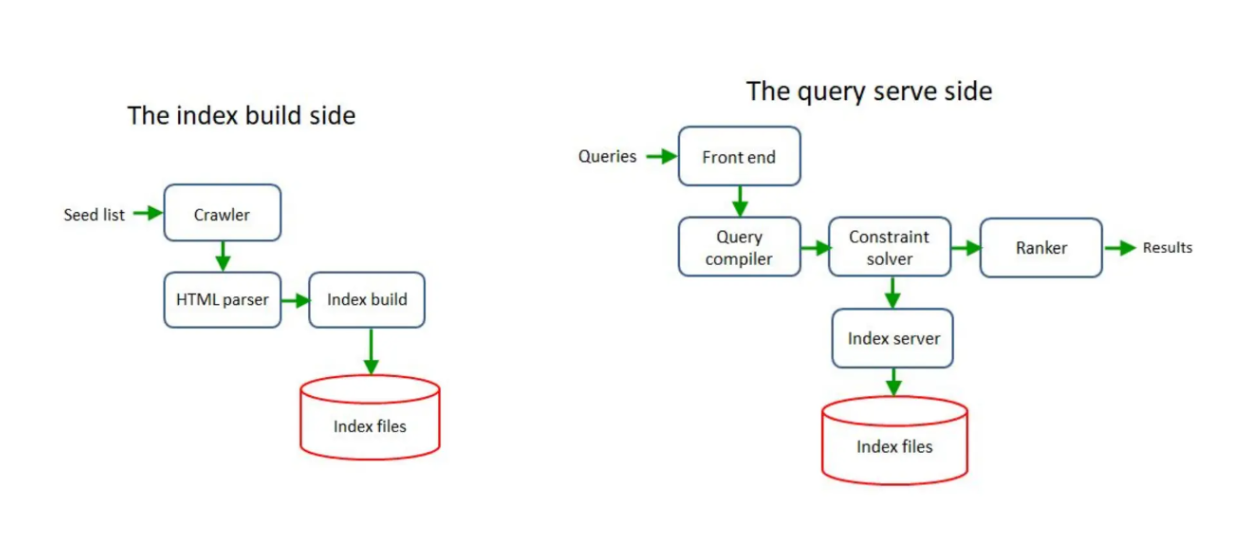
借助嵌入模型,非结构化数据可以被转换成向量嵌入,由n维向量组成。嵌入的维度取决于所使用的模型。这些嵌入携带了它们所代表数据的语义含义,因此,可以使用余弦距离等指标轻松计算任意两个嵌入之间的相似性。直观上,携带相似含义的嵌入将被放置在向量空间中彼此更近的位置。
 Example_of_vector_embeddings_that_carry_similar_semantic_meaning_in_a_2_D_vector_space_d6ca900d3a.png
Example_of_vector_embeddings_that_carry_similar_semantic_meaning_in_a_2_D_vector_space_d6ca900d3a.png
在2D向量空间中携带相似语义含义的向量嵌入示例
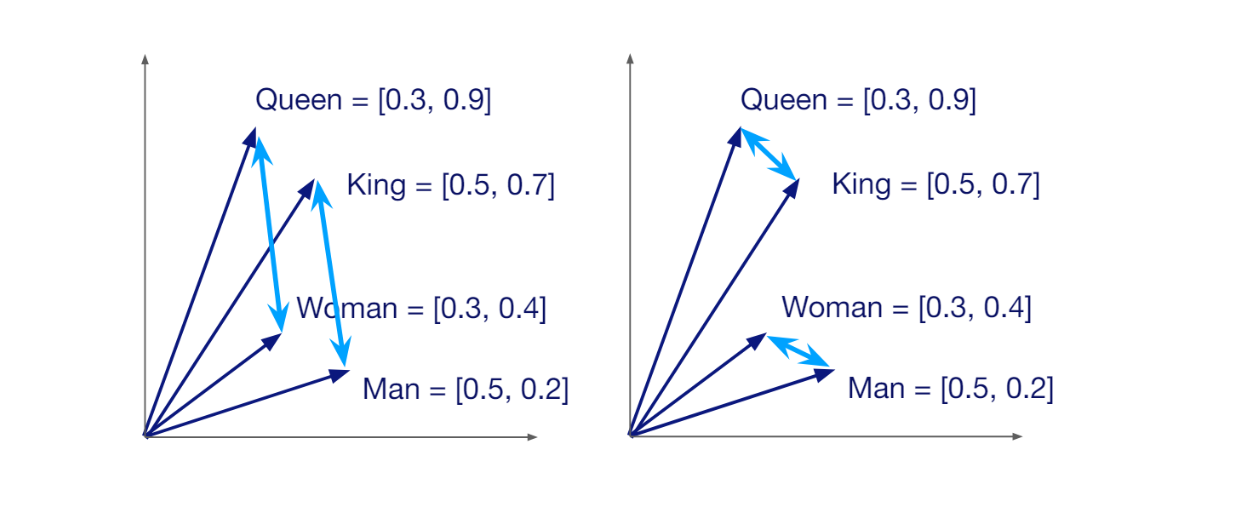
一旦我们有了嵌入,它们就可以直接被摄取到像Milvus这样的向量数据库中,完成数据摄取部分。之后,就可以执行信息检索过程。
当接收到用户查询时,它将使用与数据摄取部分相同的嵌入模型转换成嵌入。接下来,管道执行向量搜索操作,并从数据库中检索最相似的前k个嵌入。在检索增强生成(RAG)的上下文中,这些相似的嵌入随后被用作上下文,与查询一起传递给LLM以回答用户的查询。
 RAG_workflow_c37dbaa213.png
RAG_workflow_c37dbaa213.png
RAG工作流程
使用Spark和Milvus构建向量搜索管道
RAG是一种新颖的方法,通过从向量搜索中获取相关上下文来提高由LLM生成的答案的准确性。然而,由于可扩展性问题,构建生产就绪的RAG应用面临挑战。
在生产环境中部署RAG应用时,您很可能要处理数百万甚至数十亿的非结构化数据。此外,您的RAG系统将从客户那里接收到成千上万甚至更多的查询。因此,需要一个高效且可扩展的解决方案来有效处理这些问题,这就是Apache Spark的用武之地。
在本节中,我们将使用Milvus和Spark构建一个搜索管道。Milvus是一个开源向量数据库,使我们能够在几秒钟内对大量数据执行向量搜索。与此同时,Spark是一个强大的开源分布式计算框架,特别适合快速高效地处理和分析大型数据集。
让我们首先安装Milvus。安装Milvus有多种方法,但如果您想在生产环境中使用Milvus,最好在Docker中安装并运行Milvus,命令如下:
# Download the installation script
$ curl -sfL <https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh> -o standalone_embed.sh
# Start the Docker container
$ bash standalone_embed.sh start
作为一个开源向量数据库,Milvus与许多工具和AI框架无缝集成,使构建生产就绪的AI应用(如RAG)变得容易。Apache Spark是与Milvus一起使用以有效扩展数据摄取和查询检索过程的框架之一。
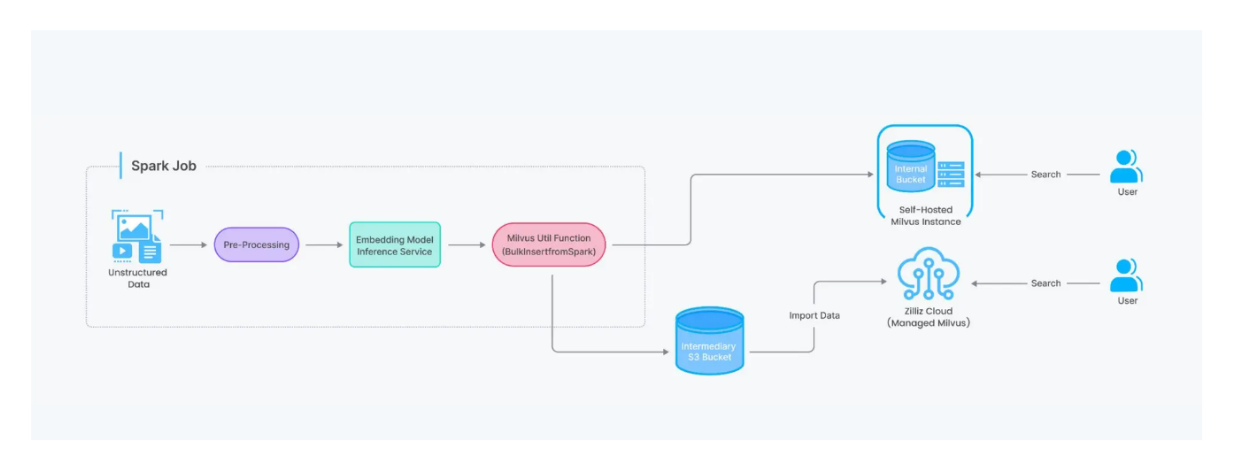 Example_of_a_vector_search_pipeline_workflow_with_Milvus_and_Spark_35c3678bd2.png
Example_of_a_vector_search_pipeline_workflow_with_Milvus_and_Spark_35c3678bd2.png
Milvus和Spark的向量搜索管道工作流程示例
由于Spark是一个分布式处理系统,它能够将数据处理任务分批跨多台计算机分布。当处理大量数据时,这一特性加快了数据处理速度,例如在生产中部署RAG应用时。借助这种集成,我们还可以在Milvus和其他数据库服务(如MySQL)之间移动数据。
要安装Apache Spark,请参考他们的最新安装文档。安装Spark后,您还需要安装spark-milvus jar文件。
wget <https://github.com/zilliztech/spark-milvus/raw/1.0.0-SNAPSHOT/output/spark-milvus-1.0.0-SNAPSHOT.jar>
一旦您下载了spark-milvus jar文件,可以通过以下步骤将其添加为依赖项:
# For pyspark
./bin/pyspark --jars spark-milvus-1.0.0-SNAPSHOT.jar
# For spark-shell
./bin/spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar
现在我们已经准备好将Milvus与Spark集成。在以下示例中,我们将向您展示如何直接从Spark数据框摄取数据到Milvus。
import org.apache.spark.sql.{SaveMode, SparkSession}
import io.milvus.client.{MilvusClient, MilvusServiceClient}
import io.milvus.grpc.{DataType, FlushResponse, ImportResponse}
import io.milvus.param.bulkinsert.{BulkInsertParam, GetBulkInsertStateParam}
import io.milvus.param.collection.{CreateCollectionParam, DescribeCollectionParam, FieldType, FlushParam, LoadCollectionParam}
import io.milvus.param.dml.SearchParam
import io.milvus.param.index.CreateIndexParam
import io.milvus.param.{ConnectParam, IndexType, MetricType, R, RpcStatus}
import zilliztech.spark.milvus.{MilvusOptions, MilvusUtils}
import zilliztech.spark.milvus.MilvusOptions._
import org.apache.spark.SparkConf
import org.apache.spark.sql.types._
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.util.CaseInsensitiveStringMap
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.log4j.Logger
import org.slf4j.LoggerFactory
import java.util
import scala.collection.JavaConverters._
object Hello extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("HelloSparkMilvus")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "a", Seq(1.0,2.0,3.0,4.0,5.0)),
(2, "b", Seq(1.0,2.0,3.0,4.0,5.0)),
(3, "c", Seq(1.0,2.0,3.0,4.0,5.0)),
(4, "d", Seq(1.0,2.0,3.0,4.0,5.0))
).toDF("id", "text", "vec")
// set milvus options
val milvusOptions = Map(
"milvus.host" -> "localhost" -> uri,
"milvus.port" -> "19530",
"milvus.collection.name" -> "hello_spark_milvus",
"milvus.collection.vectorField" -> "vec",
"milvus.collection.vectorDim" -> "5",
"milvus.collection.primaryKeyField", "id"
)
sampleDF.write.format("milvus")
.options(milvusOptions)
.mode(SaveMode.Append)
.save()
}
在上述提供的代码片段中,我们将包含三个字段的Spark数据框(一个ID、一个文本和一个向量嵌入)摄取到名为"hello_spark_milvus"的集合中。嵌入由5维向量组成,我们使用ID作为我们集合的主键。
我们还需要在milvusOptions映射中提供关于我们的Milvus数据库的几个配置项:
- milvus.host和milvus.port:Milvus服务器和端口。如果您在Docker中运行Milvus,默认端口是19530。
- milvus.collection.name:数据将被摄取到的Milvus数据库中的集合名称。
- milvus.collection.vectorField:包含向量嵌入的数据的列名。
- milvus.collection.vectorDim:我们的向量嵌入的维度。
- milvus.collection.primaryKeyField:包含主键的数据的列名。
如果您想了解更多关于您可以调整的不同Milvus选项,请参阅Milvus文档页面。
现在我们已经将数据摄取到Milvus数据库中,我们需要为集合指定索引方法。Milvus支持各种索引方法,如常规的Flat索引、倒排Flat索引(IVF)、层次可导航小世界(HNSW)等。
在以下示例中,我们将使用AUTOINDEX,这是HNSW的定制版本。作为向量搜索的度量,我们将使用L2距离。
val username = <YOUR_MILVUS_USER>
val password = <YOUR_MILVUS_PASSWORD>
val connectParam: ConnectParam = ConnectParam.newBuilder
.withHost("localhost")
.withPort("19530")
.withAuthorization(username, password)
.build
val client: MilvusClient = new MilvusServiceClient(connectParam)
val createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("hello_spark_milvus")
.withIndexName("index_name")
.withFieldName("vec")
.withMetricType(MetricType.L2)
.withIndexType(IndexType.AUTOINDEX)
.build()
val createIndexR = client.createIndex(createIndexParam)
println(createIndexR)
接下来,我们需要在能够对它执行向量搜索之前加载我们的“hello_spark_milvus”集合。
import io.milvus.param.collection.{CreateCollectionParam, DescribeCollectionParam, FieldType, FlushParam, LoadCollectionParam}
// Load collection, only loaded collection can be searched
val loadCollectionParam = LoadCollectionParam.newBuilder().withCollectionName("hello_spark_milvus").build()
val loadCollectionR = client.loadCollection(loadCollectionParam)
println(loadCollectionR)
现在我们已经将数据摄取到Milvus中并创建了索引,最后我们准备执行向量搜索操作。我们将使用我们之前创建的Spark数据框的第一行作为输入向量。
// Search, use the first row of input dataframe as search vector
val fieldList: util.List[String] = new util.ArrayList[String]()
fieldList.add("vec")
val searchVectors = util.Arrays.asList(sampleDF.first().getList(2))
val searchParam = SearchParam.newBuilder()
.withCollectionName("hello_spark_milvus")
.withMetricType(MetricType.L2)
.withOutFields("text")
.withVectors(searchVectors)
.withVectorFieldName("vec")
.withTopK(2)
.build()
val searchParamR = client.search(searchParam)
println(searchParamR)
如您所见,我们需要在SearchParam.newBuilder()方法内提供几个方法调用来执行向量搜索操作,例如:
- withCollectionName():执行向量搜索的集合名称。
- withMetricType():执行向量搜索所使用的度量。
- withOutFields():返回结果的集合中的输出字段。
- withVectors():输入或查询向量。
- withVectorFieldName():包含向量嵌入的字段名称。
- withTopK():返回与查询向量最相似的前k个条目。
在RAG应用中,最相似的前k个条目将被用作上下文,与查询一起传递给LLM。这样,LLM就可以使用上下文生成对查询的准确答案。
您可以利用Milvus与Spark的集成实现更多高级用例。例如,您可以从MySQL等常规数据库中读取数据,将它们转换成向量嵌入,并将这些嵌入摄取到Milvus中。您可以在这个GitHub存储库或这个Milvus笔记本演示中探索这些用例。
良好的RAG来自良好的数据
Milvus与许多AI工具包和框架的集成简化了生产就绪的RAG(检索增强生成)应用的开发。然而,在生产环境中部署RAG系统后,持续监控系统生成的响应质量非常重要。
如果需要提高响应质量,重要的是在深入更复杂的算法之前,首先检查基础知识。关键的焦点应该是RAG系统所使用的数据源的质量。
在评估数据源时,请考虑以下问题:
- 我们的数据库中是否有回答用户查询所需的数据?
- 我们是否已将所有必要的数据收集到我们的数据库中?
- 在将数据摄取到我们的数据库之前,我们是否执行了正确的数据预处理步骤(例如,数据解析、数据清洗、分块、使用适当的嵌入模型)?
一旦您验证了数据源的质量,然后您可以考虑从算法角度提高RAG系统的质量。提高RAG系统性能的方法有:
- 使用更强大的嵌入模型:尝试不同的预训练或自定义训练的嵌入模型,以找到最能捕捉您数据中语义关系的模型。
- 实现查询路由和第三方工具集成:如果嵌入模型不是问题,您可以通过应用查询路由代理并集成额外的工具或数据源来提高RAG系统的性能。
通过关注基础知识,并持续迭代数据源和算法组件,您可以确保您的生产就绪的RAG应用为用户提供高质量的响应。
结论
Milvus与各种框架如Spark的无缝集成,使我们能够轻松构建和部署可扩展的LLM驱动应用。Spark能够将数据处理任务跨多台计算机分批处理,这一特性在处理大量数据时大大加快了数据处理操作。当您希望将大量数据摄取到我们的向量数据库中,或者当您的应用程序同时处理大量用户查询时,这一特性特别有用。
一旦我们将数据摄取到我们的Milvus向量数据库中并接收到用户的查询,我们就可以执行向量搜索。这一过程对于获取数据库内数据中最相关的上下文以传递给LLM以生成高度上下文化的答案是至关重要的。
注:本文为AI翻译,查看原文
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer