使用 Milvus、LangChain 和 OpenAI LLM 构建多语言 RAG
在过去两年中,检索增强生成(RAG)迅速成为由大型语言模型(LLM)驱动的 GenAI 应用最受欢迎的技术之一。RAG 的核心是通过提供模型未预训练的上下文信息来增强 LLM 的输出。多语言 RAG 是处理多种语言文本数据的扩展 RAG。
OSS4AI 的首席执行官 Yujian Tang 最近在由 Zilliz 主办的非结构化数据聚会上发表演讲。他讨论了 RAG 及其基本组件,并演示了如何构建多语言 RAG 来应对多样化的真实世界语言挑战。
在本文中,我们将回顾 Yujian 演讲的关键见解,并指导您逐步实现多语言 RAG。
什么是 RAG 以及它的工作原理?
LLM 应用的一个核心限制是它们依赖于训练数据。如果 LLM 在预训练期间没有接触到某些信息或整个知识领域,它就无法理解生成准确响应所需的语言关系。这种数据缺乏可能导致 LLM 要么承认它不知道答案,要么更糟,“幻觉”并提供错误信息。 RAG 是一种流行的技术,通过提供额外的上下文信息来解决 LLM 的幻觉问题。它还使开发人员和企业能够利用他们的私有或专有数据,而不必担心安全问题。
 Figure_1_How_RAG_works_246044aacf.png
Figure_1_How_RAG_works_246044aacf.png
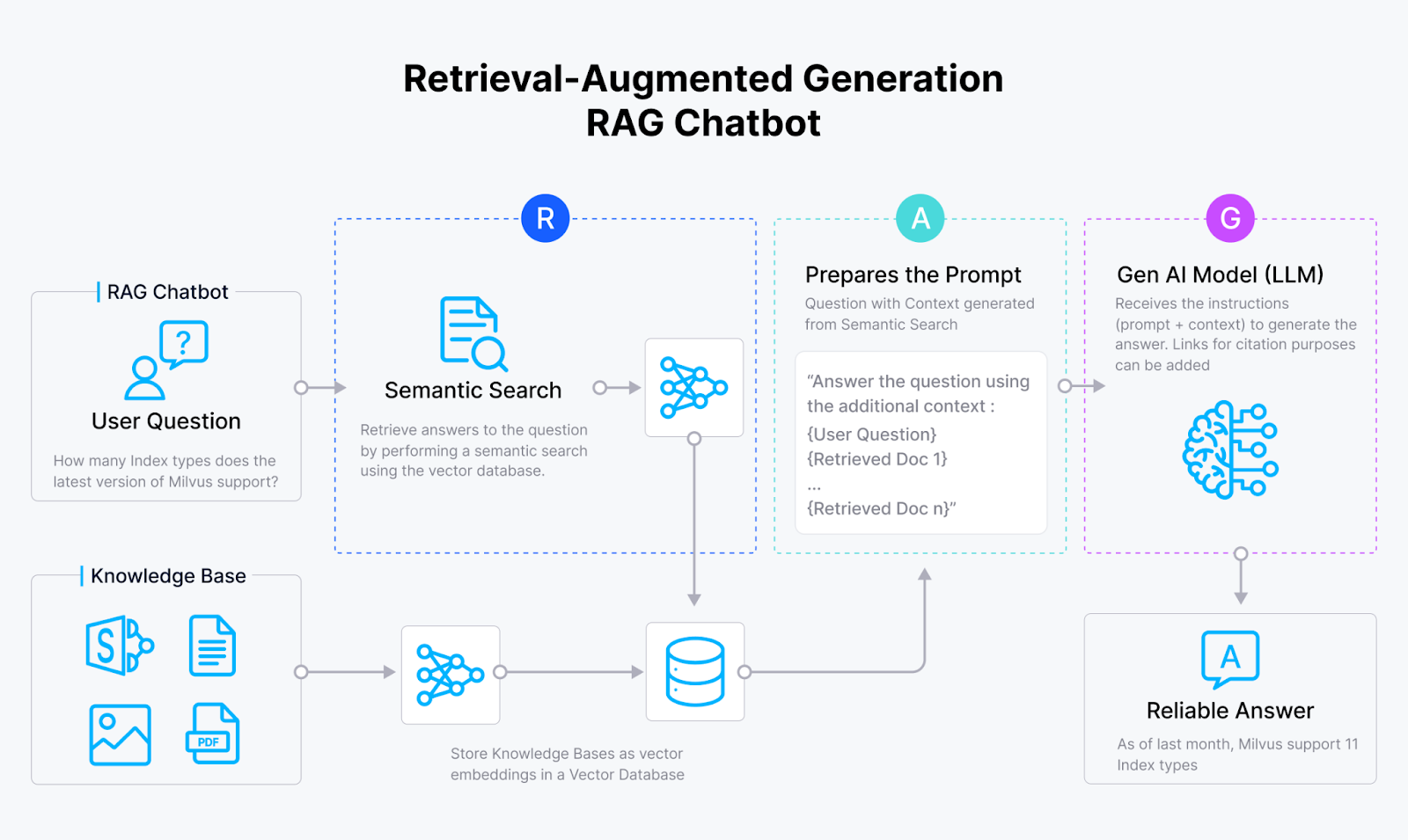
图 1 - RAG 的工作原理
RAG 从嵌入模型开始,将文本数据转换为向量嵌入,这些数值表示捕获了文本的语义含义。然后 RAG 系统将这些向量存储在像 Milvus 或 Zilliz Cloud 这样的向量数据库中,为相似性搜索建立索引。
当用户提交查询时,嵌入模型也将输入转换为向量。然后,RAG 系统通过计算高维向量空间中查询向量与向量数据库中的向量之间的距离来比较它们的相似性。如果找到相关数据,RAG 系统将检索这些信息,并将其添加到原始查询中,形成 LLM 的新提示。LLM 使用这些额外的信息生成更准确、更相关的响应,超越了仅基于其训练数据所能产生的输出。
什么是多语言 RAG?
多语言 RAG 扩展了传统 RAG 的能力,支持多种语言。它集成了在多种语言上训练的嵌入模型,使系统能够处理和生成不同语言的响应。使用这种多语言方法,RAG 系统可以处理任何语言的查询,检索与其原始语言无关的相关信息,并以用户首选的语言提供准确、相关的回答。
如何构建多语言 RAG 应用:逐步指南
现在我们已经了解了 RAG 的核心概念和组件,让我们逐步实现多语言 RAG 应用。
这个示例应用包含两个部分:网络爬虫和主应用。
- 网络爬虫从互联网上抓取所需数据集。
- 主应用创建向量嵌入,执行向量相似性搜索,并生成答案。
网络爬虫
首先,我们将从维基百科抓取数据,并将其作为本次 RAG 示例的上下文信息。
- 定义标题:我们首先定义一个名为 wiki_titles 的列表,其中包含城市列表。每个城市代表网络爬虫将用其相应的维基百科条目内容填充的文本文件。例如,"Atlanta.txt" 将包含从维基百科上的亚特兰大页面抓取的文本。
- 抓取数据:我们遍历 wiki_titles 中的每个城市,向维基百科 API 发送 GET 请求,并从 JSON 响应中提取页面内容。然后将文本保存到每个城市的相应文本文件中。
from pathlib import Path
import requests
wiki_titles = [
"Atlanta",
"Berlin",
"Boston",
"Cairo",
"Chicago",
"Copenhagen",
"Houston",
"Karachi",
"Lisbon",
"London",
"Moscow",
"Munich",
"Paris",
"Pékin", # French for Beijing
"San Francisco",
"Seattle",
"Shanghai",
"Tokyo",
"Toronto",
]
data_path = Path("./french_city_data")
data_path.mkdir(exist_ok=True) # Ensure directory exists
for title in wiki_titles:
response = requests.get(
"https://fr.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page.get("extract", "") # Use .get() to avoid KeyError
if wiki_text: # Check if the extract is not empty
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
else:
print(f"No extract found for {title}")
准备您的环境
首先,通过安装必要的库来设置您的开发环境:Milvus 向量数据库、LangChain、OpenAI 和 sentence transformers。
此外,如果您通过 API 连接到 LLM,例如 OpenAI,您还需要包含您的 API 密钥。这个密钥可以存储在一个单独的 .env 文件中,并使用 load_dotenv() 和 os 访问。
以下是安装库和加载您的 API 密钥的代码:
!pip install -qU pymilvus langchain sentence-transformers tiktoken openai
from dotenv import load_dotenv
import os
load_dotenv() # Load environment variables from the .env file
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY") # Set the API key
- 安装库:使用 pip 安装 pymilvus、langchain、sentence-transformers、tiktoken 和 openai。
- 加载环境变量:使用 dotenv 从 .env 文件加载环境变量。
- 设置 API 密钥:从环境变量中检索 OpenAI API 密钥并设置它。
确保您的 .env 文件包含您的 OpenAI API 密钥,格式如下:
OPENAI_API_KEY=your_api_key_here
初始化 LLM
设置好环境后,下一步是定义您将在应用程序中使用的 LLM。下面的代码片段通过导入 OpenAI 库并使用 OpenAI 的构造函数定义 LLM 来实现这一点。
from langchain.llms import OpenAI
llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
您可以选择一个开源 LLM 以避免与 OpenAI API 调用相关的成本。Hugging Face 提供了数十万个深度学习模型供您尝试。要使用 HuggingFace 的开源 LLM,您需要导入 Transformers 库。
from transformers import pipeline
llm = pipeline('text-generation', model='gpt2') # Replace 'gpt2' with your desired model
您可以通过修改相关的导入和初始化代码,在 OpenAI 和开源模型之间切换。
选择适当的嵌入模型
在构建多语言 RAG 系统时,我们选择的嵌入模型与我们选择的 LLM 一样重要,因为嵌入模型必须与您正在处理的语言兼容。在这个例子中,由于语言是法语,所以默认的 HuggingFace 嵌入就足够了。然而,您必须确定并使用其他语言最合适的嵌入模型。
HuggingFace 上的 MTEB 排行榜是寻找嵌入模型的宝贵资源。这个排行榜列出了各种语言的顶级嵌入模型,如 Yujian 确定的中文和波兰语嵌入。在选择嵌入模型时,您需要将模型名称作为参数指定。
以下是如何设置嵌入模型的代码:
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
# Alternatively, for the Chinese embeddings, the model is # passed as a parameter, e.g.,
# HuggingFaceEmbeddings(model_name="TownsWu/PEG")
加载和分割数据为块
接下来,加载我们从维基百科抓取的城市数据文件,并将它们分割成段或块。通过分块文本,我们避免了将查询与整个文档进行比较,这提高了信息检索效率。块越小,由 chunk_size 参数决定,准确性越高,但需要的检索操作就越多。块之间的重叠越多,由 chunk_overlap 定义,丢失上下文的可能性就越小 - 以增加冗余为代价。
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
files = os.listdir("./french_city_data")
file_texts = []
for file in files:
with open(f"./french_city_data/{file}") as f:
file_text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64,
)
texts = text_splitter.split_text(file_text)
for i, chunked_text in enumerate(texts):
file_texts.append(Document(page_content=chunked_text,
metadata={"doc_title": file.split(".")[0], "chunk_num":i}))
将文档加载到 Milvus
在将城市数据文件分块并存储为文档列表后,我们需要将它们加载到向量存储中 - 在这种情况下,是 Milvus 向量数据库。下面的代码处理初始加载和更新,当城市数据存储在 Milvus 中时。
from langchain_community.vectorstores import Milvus
# For the first run
vector_store = Milvus.from_documents(
file_texts,
embedding=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="french_cities"
)
# if your data is already stored in Milvus
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="french cities"
)
创建检索器
接下来,我们将初始化检索器,这是一个根据给定查询返回特定来源文档的接口。下面的代码使用我们在上一步创建的向量存储作为检索器,并将其分配给一个变量。
retriever = vector_store.as_retriever()
使用 LangChain 创建提示模板
提示模板允许您在应用程序中精确格式化输入到 LLM 的内容。它们在您可能想要重用相同的提示大纲但进行小幅调整的实例中特别有用 - 就像我们的多语言 RAG 应用一样,我们可以使用相同的提示模板处理各种语言。
提示模板还允许您从动态输入构建提示,例如,用户输入或从向量存储检索的数据。在我们的应用程序中,我们将动态包括将直接传递到链中的查询,以及检索器从向量存储中获得的上下文。
from langchain.prompts import ChatPromptTemplate
template="""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Answer in French.
Question: {question}
Context: {context}
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
将组件链接在一起以创建 RAG 应用
链接是连接组件以创建端到端 AI 应用程序的过程,这是 LangChain 的关键能力之一。
下面的代码演示了如何构建一个包含以下元素的链:检索器的上下文,由 runnablepassthrough() 函数处理的输入提示,提示模板,LLM,以及 stroutparser(),它输出链调用的响应。
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
使用链进行查询
一旦构建了链,您可以使用各种查询调用它。例如:
response = chain.invoke("Tell me a historical fact about Karachi.")
这个查询产生了以下法语回答!
"Karachi a été mentionnée pour la première fois dans l'ouvrage Histoire des plantes de Théophraste au IIIe siècle av. J.-C. Elle a été occupée par les Britanniques au début du XIXe siècle et est devenue la capitale du Sind en 1839. En 1876, le futur fondateur du Pakistan, Muhammad Ali Jinnah, est né et enterré à Karachi."
为了演示多语言能力,这里是另一个用法语的查询:
response_2 = chain.invoke("Racontez-moi un fait historique sur Karachi.")
尽管底层问题相同,但不同的语言(英语和法语)导致不同的嵌入,从而产生不同的输出:
"Karachi est une ville qui a été fondée par les Britanniques au début du XIXe siècle et qui est devenue la capitale du Sind. Elle a été un important centre économique et a connu une croissance rapide, notamment grâce à son port. Depuis les années 1980, la ville a été le théâtre de conflits ethniques et religieux, et en 2012, elle a été le site de l'incendie industriel le plus meurtrier de l'histoire."
恭喜!您已成功构建了一个多语言 RAG 应用。请记住,嵌入是 LLM 解释语言的核心。选择最合适的嵌入以支持多种语言,并将其集成到您的应用程序中。
总结
哇!这是一篇相当长的文章。让我们回顾一下其中的一些关键点。
- 检索增强生成(RAG)是一个框架,它通过将额外的数据插入输入提示来增强 LLM 输出。RAG 可以解决烦人的 LLM 幻觉问题。
- 多语言 RAG 是处理多语言文档的扩展 RAG。
- 嵌入模型、向量数据库和 LLM 是 RAG 应用的三个核心组件。
- 开发多语言 RAG 应用的关键考虑因素是选择嵌入模型。HuggingFace 的 MTEB 排行榜是寻找适合您应用程序的正确模型的绝佳资源。
注:本文为AI翻译,查看原文
 Tim Mugabi
Tim MugabiFreelance Technical Writer