使用LangChain和Milvus构建具有长期记忆的会话AI代理
大型语言模型(LLMs)改变了人工智能(AI)的游戏规则。这些先进的模型可以轻松理解并生成具有令人印象深刻准确性的类似人类文本,使AI助手和聊天机器人变得更智能、更有用。多亏了LLMs,我们现在拥有的AI工具可以处理复杂的语言任务,从回答问题到翻译语言。
会话代理是与用户用自然语言聊天的软件程序,就像与真人交谈一样。它们为聊天机器人和虚拟助手提供支持,通过理解和响应我们的问题和命令,帮助我们完成日常任务。
LangChain是一个开源框架,它提供了便捷的工具和模板,以快速高效地创建智能、上下文感知的聊天机器人和其他AI应用。
LangChain代理简介
LangChain代理是使用LLM与不同工具和数据源交互以完成复杂任务的高级系统。这些代理可以理解用户输入,做出决策,并创建响应,使用LLM提供比传统方法更灵活和适应性强的决策。
LangChain代理的一个很大优势是它们能够使用外部工具和数据源。这意味着它们可以收集信息、执行计算并采取行动,而不仅仅是处理语言,使它们在各种应用中更强大、更有效。
LangChain代理与链
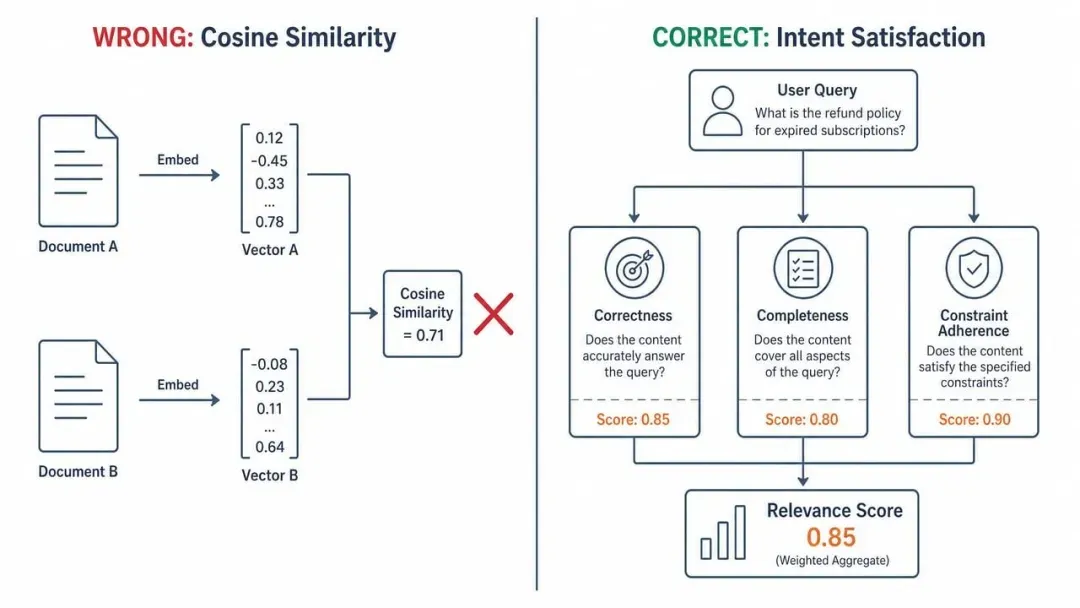
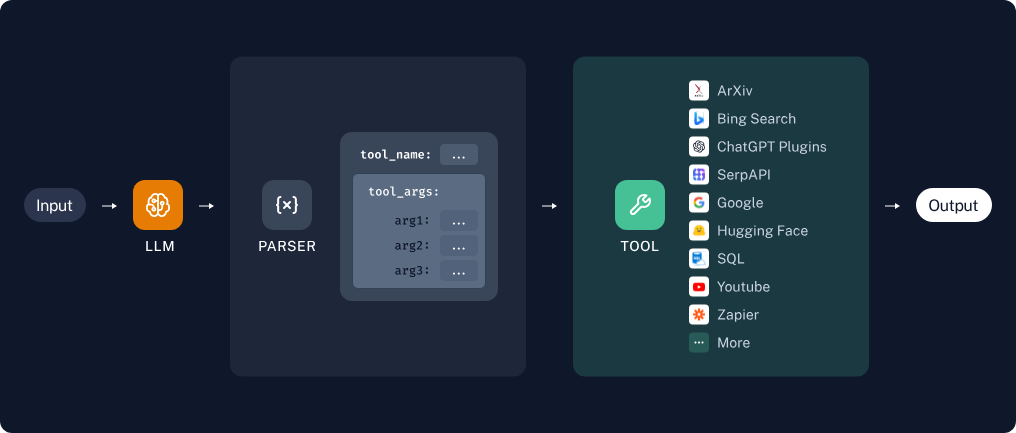
链和代理是LangChain中使用的两个主要工具。链允许您创建一个预定的工具使用顺序,这对于需要特定操作顺序的任务非常有用。
 How_Lang_Chain_Chains_work_b15cd2e788.png
How_Lang_Chain_Chains_work_b15cd2e788.png
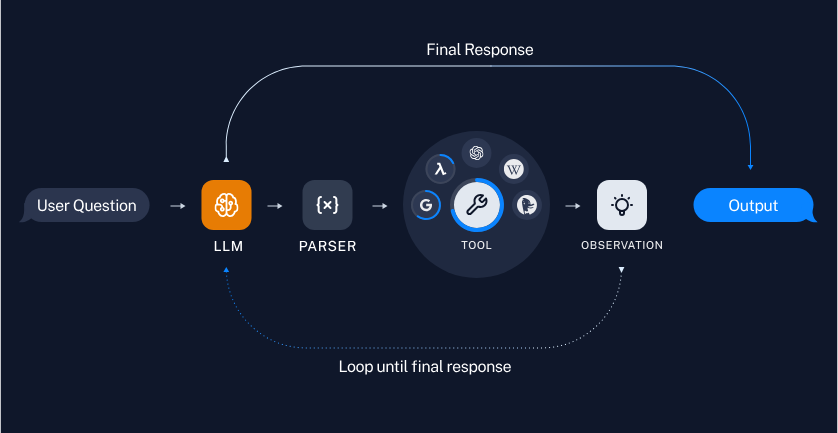
另一方面,代理允许大型语言模型在一个循环中使用工具,允许它决定使用工具的次数。这种灵活性非常适合需要迭代处理或动态决策的任务。
 How_Lang_Chain_Agents_work_de7b0757ce.png
How_Lang_Chain_Agents_work_de7b0757ce.png
使用LangChain构建会话代理
让我们使用LangChain在Python中构建一个会话代理。
安装依赖项
要构建LangChain代理,我们需要安装以下依赖项:
- LangChain:LangChain是一个开源框架,帮助开发人员使用大型语言模型(LLMs)创建应用程序。
- Langchain OpenAI:此包包含通过它们的openai SDK进行LangChain集成的OpenAI。
- OpenAI API SDK:OpenAI Python库提供了方便的访问OpenAI REST API的方式,适用于任何Python 3.7+应用程序。
- Dotenv:Python-dotenv从一个.env文件中读取键值对,并可以将它们设置为环境变量。
- Milvus:Milvus是一个开源向量数据库,最适合十亿规模的向量存储和相似性搜索。它也是构建检索增强生成(RAG)应用程序的流行基础设施组件。
- Pymilvus:Milvus的Python SDK。它集成了许多流行的嵌入和重新排名模型,简化了RAG应用程序的构建。
- Tiktoken:一个快速的BPE标记器,用于OpenAI的模型。
您可以通过执行以下命令来安装它们:
pip install langchain==0.1.20 langchain-openai openai python-dotenv pymilvus langchain_milvus tiktoken
请注意,我们将在本示例中特别使用LangChain版本0.1.20。
安装完所有依赖项后,让我们编写代码来设置一个简单的会话代理。
加载环境变量
首先,我们将使用dotenv包加载环境变量。这个包有助于保护敏感信息,如API密钥。
from dotenv import load_dotenv
load_dotenv()
确保您的项目目录中有一个.env文件,其中包含您的OpenAI API密钥。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
初始化OpenAI LLM
接下来,我们将使用langchain_openai包初始化OpenAI LLM。
from langchain_openai import OpenAI
llm = OpenAI()
创建对话链
我们使用langchain.chains中的ConversationChain类来创建一个对话代理。这个链将处理与用户的对话。
from langchain.chains import ConversationChain
conversation = ConversationChain(
llm=llm,
)
进行预测
最后,我们可以通过将用户输入传递给对话链来进行预测。在这个例子中,我们向代理提出了一个简单的问题。
answer = conversation.predict(input="What's my name?")
print(answer)
完整代码示例
将所有步骤结合起来,这是完整的代码。
from dotenv import load_dotenv
from langchain_openai import OpenAI
from langchain.chains import ConversationChain
load_dotenv()
llm = OpenAI()
conversation = ConversationChain(
llm=llm,
)
answer = conversation.predict(input="What's my name?")
print(answer)
运行代码
要运行代码,请确保您已经设置了.env文件并包含了您的OpenAI API密钥。然后,执行您的Python脚本。您应该看到代理对问题做出响应的输出,展示了LangChain框架的会话能力。
运行Python脚本后,您应该得到类似的响应:
> I do not have access to your personal information, so I am unable to answer that question accurately. Could you please provide me with your name so I can address you properly?
恭喜!您已成功使用LangChain构建了一个基本的会话代理。这个例子只是开始。有了LangChain,您可以根据需要构建更复杂、更有能力的AI代理。
会话代理中记忆的重要性
然而,当我们问我们的代理“我的名字是什么?”时,它无法正确回答,因为它没有之前互动的记忆。这种记忆的缺失限制了会话代理的实用性,因为它们无法保留有关用户或对话上下文的重要信息。通过整合记忆,我们的代理可以记住过去互动中的关键细节,使响应更准确和个性化。
使用LangChain和Milvus构建具有长期记忆的会话代理
Milvus是一个高性能的开源向量数据库,旨在高效存储和检索十亿规模的向量。它被广泛用于语义搜索和检索增强生成(RAG)等GenAI用例。它也是为LLM添加长期记忆的重要基础设施组件。
Milvus Lite是Milvus的轻量级版本,可以运行在您的本地设备上。在这个例子中,我们将使用Milvus Lite作为向量存储来存储和检索我的私有数据。
现在,让我们使用LangChain和Milvus Lite增强我们的会话代理,使其具有长期记忆。
安装要求
首先,如果您还没有安装所需的包,请安装它们。
pip install langchain==0.1.20 langchain-openai python-dotenv openai pymilvus tiktoken
现在,让我们逐步编写代码。
加载环境变量
使用dotenv包加载环境变量。这一步有助于保护敏感信息,如API密钥。
from dotenv import load_dotenv
load_dotenv()
确保您的项目目录中有一个.env文件,其中包含您的OpenAI API密钥。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
初始化OpenAI LLM和嵌入
使用langchain_openai包初始化OpenAI LLM和嵌入。
from langchain_openai import OpenAI, OpenAIEmbeddings
llm = OpenAI()
embeddings = OpenAIEmbeddings()
设置Milvus作为向量存储
设置Milvus向量数据库以存储和检索您的数据。
from langchain_milvus.vectorstores import Milvus
vectordb = Milvus(
embeddings,
connection_args={"uri": "./milvus_demo.db"},
# The easiest way is to use Milvus Lite where everything is stored in a local file.
# If you have a Milvus server you can use the server URI such as "http://localhost:19530".
)
retriever = vectordb.as_retriever( search_kwargs=dict(k=1))
为代理创建记忆
使用向量检索器设置记忆。
from langchain.memory import VectorStoreRetrieverMemory
memory = VectorStoreRetrieverMemory(retriever=retriever)
保存初始上下文
向记忆中添加一些初始信息。
about_me = [
{"input": "My name is Bob.", "output": "Got it!"},
{"input": "I'm from San Francisco.", "output": "Got it!"},
]
for example in about_me:
memory.save_context({"input": example["input"]}, {"output": example["output"]})
定义提示模板
创建包含记忆的提示模板。
from langchain.prompts import PromptTemplate
prompt_template = """The following is a friendly conversation between a user and a chatbot. The chatbot is talkative and provides lots of specific details from its context. If the chatbot does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
User: {input}
Chatbot:"""
prompt = PromptTemplate(input_variables=["history", "input"], template=prompt_template)
创建具有记忆的对话链
设置对话链以使用提示和记忆。
from langchain.chains import ConversationChain
conversation_with_memory = ConversationChain(
llm=llm, prompt=prompt, memory=memory, verbose=True
)
进行预测
最后,向代理提一个问题,看看它如何使用它的记忆。
完整代码示例
将所有步骤结合起来,这是完整的代码。
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_openai import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
from langchain_milvus.vectorstores import Milvus
load_dotenv()
llm = OpenAI()
embeddings = OpenAIEmbeddings()
vectordb = Milvus(
embeddings,
connection_args={"uri": "./milvus_demo.db"},
)
retriever = vectordb.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
about_me = [
{"input": "My name is Bob.", "output": "Got it!"},
{"input": "I'm from San Francisco.", "output": "Got it!"},
]
for example in about_me:
memory.save_context({"input": example["input"]}, {"output": example["output"]})
prompt_template = """The following is a friendly conversation between a user and a chatbot. The chatbot is talkative and provides lots of specific details from its context. If the chatbot does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
User: {input}
Chatbot:"""
prompt = PromptTemplate(input_variables=["history", "input"], template=prompt_template)
conversation_with_memory = ConversationChain(
llm=llm, prompt=prompt, memory=memory, verbose=True
)
answer = conversation_with_memory.predict(input="What's my name?")
print(answer)
运行代码
设置您的.env文件并包含您的OpenAI API密钥以运行代码。然后,执行您的Python脚本。您应该看到代理对问题做出响应的输出,展示了LangChain框架与记忆集成的增强功能。
运行Python脚本后,您应该得到类似的响应:
> Your name is Bob. Did you know that the name Bob is a diminutive form of the name Robert, which means "bright fame" in Germanic languages? It was a popular name during the Middle Ages and has been used by many famous people throughout history. Do you know any famous people named Bob?
恭喜!您已成功使用LangChain和Milvus构建了一个具有长期记忆的会话代理。这个例子展示了记忆如何显著增强代理提供准确和个性化响应的能力。有了LangChain和Milvus,您可以根据需要构建更先进、更有能力的AI代理。
总结
在本文中,我们探索了LangChain代理的迷人世界及其转变会话AI的潜力。我们从LangChain的基础知识开始,了解其在构建高级、上下文感知的会话代理中的作用。然后,我们探索了使用LangChain创建简单代理的实际操作步骤,强调了没有记忆的代理的局限性。
为了解决这些局限性,我们演示了如何使用Milvus Lite将长期记忆整合到您的代理中,展示了这种增强功能如何使代理能够保留重要信息并提供更准确、个性化的响应。
鼓励实验
现在您已经对LangChain有了基础了解,并且知道如何构建会话代理,是时候进行实验了!尝试构建更复杂的代理,整合更多工具,并探索不同的用例。LangChain的灵活性和强大功能使其成为一个推动会话AI极限的绝佳框架。
要深入了解LangChain和Milvus,请查看它们的官方文档和推荐教程:
通过探索这些资源,您将获得更全面的了解,并更好地准备构建高级、智能的会话代理。编码愉快!
注:本文为AI翻译,查看原文
 Rok Benko
Rok BenkoFreelance Technical Writer