使用自部署的Milvus向量数据库和Snowpark容器服务构建RAG
Zilliz的生态系统和AI平台负责人Jiang Chen在最近的非结构化数据 meetup 上讨论了我们如何将Milvus与Snowflake无缝集成。具体来说,他探索了如何使用Milvus向量数据库和Snowpark容器服务(SPCS)与Snowflake生态系统集成来构建检索增强生成(RAG)系统。
这篇文章将回顾Jiang的主要观点,并涵盖三个重要主题。
首先,我们将讨论使用Milvus进行向量搜索,这是构建RAG系统的关键步骤。接下来,我们将讨论如何使用SPCS将Milvus集成到Snowflake中。最后,我们还将讨论RAG的未来前景。在深入这些主题之前,让我们探索AI如何转变信息检索。
AI如何彻底改变信息检索过程
AI的进步和普及迅速改变了整个信息检索的格局。在AI崛起之前,信息检索严重依赖于统计模型和关键词匹配方法,如标记。例如,在线商店老板需要手动为每个产品输入标签到预定义的类别中。如果他们有大量的产品目录,这个过程将是不切实际的。
同样地,作为顾客,我们需要输入适当的标签来获得我们想要的确切产品。问题是,如果我们输入一个与我们想要的产品含义相近但不完全相同的标签,通过标记方法的信息检索将无法给我们提供适当的产品。换句话说,标记方法不考虑查询的语义含义。
 AI_revolutionizes_how_we_use_unstructured_data_d9c61859e0.png
AI_revolutionizes_how_we_use_unstructured_data_d9c61859e0.png
AI彻底改变了我们使用非结构化数据的方式
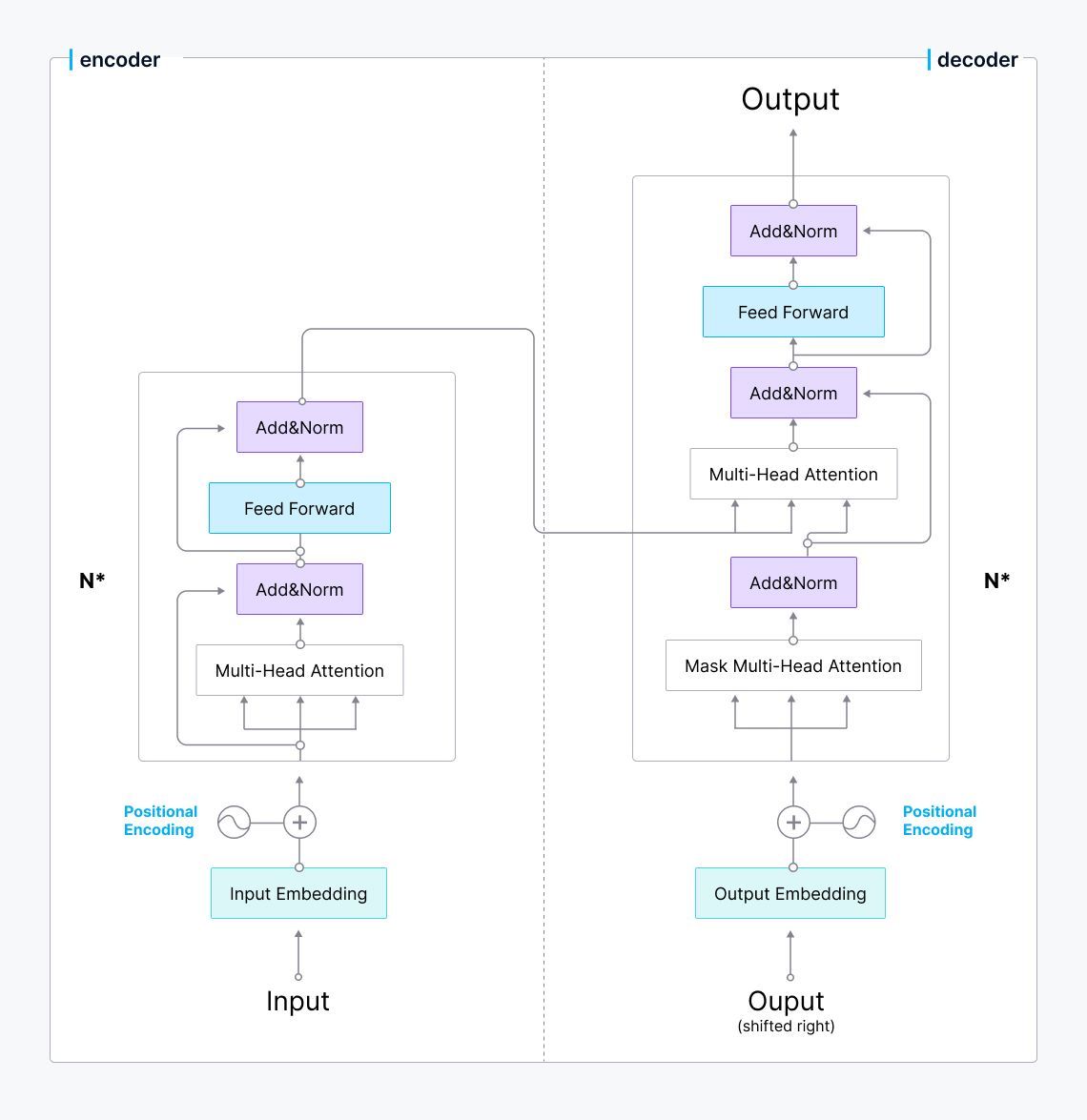
嵌入模型的出现彻底改变了我们检索信息的方式。大多数嵌入模型使用著名的Transformer架构作为它们的骨干。Transformer模型利用多个编码器-解码器块,每个块都包含一个专门的注意力层。这一层使模型能够感知每个输入标记与整个输入序列的语义含义,使嵌入模型能够推断输入词的语义含义。
 Image_title_Transformer_architecture_03ed304894.jpg
Image_title_Transformer_architecture_03ed304894.jpg
Transformer架构
嵌入模型将查询、图像或文本描述转换为称为向量嵌入的数值表示。向量嵌入包含了它所代表输入的语义丰富的意义,我们可以通过余弦相似度或余弦距离来比较两个向量嵌入之间的相似性。如果相似性很高,那么两个向量嵌入就有相似的含义,反之亦然。
 Image_title_Raw_texts_to_vector_embeddings_8056a84088.png
Image_title_Raw_texts_to_vector_embeddings_8056a84088.png
原始文本到向量嵌入
由于这些强大的特性,嵌入模型使实现信息检索概念变得更加容易和灵活。
检索增强生成(RAG)
嵌入模型的快速发展和大型语言模型(LLM)的兴起导致了RAG的诞生,这是一种非常复杂的信息检索方法。RAG旨在通过提供来自内部知识库的相关上下文以及查询,来增强LLM的响应质量。然后,LLM将使用提供的上下文来回答查询。
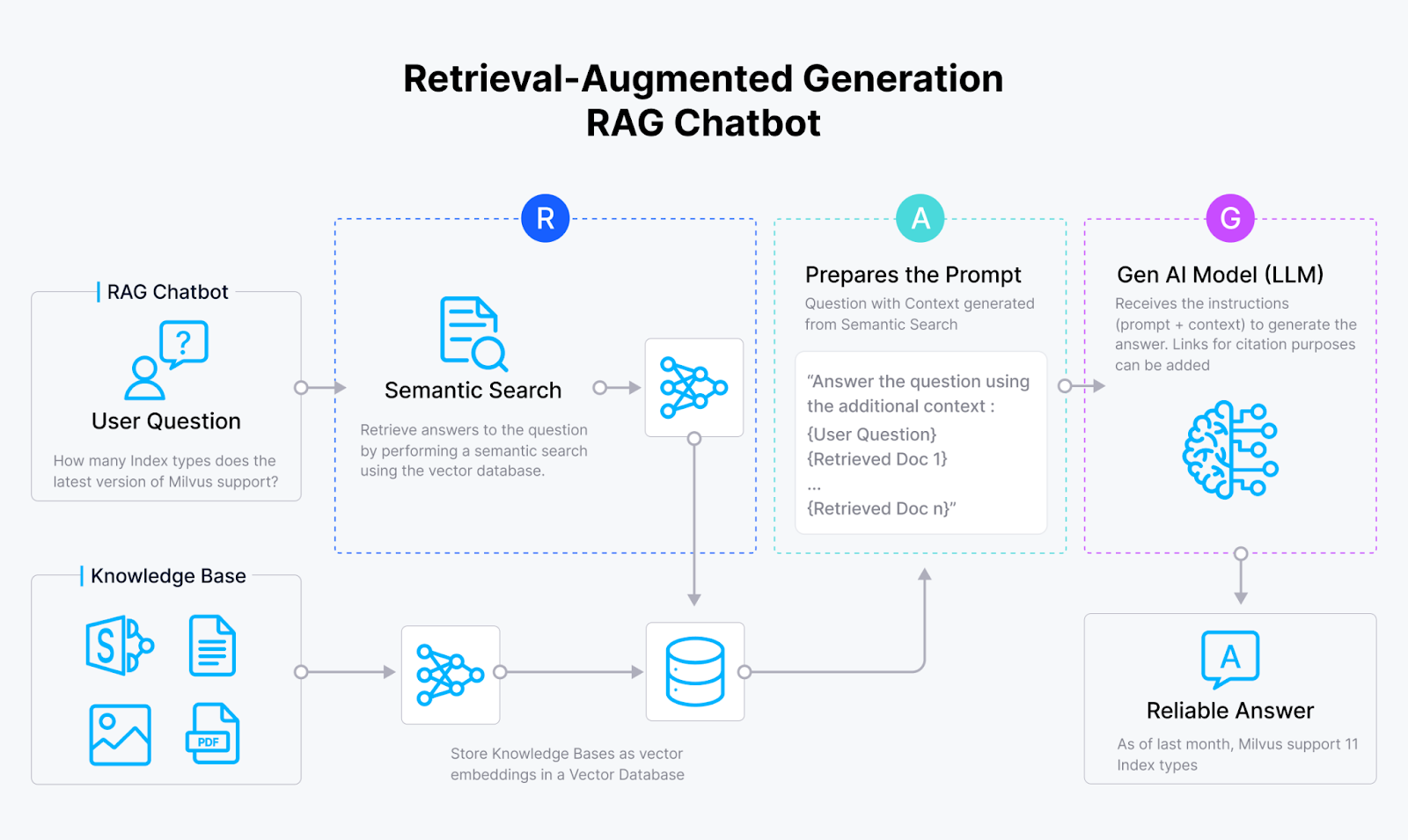 RAG_chatbot_03e36cd708.png
RAG_chatbot_03e36cd708.png
RAG架构
在RAG应用中,我们使用选定的嵌入模型将我们的数据和输入查询转换为嵌入。然后,我们计算查询的嵌入与我们自己数据的嵌入之间的相似性。与我们查询最相似的数据将作为上下文与我们的查询一起传递给LLM。最终,我们的LLM可以根据提供的上下文生成对查询的回答。通过这种方式,我们可以在不需要微调的情况下增强LLM的响应准确性。
将Milvus向量数据库和Snowflake与Snowpark容器服务集成
Milvus是一个开源的向量数据库,它使您能够存储大量对RAG应用有用的向量嵌入,并在瞬间对它们执行向量搜索。有几种安装和使用Milvus的选项:
Milvus Lite:Milvus的轻量级版本,适合快速原型设计。Milvus Lite不需要服务器;您可以在自己的设备上运行它。安装过程简单,只需使用pip install命令
(!pip install "pymilvus>=2.4.2"
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db"))
Milvus在Docker中:如果您想在生产中使用您的Milvus向量数据库并且只有少量数据,您可以将其作为Docker容器运行。这个过程也很简单,只需要在命令行中运行以下命令:
# Download the installation script
$ curl -sfL <https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh> -o standalone_embed.sh
# Start the Docker container
$ bash standalone_embed.sh start
# In your Python IDE
from pymilvus import MilvusClient
client = MilvusClient(
uri="<http://milvus:19530>",
)
Milvus在Kubernetes中:如果您有大量数据或您的RAG应用有大量用户,这个选项适合您。您可以使用Kubernetes存储高达100亿个向量。与Milvus Lite和Docker的安装过程相比,使用Kubernetes的安装过程有点复杂。因此,请参阅安装文档以获取详细信息。
Milvus提供了与流行的AI工具包(如OpenAI、HuggingFace、Cohere、LangChain、LlamaIndex和Snowflake)的无缝集成。这些集成使得构建您自己的RAG系统或其他GenAI应用变得容易。本节将向您展示如何在Snowflake生态系统内运行Milvus。
 Milvus_offers_seamless_integration_with_all_popular_AI_toolkits_20c34552aa.png
Milvus_offers_seamless_integration_with_all_popular_AI_toolkits_20c34552aa.png
Milvus与所有流行的AI工具包提供无缝集成
Snowflake是一个数据仓库平台,使您能够高效、可靠地存储、处理和分析数据。随着Snowpark容器服务(SPCS)的引入,您现在可以在Snowflake环境中运行容器化应用程序。这样,您的应用程序可以与存储在Snowflake中的数据交互,允许您构建包括RAG系统在内的各种应用程序。
在本节中,我们首先使用Milvus构建一个执行向量搜索的应用程序。接下来,我们使用Docker容器化应用程序,并在Snowflake中使用SPCS运行容器。
首先,让我们使用Jupyter Notebook构建一个执行向量搜索的Milvus应用程序。如果您想跟随操作,请参阅此存储库,完整的笔记本和构建嵌入模型的脚本。
from pymilvus import MilvusClient
from pymilvus import DataType
import os
import mode
# init client
client = MilvusClient(
uri="<http://milvus:19530>",
)
# init model
model = model.Onnx()
# Create a collection in quick setup mode
client.create_collection(
collection_name="quick_demo",
dimension=model.dimension,
)
print("Collection Created!")
在上述代码中,我们在Milvus向量数据库中创建了一个名为“quick_demo”的集合,并加载了模型以将文本转换为嵌入。我们使用ALBERT作为我们的嵌入模型,它将输入文本映射到一个768维的向量嵌入。
接下来,在我们的“quick_demo”集合中插入一些文本数据。
# Data from which embeddings are to be generated
docs=[
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
# Insert data into the collection
data=[]
for i in range(len(docs)):
data.append({
'id': i,
'vector': model.to_embeddings(docs[i]),
'doc_str': docs[i]
})
res = client.insert(
collection_name="quick_demo",
data=data
)
在上述代码中,我们使用ALBERT将输入文本转换为嵌入,并将它们连同它们的ID和原始文本一起存储在集合中。
现在,如果我们有一个查询,比如“谁开始了人工智能研究?”我们想要获得可能包含我们查询答案的相关上下文,我们可以使用Milvus轻松执行向量搜索,如下所示:
# Search with a text query
query = "Who started AI research?"
query_embeddings = model.to_embeddings(query)
res = client.search(
collection_name="quick_demo",
data=[query_embeddings],
limit=1,
output_fields=["doc_str"],
)
print(res)
"""
Expected output:
"Alan Turing was the first person to conduct substantial research in AI."
"""
这就是我们的Milvus应用程序。
在这个阶段,我们有一个Jupyter Notebook来执行Milvus的向量搜索。假设我们想要将这个笔记本容器化,以便在Snowflake生态系统内运行。我们需要做的第一件事是配置角色和权限,以创建和运行Snowflake提供的服务。
首先,按照安装SnowSQL文档页面上的说明下载SnowSQL。接下来,在终端中运行以下命令:
snowsql -a ${instance_name} -u ${user_name}
其中{org_name}-${acct_name},您可以在Snowflake账户中找到这两个字段的信息。现在我们可以在SnowSQL shell中使用以下命令配置角色和权限:
USE ROLE ACCOUNTADMIN;
CREATE SECURITY INTEGRATION SNOWSERVICES_INGRESS_OAUTH
TYPE=oauth
OAUTH_CLIENT=snowservices_ingress
ENABLED=true;
USE ROLE ACCOUNTADMIN;
GRANT BIND SERVICE ENDPOINT ON ACCOUNT TO ROLE SYSADMIN;
USE ROLE SECURITYADMIN;
CREATE ROLE MILVUS_ROLE;
USE ROLE USERADMIN;
CREATE USER milvus_user
PASSWORD='milvususerok'
DEFAULT_ROLE = MILVUS_ROLE
DEFAULT_SECONDARY_ROLES = ('ALL')
MUST_CHANGE_PASSWORD = FALSE;
USE ROLE SECURITYADMIN;
GRANT ROLE MILVUS_ROLE TO USER milvus_user;
由于Snowflake是一个数据仓库平台,我们通过类似SQL查询的命令与Snowflake中的所有对象进行交互,如上所示。接下来,我们可以使用以下命令在Snowflake中创建数据仓库和数据库:
USE ROLE SYSADMIN;
CREATE OR REPLACE WAREHOUSE MILVUS_WAREHOUSE WITH
WAREHOUSE_SIZE='X-SMALL'
AUTO_SUSPEND = 180
AUTO_RESUME = true
INITIALLY_SUSPENDED=false;
USE ROLE SYSADMIN;
CREATE DATABASE IF NOT EXISTS MILVUS_DEMO;
USE DATABASE MILVUS_DEMO;
CREATE IMAGE REPOSITORY MILVUS_DEMO.PUBLIC.MILVUS_REPO;
CREATE OR REPLACE STAGE YAML_STAGE;
CREATE OR REPLACE STAGE DATA ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
CREATE OR REPLACE STAGE FILES ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
--GRANT ROLE PRIVILEGES--
USE ROLE SECURITYADMIN;
GRANT ALL PRIVILEGES ON DATABASE MILVUS_DEMO TO MILVUS_ROLE;
GRANT ALL PRIVILEGES ON SCHEMA MILVUS_DEMO.PUBLIC TO MILVUS_ROLE;
GRANT ALL PRIVILEGES ON WAREHOUSE MILVUS_WAREHOUSE TO MILVUS_ROLE;
GRANT ALL PRIVILEGES ON STAGE MILVUS_DEMO.PUBLIC.FILES TO MILVUS_ROLE;
--CONFIGURE ACL--
USE ROLE ACCOUNTADMIN;
USE DATABASE MILVUS_DEMO;
USE SCHEMA PUBLIC;
CREATE NETWORK RULE allow_all_rule
TYPE = 'HOST_PORT'
MODE= 'EGRESS'
VALUE_LIST = ('0.0.0.0:443','0.0.0.0:80');
CREATE EXTERNAL ACCESS INTEGRATION allow_all_eai
ALLOWED_NETWORK_RULES=(allow_all_rule)
ENABLED=TRUE;
GRANT USAGE ON INTEGRATION allow_all_eai TO ROLE SYSADMIN;
要在Snowflake内运行容器化应用程序,我们需要在本地机器上构建应用程序的Docker映像。在这个项目中,我们需要构建两个不同的Docker映像:一个用于实例化Milvus向量数据库,一个用于运行我们上面创建的笔记本文件。
然而,我们需要一个Dockerfile来构建Docker映像。为了简化事情,克隆以下存储库。您将在这个存储库中找到构建我们需要的两个映像的所有必要文件。克隆存储库后,您可以使用以下命令在本地终端构建两个Docker映像:
cd ${repo_git_root_path}
docker build --rm --no-cache --platform linux/amd64 -t milvus ./images/milvus
docker build --rm --no-cache --platform linux/amd64 -t jupyter ./images/jupyter
然后,我们可以使用以下命令为两个新构建的映像添加适当的标签:
docker login ${instance_name}.registry.snowflakecomputing.com -u ${user_name}
docker tag milvus ${instance_name}.registry.snowflakecomputing.com/milvus_demo/public/milvus_repo/milvus
docker tag jupyter ${instance_name}.registry.snowflakecomputing.com/milvus_demo/public/milvus_repo/jupyter
最后,我们可以使用以下命令将映像推送到SPCS:
docker push ${instance_name}.registry.snowflakecomputing.com/milvus_demo/public/milvus_repo/milvus
docker push ${instance_name}.registry.snowflakecomputing.com/milvus_demo/public/milvus_repo/jupyter
现在我们已经将映像推送到SPCS,我们需要做的就是创建两个计算服务,每个映像一个,如您在SnowSQL shell中的以下命令中看到的:
USE ROLE SYSADMIN;
CREATE COMPUTE POOL IF NOT EXISTS MILVUS_COMPUTE_POOL
MIN_NODES = 1
MAX_NODES = 1
INSTANCE_FAMILY = CPU_X64_S
AUTO_RESUME = true;
CREATE COMPUTE POOL IF NOT EXISTS JUPYTER_COMPUTE_POOL
MIN_NODES = 1
MAX_NODES = 1
INSTANCE_FAMILY = CPU_X64_S
AUTO_RESUME = true;
在我们之前克隆的存储库中有一个名为“specs”的文件夹。在该文件夹中有两个YAML文件,每个映像一个。打开每个YAML文件,并根据您的Snowflake账户更改image字段中的{acct_name}。
接下来,使用SnowSQL上传修改后的YAML文件:
PUT file://${path/to/jupyter.yaml} @yaml_stage overwrite=true auto_compress=false;
PUT file://${path/to/milvus.yaml} @yaml_stage overwrite=true auto_compress=false;
最后,我们可以按照以下方式为两个映像创建服务:
USE ROLE SYSADMIN;
USE DATABASE MILVUS_DEMO;
USE SCHEMA PUBLIC;
CREATE SERVICE MILVUS
IN COMPUTE POOL MILVUS_COMPUTE_POOL
FROM @YAML_STAGE
SPEC='milvus.yaml'
MIN_INSTANCES=1
MAX_INSTANCES=1;
CREATE SERVICE JUPYTER
IN COMPUTE POOL JUPYTER_COMPUTE_POOL
FROM @YAML_STAGE
SPEC='jupyter.yaml'
MIN_INSTANCES=1
MAX_INSTANCES=1;
现在如果您输入SHOW SERVICE命令,您应该看到以下输出:
SHOW SERVICES;
+---------+---------------+-------------+----------+----------------------+--------------------------------------------------------+-----------------
| name | database_name | schema_name | owner | compute_pool | dns_name | ......
|---------+---------------+-------------+----------+----------------------+--------------------------------------------------------+-----------------
| JUPYTER | MILVUS_DEMO | PUBLIC | SYSADMIN | JUPYTER_COMPUTE_POOL | jupyter.public.milvus-demo.snowflakecomputing.internal | ......
| MILVUS | MILVUS_DEMO | PUBLIC | SYSADMIN | MILVUS_COMPUTE_POOL | milvus.public.milvus-demo.snowflakecomputing.internal | ......
+---------+---------------+-------------+----------+----------------------+--------------------------------------------------------+-----------------
现在,我们已经准备好在Snowflake中运行Milvus向量数据库并测试我们的笔记本。首先,授予我们之前创建的角色访问容器化应用程序的权限。
USE ROLE SECURITYADMIN;
GRANT USAGE ON SERVICE MILVUS_DEMO.PUBLIC.JUPYTER TO ROLE MILVUS_ROLE;
接下来,在Snowflake中检查我们笔记本容器的端点,使用以下命令:
USE ROLE SYSADMIN;
SHOW ENDPOINTS IN SERVICE MILVUS_DEMO.PUBLIC.JUPYTER;
 Jupyter_endpoint_as_shown_in_ingress_url_01949d3073.png
Jupyter_endpoint_as_shown_in_ingress_url_01949d3073.png
Jupyter端点,如ingress_url所示
如果一切运行顺利,您将看到名为“ingress_url”的列作为输出。打开浏览器,复制粘贴该“ingress_url”,您应该可以看到Jupyter启动。然后,您可以在容器内打开笔记本文件,并正常运行笔记本中的每个单元格。
RAG的未来前景
RAG目前是一种非常流行的技术。然而,其当前的应用远非完美。根据Jiang Chen的说法,以下是关于RAG应用未来使用和改进的几个预测。
持续评估和可观察性
随着各种平台或库的可用性,使得简化和抽象RAG开发过程,构建RAG变得更加容易。例如,我们可以通过三个不同的平台:Milvus、LangChain和OpenAI的帮助,在几分钟内构建一个RAG原型。
然而,当我们将由RAG驱动的应用程序从原型转移到生产环境时,我们经常面临挑战。在生产环境中,我们的RAG系统需要处理数百万甚至数十亿的文档,因此至关重要的是持续监控我们的LLM生成的响应质量。
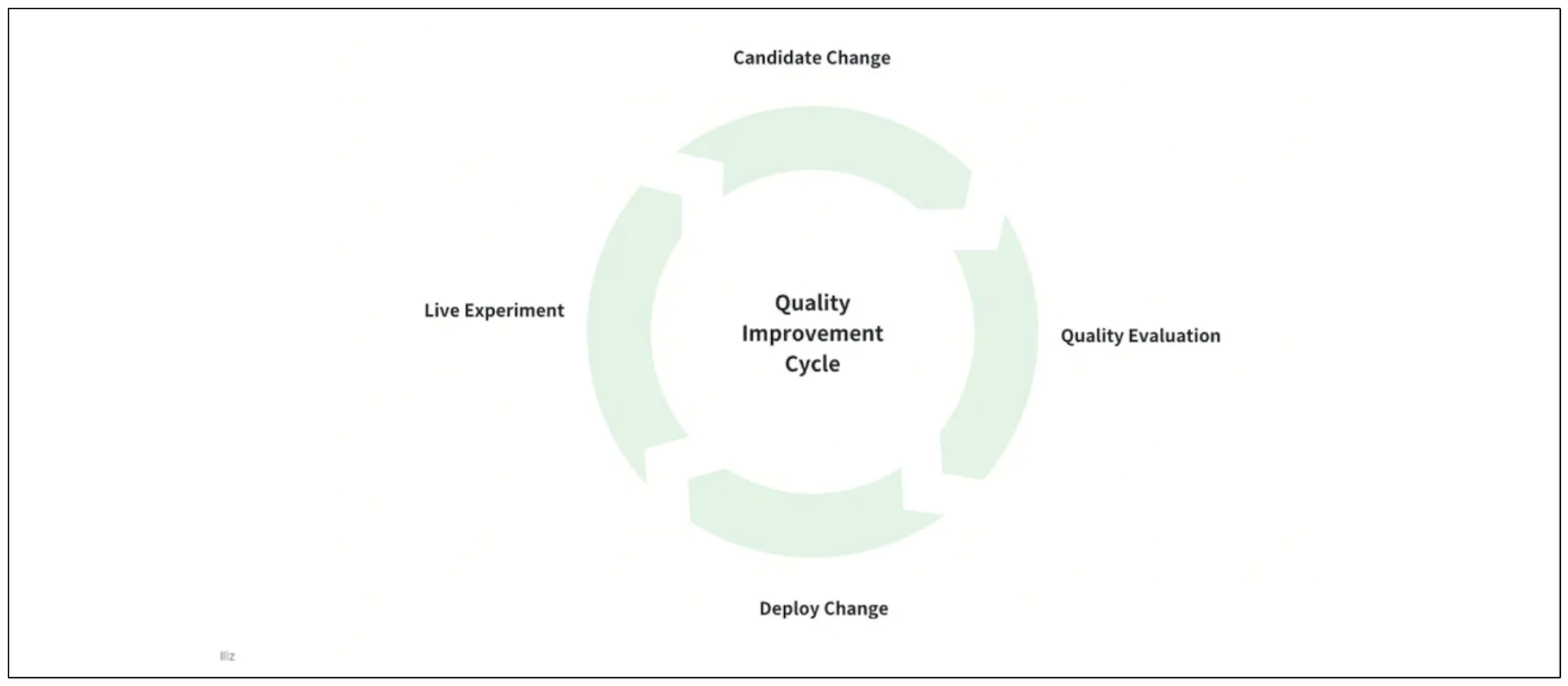 Continuous_evaluation_of_the_RAG_system_7e7453c4cf.png
Continuous_evaluation_of_the_RAG_system_7e7453c4cf.png
RAG系统的持续评估
在实施改进以提高我们RAG的质量之前,重要的是建立一个系统化的方法来持续评估和改进它。
这个系统化方法的一些关键要素包括:
构建一个专门的改进基础设施:在这个基础设施中,我们可以实施各种方法来提高RAG的质量,然后通过A/B测试比较它们的响应。
计划发布周期:一旦我们找到一个根据我们的用例提高RAG质量的方法,我们需要计划如何发布和将其集成到我们的系统中以替换旧的,而不中断用户体验。
实施可观察性系统:我们还需要构建一个系统来观察我们的RAG在生产环境中的性能,并确定其有效性。如果性能不满意,我们可以通过专门的改进基础设施探索和实施改进。
多模态RAG
到目前为止,我们主要在自然语言处理中使用RAG。这意味着我们使用文本作为提示或查询,我们的LLM的响应也是文本形式。
然而,随着近年来多模态嵌入模型的兴起,RAG的未来前景可能会发生变化。多模态RAG之所以成为可能,是因为Transformer可以处理自然语言作为输入以及其他模态,如图像和声音。
Vision Transformers(ViT)和DETR模型已经证明Transformer可以用作强大的图像分类和目标检测模型。在ViT的基础上,OpenAI引入了一个名为CLIP的多模态模型,它可以计算来自不同模态的两个输入之间的相似性:文本和图像。
这些基于Transformer的模型所展示的多模态能力可以作为未来多模态RAG应用的基础。在这个系统中,我们可以使用文本和图像的组合作为查询,LLM将根据我们的多模态查询生成图像。
例如,假设我们希望我们的LLM生成一张与提供的查询图像非常相似的图像。我们可以通过添加文本描述来丰富我们的查询图像,以进一步微调我们希望LLM生成的图像类型,如下所示的可视化:
 Multi_modal_RAG_application_combination_of_text_and_image_queries_36fd637a39.png
Multi_modal_RAG_application_combination_of_text_and_image_queries_36fd637a39.png
多模态RAG应用,文本和图像查询的组合
在上述可视化中,我们要求我们的嵌入模型返回类似于左上角图像的图像,并且我们在左上角图像旁边添加了一个文本提示,如“黄金时段的山脉图片”。结果是基于多模态查询生成的其他三张图像。
这种多模态方法到RAG为更直观和富有表现力的信息检索和生成开辟了新的可能性,结合了文本和视觉模态的优势。
良好的RAG来自良好的数据
我们的RAG系统的质量严重依赖于我们数据库中的数据质量。因此,当由我们的RAG生成的响应不是最优的时候,我们不应该急于得出模型需要改进的结论。首先,我们需要始终检查数据的质量。
如您所知,RAG的响应质量取决于与查询一起传递的上下文。如果我们的LLM无法从提供的上下文中找到对查询的适当答案,那么由我们的RAG系统生成的响应质量差也就不足为奇了。
因此,在考虑改进RAG系统中的嵌入模型和LLM之前,我们始终应该问以下问题:
我们的数据库中是否有正确的数据?
我们是否已将所有可用的数据从数据源收集到我们的数据库中?
我们在将数据传递给嵌入模型之前是否实施了正确的数据清洗流程?
我们是否对我们的数据实施了适当的分块方法?
我们是否对我们的数据实施了正确的数据预处理方法(例如,PDF解析、OCR解析)?
解决与数据相关的问题是优化由RAG驱动的应用程序性能的关键第一步。只有在验证数据质量之后,我们才应该考虑改进嵌入模型、LLM或RAG系统的其他组件。
代理:带有子查询的查询路由
目前,常见的RAG系统从内部数据库中保存的文本和嵌入中检索给定查询的相关上下文。然而,这种方法可能会演变,因为上下文可以从内部数据库和外部来源(如网络搜索)中检索。
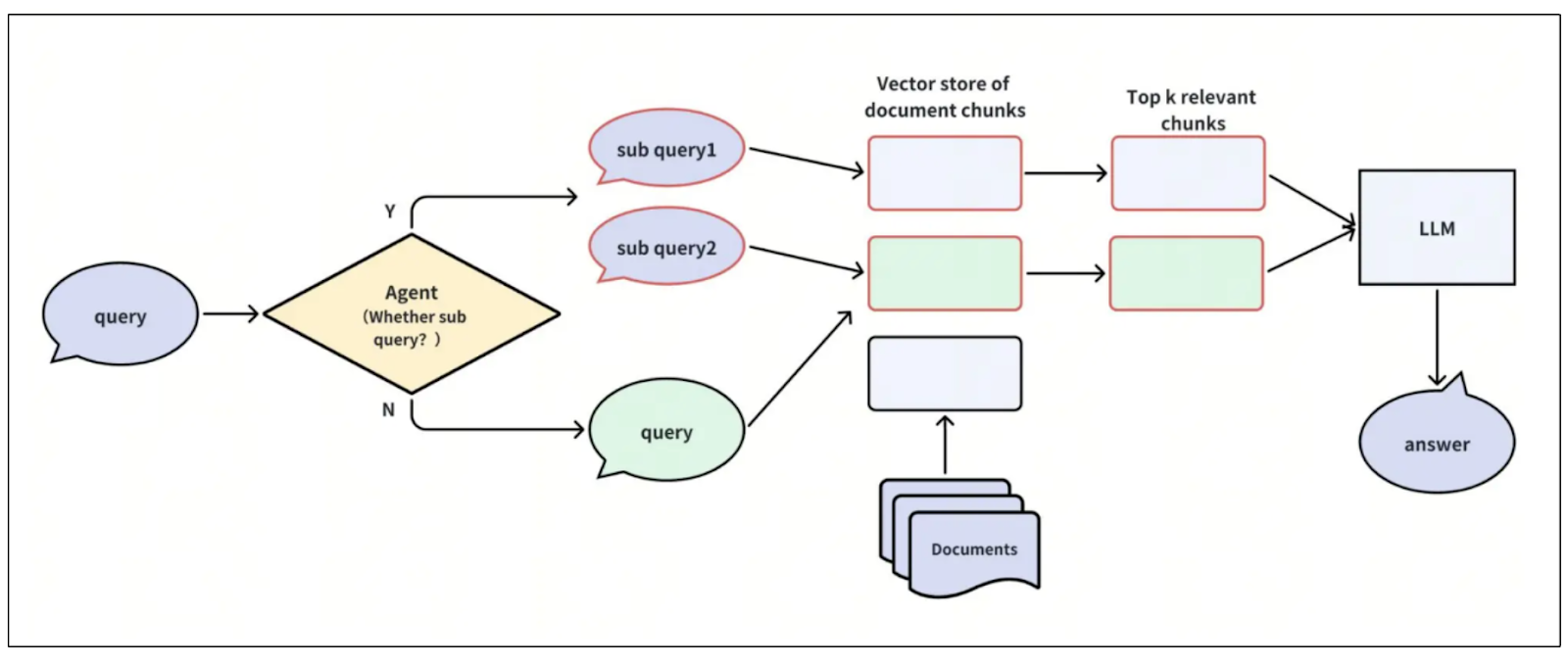 Visualization_of_agents_for_query_routing_6a8d8ff894.png
Visualization_of_agents_for_query_routing_6a8d8ff894.png
代理查询路由的可视化
这个领域的研究仍在进行中,但在RAG系统中添加所谓的“代理”可能有助于确定给定查询的适当上下文来源。
例如,对于“谁开始了人工智能研究?”这样的查询,代理可以决定是否需要RAG来回答这个问题。如果不需要,系统可以让LLM直接对查询生成响应,而不需要任何额外的上下文。
如果认为需要RAG,代理应该确定上下文的来源,无论是内部数据库还是外部来源。另一种方法是让代理从各种来源聚合信息到一个单一的、汇总的上下文中,该上下文可以由LLM用来生成适当的答案。
结论
LLM在生成类人文本响应方面的强劲性能已经改变了整个信息检索的格局。RAG的引入旨在通过为给定查询提供相关上下文来提高LLM的响应准确性。这些上下文通常存储为嵌入,必须存储在像Milvus这样的向量数据库中。
作为一个具有先进向量搜索能力的开源向量数据库,Milvus提供了与流行的AI工具包(如Snowflake)的无缝集成。有了Snowflake的Snowpark容器服务(SPCS),用户现在可以在Snowflake生态系统内运行Milvus,允许他们轻松地使用存储在Snowflake中的数据与Milvus进行交互。
注:本文为AI翻译,查看原文
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer