



使用 Neo4j 和 Milvus 搭建 GraphRAG Agent
文本最初发布于 Neo4j,已获得授权转载。
概览
本文详细介绍了如何使用 Neo4j 图数据库和 Milvus 向量数据库搭建 GraphRAG Agent。这个 Agent 通过结合图数据库和向量搜索的强大功能,能够提供准确且与用户查询十分相关的答案。在本文示例中,我们将使用 LangGraph、Llama 3.1 8B 配合 Ollama 和 GPT-4o。
传统的检索增强生成(RAG)系统仅依赖向量数据库来检索相关文档。但我们进一步通过引入 Neo4j 来捕捉 Entity 和概念之间的关系,提供对信息更细致的理解。我们希望通过结合这两种技术,搭建一个更可靠、更富含信息量的 RAG 系统。
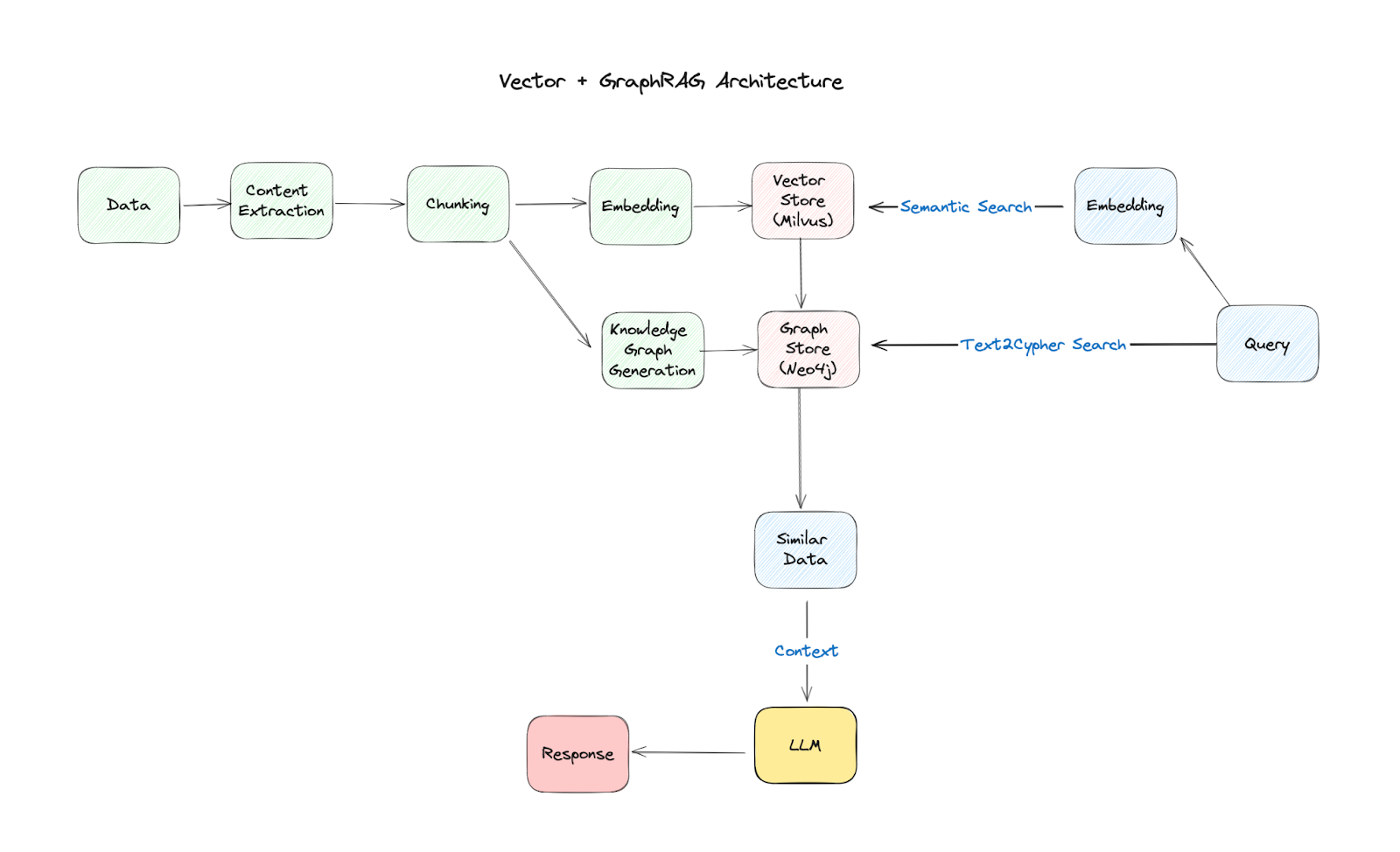 Vector_Graph_RAG_Architecture_46ecb2f9c3.png
Vector_Graph_RAG_Architecture_46ecb2f9c3.png
搭建 RAG Agent
我们的 Agent 遵循三个关键概念:路由(routing)、回退机制(fallback)和自我修正(self-correction)。这些原则通过一系列 LangGraph 组件实现:
路由 —— 一个专门的路由机制决定是使用向量数据库、知识图谱,还是两者的结合,这取决于查询内容。
回退机制 —— 在初始检索不足的情况下,代理会回退到使用 Tavily 进行网络搜索。
自我修正 —— Agent 评估答案,并尝试修正幻觉(Hallucination)或不准确之处。
我们还有其他组件,例如:
检索 —— 我们使用 Milvus,一款高性能的开源向量数据库,用于存储文档片段并根据与用户查询的语义进行相似性搜索。
图增强 —— 使用 Neo4j 从检索到的文档构建知识图谱,用关系和 Entity 丰富上下文。
大语言模型(LLM)集成 —— Llama 3.1 8B,一个本地 LLM,用于生成答案并评估检索信息的相关性和准确性,而 GPT-4o 用于生成 Cypher,即 Neo4j 使用的查询语言。
GraphRAG 架构
我们的 GraphRAG Agent 的架构可以被看作是一个具有多个相互连接的节点的工作流程:
问题路由 —— Agent 首先分析问题,以确定最佳的检索策略(向量搜索、图谱搜索或两者兼有)。
检索 —— 根据路由决策,从 Milvus 检索相关文档,或从 Neo4j 图谱中提取信息。
生成 —— LLM 使用检索到的上下文生成答案。
评估 —— Agent 评估生成的答案的相关性、准确性,并检测是否出现幻觉。
细化(可选) —— 如果对答案不满意,Agent 可能会优化其搜索或尝试纠正错误。
Agents 示例
为了展示 LLM Agent 的能力,让我们深入了解两个不同的组件:图生成 Graph Generation和复合代理 Composite Agent。
本章节将帮助您更好理解这些 Agent 在 LangChain 框架中的工作原理。您可以在文末获取完整代码。
Graph Generation
这个组件旨在通过使用 Neo4j 的能力来改进问答过程。它通过利用 Neo4j 图形数据库中的知识来回答问题。以下是它的工作原理:
GraphCypherQAChain:允许 LLM 与 Neo4j 图数据库进行交互。它以两种方式使用 LLM:
cypher_llm:这个 LLM 实例负责生成 Cypher 查询,以便根据用户的问题从图中提取相关信息。验证:确保 Cypher 查询经过验证,以确保它们从语法上来说是正确的。
上下文检索:在 Neo4j 图上进行经过验证的查询以检索相关的上下文。
答案生成:语言模型使用检索到的上下文来生成用户问题的答案。
### Generate Cypher Query
llm = ChatOllama(model=local_llm, temperature=0)
# Chain
graph_rag_chain = GraphCypherQAChain.from_llm(
cypher_llm=llm,
qa_llm=llm,
validate_cypher=True,
graph=graph,
verbose=True,
return_intermediate_steps=True,
return_direct=True,
)
# Run
question = "agent memory"
generation = graph_rag_chain.invoke({"query": question})
这个组建帮助 RAG 系统充分利用 Neo4j,从而提供更准确的答案。
Composite Agent:图 + 向量 🪄
如同魔法一般,我们的 Agent 可以结合 Milvus 和 Neo4j 的结果,从而更好地理解信息,并返回更准确和细致的答案。以下是 Composite Agent 组件的工作原理:
Prompt —— 我们定义了一个 Prompt,指导 LLM 使用来自 Milvus 和 Neo4j 的上下文来回答问题。
检索 —— Agent 从 Milvus(使用向量搜索)和 Neo4j(使用图生成)检索相关信息。
答案生成 —— Llama 3.1 8B 处理提示,并生成一个简洁的答案,利用来自向量和图数据库的复合链组合知识。
### Composite Vector + Graph Generations
cypher_prompt = PromptTemplate(
template="""You are an expert at generating Cypher queries for Neo4j.
Use the following schema to generate a Cypher query that answers the given question.
Make the query flexible by using case-insensitive matching and partial string matching where appropriate.
Focus on searching paper titles as they contain the most relevant information.
Schema:
{schema}
Question: {question}
Cypher Query:""",
input_variables=["schema", "question"],
)
# QA prompt
qa_prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following Cypher query results to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise. If topic information is not available, focus on the paper titles.
Question: {question}
Cypher Query: {query}
Query Results: {context}
Answer:""",
input_variables=["question", "query", "context"],
)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Chain
graph_rag_chain = GraphCypherQAChain.from_llm(
cypher_llm=llm,
qa_llm=llm,
validate_cypher=True,
graph=graph,
verbose=True,
return_intermediate_steps=True,
return_direct=True,
cypher_prompt=cypher_prompt,
qa_prompt=qa_prompt,
)
让我们来看一下搜索结果,结合图数据库和向量数据库的优势来增强在研究论文中的发现。
我们首先使用 Neo4j 进行图搜索:
# Example input data
question = "What paper talks about Multi-Agent?"
generation = graph_rag_chain.invoke({"query": question})
print(generation)
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (p:Paper)
WHERE toLower(p.title) CONTAINS toLower("Multi-Agent")
RETURN p.title AS PaperTitle, p.summary AS Summary, p.url AS URL
> Finished chain.
{'query': 'What paper talks about Multi-Agent?', 'result': [{'PaperTitle': 'Collaborative Multi-Agent, Multi-Reasoning-Path (CoMM) Prompting Framework', 'Summary': 'In this work, we aim to push the upper bound of the reasoning capability of LLMs by proposing a collaborative multi-agent, multi-reasoning-path (CoMM) prompting framework. Specifically, we prompt LLMs to play different roles in a problem-solving team, and encourage different role-play agents to collaboratively solve the target task. In particular, we discover that applying different reasoning paths for different roles is an effective strategy to implement few-shot prompting approaches in the multi-agent scenarios. Empirical results demonstrate the effectiveness of the proposed methods on two college-level science problems over competitive baselines. Our further analysis shows the necessity of prompting LLMs to play different roles or experts independently.', 'URL': 'https://github.com/amazon-science/comm-prompt'}]
图搜索在查找关系和元数据方面表现出色。它能够快速根据标题、作者或预定义的类别识别论文,提供数据的结构化视图。
下面,我们换个角度,看一下使用向量搜索的结果:
# Example input data
question = "What paper talks about Multi-Agent?"
# Get vector + graph answers
docs = retriever.invoke(question)
vector_context = rag_chain.invoke({"context": docs, "question": question})
> The paper discusses "Adaptive In-conversation Team Building for Language Model Agents" and talks about Multi-Agent. It presents a new adaptive team-building paradigm that offers a flexible solution for building teams of LLM agents to solve complex tasks effectively. The approach, called Captain Agent, dynamically forms and manages teams for each step of the task-solving process, utilizing nested group conversations and reflection to ensure diverse expertise and prevent stereotypical outputs.
向量搜索在理解上下文和语义相似性方面非常出色。它能够发现与查询概念相关的论文,即使这些论文没有明确包含搜索词。
最后,我们结合了两种搜索方法:
这是我们 RAG Agent 的一个关键部分,帮助我们同时发挥向量和图数据库的力量。
composite_chain = prompt | llm | StrOutputParser()
answer = composite_chain.invoke({"question": question, "context": vector_context, "graph_context": graph_context})
print(answer)
> The paper "Collaborative Multi-Agent, Multi-Reasoning-Path (CoMM) Prompting Framework" talks about Multi-Agent. It proposes a framework that prompts LLMs to play different roles in a problem-solving team and encourages different role-play agents to collaboratively solve the target task. The paper presents empirical results demonstrating the effectiveness of the proposed methods on two college-level science problems.
通过整合图搜索和向量搜索,我们发挥了这两种方法的优势。图搜索提供了精确度并展示了结构化的关系,而向量搜索通过语义理解增加了深度。
这种结合的方法提供了几个优势:
提高召回率:能够找到可能被单一方法遗漏的相关论文。
增强上下文:对论文之间关系提供了更细致的理解。
灵活性:可以适应不同类型的查询,从具体的关键词搜索到更广泛的概念探索。
总结
本文展示了如何使用 Neo4j 和 Milvus 搭建一个 GraphRAG Agent。通过结合图数据库和向量搜索的优势,这个 Agent 能够为用户提供准确且相关的查询答案。
这个 RAG Agent 的架构中,配备了专门的路由、回退机制和自我修正能力,从而变得更可靠。Graph Generation 和 Composite Agent 组件的示例展示了这个 Agent 如何利用向量和图数据库来提供全面且细致的答案。
我们希望这篇文章对您有所帮助。同时,我们鼓励您在自己的项目中结合图数据库和向量搜索,探索更多可能性。
本文涉及的代码可以通过 GitHub 获取。
 Stephen Batifol
Stephen BatifolDeveloper Advocate
 Jason Koo
Jason KooDeveloper Advocate, Neo4j


