



推荐系统中的近似最近邻搜索
在2024年2月,我们在旧金山非结构化数据聚会上听到了Yury Malkov关于近似最近邻(ANN)及其在推荐系统中的关键作用的演讲。ANN搜索已经整合到了世界上最受欢迎的工具的生产堆栈中。Yury帮助我们理解了推动ANN在大规模推荐系统中被采用的关键概念和背景。
Yury Malkov演讲的YouTube回放链接:在YouTube上观看演讲
为什么你应该关心ANN?
Yuri Malkov简直就是个天才。如果你不相信我,可以查看他的Google Scholar列表:https://scholar.google.com/citations?user=KvAyakQAAAAJ&hl=en。物理学家、激光研究员,以及HNSW(一种基于图的索引算法)的发明者,现在所有主要的向量数据库都内置了这种算法。他现在在OpenAI担任研究科学家。告诉我,这听起来不像是2024年Tony Stark的可信传记吗?
让我们深入Yuri关于“推荐系统中的近似最近邻搜索”的演讲。
什么是ANN搜索?
我们将简要介绍,因为我们已经简短且详细地介绍了ANN搜索的基础知识。
最近邻搜索是一组统计技术,我们可以使用它们在机器学习或数据科学应用中进行相似性搜索。与它们特殊的K风味的KNN不同,KNN在完成搜索时会将系统中的每个数据点相互比较,ANN搜索算法使用各种索引技术返回近似最近邻。ANN搜索已经成为今天面向客户的许多应用程序和技术的核心。从搜索引擎(像谷歌,不是向量搜索)到社交媒体网站,ANN和推荐系统已经通过堆栈集成到生产中。
ANN并不是推荐系统的唯一解决方案。那么我们是如何走到这一步的呢?我们将介绍当今市场上成熟的ANN解决方案,推荐系统对最近邻算法来说是一个棘手问题的原因,开发人员如何构建推荐系统,以及研究人员如何使用ANN重写推荐系统堆栈。Yuri在他的演讲中指出,许多成熟的ANN解决方案存在。这些主题在我们的“选择向量索引的视觉指南”中都有深入的介绍,但我整理了Yuri演讲中提到的工具表。
提到的ANN索引表
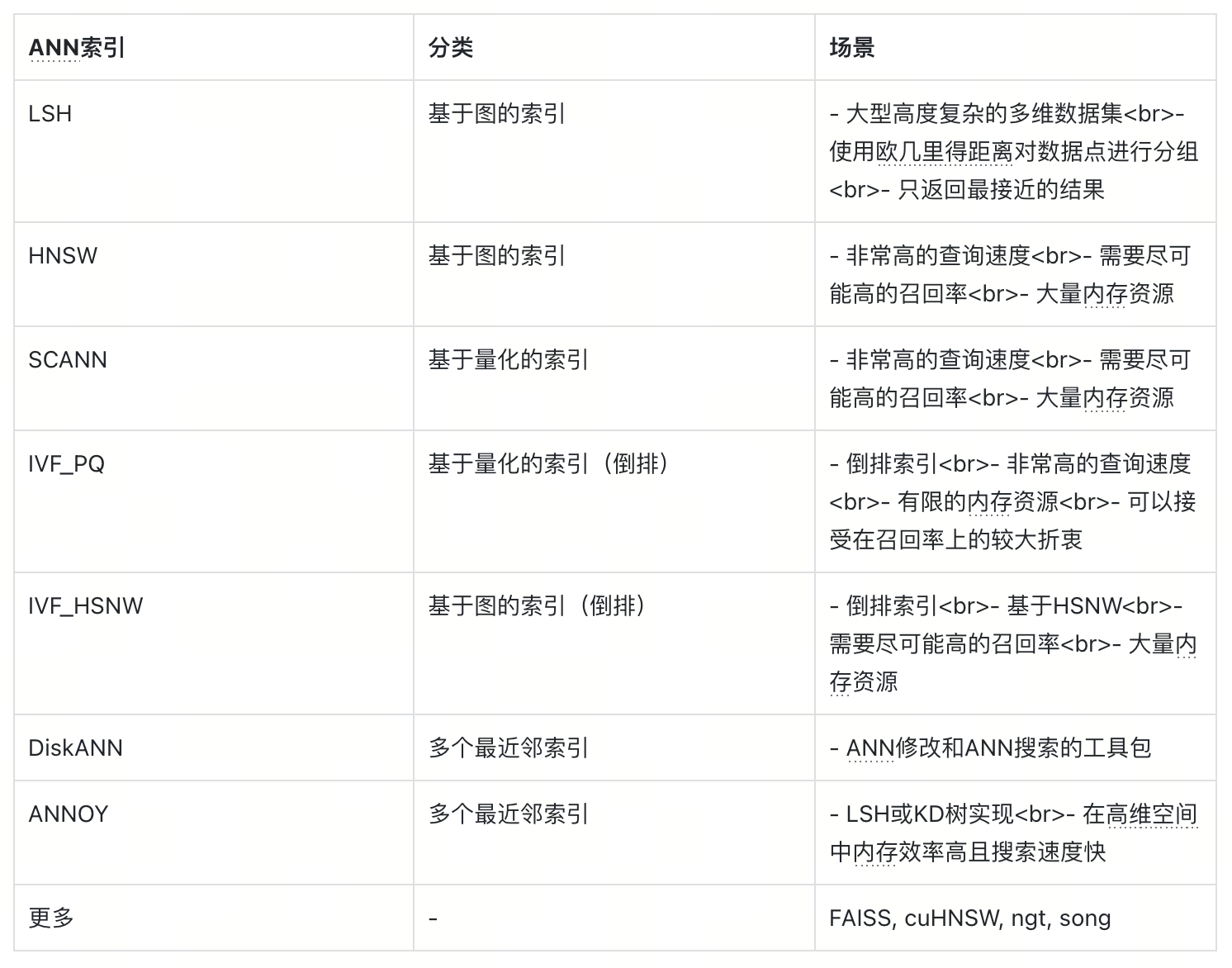 84-1.png
84-1.png
关于ANN基准测试
Yuri快速地介绍了ANN基准测试 - 指向ANN基准测试,并指出基准测试逆ANN算法可能会变得棘手。让我们放慢速度:
什么是ANN基准测试?
ANN基准测试是一个基准测试环境,评估各种近似最近邻搜索算法,并在他们的网站上按距离度量和数据集提供结果。基准测试显示性能指标,如召回率和每秒查询次数,用户可以通过GitHub拉取请求提交他们的代码。
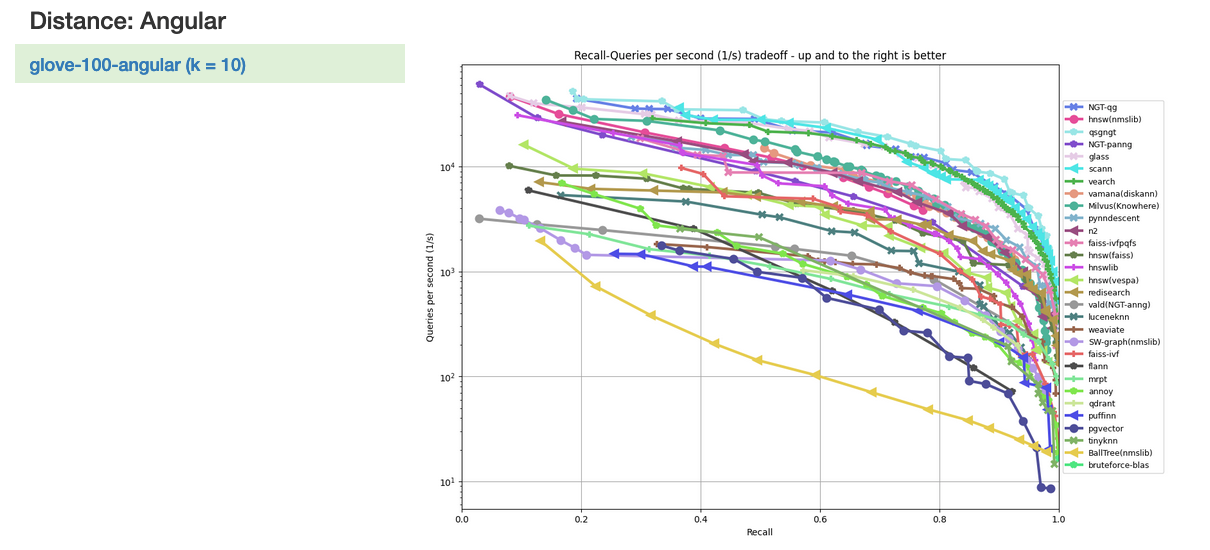 84-2.png
84-2.png
选择ANN(和其他向量搜索)算法的说明
如果查看算法基准测试让你感到头痛,你并不孤单。这就是为什么Milvus团队构建了Knowhere。Knowhere是Milvus的核心开源向量执行引擎,它结合了几个向量相似性搜索库,包括Faiss、Hnswlib和Annoy。Knowhere控制在哪种硬件(CPU或GPU)上执行索引构建和搜索请求。这就是Knowhere得名的原因 - 知道在哪里执行操作。未来版本将支持更多类型的硬件,包括DPU和TPU。
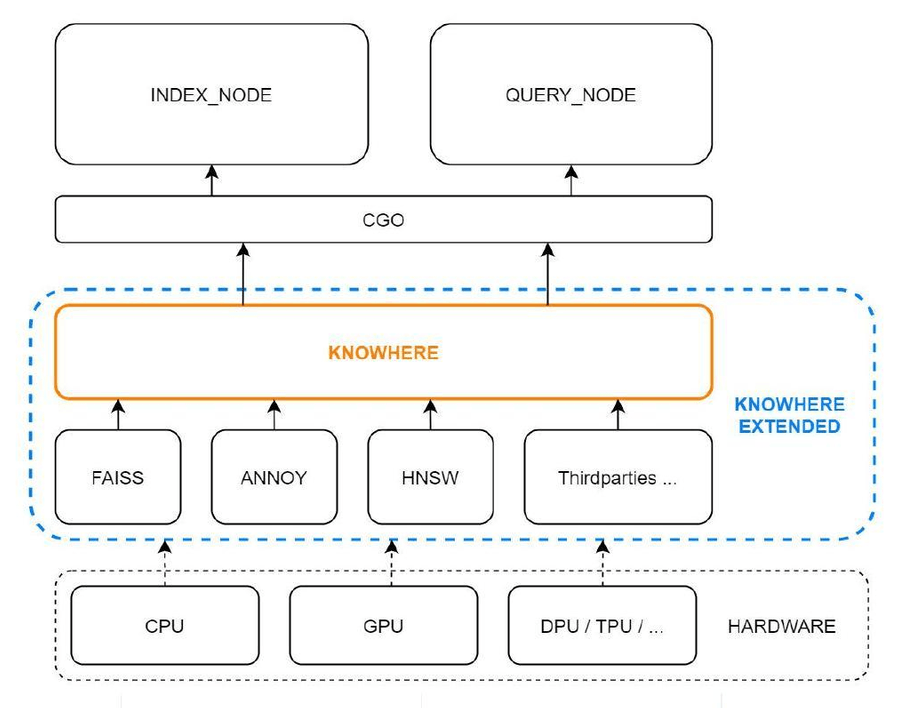 84-3.png
84-3.png
在Knowhere基础上构建 - Zilliz Cloud团队发布了Cardinal,这是Zilliz的核心向量搜索引擎。这个搜索引擎已经证明了与以前版本相比性能提高了三倍,提供了达到Milvus十倍的搜索性能(QPS)。ANN搜索早已整合到推荐系统中。要了解为什么ANN搜索算法在生产中变得如此流行,我们需要退一步,看看ANN超越了的动机、架构和新颖解决方案。
大规模推荐系统应用:动机和挑战
目标:所有推荐系统的基本目标是返回一个项目(视频、产品、文档、消息)给一个查询(用户、应用程序、上下文)。记住这个项目-查询关系 - 这对理解搜索(推荐)算法很重要。
市场:推荐技术已经呈现并代表了一个巨大的市场,因为它们能够产生消费者行为。
大规模的典型挑战:
生成性: 传统推荐系统通常生成性较低 - 主要是由于依赖内部数据、模型和基础设施。
庞大的语料库: 大型数据集(百万到万亿个项目、查询)产生巨大的推理成本。 效率和限制推理成本非常重要。
**重量级视频和图像处理需要专门的工程师来维护基础设施。
解决方案,成熟度: 自家解决方案/基础设施通常是自家种植的(例如谷歌、Meta、X) 通常是一个多阶段推荐漏斗(见下文)以节省推理成本 现成的工具在向量数据库和LLMs的崛起中越来越受欢迎和吸引力。
典型的多阶段漏斗
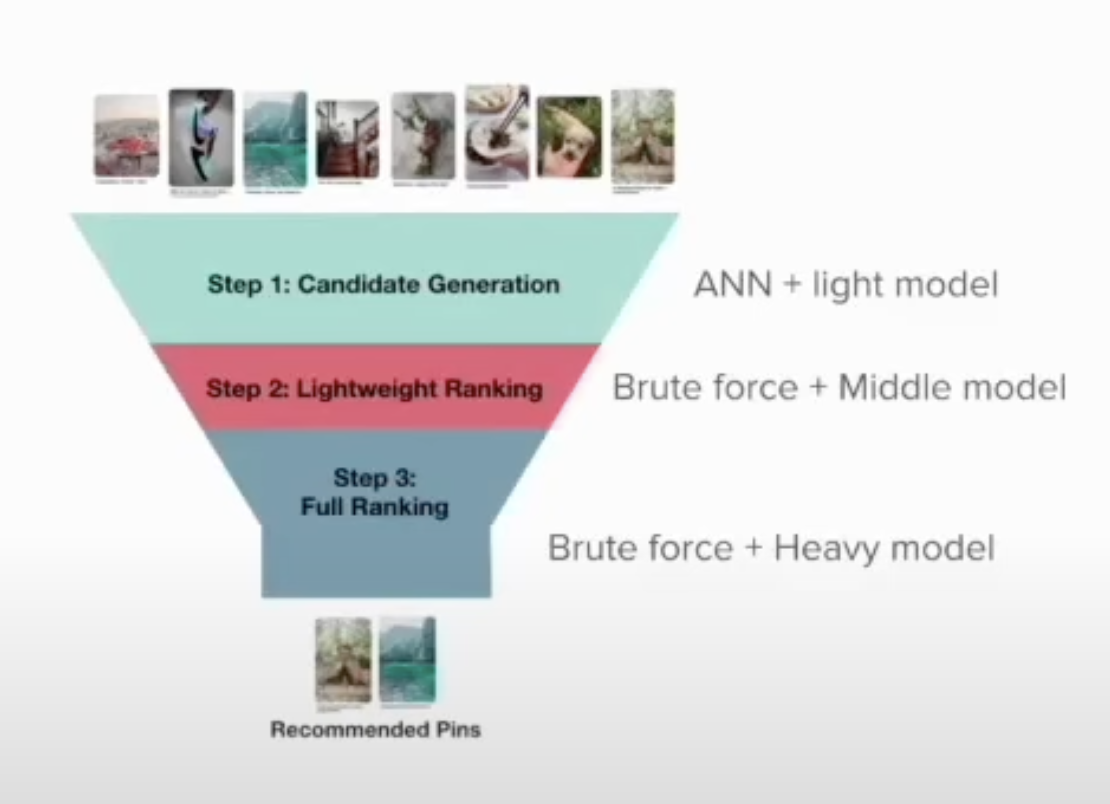
Yuri深入研究了一个典型的生产推荐系统的图表。在下面的视频推荐示例中,应用程序接收项目和查询,并必须返回视频推荐引脚。这些应用程序是多阶段漏斗,其中项目候选项被生成并通过连续的排名模型运行以细化搜索结果。
步骤1:候选项生成 - ANN + 轻量模型 在这个阶段,系统使用近似最近邻快速筛选庞大的视频数据库,并确定与用户查询相关的初步候选视频列表。这个过程设计得快速高效,处理可能的数百万项目,专注于最有可能匹配查询特征的项目。在这一步中使用的“轻量模型”通常是更简单、计算量较小的模型,有助于将候选池缩小到最符合用户兴趣或搜索词的项目。
步骤2:轻量级排名 - 暴力方法 + 中型模型 一旦生成候选集,下一步涉及对这些候选项进行更详细的检查。这是通过“暴力方法”完成的,其中每个候选项都使用比第一步中使用的轻量模型更复杂的“中型模型”进行更彻底的评估。这个模型考虑了额外的特征,如用户参与度指标、上下文相关性和内容质量,以一种将最相关视频推向推荐列表顶部的方式对候选项进行排名。这一步在性能和精度之间取得了平衡,通过更注重质量和相关性来细化选择。
步骤3:完整排名 - 暴力方法 + 重型模型 推荐过程的最后阶段是完整排名阶段,它采用了“重型模型” - 使用的模型中最复杂和资源密集型的模型。这个模型结合了广泛的信号和数据点,包括更深入的用户档案分析、长期偏好、详细内容分析,可能还有实时数据,如当前的观看趋势。应用在这里的暴力方法确保每个视频都被全面评分和排名,确保最终推荐高度个性化和相关。这一步确保了最高质量的推荐,但需要更多的处理能力和时间,使其适合最终推荐列表的细化。
 84-4.png
84-4.png
为什么HSNW在传统推荐系统中表现不佳以及(不完美的)解决方案
知道大规模生产推荐系统受到大型数据集和相关成本的限制,Yuri断言项目和查询位于两个 - 不兼容的平面上。 当查询和项目位于不同且不兼容的空间时,传统的相似性搜索算法如分层可导航小世界(HNSW)面临挑战,因为这些算法依赖于直接在查询和项目之间的可测量关系或距离函数。没有明确的度量来评估接近度,HNSW无法有效地执行其功能,即通过项目图导航以找到与查询最匹配的项目。
对项目-查询不兼容性的新颖解决方案回顾
数据向量上的L2距离 工作原理:使用向量化数据输入之间的L2距离来创建推荐系统的替代图结构。 优点:通过使用直接的距离计算简化了过程,在候选生成和重新排名阶段提供了速度优势。 缺点:可能无法像更复杂的模型那样有效地捕捉项目和查询之间的复杂关系或细微差别,可能导致个性化推荐较少。 参考:https://scholar.google.com/citations?view_op=view_citation&hl=en&user=glaTwrUAAAAJ&sortby=pubdate&citation_for_view=glaTwrUAAAAJ:dhFuZR0502QC
二分图排名 工作原理:将项目和查询投影到二分图中,项目与它们最接近的用户或查询链接,允许基于这些关系生成边。 优点:在构建用户和项目之间的关系数据方面非常有效,尽管与其他方法的直接比较有限。 缺点:构建和维护二分图可能是资源密集型的,其有效性可能因图连接的密度和质量而大不相同。
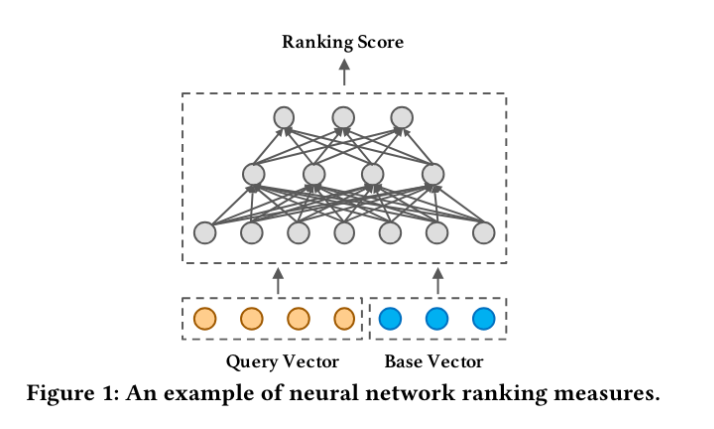 84-5.png
84-5.png
图片来源:https://www.vldb.org/pvldb/vol15/p794-tan.pdf
基于图的重新排名(以文本为重点) 工作原理:利用向量创建的图进行候选生成,直接将重排名器应用于图以进行文本检索,从而提高结果质量。 优点:消除了传统的多阶段漏斗,允许纠正早期候选过滤阶段的错误。 缺点:主要适用于基于文本的检索;在非文本特征占主导地位的其他情境中可能不太有效,限制了其适用性。
 84-6.png
84-6.png
图片来源:https://arxiv.org/pdf/2208.08942
级联图搜索 工作原理:以轻量级距离函数开始初始搜索,并在搜索过程中无缝过渡到更重的距离函数。 优点:通过实时调整距离函数提供灵活性,优化搜索过程的速度和准确性。 缺点:管理和优化双重距离函数的复杂性可能会增加系统的计算开销和复杂性,可能影响可扩展性。
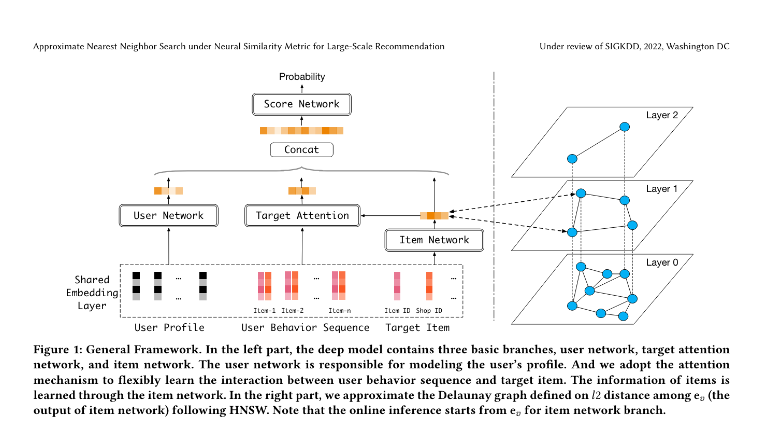 84-7.png
84-7.png
图片来源:https://arxiv.org/pdf/2202.10226
为什么ANN搜索如此受欢迎? 将所有这些放在一起 - Yuri很好地描绘了为什么ANN算法在应用中看到了如此广泛的实施,特别是在处理高维数据集的大规模推荐系统中。 足够好(或更好)的匹配 - 如果你不需要完美的匹配,ANN风味总是几乎比其他NN算法更好的解决方案。 灵活性 - 有广泛的实现,开发人员可以选择成本 成熟度 - ANN已经在所有主要的编程语言中实现,并且有几个流行的框架用于选择和执行ANN搜索。
更多资源 https://zilliz.com/learn/Local-Sensitivity-Hashing-A-Comprehensive-Guide https://zilliz.com/learn/how-to-pick-a-vector-index-in-milvus-visual-guide https://docs.zilliz.com/docs/ann-search-explained https://milvus.io/docs/index.md
 Tyler Falcon
Tyler FalconDigital Marketing Manager at Zilliz.


