Response指南:为什么90%的多模态RAG,一做就会,一用就废?
前言
近年来,GPT-4V、Gemini Pro Vision 等多模态大模型快速兴起,将图像、文本、音频等多种数据类型统一理解的能力,拓展到了搜索问答、辅助诊疗、法律检索等更复杂的任务场景中。
相比传统大语言模型(LLMs),多模态大模型具备更强的上下文理解能力,适配更丰富的输入方式,具备更广泛的落地潜力。
但与此同时,这些模型也继承了LLMs的一个老毛病:幻觉。尤其是在处理图文混合输入时,模型可能产生与事实不符、逻辑混乱的输出。为了解决这一问题,RAG(检索增强生成)成为业内主流方案——通过外部向量数据库提供的高相关内容,帮助模型“补课”,降低幻觉概率。
在 Zilliz 主办的一场非结构化数据 Meetup 上,来自 TruEra(已被 Snowflake 收购)的开发布道师 Josh Reini 深入讲解了多模态 RAG 架构的实际挑战与落地经验,并分享了如何借助开源工具 TruLens 进行系统级评估,以及如何集成 Milvus 向量数据库来提升检索效果。
01
为什么说多模态RAG会成为大趋势?
与传统只接受文本输入的语言模型不同,多模态大模型可并行处理图像、文字、视频等多种模态,在理解力和生成能力上更接近“现实场景”。
例如,仅依靠图像输入让模型生成中国神话角色“哪吒”的形象,可能出现“双头七臂”之类的误解;但一旦配合如“三头六臂”的文本提示,生成结果便能更准确地符合文化设定。
为了让模型具有“长期记忆”,多模态RAG可以将来自外部的图像、文字、音频、视频等信息嵌入(embedding)到向量数据库(如 Milvus 或托管版 Zilliz Cloud)中,结合检索与生成,形成增强的智能推理能力。
这种多模态RAG能力,相比传统LLM,相当于给一个聪明的大脑,加上了负责记忆的海马体之外,还打通了视觉、听觉等五感,从而更好的理解与响应用户需求。
02
多模态 RAG 系统架构拆解
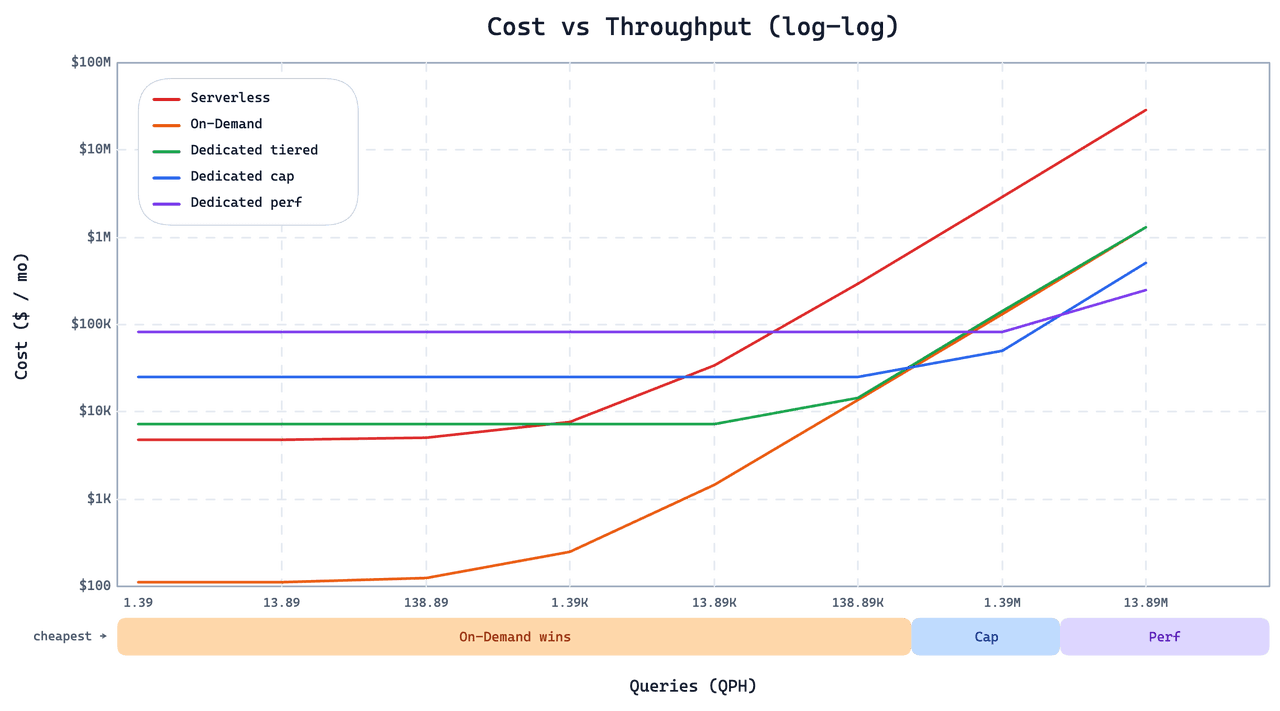
我们以“图像问答”任务为例,来理解多模态 RAG 的工作流程:
多模态RAG系统工作流程
Multimodal Input Processing(多模态输入处理):RAG系统接收用户的查询问题以及相关图像。
Embedding:使用多模态embedding模型将图像和文本查询转换为统一的向量表达,从而能够分析、理解、比较不同模态输入之间的关系。
Vector Database Retrieval(向量数据库检索):系统使用 embedding 查询 Milvus或者Zilliz Cloud 数据库,返回相似图像及其关联注释;
Completion(完成):检索到的数据(相似图像及其注释)与原始输入查询结合,形成大模型生成响应的上下文窗口。
Response(响应):多模态大模型据此输出更精准、更具语境感的答案。
03
为什么原型无法直接上线?
尽管多模态RAG的效果在demo阶段常常令人惊艳,但一旦进入生产环境,问题随之暴露:如何判断模型是否在“胡说”?是否检索对了内容?是否真正用了检索到的内容?不同组件出了问题,怎么排查?
这些问题的核心在于——缺少系统性评估机制。而这对于教育、医疗、金融等高准确率要求行业,评估工具不可或缺。
目前常见的开源或商用评估工具包括 TruLens、Ragas、LangSmith、LangFuse、OpenAI Evals、DeepEval 和 Phoenix。
其中,TruLens 是目前多模态支持度最强、社区活跃度最高的方案之一,支持与向量数据库、OpenAI、LangChain 等框架无缝集成。
04
如何用 TruLens 评估多模态 RAG:三大核心指标
概括而言,Trulens的优势在于监控、测试和调试应用的能力。通过集成 TruLens,开发团队可以在系统运行过程中持续记录日志、收集反馈,并在每次迭代中明确优化方向。
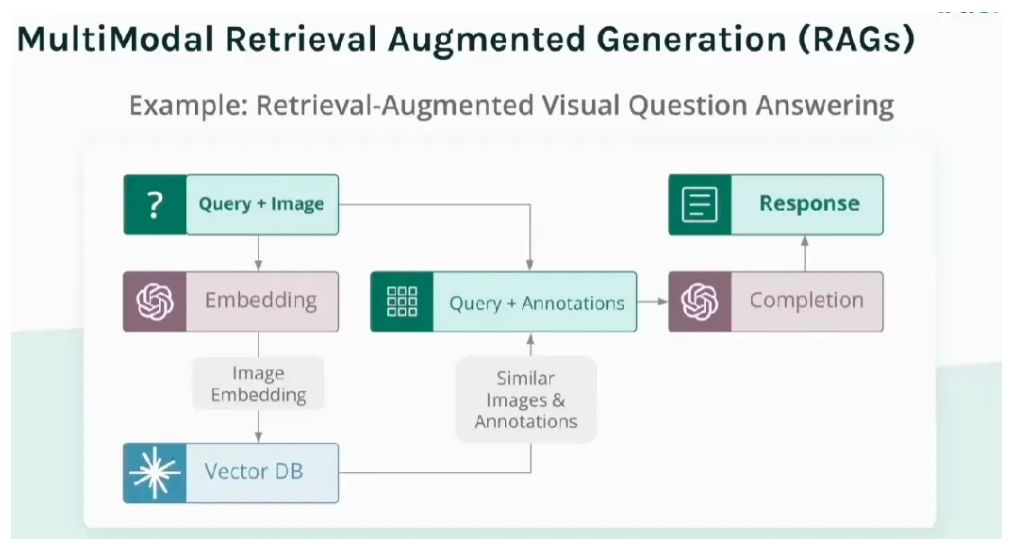
在典型的RAG系统中,需要评估三个核心组件如下:
RAG的三个核心组件
Query(查询):即用户发送的查询,可能是文本或文本和图像组合的形式。我们需要评估输入是否清晰、是否会引发歧义(如图文冲突)。
Context(检索上下文):系统从向量数据库中检索到的相关信息,如图像和文本。这部分,需要评估系统从向量数据库中检索回来的内容是否与问题相关,是否提供了有用信息。
Response(模型输出):LLM或多模态模型基于检索到的上下文和原始查询生成答案。这部分,评估生成的回答是否基于上下文,是否存在逻辑错误或编造内容。
基于此,TruLens的所有评估,主要基于三大方面出发:
Context Relevance(上下文相关性):检索到的内容是否与原始问题匹配?
Groundedness(基于事实):回答是否有检索内容支撑?
Answer Relevance(答案相关性):最终回答是否有用、准确、有逻辑?
05
实战:X-ray Insight 的医学图像问答系统
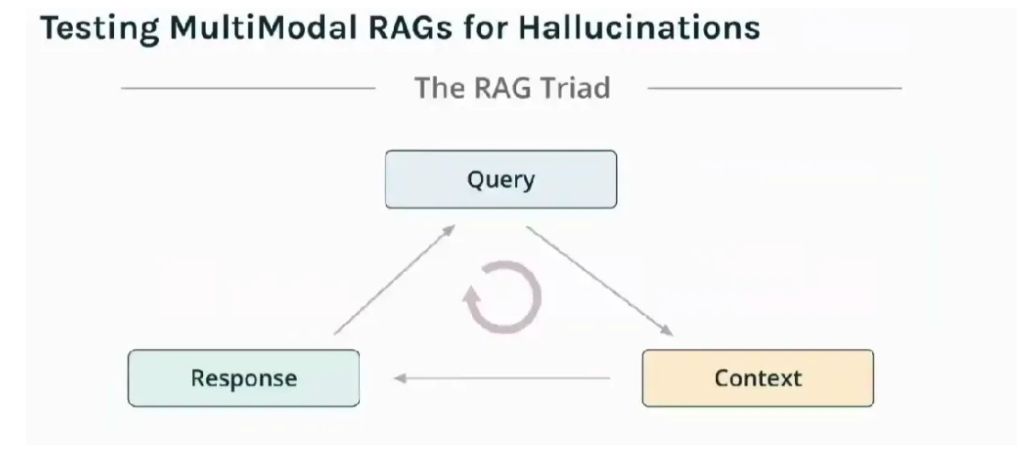
在一次黑客松中,X-ray Insight 团队构建了一个基于 Milvus 和 TruLens 的图像问答系统,用于 X 光图像辅助诊断。
系统流程如下:
第一步,图像预处理:用户上传 X 光图与诊断,其中, X 光图系统生成 embedding后,与元数据(诊断)一起加载到Milvus/Zilliz向量数据库
第二步,向量检索:Milvus 检索相似病例图像及诊断注释;
第三步,诊断生成:多模态模型结合原始输入和注释生成建议诊断;
第四步,系统评估:TruLens 评估生成诊断是否真实可靠,并根据获得的反馈进行改进。(准确说,这个评估流程其实从预处理阶段就已经伴随产生)
X-ray Insight系统的工作流程
结论
多模态RAG架构的出现,无疑让我们离“通用人工智能”的愿景更近了一步。但它并不是银弹。再先进的模型,也可能在关键时刻出现幻觉,真正决定一个AI系统能否落地并可持续演进的,不是它能生成什么,而是我们是否有能力让它做的更好。
而围绕做的更好,必须要有充分的工程实践,以及对细节的打磨。过程中,像Milvus这样的向量数据库,可以把RAG系统的“知识外脑”变得可扩展、可控、可观测。TruLens则把评估从事后倒查,变成过程中优化,成为系统性设计的一部分。
如需进一步了解 TruLens 与 Milvus 的集成方式,欢迎访问我们的文档与 GitHub 示例仓库。
 Zilliz
Zilliz